Mysql完整性约束详解(字段唯一,非空,主键primary key,外键foreign key,自增长auto_increment)
引入
1.什么是完整性约束, 为什么使用
为了规范数据格式, 在用户进行插入、修改、删除等操作时,DBMS(数据库管理系统(Data Base Management System))自动按照约束条件对数据进行监测, 使不符合规范的数据不能进入数据库, 以确保数据的完整性和唯一性
2.约束分类
表完整性约束条件与字段数据类型的宽度一样, 都是可选参数,分为以下几种:
| 完整性约束关键字 | 含义 |
|---|---|
| NULL | 标识字段值可以为空 |
| NOT NULL | 约束字段值不为空 |
| DEAFAULT | 设置字段值为默认值 |
| UNIQUE KEY(UK) | 约束字段的值唯一 |
| PRIMARY KEY(PK) | 设置字段为表的主键 |
| FOREIGN KEY(FK) | 设置字段为表的外键 |
| AUTO_INCREAMENT | 约束字段的值为自动递增 |
| UNSIGNED | 无符号 |
| AEROFILL | 使用 0 填充 |
一.null (空)
- 被指定的字段的可以为空, 没有指定则默认约束条件就是null
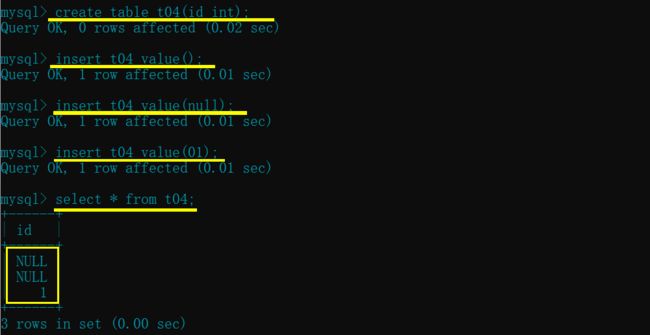
create table t04(id int);
insert t04 value(); # values() 也可以 value()
insert t04 value(null); # 并且 into 可以省略
insert t04 value(1);
二.not null (非空)
- 被指定字段的值不能为空
create table t05(name char(16) not null);
insert t05 value();
insert t05 value(null);
insert t05 value("shawn");

三.default (默认)
- 被指定了default条件的字段在插入的值时, 无论null还是not null都可以插入空
- 插入时不给赋值默认填入default指定的默认值
- 注意 : 当已经制定了约束条件not null时default后面就不能指定null作为默认值
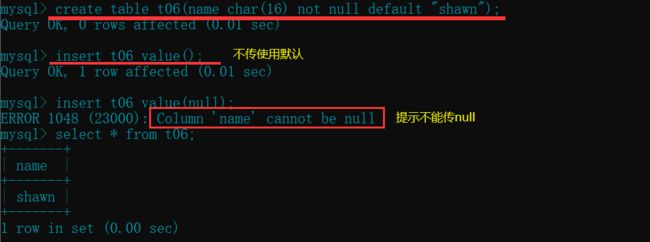
create table t06(name char not null default "shawn");
insert t06 value();
insert t06 value(null);
create table t07(name char not null dafault null); # 直接报错
四.unique (唯一)
- 被指定了unique的字段唯一, 两种唯一 :
- 单列唯一 : 一个字段唯一
- 联合唯一 : 多个字段联合后唯一
1.单列唯一
create table t07(id int unique,name char(16));
insert t07 value(1,"shawn"),(2,"song");
insert t07 value(1,"xing"); # 报错提示重复

2.联合唯一
create table t08(id int,ip varchar(16),port int,unique(ip,port)); # ip + port 联合单个可以重复, 联合不能相同
insert t08 value(1,"127.0.0.1",8090);
insert t08 value(2,"127.0.0.1",8091);
insert t08 value(3,"127.0.0.1",8090); # 联合与id为1的相同, 报错

