C++ 入门学习笔记
目录
-
- 核心部分
-
- 怎么记忆底层顶层 const
- 调用拷贝构造函数的时机
- 构造函数的调用(生成?)规则
- 浅拷贝问题
- 全局变量
- 全局函数
- static 和 const
-
- static
- const
- C++ 对象模型
- this 指针
- const 修饰成员函数
- 友元的三种实现
- 一般不用成员函数重载<<而是用友元全局函数重载<<的原因
- 递增运算符重载
-
- 占位参数可以用来区分重载运算符的前置或者后置
- 前置和后置返回值的不同
- 默认赋值运算符也有浅拷贝问题
- 利用VS的开发人员命令提示工具查看对象模型
- 重载括号运算符
- 访问类的同名成员
- private 继承
- 菱形继承
- 虚继承的原理
- 虚继承的要求
- 多继承中的 public private 继承的问题
- 虚继承的所有基类的构造函数都在最终派生类的构造函数中被调用
- 构造函数的列表初始化
- 不能 在派生类构造函数初始化列表中初始化 父类的成员
- 编译器只在一定需要默认构造函数时,才会创建默认构造函数
- 多态
- 动态多态的原理
- 虚析构和纯虚析构
- 进阶部分
-
- 函数模板
-
- 普通函数与函数模板的区别
- 普通函数与函数模板的调用规则
- 模板的局限性
- 解决函数模板局限性的方法:具体化的函数模板
- 类模板
-
- 类模板与函数模板的区别
- 类模板中的成员函数只在代码中有引用时,编译器才将其实例化
- 类模板对象做函数参数
- 类模板与继承
- 类模板成员函数类外实现
- 类模板分文件编写的问题
- 使用类模板的友元函数
- STL
-
- 容器、算法、迭代器
- STL 常用容器
-
- string
- vector
-
- 使用 swap 收缩 vector 的内存
- 用 reserve 为 vector预留空间
- deque
-
- deque 的内部工作原理
- stack
- queue
- list
- set/multiset
- map/multimap
- STL 函数对象
-
- 函数对象
- 谓词
- 内建函数对象
- STL 常用算法
-
- 常用遍历算法
-
- for_each
- transform
- 常用查找算法
-
- find
- find_if
- adjacent_find
- binary_search
- count
- count_if
- 常用的排序算法
-
- sort
- random_shuffle
- merge
- reverse
- 常用的拷贝和替换算法
-
- copy
- replace
- replace_if
- swap
- 常用算数生成算法
-
- accumulate
- fill
- 常用集合算法
-
- set_intersection
- set_union
- set_difference
- C++11
-
- 列表初始化
- 变量类型推导
- final 与 override
- 默认成员函数控制 =default =delete
- 左值引用与右值引用
- 右值引用与移动语义
-
- 编译器自动优化拷贝构造相关
- 移动构造与移动赋值
- 万能引用与完美转发
-
- 万能引用
- 右值传参时退化为左值原因
- 完美转发
- lambda 表达式
- 可变参数模板
整理一遍的起因是,我觉得我虽然懂一点,但是不多……
快速看了一遍别人的笔记,不想看黑马的视频,有点浪费时间
https://blog.csdn.net/qq_51604330/article/details/119688133
大部分是复制粘贴的,就记一些我不懂的
核心部分
怎么记忆底层顶层 const
底层 const 是 不能通过指针来修改指针指向的内容
例如:const int* 或 int const*
一般别人说的什么“指向的内容是 const”从某种意义上来说是对的,但是这就很容易理解错,可能被理解为“指向的是 const int”或者“指向 int 之后这个 int 就变成了 int const”一样
(不知道别人看到这句话会不会有这种理解,反正我是这样hhh)
顶层 const 是 指针指向的地址不能更改
例如:int* const
int a = 1, b = 2;
int const* p = &a;
p = &b; // valid
*p = 1; // invalid
a = 3; // of course valid
const int* p2 = &a;
p2 = &b; // valid
*p2 = 1; // invalid
int* const p3 = &a;
p3 = &b; // invalid
*p3 = 1; // valid
之后看到别人的例子中有一个奇怪的例子,const int *const *const * 我就不知道怎么看了
const int a = 1;
//int * pi = &a; //错误,&a是底层const,不能赋值给非底层const
const int * pi = &a; //正确,&a是底层const,可以赋值给底层const
const int *const *const ppi = &pi //即是底层const,也是顶层const
const int *const *const *pppi = &ppi; //底层const
所以我觉得还是需要一个根本的判断,判断变量名之间的类型修饰符到底是怎么判断的
于是我搜到了
https://www.geeksforgeeks.org/difference-between-const-int-const-int-const-and-int-const/
我觉得他那个从右到左的看法很好……
const int
const <- int
整型常数
const int *
const <- int <- *
(const int) <- *
这其实就相当于 pointer of (const int) 也就是指向整型常数的指针,也就是底层 const
int * const
int <- * <- const
(int *) <- const
constant of (pointer of int) 也就是 不变的整型指针
那再看这个奇葩的例子
const int *const *const *
pointer of (const pointer of (const pointer of (int const)))
等价于 pointer of (const X)
其实也就是一个底层指针
这就很容易理解了
调用拷贝构造函数的时机
在函数返回作为局部变量的对象的时候会调用拷贝构造函数
这里与我之前的一些直觉是有一些联系
我以前记得的是不能返回局部变量的引用嘛
但是其实这是是返回局部变量的值嘛
不冲突,但是只是联想到这一点
构造函数的调用(生成?)规则
默认情况下,C++编译器至少给一个类添加三个函数
-
默认构造函数(无参、函数体为空)
-
默认析构函数(无参、函数体为空)
-
默认拷贝函数构造函数,对属性值拷贝
构造函数调用规则如下:
-
如果用户定义有参构造函数,C++不再提供默认无参构造,但是会提供默认拷贝构造
-
如果用户定义拷贝构造函数,C++不会再提供其他构造函数
记在这里只是感觉……似乎就是单纯记忆的?
