论文阅读 新的非视距场景(imaging behind occluders)|| ECCV 2020: Imaging Behind Occluders Using Two-Bounce Light
论文阅读
Henley, C., Maeda, T., Swedish, T., & Raskar, R. (2020, August). Imaging Behind Occluders Using Two-Bounce Light. In European Conference on Computer Vision (pp. 573-588). Springer, Cham.
https://www.media.mit.edu/publications/imaging-behind-occluders-using-two-bounce-light/
目录
Abstract
什么是imaging behind an occluder?
这篇文章做了什么?
Introduction
Related Work
非视距成像
根据阴影恢复形状(Shape from shadows)
Imaging Behind Occluders
基本的测量(The Elementary Measurement)
Method 方法
数据获取
预处理
重建
Reconstructing the Shape of Hidden Objects 重建隐藏物体的形状
实现
静止的隐藏物体 Stationary Hidden Objects
移动的隐藏物体 Moving Hidden Object
克服几何和光度学的挑战 Overcoming Geometric and Photometric Challenges of Imaging Behind Occluders
错误出现的原因 Sources of Error in Imaging Behind Occluders
错误地"雕刻" False Carving (把inside误判为outside)
假阳性 False Positives (把outside误判为inside)
Robust Carving 鲁棒的”雕刻“算法
阈值的更改和添加
基于概率的操作
实现 Implementation
应用 Applications
Conclusion
Abstract
本文引入并解决了一类新的非视距成像问题:障碍物后面的成像 (imaging behind an occluder, behind-an-occluder problem).
什么是imaging behind an occluder?
behind-an-occluder problem是指隐藏物体O侧面有两个相对的可见反射面A, B;
通过照明其中一个反射面A,光在A表面反射后,穿过O的表面,到达B表面。通过相机捕获B表面的光斑作为输入,来重建隐藏物体O.
如下图所示:
 图1
图1
这篇文章做了什么?
- 使用了一个简单的硬件设置采集数据(two-bounce light)——使用eye-safe的激光器作为光源,和现成的(off-the-shelf)RGB / RGB-D相机;
- 分析了该问题存在的光度学和几何学挑战;
- 提出了一个能够在不可控条件下,如表面不平,完成高质量3D重建的方法。
Introduction
研究非视域成像的意义:能够看到被遮挡的物体;
什么是behind-an-occluder problem: 通过照明其中一个反射面A,光在A表面反射后,穿过O的表面,到达B表面,形成光斑。通过分析光斑完成对隐藏场景的3D重建。
本文的贡献:
- 对imaging behind an occluder问题进行了公式化,包括讨论该问题存在的挑战、重建结果的错误原因等;
- 提出了解决该问题的方法,它基于space carving方法并利用了two-bounce光作为测量值。该方法是第一个不需要特定设备(只使用了激光器和现成的相机)就能恢复3D形状的非视距成像算法。
- 重建结果表明,本文提出的方法能够恢复隐藏物体的细节结构,对移动场景能够完成视频重建,同时能够适应非平面、非连续的中继面。
Related Work
非视距成像
首先说了非视距成像要解决的问题是什么;
之后将一遍非视距成像的研究,包括主动非视距成像研究和几个利用光斑、空间相干、强度信息的被动方法;说明了典型的非视距成像算法都是three-bounce反射光成像,但本文(由于本文问题的设置)使用了two-bounce反射光在不需要ToF信息的情况下完成了三维成像。
接下来描述了非视距成像中对遮挡的利用,即通过遮挡约束光线路径,从而利用这些约束信息建立前向传播模型并进行重建。在之前的这些研究中,遮挡物和隐藏物体是分离的两个东西,通过利用遮挡物来恢复隐藏物。但在本文的研究中,者当物体和隐藏物体是同一个物体。
最后推荐了关于非视距成像的综述文章:
T. Maeda, G. Satat, T. Swedish, L. Sinha, and R. Raskar, “Recent advances in imaging around corners,” arXiv preprint arXiv:1910.05613, 2019.
