计算机视觉大型攻略 —— CUDA(3)内存模型(一)CUDA内存
上篇写了执行模型,这篇继续总结[1]的第四章: 内存模型。
首先介绍CUDA内存空间以及物理内存与逻辑内存的对应关系,后续文章写如何通过改善访存策略来提升CUDA Kernel函数的性能。
参考文献:
[1] PROFESSIONAL CUDA C Programming. John Cheng, Max Grossman, Ty McKercher.
[2] CUDA C PROGRAMMING GUIDE
CUDA内存模型
分级模型
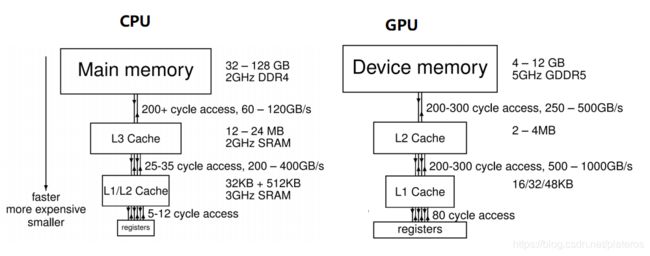
与CPU内存分层架构类似,GPU同样采用分层架构,由大容量高延迟的片外SDRAM和小容量低延迟的片内SRAM组成。数据的存储和写入通过缓存机制提高效率。缓存模型在时间局部性和空间局部性两方面提高系统性能。
- 时间局部性: 如果一个数据项正在被访问,那么近期他还有可能再次被访问。将这个数据放入高速缓存,以便下次更快速的访问。
- 空间局部性: 如果一个数据项正在被访问,那么与之相邻的数据可能近期会被访问。将这些相邻的数据也放入Cache。
与CPU相比,GPU的带宽更高,延迟更大,Cache更少。
CUDA内存模型

上图为CUDA内存模型,包括
- 寄存器(Registers)
- 共享内存(Shared Memory)
- 局部内存(Local Memory)
- 常量内存(Constant Memory)
- 纹理内存(Texture memory)
- 全局内存 Global Memory
他们拥有不同的作用范围,生命周期以及缓存机制。
简言之,
- 一个线程拥有自己私有的寄存器和局部内存(local memory)。
- 一个block内的所有线程可以读写该block专有的共享内存(shared memory)。
- 所有线程可以读写全局内存(Global memory),只读常量内存(constant memory)和纹理内存(texture memory)。
寄存器(Registers)
Registers拥有最快的访问速度。在Kernel函数里定义的变量以及确定长度的数组都可存放在寄存器中。
__global__ void kernelfunc()
{
float variable; // in registers
...寄存器属于线程私有资源,SM为每个active block里的线程都分配了寄存器。不同GPU每个线程的最大寄存器数量不同(Fermi为63, Kepler扩展到255)。上一篇文章提到了SM资源限制对active block数量的影响,线程使用的寄存器越少,SM上active block就越多,使SM硬件资源得到更有效的利用。
传送门: CUDA(2)执行模型
可以通过如下编译选项查看线程的寄存器,共享内存的使用情况
-Xptxas -v,-abi=no
如果使用的寄存器超出了硬件限制,那么多出来的部分就会存放在Local memory里。
CUDA编译器提供了关键字__launch_bound__启发式地限制寄存器的使用,从而提高SM内active block数量。
__global__ void
__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
kernel(...) {
// your kernel body
}heuristics(启发式)一词,多少让人有点摸不到头脑。 说通俗一点,就是我们在代码中直接告诉编译器,该Kernel函数每个Block分配的最大线程数以及SM最小支持的active block数,这样编译器就可以调整每个线程拥有的寄存器数,优化SM中active block的数量了。
- maxThreadPerblock: 参数指定了一个Block内最大线程数。通常情况下,只有在Kernel执行时,才能真正知道Block内的线程数,编译状态下是没法获得的。但是使用__launch_bounds__就可以直接告诉编译器,使用该Kernel函数时,一个Block包含的线程数量,从而让编译器做寄存器分配上的优化。
- minBlockkPerMultiprocessor: 一个SM最少支持的active block数。这个参数不是必需的,编译器会根据不同的GPU架构赋值。