当然其实我之后遇到了一些问题,就是,如果不写任何函数,类也没有生成默认构造函数的
所以这个规则只是一个粗浅的惯例,并不是一定发生的定理
浅拷贝问题
浅拷贝问题:编译器提供的默认拷贝构造函数,对所有成员都是值拷贝,那么如果某一个对象有一个指针成员,指针指向的地址在堆上分配,那么调用默认的拷贝构造函数之后,拷贝得到的对象与源对象各自的指针成员指向的是同一个堆上的地址。在对象释放的时候,调用析构函数,析构函数中释放掉指针成员指向的地址,那么两个对象释放的时候,就对同一个堆上的地址释放了两次,这样就会导致错误
解决的方法——深拷贝:如果对象有指针成员指向的是堆上的地址,那么需要自定义拷贝构造函数,在自定义的拷贝构造函数中对新对象的指针成员分配堆上的内存,然后再拷贝指针指向的值
全局变量
https://blog.csdn.net/u013250861/article/details/127563427
这样当我们编译某个单元时, 编译器发现了使用 extern 修饰的变量:
-
如果正好本模块中有其相关定义, 那么就直接使用;
-
如果本模块中没有相关定义, 那么就挂起, 在编译后续其他模块的时候进行查找,
-
如果到最后还没有找到, 那么在链接阶段就会报错,例如:无法解析的外部符号
嗯,我还是第一次直到是挂起来查找这样子
正确用例:
在 test1.h 中声明 extern int a;
在 test1.cpp 中定义 int a = 10; (或者使用 int a; 定义, 这样的话值是默认值 0)
在 test2.cpp 中 #include "test1.h", 这样便可以在 test2.cpp 中直接使用 a 变量了.
其中,test1.cpp 中不管是否 include “test1.h”,都可以完成对 test1.h 中的 extern int a 的定义
错误用例 1:
在 test1.h 中声明 int a; 不赋值的全局变量也算定义,因为分配了内存
在 test1.cpp 中定义 int a = 10; 此文件报错:a 重定义
具体可见 https://www.cnblogs.com/zhuluqing/p/8761293.html
错误用例 2:
在 test1.h 中声明 extern int a = 1;
在这种情况下如果有多个 implementation file 都 #include "test1.h"
那么会造成在 obj 文件的 链接 阶段发现多处存在同一个变量的定义,报错
错误用例 3:
在头文件 test1.h 中 直接 extern int a = 10;
在 test2.cpp 中直接使用 extern int a;(没有 #include test1.h)
这样做可以避免多处重复定义的问题
但是这样的话 test1.h 定义的其他变量与方法都不可以使用了
(因为为了避免多个对头文件的引用,而干脆哪个源文件都不引用这个包含变量定义的头文件)
那么各个源文件必须全部使用 extern XXX 的形式进行声明然后使用, 这样会得不偿失.
全局函数
函数与变量类似, 也分为定义与声明. 但是与变量在声明时必须要包含 extern 不同, 由于函数的定义和声明是有区别的:
-
定义函数要有函数体;
-
声明函数没有函数体;
所以函数定义和声明时都可以将 extern 省略掉, 反正其他文件也是知道这个函数是在其他地方定义的, 所以不加 extern 也行.
所以在 cpp 中, 如果在一个函数前添加了 extern, 那么仅表示此函数可能在别的模块中定义; 或者也可以让我们在只使用了某个头文件的这个方法时不用 #include
static 和 const
static
https://blog.csdn.net/u013250861/article/details/127563427
当 static 用于修饰类中的变量/函数,表明该变量/函数是一个静态成员变量/函数:
-
类加载的时候会分配内存
-
可以通过类名直接访问
-
注意 静态成员变量类内声明,类外初始化
这里有一个神奇的地方就是,如果 static 类内成员是 private 的,虽然因为 private 所以无法在类外访问,但仍然要在类外初始化
当 static 用于修饰类之外的变量/函数,表明该变量/函数是一个普通的全局静态成员变量/函数:
-
用于修饰变量时表示其存储在全局(静态)区, 不存储在栈上面;
-
只对本编译模块有效(即使在外部使用 extern 声明也不可以), 不是真正意义的全局(普通的函数默认是 extern 的)
(我觉得这一条对于类内 static 成员也是一样吧,只对本编译模块有效)
-
声明与定义时同时发生的
-
当局部变量不想在函数结束时被释放的时候可以使用 static, 比如函数中要返回一个数组, 不想让这个数组函数结束时被释放, 那么可以使用 static 修饰此局部变量
static 使变量/函数只在本编译模块内部可见, 这样的话如果两个编译模块各自都有一个 value 变量/函数的话, 那么千万不要将两个编译模块内 static 修饰的变量/函数认为是同一份内存, 他们实际上是两份内存, 修改其中一个不会影响另外一个
这个所谓的编译模块就是一个 cpp 和它所包含的头文件
所以如果两个 cpp 中有相同名字的类外 static 变量/函数,它们之间没有包含关系,那么它们即使是相同名字,也能通过编译,并且它们不是同一内存
const
当 const 单独使用时它就与 static 相同, 而当与 extern 一起合作的时候, 它的特性就跟 extern 的一样了。
C++ 对象模型
成员变量和成员函数分开存储
在C++中,类内的成员变量和成员函数分开存储,
只有非静态成员变量才属于类的对象上。
(只有非静态成员变量的大小算进类的大小中,其他的都不算。)
空对象的大小是1,为的是区分不同类在内存中的占用位置。
this 指针
因为成员函数在内存中是唯一的,所以才需要一个this来表示是哪个对象调用的这个成员函数
this指针的本质是指针常量,指针的指向是不可以修改的
空指针是可以调用成员函数的,也就是说 this 可能为空,所以在成员函数使用 this 之前要判断 this 是否为空
const 修饰成员函数
常函数:
-
成员函数后加const后我们称这个函数为常函数
-
常函数不可以修改成员属性
-
成员属性声明时加关键字mutable后,在常函数中依然可以修改
常对象:
-
声明对象前const称该对象为常对象。
-
常对象只能调用常函数。
友元的三种实现
-
全局函数做友元
-
类做友元
-
成员函数做友元
一般不用成员函数重载<<而是用友元全局函数重载<<的原因
#include
//一般我们不会利用成员函数来重载<<运算符,以为无法实现cout在左边
/*void operator<<(ostream &cout,Person &p)
{