根据阴影恢复形状(Shape from shadows)
首先说明了本文和过去的根据阴影恢复形状的研究的区别:常见的根据阴影恢复形状的研究:通过不同位置的光源在平面上形成一系列阴影来恢复物体形状,且光源必须在物体的视域内(与非视域成像相区分);本文的形状恢复:不一定要是平面,也可以不平或者反照率不同;物体是被隐藏的。
之后介绍了根据阴影恢复形状的已有研究:这类研究通常都将一个平面阴影看作是从光源角度得到的目标物体的一个二维剪影;好几个研究完成了从一系列二维剪影中恢复3D形状的任务(shape-from-silhouettes (SfS)), 其中引入了空间雕刻算法(space carving approach).
最后说明本文修改了空间雕刻算法使其对平面上的表面误差等鲁棒,同时适用于非视距成像。
Imaging Behind Occluders
问题总述:如下图所示,观察者(detector所在)的视野被遮挡物挡住了很大一部分,而本文想要解决的就是:被挡住的部分中的任意一点x到底有没有东西。这样就能恢复出隐藏的三维物体。
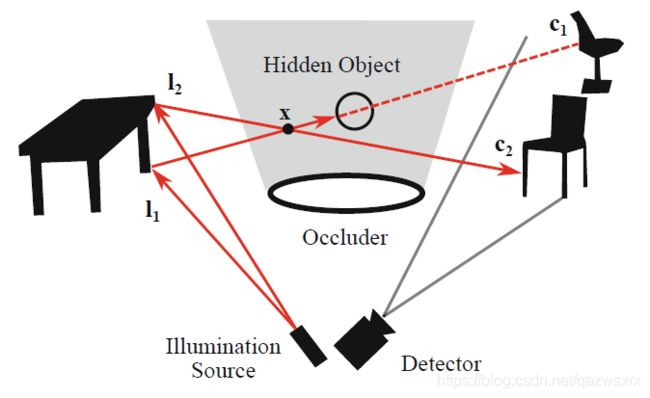 图2
图2
基本的测量(The Elementary Measurement)
对于想要知道的点x,给定照明点l1,就能得到测量点c1.
在图中所示的情况下,c1处的测量值是一个阴影(因为光路中存在不透明隐藏物体),从而推断出路线l1c1上必有隐藏物体,但隐藏物体的位置还不能确定。也就是说并不能确定点x处有隐藏物体。
于是进行第二次测量,即给定另一个照明点,从而得到新的测量点l2.
在图中所示的情况下,c2处不再是阴影而是会被照亮。这就说明包括x在内的l2-c2整条光路上都没有隐藏物体。
上述就是一个基本的测量,即本文提出的方法所基于的主要原则。
通过将隐藏空间离散化为多个离散点 ,即可将问题转换为隐藏空间的重建问题。在实际采集的过程中,本文并没有逐个去采集(l,c)。而是逐个扫描l, 然后对每一个l,都使用相机去一次性地捕获整个区域内所有的c。
,即可将问题转换为隐藏空间的重建问题。在实际采集的过程中,本文并没有逐个去采集(l,c)。而是逐个扫描l, 然后对每一个l,都使用相机去一次性地捕获整个区域内所有的c。
Method 方法
本文的方法可以大致分为3步,即:
- 数据获取;
- 预处理;
- 重建.
数据获取
使用扫描振镜控制激光完成扫描,同时在每个激光点拍摄两幅照片:
- 一幅面向激光点所在平面的短曝光照片,用于记录激光点的位置;
- 一幅面向观测平面的长曝光照片,用于高对比度地拍摄观测平面。
预处理
遍历拍摄地每一个扫描点的两张图片:
对于每一幅短曝光图片,将其上的激光点坐标转换为三维空间的坐标。如果用的是RGB-D相机,就依赖于可见平面几何形状的先验知识来进行估计;如果无法获取几何形状,就直接通过RGB-D相机来获取三维位置。捕获装置如图3(a)
对于每一幅长曝光图片,首先选择包含隐藏物体阴影的感兴趣区域,之后对该区域内的每一个像素点分类,判定其是被遮挡的、被照亮的 还是 无法判断的。判断的标准依赖于具体的场景,可以很简单比如仅仅设置一个阈值。也可以更加复杂。一个分割案例如图3(b)和(c)所示。
重建
首先将隐藏空间离散化为很多voxel,并对每一个激光点l,都做以l为投影中心,隐藏空间上每一点x在阴影平面的投影;之后判断隐藏空间的每一点x是outside还是inside。其中:
- inside的含义是经过点x的投影落在了阴影区域;
- outside的含义是经过该点的投影落在了照明区域(即阴影区域之外)。
在此过程中,文章对每一个voxel被判断为inside/ outside的次数进行计数。计数结果可以被用来判断每个voxel x是有隐藏物体的还是没有隐藏物体的。
在后面的section 4中,文章使用了非常朴素的判断方法,即对outside计数大于等于1的voxel,都判断成无隐藏物体;
在section 5和6中,则使用了概率阈值从而对分类中的错误更加鲁棒。一个重建结果如图3(d)所示。
 图3
图3
Reconstructing the Shape of Hidden Objects 重建隐藏物体的形状
本节内容:
- 说明本文的方法能够恢复静止的隐藏场景的细节特征;
- 说明本文如何完成运动隐藏场景的重建;
本节的实验场景包括两个白色的中继面和黑色的遮挡墙。这种场景能够避免预处理时的错误。后面的章节会对有错误的情况进行说明。
实现
实验场景如图1(a), 观测墙面大小为61cm×76cm;
使用二维扫描振镜进行扫描;相机:Point Grey Blackfly RGB camera.
