分割中的解码编码结构-SegNet(包含代码复现)
分割中的解码编码结构-SegNet
- 一 前置知识
-
- 1.1 编码器-解码器架构
- 2.2 随机丢弃层(dropout)
- 2.3 反池化
- 二 论文研究背景、成果及意义
- 三 论文摘要
- 四 引言
- 五 相关工作
- 六 模型图
- 代码复现
一 前置知识
1.1 编码器-解码器架构
编码器:编码器部分主要由普通卷积层和下采样层将特征图尺寸缩小,使其成为更低微的表征。目的是提取更多低级特征和低级特征,从而利用提取到的空间信息和全局信息精确分割。
解码器:主要是普通卷积、上采样层和融合层组成。利用上采样操作逐步恢复空间维度,融合编码过程中提取到的特征,在尽可能减少信息损失的前提下完成同尺寸的输出。

2.2 随机丢弃层(dropout)
当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合,为了防止过拟合,可以通过阻止特征检测器的共同作用来提高网络性能。Dropout可以作为训练深度神经网络的一种技巧供选择。在每个批次训练中,可以忽略一半的特征检测器,可以明显的减少过拟合现象,这种方式可以减少特征检测器间的互相作用。
2.3 反池化
编码器中的每一个最大池化层的索引都存储了起来,用于之后在解码器中使用那些存储的索引来对应特征图进行去池化操作,这有助于保持高频信息的完整性,当但对地分辨图进行反池化时,他也会忽略临近信息。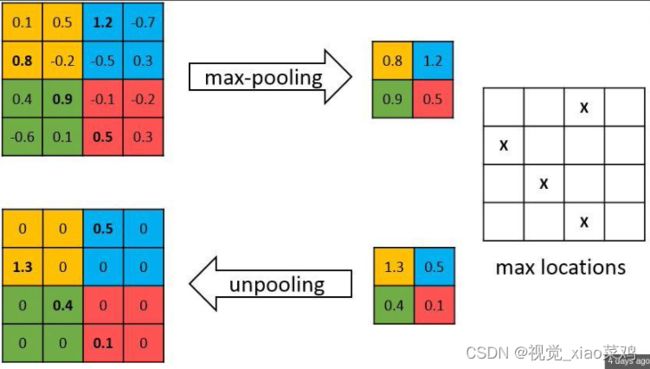
二 论文研究背景、成果及意义
- 在内存(参数)和准确率之间找到了很好地平衡点
- 将编码结构普适化
- 在多个场景数据集中均取得了好的结果
三 论文摘要
- 算法结构:提出了SegNet网络,其核心的训练引擎包含一个encode网络,和一个对称的decode网络,即编码器-解码器结构,并跟随一个用于pixel-wise的分类层。
- 文章亮点:decode进行上采样的方式,直接利用与之对应的encode阶段中,在经过最大池化时保留的polling idex进行非线性上采样
- 比较结果:通过比较SegNet与FCN、DeepLab-LargeFOV结构,统筹内存与准确率,SegNet实现了良好的分割效果
四 引言
近期的许多语义分割研究采用DNN,但是结果比较粗糙,主要原因是max-pooling和sub-sampling降低了特征图的分辨率,道路场景理解需要算法具有appearance外形、shape形状和理解空间关系(上下文)的能力。由于是道路场景,因此需要网络能够产生光滑的分割,网络也必须有能力勾画出小尺寸的物体,因此在提取图片特征过程中保留边界信息很重要。重用max-pooling indices的优点,提高边界够画,减少了进行端到端训练的参数,这种上采样形式可以被集成到任何encode-decode架构的网络中。
五 相关工作
- 介绍前FCN时代的深度学习分割方法
- 介绍FCN:
- FCN架构中的每个解码器都对其输入的特征图进行上采样,并将其与对应的编码器特征图组合,以产生下一个解码器的输入
- 该网络的整体大小使其难以在相关任务上端到端的进行训练,因此,作者使用了阶段性的训练过程,解码器网络中的每个解码器逐步添加到预训练好的网络中
- 网络生长直到没有进一步的性能提高,这种增长在三个解码器之后停止
- FCN弊端:
- 忽略了高分辨率的特征图,会导致边缘信息的丢失
- FCN编码器网络中有大量参数,但是解码器网络非常小
六 模型图

代码复现
导入需要用到的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
这里是用VGG16训练的,从models里面调用
vgg16_pretrained = models.vgg16(pretrained=False)
因为整个网络的解码部分是通过对VGG中对应编码部分池化做的反池化,所以需要将编码部分池化的索引拿到
pool_list = [4,9,16,23,30]
for index in pool_list:
vgg16_pretrained.features[index].return_indices = True
在解码部分,里面相同的模块我们可以用函数来包起来
def decode(input_channel,out_channel,num=3):
if num == 3:
decode_boby = nn.Sequential(
nn.Conv2d(input_channel,input_channel,3,padding=1),
nn.Conv2d(input_channel,input_channel,3,padding=1),
nn.Conv2d(input_channel,out_channel,3,padding=1)
)
if num == 2:
decode_boby = nn.Sequential(
nn.Conv2d(input_channel,input_channel,3,padding=1),