cout << p.m_A << endl;
cout << p.m_B << endl;
}*/
private:
int m_A;
int m_B;
};
//只能利用全局函数来重载左移运算符
ostream& operator<<(ostream &cout, Person &p) //这样写的本质就是operator<<(cout,p)简化版本就是cout<
{
cout << p.m_A << endl;
cout << p.m_B << endl;
return cout;
}
void test()
{
Person p(10,10);
cout << p << "hello world" << endl;
}
int main(void)
{
test();
system("pause");
return 0;
}
递增运算符重载
占位参数可以用来区分重载运算符的前置或者后置
前置和后置返回值的不同
前置可以返回引用,这样就方便连续前置自增
于是我们希望后置也能返回引用,如果能这样是最好的
但是后置自增需要执行完自增之后,返回的东西(假设可以选择返回值或返回引用)代表的是自增之前的值,而因为变量地址所代表的值是已经自增了,所以如果返回*this的话,值是不对的,而你也不能返回局部变量的引用,所以就只能返回值了
#include默认赋值运算符也有浅拷贝问题
默认拷贝构造函数有浅拷贝问题
默认赋值运算符也有浅拷贝问题,也需要人工写深拷贝的重载的赋值运算符来解决
利用VS的开发人员命令提示工具查看对象模型
打开 Developer Command Prompt for VS 2019
cd 到 cpp 文件所在的目录
cl /d1 reportSingleClassLayout类名 文件名
emmm不知道为什么我尝试了之后会显示一些不该出现的错误……
重载括号运算符
//打印输出类
class MyPrint
{
public:
//重载函数调用运算符
void operator()(std::string test)
{
std::cout << test << std::endl;
}
};
void MyPrint02(std::string test)
{
std::cout << test << std::endl;
}
void test01()
{
MyPrint myPrint;
myPrint("hello word");//调用 () 运算符,很像下面的函数调用
//由于使用起来非常类似于函数调用,因此称为仿函数
MyPrint02("xyq");//函数调用
}
//仿函数非常灵活,没有固定的写法
//加法类
class MyAdd
{
public:
int operator()(int num1, int num2)
{
return num1 + num2;
}
};
void test02()
{
MyAdd myAdd;
int ret = myAdd(10, 10); //调用 () 运算符
std::cout << ret << myAdd(10, 10) << std::endl;
//匿名函数对象
//因为重载了小括号称为匿名函数对象
std::cout << MyAdd()(100, 100) << std::endl;
// MyAdd()会创建出来一个匿名对象,通过类名加小括号会创建出来一个匿名对象
//匿名函数对象有一个特点当前行执行完了立即被释放
//匿名对象在构造函数分类及调用时讲过
}
访问类的同名成员
访问子类同名成员,直接访问即可
访问父类同名成员,需要加作用域
private 继承
https://www.bogotobogo.com/cplusplus/private_inheritance.php#:~:text=Private%20Inheritance%20is%20one%20of,interface%20of%20the%20derived%20object
public 继承是 is a private 继承是 has a
意思是,private 继承的派生类对象无法用基类指针指向,也就是无法转换到基类
因为是 private 继承,所以它能在内部用基类的 public 和 protected 的方法,但是不能暴露给外界
综合这两点,他就像是,有这个东西,但是我又不是这个东西
菱形继承
菱形继承:子类继承两份相同的数据,导致资源浪费以及毫无意义。
例如 base 为基类,child1 类和 child2 类都继承 base 类,child3 类继承 child1 和 child2 类
那么如果 base 类中有成员 int num
解决方法:菱形中间的类对基类的继承改为虚继承
虚继承的原理
我们已知菱形继承的解决方法是虚继承
而细究虚继承这件事,他是用一个隐含在类中的虚基类指针实现的
使用了虚继承的类,继承使用了虚继承的类的类,都有自己的独一无二的虚基类指针
这个虚基类指针指向一个虚基类表
而虚基表中会存在偏移量,这个量就是表的地址到父类数据地址的距离。
我是想模仿这个文章的
https://blog.csdn.net/weixin_61857742/article/details/127344922
然后我才知道 vs 中可以添加监视
就是,在局部变量窗口中给出的就确实只是局部变量而已,但是在监视窗口,可以输入变量名,也可以输出 &变量名,查看到这个变量名的地址,就很方便
然后通过监视找到变量的地址之后,就可以打开内存窗口,输出变量的地址,就能看到变量所在内存是什么样的,就很强
#include监视:
+ &d 0x0053fad4 {d=4 } D *
+ &d.a 0x0053fae8 {1} int *
+ &d.b 0x0053fad8 {2} int *
+ &d.c 0x0053fae0 {3} int *
+ &d.d 0x0053fae4 {4} int *
内存:地址 0x0053FAD4
0x0053FAD4 40 9b ba 00 @??.
0x0053FAD8 02 00 00 00 ....
0x0053FADC 48 9b ba 00 H??.
0x0053FAE0 03 00 00 00 ....
0x0053FAE4 04 00 00 00 ....
0x0053FAE8 01 00 00 00 ....
其中,01 02 03 04 就是各个 int 值了,那么其他的内容就是虚基类指针了
然后,我们就知道了这个虚基类指针的大小跟 int 一样,是四个字节
然后,我们也是知道这里是小端存储
然后我们去查找这个虚基类指针指向的地址,可以发现他是八个字节,对应 64 位虚存空间的 64 位地址
0x00BA9B40 00 00 00 00 ....
0x00BA9B44 14 00 00 00 ....
0x00BA9B48 00 00 00 00 ....
0x00BA9B4C 0c 00 00 00 ....