- 首先将拍摄的图片进行二值化,其中阈值设置方法为手动设置 或者 通过Otsu算法自适应设置;
- 接下来通过双边滤波器进行去噪;此步骤能够时像素分类更加robust.
- 之后使用另一个阈值将滤波后的图片的像素划分为阴影 和 照明 两个部分。
在上述过程中,文章假设观察者是知道两面墙的形状的,即可见平面几何形状属于先验知识,这样就可以得到laser spot的位置并且转换为三维空间的坐标;同理,观察面上的点的坐标也可以转换为三维空间坐标。从而判断每一个体素x是inside还是outside;
对于所有outside判定次数不少于1次的,均认为是对应重建位置没有物体的体素。Inside的分类结果并没有使用。
静止的隐藏物体 Stationary Hidden Objects
图1和图4给出了几个静态物体的结果。可见:
- 细节能够得到恢复;
- 恢复结果足够进行后续操作,如姿态估计等;
- 镜面表面(图1的三个disc球)并没有对该算法的成像产生影响。
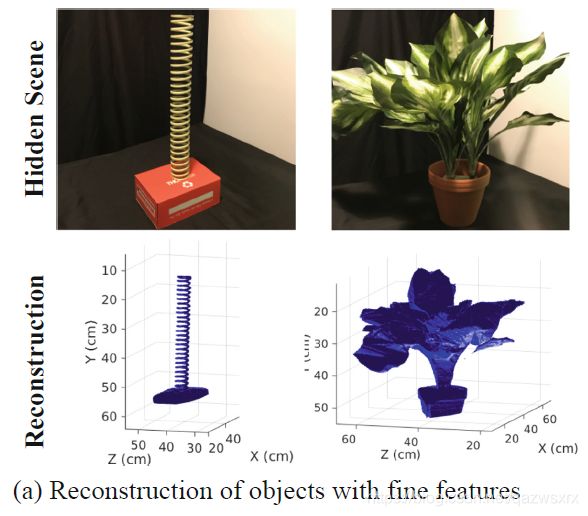 图4
图4
对每一个物体,本文都扫描了9*11个laser points; 扫描点均匀分布且几乎覆盖了整个中继平面。对每个物体的数据获取时间约27s, 隐藏空间离散化的间隔为0.25cm;
移动的隐藏物体 Moving Hidden Object
通过降低扫描的点数,就可以获得对动态隐藏场景的观察视频。
从视频中,还是可以恢复隐藏物体的大概尺寸、形状和移动的位置。这只需要视频的每帧包含4个观察到的阴影图片。
注:这句话没看懂,为什么一帧可以包含4个观察到的阴影?原话是:
By reducing the number of scan points per reconstruction, we can capture videos of dynamic hidden scenes. Although these videos do not capture fine detail, we are able to recover the approximate size, shape, and position of a moving object using only four observed shadows per video frame.