另一种方法限制线程使用的寄存器的数量是采用如下编译参数,
-maxrregcount=32
这种方式看上去比较粗暴,所有CUDA线程的寄存器都被限制在32个,除非某个Kernel函数显示的使用__launch_bounds__。
Local Memory
线程私有。当SM内寄存器使用达到上限,或者无法确定数组大小的时候,数据会存放在局部内存。
float variable[100]; //In Local Memory物理上并不存在单独的Local memory。编译器会将其放入片外的DRAM中(与Global Memory相同),访存延迟大,带宽小。
Shared Memory
共享内存是SM的私有资源,属于on-chip内存,带宽相对较高,延迟也较低。SM将共享内存资源划分给每个active block。上一篇提到了共享资源限制与SM active block之间的关系,使用共享内存越少,active block数量越多。
__shared__ float variable;Block内的线程共享Shared Memory。可以使用__syncthreads()执行同步操作。该函数会阻塞线程,直到block内所有线程都执行到此函数。
Constant Memory
常量内存同样是offchip内存,只读,拥有SM私有的constant cache,因此在cache hit的情况下速度快。常量内存是全局的,对所有Kernel函数可见。因此声明要在Kernel函数外,
__constant__ float variable;Texture Memory
与常量内存类似,纹理内存也是offchip内存,拥有SM私有的cache,在cache hit的情况下访存速度快,对所有线程可见。纹理内存对2D空间存储做了优化,因此如果Warp访问2D/3D数据,会得到更好的性能,但是对于其他线程,性能反而会差。
texture
tex_var; //Initialize
cudaChannelFormatDesc(); //Options
cudaBindTexture2D(...); //Bind
tex2D(tex_var,
x_index,
y_index); //Fetch Global Memory
offchip内存,所有线程可见。使用cudaMalloc分配的内存就属于Global Memory。另外还可以静态分配,
__device__ float devData;值得注意的是,静态声明的devData只是一个符号(Symbol),不能像其他Host内存变量那样使用&devData获取其Device内存指针,因此无法使用cudaMemcpy(&devData...)对其赋值。
cuda runtime API提供了专门的赋值函数。
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));也可以通过cudaGetSymbolAddress先获取他的地址,再使用cudaMemcpy对其赋值。
float *dptr = NULL;
cudaGetSymbolAddress((void**)&dptr, devData);
cudaMemcpy(dptr, &value, sizeof(float), cudaMemcpyHostToDevice);
[1]中,Table4-2总结了这几种内存。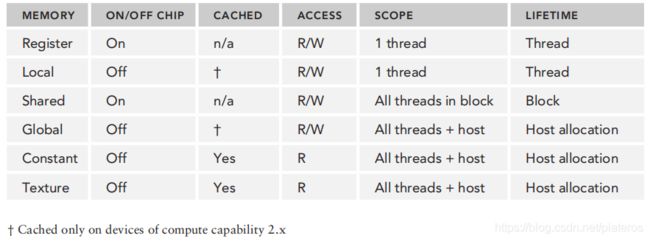
下图表达的更加直观一些。
- Local, Global, Contant, Texture为片外DRAM,其中Global, Constant, texture内存在Host端代码声明,所有线程可见。
- SM拥有私有的Registers和Shared Memory(其实还有SM私有的L1 cache以及共有的L2 cache,下一篇会详细说明),Constant和Texture内存有专有的Caches, 这些在片上。
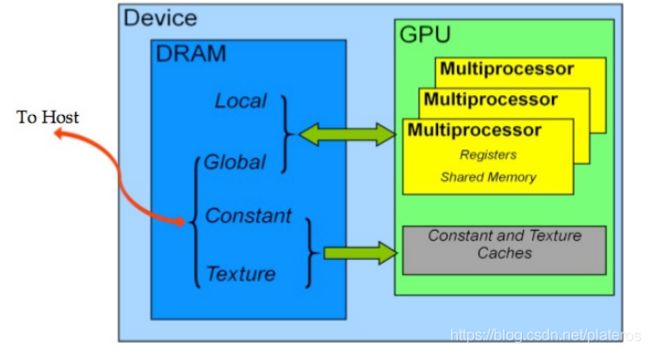
通常来讲,CPU/GPU访存性能瓶颈在访问片外DRAM上,即访问Global, Constant, Local, Texture内存。下一篇会以Global Memory为例,写如何高效的访问DRAM。