一个指针指向的内容是 0x14,另一个指向的内容是 0x0c
也就是 0x0053FAD4 这行加上偏移量 0x14 得 0x0053FAE8,0x0053FADC 加上偏移量 0x0c 得 0x00BA9B4C,都是指向 int a
虚继承的要求
虚继承是用来确保虚继承的基类只存在一个
所以菱形继承时需要确保那个要求唯一存在的基类确实被中间类用 virtual 修饰了
https://blog.csdn.net/weixin_61857742/article/details/127344922
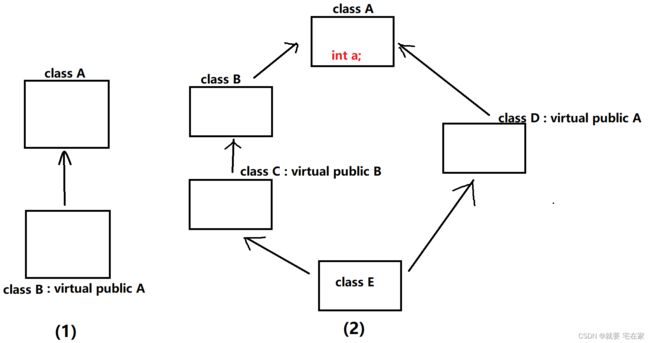
上面两种情况都不符合要求
多继承中的 public private 继承的问题
这么写是没有问题的
#include这么写是没有问题的
#include这么写就有问题了:
#include错误信息:
错误 C2280 “D::D(void)”: 尝试引用已删除的函数
输出信息:
warning C4594: 决不可实例化类“D” - 不可访问间接虚拟基类“A”
warning C4624: “D”: 已将析构函数隐式定义为“已删除”
error C2280: “D::D(void)”: 尝试引用已删除的函数
所以就很迷惑,它的意思就是 D 中没有默认无参构造函数了,但是为什么菱形继承的时候,不用虚继承就没有这个问题,用虚继承就会有这个问题?
之后我用 g++ 编译就没有问题了,所以我觉得这是编译器对 cpp 标准的实现的问题
g++ -o Test Test.cpp
然后我如果自己声明一个构造函数就会有不可访问的问题,说明这里是
class D : B, C {
int d = 4;
D() : B(), C() {}
};
但是这个时候 A B C 都是有自己的默认构造函数的呀,难道是
错误信息:
错误(活动) E0330 "D::D()" (已声明 所在行数:14) 不可访问
错误 C2248 “D::D”: 无法访问 private 成员(在“D”类中声明)
这时,B 和 C 类对 A 类的 virtual 继承加不加 public 都是这个错误
如果添加 public 构造函数和析构函数,那么就会正常
public:
D() : B(), C() {}
~D(){}
};
但是必须是添加构造和析构,不能只添加构造函数
就很奇怪
而如果不在 D 里面自定义构造函数,让虚继承用 public 限定,也能正常运行
#include也就是这个时候也能有默认无参构造函数
于是我搜了一下,看到一个东西,虽然这也没有解决我的问题
虚继承的所有基类的构造函数都在最终派生类的构造函数中被调用
https://stackoverflow.com/questions/24543584/diamond-inheritance-twice-derived-constructor-params-different-base-cannot-b
这里面提到了,一个非虚类如果有虚继承的基类,这么它虚继承的所有基类的构造函数都要在这个最终子类的构造函数中调用,也就是 derivatived class constructor 调用 virtual base 1 constructor,derivatived class constructor 调用 virtual base 2 constructor,而不是像我们习惯的普通的继承那样,derivatived class constructor 调用 base 2 constructor,base 2 constructor 调用 base 1 constructor
那么这就要求了这个最终子类的构造函数要接受更多的参数,才能提供给所有的虚继承类的构造函数
如果虚继承类的构造函数是无参的,那么会更省事
What special considerations do I need to know about when I inherit from a class that uses virtual inheritance?
Initialization list of most-derived-class’s ctor directly invokes the virtual base class’s ctor.
Because a virtual base class subobject occurs only once in an instance, there are special rules to make sure the virtual base class’s constructor and destructor get called exactly once per instance. The C++ rules say that virtual base classes are constructed before all non-virtual base classes. The thing you as a programmer need to know is this: constructors for virtual base classes anywhere in your class’s inheritance hierarchy are called by the “most derived” class’s constructor.
Practically speaking, this means that when you create a concrete class that has a virtual base class, you must be prepared to pass whatever parameters are required to call the virtual base class’s constructor. And, of course, if there are several virtual base classes anywhere in your classes ancestry, you must be prepared to call all their constructors. This might mean that the most-derived class’s constructor needs more parameters than you might otherwise think.
However, if the author of the virtual base class followed the guideline in the previous FAQ, then the virtual base class’s constructor probably takes no parameters since it doesn’t have any data to initialize. This means (fortunately!) the authors of the concrete classes that inherit eventually from the virtual base class do not need to worry about taking extra parameters to pass to the virtual base class’s ctor.