重建的视频在附录中有,其不同时刻的截图如图5,不同颜色代表了不同时刻
 图5
图5
gt是一个人偶在以很慢的速度移动,本文每秒获得了15个阴影图片,因此结合前面的一帧可以包含4个观察到的阴影,故一帧只需要采集0.27s。空间雕刻则是在55cm*45cm*55cm的隐藏点上完成的,点的彼此间隔为1cm。
克服几何和光度学的挑战 Overcoming Geometric and Photometric Challenges of Imaging Behind Occluders
上述流程和算法在实际应用时会遇到问题:可见平面估计和阴影分割总是存在误差,从而导致最终inside和outside判断错误。
本节将会讨论:
- 当使用前面的简单算法时,这些问题是如何出现的?
- 如何使用一个基于概率的雕刻方法来避免这些错误(robust to pre-processing errors)?
- 将改进后的方法用于不平的中继面(不平意味着深度测量存在误差),并说明其好于前一节所述的未改进的方法。
错误出现的原因 Sources of Error in Imaging Behind Occluders
错误地"雕刻" False Carving (把inside误判为outside)
几何学原因:在之前的朴素方法中,只要有1个经过体素x的投影被判定为”光照“,该体素x就会被判定为outside,从而不在最终的重建中出现。但在实际操作上,如果没能准确估计激光点和观察到的像素的3D位置,那么它们之间的连线就会不准确,从而l-x就会对应错误的观测像素,故x就会被错误地判定为inside/ outside, 进而出现误差。
光度学原因:复杂的光传输现象,如内部反射,镜面反射,透明的隐藏物体和折射也能导致错误地curving。这是因为这些复杂的现象都不能用前面的two-bounce模型解释,自然也不适用于之前的理论,如图6所示。
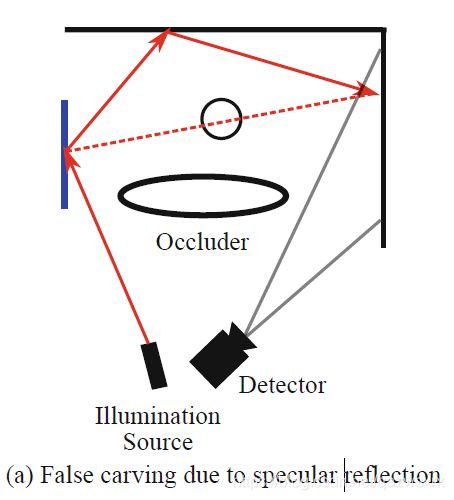 图6
图6
假阳性 False Positives (把outside误判为inside)
除了上述把inside判为outside的情况外,还有把outside误判为inside的情况。
在有些情况下,这种错误是不可避免的,如该outside voxel恰好位于场景的visual hull上。注:关于visual hull的定义参考
Laurentini, A.: How far 3D shapes can be understood from 2D silhouettes. IEEE Trans. Pattern Anal. Mach. Intell. 3(2), 188–195 (1995)
还有一些情况,把outside误判为inside和把inside判为outside的原因相同,即几何学原因导致三维坐标估计错误。这种原因下把inside判为outside的情况更多,因为每个体素都会对应很多次投影(射线),而只要有一个投影是光照就会被判为outside。
自然地,当投影射线的个数变少时,把outside误判为inside的情况就会随之增加。当可见表面变得复杂时,很多可见表面都会被表面自身遮挡而变得不可见,从而导致坐标估计更容易出错,进而此类错误就会更加严重。
这种自身遮挡会导致可利用的可见面上的点变少,从而出现重建结果大面积的失真。图7给出了一种相应的情况。
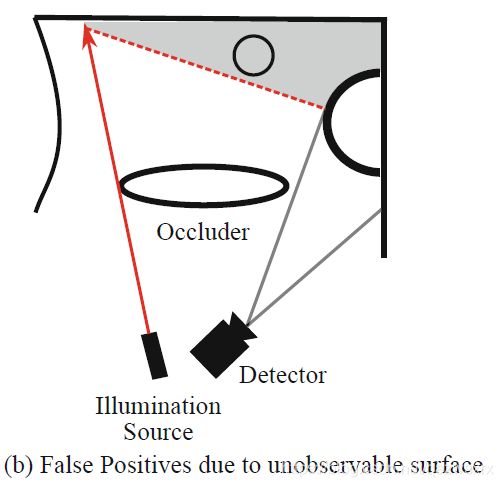 图7
图7
Robust Carving 鲁棒的”雕刻“算法
阈值的更改和添加
对于把inside误判为outside的问题:显然可以通过增加阈值,即需要不止1次光照才能判为outside来实现。当然,这会导致False Positives (把outside误判为inside)问题的增加。
这种权衡的平衡点是,阈值应一直减小,直到当阈值再减小时,就会导致把inside误判为outside的增加。
此时,为了减少False Positives (把outside误判为inside)问题,本节增加了一个新的标准,也就是一个体素x要被判做inside,不仅要满足未被判做outside(即原标准),还要满足它有N>0次被判为阴影的投影射线。
这种操作对于前面所述的由于自遮挡而导致的False Positives (把outside误判为inside)问题也有好处。
基于概率的操作
下面将上面参考的两种决策阈值转换为概率模型:
如果一个体素有N次测试,第i次对应的结果yi与其他N-1个结果相互独立,记empty为e, occupied(也就是有隐藏物体)为o, 则在已知N次测试结果的条件下,某个体素v被占用的概率为
![]()
其中,η是把被占用的体素投影为光照区域的概率(对应把inside误判为outside),ξ则是将空着的体素投影为为阴影区域的概率(对应把outside误判为inside),po = P(vi = o)和pe = P(vi = e)则是先验概率。等式1的推导见补充材料。
这样,文章就根据上式计算出概率,再将该概率和一个特定的阈值相比较,以判定体素vi是inside还是outside.