3.not null + unique
- 不为空且唯一
五.primary key (主键)
主键约束(primary key)
1.什么是主键约束
- primary key 约束唯一表示数据库表中的美条记录
- 主键列不能为空(not null), 且必须唯一(unique), 效果上与(not null + unique一样)
- 每个表都应该有一个主键, 并且每个表只能有一个主键
2.主键的作用
- ’‘索引’'是mysql提供的一种数据结构, 在mysql中称之为**“键”**
- 它除了有约束效果之外, 它还是Innodb存储引擎组织数据的依据
- 因为它类似于书的目录, 能够提升查询效率并且它也是建表的依据
3.未设置主键如何处理表
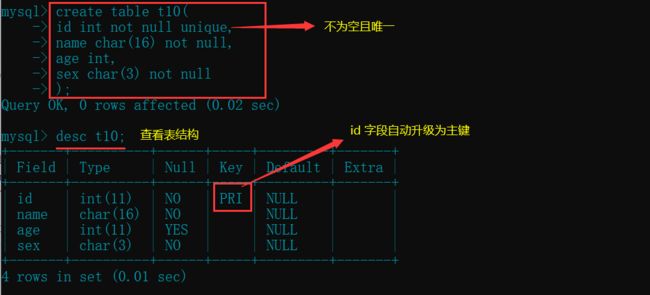
- 首先Innodb从上往下搜索所有字段, 直到找到一个非空且唯一的字段, 该字段就会自动升级为主键
- 如果表中既没有主键, 也没有非空且唯一的字段, 那么InnoDB会采用自己内部提供的一个隐藏字段作为主键, 此时提升查询效率的作用就无法享受了(隐藏字段看不见)
ps : InnoDB引擎表是基于B+树的索引组织表(IOT)(自行百度)
4.表的两种主键方式
- 单列主键 : 单个字段的主键
- 联合主键 : 多列做主键, 符合主键, 多个字段联合做主键
5.验证演示
- 验证约束效果 not null + unique (非空且唯一)
create table t09(id int primary key); # 设置主键
insert t09 value(1),(2);
insert t09 value(null); # 插入 null 报错
insert t09 value(1); # 插入id 1 报错
insert t09 value(2); # 插入id 2 也报错

- 验证不设置主键, 非空且唯一的字段自动升级主键
create table t10(
id int not null unique, # 设置 id 字段不为空,且唯一
name char(16) not null,
age int,
sex char(3) not null
);
desc t10; # 查看表结构
- 单列主键演示
create table t11(
id int primary key,
name varchar(16)
);
desc t11;

- 联合主键演示
create table t12(
ip varchar(16),
port int,
primary key(ip,port) # 设置 IP + port 联合主键
);
insert t12 value("127.0.0.1",8090);
insert t12 value("127.0.0.1",8091); # 单个字段可以相同
insert t12 value("127.0.0.1",8090); # 连个字段不能相同, 报错

6.主键总结
- 建表必须制定一个主键, 一般将 id 字段设置成主键
- 制定主键字段后, 该字段就非空且唯一(Innodb引擎的查找机制就是非空且唯一字段)
六.auto_increment (自增长)
1.自增长说明
- 自增长字段的值默认从 1 开始, 每次递增 1
- 自增长字段数据不可以重复
- 如果插入数据时id字段指定为0、null或未指定值,那么就把这个表当前的AUTO_INCREMENT值填到自增字段
- 如果插入数据时id字段指定了具体的值,就直接使用语句里指定的值
- 自增长字段必须是主键 (primary key)
2.使用场景
- 编号过多, 人为的去设置和维护太麻烦, 可以添加自增字段解决
3.自增长演示
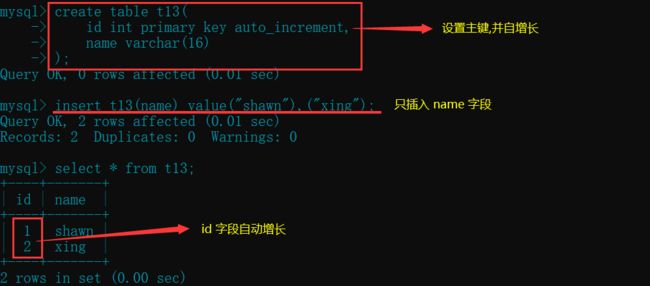
- 不指定 id , 让其自动增长
create table t13(
id int primary key auto_increment,
name varchar(16)
);
insert t13(name) value("shawn"),("xing");
- 指定 id, 则使用自己指定
insert t13 value(7,"xing"),(9,"hai");
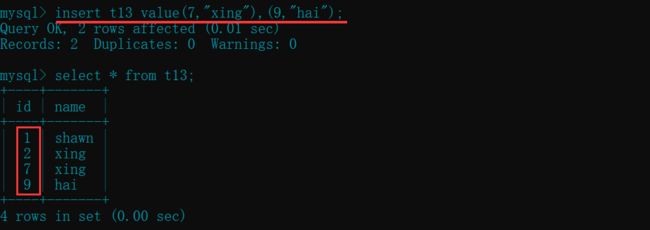
insert t13(name) value("hello"); # 再次不指定 id