来源:https://isocpp.org/wiki/faq/multiple-inheritance#virtual-inheritance-ctors
举例:
#include 输出:
grandmother (default)
mother: 0
daughter: 0
daughter 的构造函数中,显式调用了 mother 的构造函数,但是 grandmother 是虚继承的,所以 daughter 构造时虽然调用了 mother 的构造函数,但是 mother 的构造函数并没有调用 grandmother(int attr) 构造函数,而是由 daughter 的构造函数来调用 grandmother 的构造函数;又因为 daughter 的构造函数中没有显式调用 grandmother 的构造函数,所以编译器就认为是调用了无参的构造函数
所以要 daughter 的构造函数能够调用 mother 和 grandmother 的有参构造函数,需要
daugther(int attr) : grandmother(attr), mother(attr) { ... }
构造函数的列表初始化
在搜索什么情况导致的没有默认构造函数的时候,又搜到一个帖子
https://stackoverflow.com/questions/27872165/no-default-constructor-exists-for-class-error
这里讲了构造函数的列表初始化的作用
#include错误信息:
In constructor 'Stuff::Stuff(Thing)':
error: no matching function for call to 'Thing::Thing()'
Stuff(Thing thing){ this->thing = thing; }
candidate expects 1 argument, 0 provided
这是因为在进入构造函数的时候就应该调用 Thing 的
前面提到“如果用户定义有参构造函数,C++不再提供默认无参构造,但是会提供默认拷贝构造”
所以这样写是可以的
#include相当于提供了拷贝函数
#include不能 在派生类构造函数初始化列表中初始化 父类的成员
https://stackoverflow.com/questions/2290733/initialize-parents-protected-members-with-initialization-list-c
无法在初始化列表中初始化父类的成员的原因是因为此时父类构造函数尚未被调用,因此这些字段不可用。
但是我看另外一个帖子,他讲到了 C++ 类的初始化的顺序,应该是父类的构造函数比子类的先啊,这不是很自然的吗
https://stackoverflow.com/questions/18479295/member-initializer-does-not-name-a-non-static-data-member-or-base-class
所以我就觉得有点懵
或许我该这么想,就是在派生类的构造函数的列表初始化的时候,没有调用父类构造函数,但是在派生类的构造函数的函数体里面,已经调用了父类的构造函数
class A {
public:
int a;
A() {};
};
class B : public A {
public:
B(int b) : a(b) { a = b; };
};
所以才导致派生类的构造函数的列表初始化 a(b) 报错,函数体内的 a = b; 正常
编译器只在一定需要默认构造函数时,才会创建默认构造函数
然后又搜到一个文章
https://blog.csdn.net/zhangpeterx/article/details/102762410
里面解释了,编译器只在一定需要默认构造函数时,才会创建默认构造函数
很强……这个书和这个反汇编的格式都很好……
多态
多态分为两种
-
静态多态:函数重载和运算符重载属于静态多态,复用函数名
-
动态多态:派生类和虚函数实现运行时多态
静态多态和动态多态的区别
-
静态多态的函数地址早绑定 - 编译阶段确定函数地址
-
动态多态的函数地址晚绑定 - 运行阶段确定函数地址
#includeAnimal 中的 speak 函数不加 virtual:
动物在说话
动物在说话
Animal 中的 speak 函数加 virtual:
小猫在说话
小狗在说话
Animal 中的 speak 函数,不加 virtual 的话,那么 Cat 类用 Animal 指针来指向,调用 speak 的话,调用的函数是 Animal 中的 speak,这就是地址早绑定
这里我们说,不加 virtual,基类与子类之间都定义了的同名函数实际上是进行了函数重载
而如果用 virtual 修饰 Animal 中的 speak 函数,那么 Cat 类用 Animal 指针来指向,调用 speak 的话,调用的函数是 Cat 中的 speak,这就是地址晚绑定
因为函数加了 virtual 相当于告诉编译器,这个函数是“未知”的,所以编译器就不会按照函数重载的那套规则,在编译的时候就确定函数地址,而是会在运行时根据另一套规则来
也就是按照虚函数的规则,我们称为函数重写
重写虚函数的要求:返回值类型 函数名 参数列表 完全相同
这里从要求也可以看出,函数重载和函数重写是不一样的。之后我们详细解释虚函数的实现方法,就更加能看出这两个是不一样的
动态多态的原理
一般说的多态指的是动态多态
虚函数(表)指针
#include 这里与虚基类指针有一点不同的是,虚基类指针指向虚基类表,虚基类表的表项表示虚基类指针到虚基类成员的偏移量
而虚函数指针指向虚函数表,虚函数表的表项表示虚函数的地址(而不是虚函数指针到虚函数的偏移量)
虚析构和纯虚析构
多态使用的时候,如果子类中有属性开辟到堆区,如果使用父类类型的指针来指向子类对象,那么使用这个父类类型的指针来释放对象时,只会调用父类的析构函数(进行了函数地址早绑定)
解决方法:将父类中的析构函数改为虚析构或者纯虚析构(进行了函数地址晚绑定)
虚析构和纯析构共性:
-
可以解决父类指针释放子类对象,
-
都需要有具体的含函数实现
虚析构和纯虚构的区别:
- 如果是纯虚析构,该类属于抽象类,无法实例化对象
进阶部分
函数模板
普通函数与函数模板的区别
-
普通函数调用时可以发生自动类型转换(隐式类型推导)
-
函数模板调用时,如果利用自动类型推导,不会发生隐式类型转换
-
如果利用显式指定类型的方式,可以发生隐式类型转换
#include总结:建议使用显式指定类型的方式,调用函数模板,因为可以自己确定通用类型 T
普通函数与函数模板的调用规则
-
如果函数模板和普通函数都可以实现,优先调用普通函数
-
可以通过空模板参数列表来强制调用函数模板
-
函数模板也可以发生重载
-
如果函数模板可以产生更好的匹配,优先调用函数模板
#include总结:既然提供了函数模板,最好就不要提供普通函数,否则容易出现二义性。
模板的局限性
template<class T>
void f(T a,T b)
{
a = b;
}
在上述代码中提供的赋值操作,如果传入的a和b是一个数组,就无法实现了。
template<class T>
void f(T a,T b)
{
if(a>b)
{......}
}
在上述代码中,如果T的数据类型传入的是像Person这样的自定义类型,也无法正常运行。
解决函数模板局限性的方法:具体化的函数模板
因此C++为了解决这种问题,提供模板的重载,可以为这些特定的类型提供具体化的模板。
#include类模板
类模板与函数模板的区别
-
类模板没有自动类型推导的使用方式
-
类模板在模板参数列表中可以有默认参数
#include总结:
-
类模板使用只能用显式指定类型方式
-
类模板中的模板参数列表可以有默认参数
类模板中的成员函数只在代码中有引用时,编译器才将其实例化
类模板中成员函数和普通类中成员函数创建实际是有区别的:
-
普通类中的成员函数一开始就可以创建
-
类模板中的成员函数在调用时才创建
#include相对地,如果类模板的成员函数没有被调用,他就不会生成
这样就是会导致一个容易被忽视的问题,输入的模板类型 T 在某些情况下会导致错误,但是由于类模板的成员函数没有调用,所以没有生成,所以编译不会报错