nn.Conv2d(input_channel,out_channel,3,padding=1)
)
return decode_boby
网络部分 没有加softmax这部分,读者可以自行加上
self.encode1 = vgg16_pretrained.features[:4]
self.pool1 = vgg16_pretrained.features[4]
self.encode2 = vgg16_pretrained.features[5:9]
self.pool2 = vgg16_pretrained.features[9]
self.encode3 = vgg16_pretrained.features[10:16]
self.pool3 = vgg16_pretrained.features[16]
self.encode4 = vgg16_pretrained.features[17:23]
self.pool4 = vgg16_pretrained.features[23]
self.encode5 = vgg16_pretrained.features[24:30]
self.pool5 = vgg16_pretrained.features[30]
self.decode5 = decode(512,512)
self.uppool5 = nn.MaxUnpool2d(2,2)
self.decode4 = decode(512,256)
self.uppool4 = nn.MaxUnpool2d(2,2)
self.decode3 = decode(256,128)
self.uppool3 = nn.MaxUnpool2d(2,2)
self.decode2 = decode(128,64,2)
self.uppool2 = nn.MaxUnpool2d(2,2)
self.decode1 = decode(64,12,2)
self.uppool1 = nn.MaxUnpool2d(2,2)
正向传播部分
encode1 = self.encode1(x)
output_size1 = encode1.size()
pool1,indices1 = self.pool1(encode1)
encode2 = self.encode2(pool1)
output_size2 = encode2.size()
pool2,indices2 = self.pool2(encode2)
encode3 = self.encode3(pool2)
output_size3 = encode3.size()
pool3,indices3 = self.pool3(encode3)
encode4 = self.encode4(pool3)
output_size4 = encode4.size()
pool4,indices4 = self.pool4(encode4)
encode5 = self.encode5(pool4)
output_size5 = encode5.size()
pool5,indices5 = self.pool5(encode5)
uppool5 = self.uppool5(pool5,indices5,output_size5)
decode5 = self.decode5(uppool5)
print(decode5.size())
uppool4 = self.uppool4(decode5,indices4,output_size4)
decode4 = self.decode4(uppool4)
print(decode4.size())
uppool3 = self.uppool3(decode4,indices3,output_size3)
decode3 = self.decode3(uppool3)
print("3:",decode3.size())
uppool2 = self.uppool2(decode3,indices2,output_size2)
print(uppool2.size())
decode2 = self.decode2(uppool2)
uppool1 = self.uppool1(decode2,indices1,output_size1)
decode1 = self.decode1(uppool1)
代码测试
img = torch.rand((1,3,480,480))
img.size()
SegNet = VGG16_SegNet()
SegNet(img)
结果:
input_img torch.Size([1, 3, 480, 480])
torch.Size([1, 512, 30, 30])
torch.Size([1, 256, 60, 60])
3: torch.Size([1, 128, 120, 120])
torch.Size([1, 128, 240, 240])
torch.Size([1, 12, 480, 480])