4.删除表记录和清空表的区别
- 对于自增字段, 在用delete删除后, 再插入值, 该字段仍按照删除前的位置继续增长(delete是一条一条删除记录)
"delete"删除表再插入记录演示
delete from t13;
insert t13(name) value("shawn");
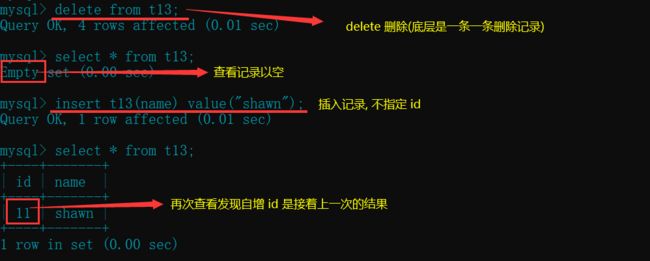
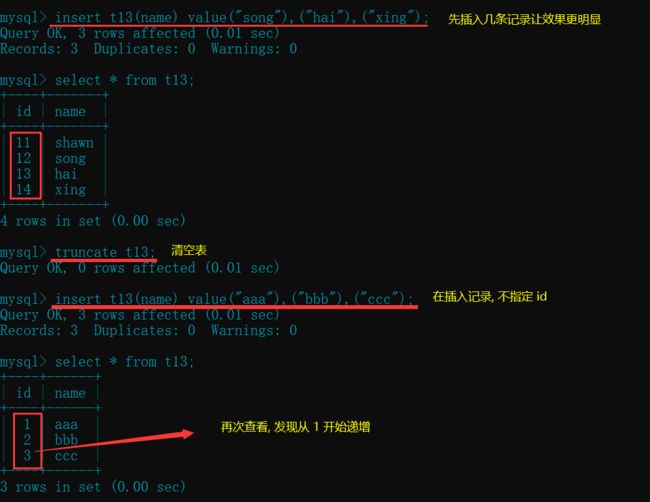
- 而使用truncate直接清空表, 不但将数据全部删除, 而且重新定位自增的字段, 删除大表时推荐使用
"truncate"清空表再插入记录演示
insert t13(name) value("song"),("hai"),("xing"); # 先插入几条记录
truncate t13;
insert t13(name) value("aaa"),("bbb"),("ccc"); # 再次插入记录
5.auto_increment修改和指定初始值
- 修改初始值演示
alter table t13 auto_increment=18;
insert t13(name) value("ddd"),("eee"),("fff");
select * from t13;

- 创建表时指定初始值
create table t14(
id int primary key auto_increment,
name varchar(16),
sex enum("male","female") default "male"
)auto_increment=5; # 初始值的设置为表选项,应该放到括号外
insert t14(name) value("aaa"),("bbb"),("ccc");

七.foreign key (外键)
1.外键的作用
- 可以使得两张表关联, 保证数据一致性和实现级联操作
2.外键介绍
- 外键也称之为外键约束 : foreign key
- MySQL 3.23.44版本后, Innodb引擎类型的表支持了外键约束
- 外键 : 一张表的一个字段(非主键字段)指向零一个表的主键, 那么该字段就称之为外键
- 相关联的两张表必须是Innodb表, 目前只支持Innodb存储引擎
3.子表和父表
- 子表 : 外键所在的表称之为子表(附表)
- 父表 : 外键所指向的主键所在的表称之为父表(主表)
4.表的三种对应关系
- 一对多(或者多对一)
- 多对多关系
- 一对一关系
ps : 得出表关系结论需要双向进行观察对比 (当然没有关系也是一种关系
)
5.快速了解 foreign key 的使用
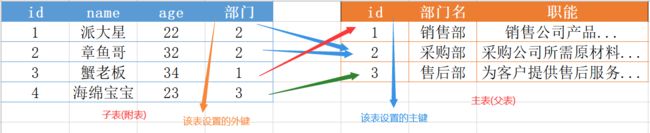
- 我们先定义一张员工表 : id、姓名、年龄、部门名、部门职能

从上面的表中我们不难发现缺点(以上只演示了7个员工, 假设有一万个员工) :
- 部门名和职能说明重复, 浪费磁盘空间
- 组织结构不是很清晰
- 数据的扩展性差 (重点)
- 优化表的组织结构, 将其抽离成两张表 : 员工信息表(emp)、部门表(dep)