https://stackoverflow.com/questions/33648155/does-the-member-function-of-class-template-not-get-instantiated-if-never-be-call
例如,以下代码会报错,因为 int 没有 foo 成员函数
template <typename T,bool hasFoo>
struct Broken {
void foobar(){
if (hasFoo){T::foo();}
else { std::cout << "BROKEN" << std::endl;}
}
};
int main(){
Broken<int,false> t;
t.foobar();
}
但是以下代码不会报错,因为 Works 类的 foo() 函数没有实例化,所以没有编译错误
template <typename T>
struct Works {
void foo(){T::foo();}
void bar(){std::cout << "WORKS" << std::endl;}
};
int main(){
Works<int> t;
t.bar();
}
其实我一直觉得这个所谓的“调用时”生成的说法怎么这么奇怪呢,什么叫作调用时啊,难道是编译成汇编语言之后吗?肯定不是啊,所以肯定是编译的时候生成的
所以我把这个说法改成了“类模板中的成员函数只在代码中有引用时,编译器才将其实例化”
当然实际上我也不知道具体是怎么回事哈哈哈
类模板对象做函数参数
类模板实例化出的对象,向函数传参的方式:
-
指定传入的类型——直接显式对象的数据类型
-
参数模板化——将对象中的参数变为模板参数进行传递
-
整个类模板化——将这个对象类型,模板化进行传递
#include类模板与继承
template<class T>
class Base{ ... };
class Son :public Base<int>{ ... };
template<class T>
class Son2 :public Base<T>{ ... };
类模板成员函数类外实现
类模板中成员函数类外实现时,需要加上模板参数列表。
类模板分文件编写的问题
一种会出错的,类模板成员函数在头文件中声明,在源文件中实现,在另一源文件中调用的例子
preson.h
#pragma once
#includeperson.cpp
#include"person.h"
template<class T1, class T2>
person<T1, T2>::person(T1 name, T2 age)
{
this->m_name = name;
this->m_age = age;
}
template<class T1, class T2>
void person<T1, T2>::show_person()
{
cout << m_name << endl;
cout << m_age << endl;
}
main.cpp
#include因为类模板中的成员函数创建时机是在调用阶段,这导致分文件编写时链接不到(按照普通类的分文件编写在创建成员函数时系统(我感觉应该是对于 main.cpp 中的 person 而言?)只能看到 ‘.h’ 头文件,而看不到 ‘.cpp’ 源文件,所以无法成功创建成员函数)
解决方式:
-
直接包含.cpp源文件
-
将声明.h和实现.cpp在到同一个文件中,并更改后缀名为.hpp,hpp是约定俗成的名称,并不是强制
解决方式 1:
将 main.cpp 中的包含头文件改为包含源文件
#include解决方式 2:
头文件和源文件合并为一个文件
person.hpp
#pragma once
#includemain.cpp 中包含这个 person.hpp
主流用法
使用类模板的友元函数
全局函数类内实现,直接在类内声明友元即可、
全局函数类外实现,需要提前让编译器知道全局函数的存在
#include虽然别人都是这么说……
但是我发现对于那些无参的函数,就会出现问题
#include我再把类中的模板删掉,还是一样的
#include说明这应该是跟模板无关的,纯粹是 friend 的应用问题
在类外面声明才能全局调用
而对于普通类中的有参函数,也是这样
#include其实本来,正常从直觉来说,在一个类里面声明的函数,又不是 static,就算是 static 也没有用类名空间修饰,怎么能直接就在类外当成全局函数用呢?
所以说,使用类模板的友元函数,的类内实现,是比较奇怪的……?
STL
STL大体分为六大组件,分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器。
-
容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据。
-
算法:常用的各种算法,如sort、find、copy、for_each等
-
迭代器:扮演了容器与算法之间的胶合剂
-
仿函数:行为类似函数,可作为算法的某种策略
-
适配器:一种用来修饰容器或者仿函数或迭代器结构的东西。
-
空间配置器:负责空间的配置与管理。
容器、算法、迭代器
序列式容器:强调值的排序,序列式容器中的每个元素均有固定的位置
关联式容器:二叉树结构体,各元素之间没有严格上的物理上的顺序关系
STL 常用容器
string
vector
使用 swap 收缩 vector 的内存
https://blog.csdn.net/qq_43684922/article/details/96569413
#include运行结果:
容量12138
大小10000
容量12138
大小3
容量3
大小3
这段代码实现的功能是,在初始放入一定量的数据时,vector 所占的内存可以跟数据量大致相等,而当数据量变小时,vector 的容量不会及时减少,也就是所占的很大的一部分内存不会被释放,所以我们需要一个方法去释放掉 vector 空占着的内存
swap 实现原理:可以看到实际是交换 vector 中用于指示空间的三个指针而已,也就是空间的交换实际是指针指向的交换(vector 的迭代器实现是指针,其他的不是,比如:deque 就是比较复杂的结构,别把迭代器都误认为指针,不同容器的迭代器实现不同),因为是指针交换,所以并不影响 *t1 的值。
这里,将 v 的指向从那“一百多万”的空间变成了新的匿名函数的“3”的空间,又因为匿名对象使用完就会被自动释放,因此也就把原 vector 开辟的空间释放干净了,也就不存在内存浪费的问题了。
用 reserve 为 vector预留空间
#include运行结果:
30
30 次还是很多的,一开始能确定要分配的数量大小的话,用 reverse 就只用分配一次
deque
双端数组,也就是支持随机访问,可以对头端进行插入删除操作
-
vector 对于头部的插入删除效率低,数据量越大,效率越低
-
deque 相对而言,对头部的插入删除速度会比 vector 快
-
vector 访问元素时的速度会比 deque 快,这和两者内部实现有关
deque 的内部工作原理
deque 内部有个中控器,维护每段缓冲区中的内容,缓冲区中存放真实数据。
中控器维护的是每个缓冲区的地址,使得使用 deque 时像一片连续的内存空间。
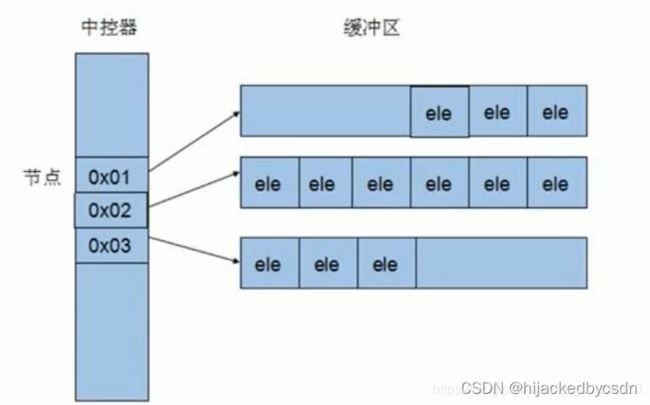
也因为 deque 由动态分配的连续空间组合而成,随时可以增加一段新的空间链接起来。所以 deque 没有容量 capacity 概念,只有像 vector 这种可能出现空间不足的容器才需要 capacity 与 reserve 的概念。包括 list 也是不需要 capacity 与 reserve 的
stack
queue
list
set/multiset
map/multimap
STL 函数对象
函数对象
重载了函数调用操作符 () 的类,其对象也称为函数对象
函数对象使用重载()时,行为类似函数调用,也叫仿函数
因为它本质是一个对象,所以可以有自己的状态(成员),但是它又能像函数那样调用,所以它用起来就像一个有状态的函数
因为它是一个对象,所以可以作为参数被传递,所以又像一个可以作为参数的函数
谓词
返回 bool 类型的仿函数称为谓词
如果operator()接受一个参数,那么叫做一元谓词
如果operator()接收两个参数,那么叫做二元谓词
内建函数对象
STL 内建了一些使用模板的函数对象,也是方便模板的使用……?