文章通过调参的方法确定了上述的参数η,ξ,po和pe:
降低η意味着降低把outside误判为inside的概率,但提高把inside误判为outside概率;刚开始的朴素方法对应着η=0;
降低ξ则能降低把inside误判为outside概率。
在实际实验中,当进行次数很多时,先验概率的选择对最终的结果影响很小。
实现 Implementation
为了验证上述基于概率的方法的鲁棒性,文章选择了一个新的实验场景,该场景的中继面时不平且不连续的,它由多个白色小块组成。(如图8(a)所示).
之后,通过RealSense D435 RGB-D相机获得激光点的位置和可见平面的形状;
接下来,现在有隐藏场景的情况下采集了一组数据;又把隐藏场景拿开采集了一组背景数据以作校正。事实上,即便没有背景数据也可以做到较好的效果。
相同数据下,使用不同的雕刻(space carving)阈值方法的结果如图8(b)(c)所示·。可见,提出的概率方法很有效。
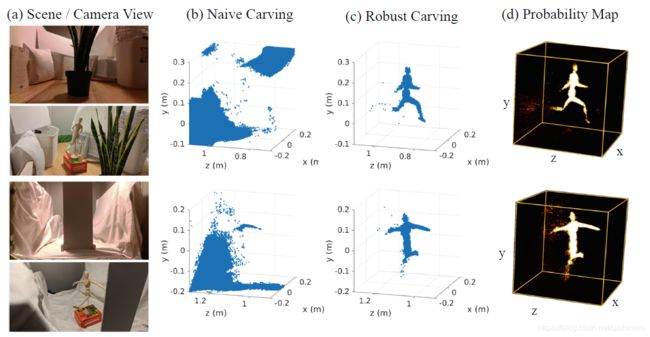 图8
图8
应用 Applications
本节介绍了两种可能的应用,如图9所示。
 图9
图9
分别为:
图9(a) 让自动驾驶汽车看到被遮挡的卡车;
图9(b) 通过看到窗户中间被墙挡到的部分来帮助搜救。
Conclusion
文章首先提出并描述了image behind occluders这个问题;之后使用了一种相当朴素的方法解决了理想条件下的该问题。最后,又修改了算法,使其在有错误的条件下和非平面、不连续的中继面下也能取得较好的效果。
文章是第一个使用简单设备就能恢复隐藏场景3D形状的非视距研究;也是第一个在实时环境和有意义的设置下完成实现的研究。
文章可能会促进医学内窥镜(medical endoscopes)的研究、使无人机能够看到被障碍物,如树,遮挡的物体;提高自动驾驶安全性;搜救房屋内被困人员等领域的进展。
文章还建立了非视距成像 和 从轮廓中成像 之间的联系;
未来工作:摆脱实验室环境,到更加自然的有环境光的环境中去。除此之外,关于中继面几何形状对重建的影响也值得研究。最后,当深度未知/ 隐藏物体透明时如何成像也值得研究。
==================================================================================================================
原载于 我的博客
如有错误,可联系 [email protected]
=================================================================================================================