-
算数仿函数
-
关系仿函数
-
逻辑仿函数
STL 常用算法
常用遍历算法
for_each
transform
目标容器需要提前开辟空间
常用查找算法
find
find_if
adjacent_find
查找相邻重复元素
binary_search
二分查找指定元素是否存在
二分查找法效率很高,值得注意的是查找的容器中元素必须得是有序序列,否则结果未知。
count
count_if
常用的排序算法
sort
random_shuffle
merge
merge 合并的两个容器必须得是有序序列。
目标容器需要提前开辟空间
reverse
常用的拷贝和替换算法
copy
目标容器需要提前开辟空间
replace
将容器内指定范围的指定的旧元素修改为指定的新元素。
replace_if
swap
swap 交换容器时,注意交换的容器是同种类型。
常用算数生成算法
accumulate
累加指定范围内的元素
fill
用指定的元素填充指定范围内的元素
常用集合算法
set_intersection
-
求交集的两个容器必须得是有序序列。
-
目标容器开辟空间需要从两个容器中取小值。
-
set_intersection 返回值(迭代器)是交集中最后一个元素的位置。
set_union
-
求并集的两个集合必须得是有序序列。
-
目标容器开辟空间需要两个容器相加。
-
set_union返回值(迭代器)是并集中最后一个元素的位置。
set_difference
-
求差集的两个集合必须得是有序序列。
-
目标容器开辟空间需要从两个容器取较大值。
C++11
列表初始化
变量类型推导
https://blog.csdn.net/WJSZMD/article/details/53539739
auto和decltype都是类型推断的两种方式,但之间又有区别。
主要有这几个方面的区别:
1.auto是通过编译器计算变量的初始值来推断类型的,decltype同样也是通过编译器来分析表达式进而得到它的类型,但是它不用将表达式的值计算出来。
2.编译器推断出来的auto类型有可能和初始值类型不同,比如对于顶层const,auto会忽略顶层const性质,但是decltype是保留下来的,这在下面的代码中会有所体现。
3.与auto不一样,decltype的结果类型与表达式形式有密切关系。比如decltype()内层没有括号,那么得到的类型就是变量的类型,如果有多层括号decltype(())那么返回的就是引用,具体可以通过代码分析。
然后就是书写形式不同……我觉得这也不算是区别吧
#include final 与 override
默认成员函数控制 =default =delete
左值引用与右值引用
左值引用:
-
左值引用只能引用左值,不能引用右值
-
const左值引用既可以引用左值,也可以引用右值
右值引用:
-
右值引用只能引用右值,不能引用左值
-
右值引用可以move以后的左值
右值引用与移动语义
编译器自动优化拷贝构造相关
https://blog.csdn.net/GG_Bruse/article/details/128458935
这里有一个地方说是,函数返回将亡值到一个左值,会发生优化,而直接把函数返回值 -> tmp -> 左值接受分成两行写,就没有这个优化了
但是我实际写出来感觉不对啊
我写的 string 定义
#include 测试用例:
void main() {
string s = to_string(1);
}
输出:
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(const string& s) -- 拷贝构造(深拷贝)
string(const char* s = "") -- 默认构造
swap(tmp);
测试用例:
void main() {
string s;
s = to_string(1);
}
输出:
string(const char* s = "") -- 默认构造
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(const string& s) -- 拷贝构造(深拷贝)
string(const char* s = "") -- 默认构造
swap(tmp);
我的感觉就是,似乎不管怎么写,编译器都自动把函数内的局部变量 -> tmp 变量 -> 左值接受 中间的两次拷贝优化成一个了
如果提供了移动构造函数
#include 测试用例:
void main() {
string s = to_string(1);
}
输出:
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(string&& s) -- 资源转移
添加了移动构造之后,没有默认赋值函数了
这里,我们在赋值重载上,又有拷贝赋值重载和移动赋值重载的区别
#include 测试用例:
void main() {
string s = to_string(1);
}
输出:
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(string&& s) -- 资源转移
说明编译器把这个赋值函数给优化掉了,直接就是把返回值作为初始化
测试用例:
void main() {
string s;
s = to_string(1);
}
输出:
string(const char* s = "") -- 默认构造
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(string&& s) -- 资源转移
string& operator=(string s) -- 拷贝赋值(深拷贝)
string(const string& s) -- 拷贝构造(深拷贝)
string(const char* s = "") -- 默认构造
swap(tmp);
这个时候编译器没有优化掉这个等号
如果加上移动赋值重载
#include 测试用例:
已经知道了编译器会怎么优化了,所以只看没有优化后的
void main() {
string s;
s = to_string(1);
}
输出:
string(const char* s = "") -- 默认构造
string to_string(int val)
string(const char* s = "") -- 默认构造
return str;
string(string&& s) -- 资源转移
string& operator=(string s) -- 移动赋值(资源移动)
所以总之,使用右值引用的目的,并不是直接使用右值引用去减少拷贝,提高效率。而是对于那些支持深拷贝的类,提供移动构造和移动赋值,这时这些类的对象进行传值返回或者是参数为右值时,则可以用移动构造和移动赋值,转移资源,避免(没有移动构造或移动赋值时默认的)深拷贝,提高效率。
移动构造与移动赋值
在C++98时,我们学习过C++的类中一共有6个默认成员函数(分别是构造函数、析构函数、拷贝构造函数、拷贝赋值重载、取地址重载、const取地址重载)。但随着C++11的更新又新增了两个默认成员函数,即移动构造函数和移动赋值重载。
注意情况
-
若没有自主实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员则需要看这个成员是否存在移动构造,若存在就调用移动构造,不存在就调用拷贝构造。
-
若没有自主实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员则需要看这个成员是否存在移动赋值,若存在就调用移动赋值,不存在就调用拷贝赋值。
-
若提供了移动构造或者移动赋值中任意一个,编译器不会自动提供拷贝构造和拷贝赋值。
万能引用与完美转发
万能引用
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够同时接收左值引用和右值引用的能力,但是引用类型就会被限制,在后续使用中都退化成了左值。所以万能引用也被称为引用折叠(即左值引用和右值引用都被折叠为左值)。
也可以换一种理解方式。在前面提到过右值引用的特性,右值引用是左值,且左值引用也是左值。所以不出意外,既能接收左值也能接收右值的万能引用也是左值。
#include 右值传参时退化为左值原因
左值与右值最明显的区别是:右值不可以取地址,左值可以
右值在传参的时候被保存到了特定的位置,所以就可以取地址了,失去了右值属性。
例如在 void PerfectForward(T&& t) 中,右值被保存到了一个 t 中,可以对这个 t 取地址,所以 t 是左值
完美转发
std::forward 完美转发在传参的过程中保留对象原生类型属性
#include 使用场景
在实际开发中,某些接口函数是提供了右值引用版本的,譬如STL中vector、list等容器的插入接口。传入右值参数并被右值引用接收后,会被认为是左值,无法顺利调用到移动构造和移动赋值等函数(没有真正减少拷贝、提高效率),这时就需要使用完美转发来在传参过程中保证右值对象的属性。
还有一种使用场景,就是万能引用和完美转发配合的
https://blog.csdn.net/lichao201005/article/details/124264766
我们现在通过这个示例已经知道,万能引用最终得到的一定是左值引用
那么把万能引用得到的左值引用传给我们的业务逻辑的函数模板,只能匹配到形参为左值引用的模板,这样就无法使用到形参为右值引用的函数了,例如移动构造函数和移动赋值函数
template<typename F,typename T, typename U>
void tempFun(F f, T && t1, U && t2)
{
f(t1, t2);
}
我们可以用 std::move 来获得右值引用,但是这样我们又相当于在模板中只能获得右值引用了,这样就又匹配不到形参为左值引用的函数
因此我们可以用 std::forward 来保留传入的参数的左值右值性质
template<typename F,typename T, typename U>
void tempFun(F f, T && t1, U && t2)
{
f(std::forward<T>(t1), std::forword<U>(t2));
}
这里就解释了万能引用和完美转发在函数模板中的作用
lambda 表达式
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
可变参数模板
https://blog.csdn.net/chenlong_cxy/article/details/126807356
模板中如果要出现可变参数,模板中和函数形参中的写法都是特定的
template<class ...Args>
void ShowList(Args... args)
{}
Args 表示可变参数的各个类型,args 表示可变参数的值,这两个地方的写法记住就好了
然后在函数体中,args... 表示把可变参数展开
可变参数的用法是,要么是用递归展开,要么就是借助列表初始化,把 args… 放到一个列表中
递归展开记得要多写一个递归终止情况下的同名函数,比如最后递归到一定只剩下一个参数,就写一个参数的同名函数,可能最后递归到没有参数输入,就写一个无参的同名函数,不能在函数里企图用 if 配合 size…(args) 终止模板展开的递归,学模板的最初就应该知道,模板只是一个格式,用来告诉编译器以什么格式生成函数,而if是在运行时判断的,编译器不会管,所以编译器展开可变参数的时候不会被 if 配合 size…(args) 阻挡
同理,因为是编译时推导,可变参数模板也不支持 Args[i] 来找参数
然后他还提到了 emplace 接口和 push_back 接口之间的对比
emplace 接口可以接受左值,右值,和参数包(就是用可变参数实现)
用参数包的时候就是直接构造到指定位置,而如果传左值,左值进入拷贝构造函数内部,先拷贝左值构造一个 tmp,然后再与 tmp 交换;传右值,右值本身有一次构造函数,然后进入移动构造函数
所以 传左值 拷贝构造函数 构造函数;传右值 移动构造函数 构造函数;传构造参数 直接在容器位置构造
而 push_back 没有这种传构造参数的形式
所以一般人说 emplace 性能更好,但是这也只是给 emplace 直接传构造参数才可能性能更好
还有 左值对应拷贝构造函数,右值对应移动构造函数,这种似乎是一个约定俗成的东西?
是的,如果第一次学的人,一下子就来看这个可变参数模板,在这里可能会疑惑,但是如果我们从右值引用开始学起,就知道,我们是先引入了右值,然后我们再引入的形参为右值的移动构造函数
然后还有,他的拷贝构造,移动构造,移动赋值函数用 swap 来实现?这不本质上就是交换吗?虽然和右值交换之后,自己变成了右值,但是右值也变成了自己呀,右值变化了,这无所谓吗?一定要用 swap 吗,为什么不直接赋值,比如 this.size=tmp.size
我觉得,这是它自定义的移动构造函数的自己选择的写法,我觉得我也可以不用 swap,我自己怎么写都行,其实主要我们只是需要,在编译器识别到右值之后,进入我们定义的形参为右值的构造函数就好了