表已经抽离成功, 我们使用 dep_id 将两个表建立联系
正常来说, 一个员工只能对应一个部门, 一个部门可以包含多个员工
结论 : 员工表与部门表是 一对多(或多对一) 的关系
- 一对多关系表, 外键关键字设置在多的一方(emp)
- 在建表时, 需先建立被关联的表(主表)(dep), 不然先创建附表会报错
- 插入数据时, 必须先往被关联的表(主表)插入(dep)
- 演示操作
语法 :
foreign key([子表字段]) references [主表名]([主表字段])
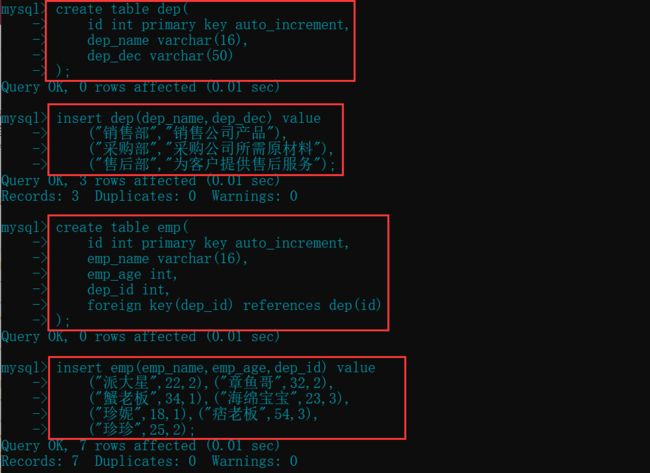
先创建被关联的表(主表)(dep)
create table dep(
id int primary key auto_increment,
dep_name varchar(16),
dep_dec varchar(50)
);
insert dep(dep_name,dep_dec) value
("销售部","销售公司产品"),
("采购部","采购公司所需原材料"),
("售后部","为客户提供售后服务"); # 插入部门数据
再创建附表(子表)(emp)
create table emp(
id int primary key auto_increment,
emp_name varchar(16),
emp_age int,
dep_id int,
foreign key(dep_id) references dep(id)
);
insert emp(emp_name,emp_age,dep_id) value
("派大星",22,2),("章鱼哥",32,2),
("蟹老板",34,1),("海绵宝宝",23,3),
("珍妮",18,1),("痞老板",54,3),
("珍珍",25,2); # 插入员工数据
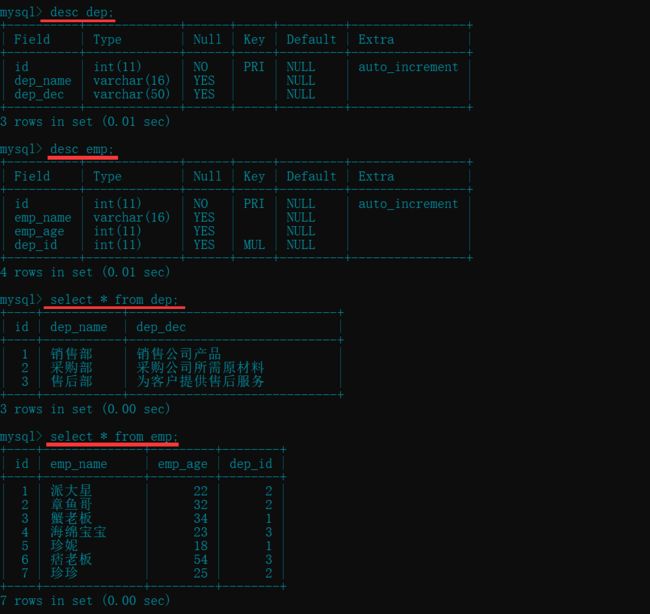
- 相互关联的主表和子表的关联字段无法更新, 除非设置级联更新(下边介绍)
update dep set id=100 where id=1; # 报错
update emp set dep_id=200 where dep_id=2; # 报错
- 相互关联的主表(dep)不能删除记录, 而子表(emp)可以
delete from dep where id=2; # 报错
delete from emp where id=4; # 可以删除成功
6.级联更新与级联删除
- 就是同步更新(
on update cascade), 同步删除(on delete cascade)
新建一个子表,并设置级联(emp2)
create table emp2(
id int primary key auto_increment,
emp2_name varchar(16),
emp2_age int,
dep_id int,
foreign key(dep_id) references dep(id)
on delete cascade
on update cascade
);
insert emp2(emp2_name,emp2_age,dep_id) value
("派大星",22,2),("章鱼哥",32,2),
("蟹老板",34,1),("海绵宝宝",23,3),
("珍妮",18,1),("痞老板",54,3),
("珍珍",25,2); # 插入员工数据

- **更新(update)**主表(dep)的 id, 子表(emp2)也随之更新
drop table emp; # 测试之前先删除 emp 表,以免受影响
update dep set id=100 where id=1; # 将主表 id 为 1 的改为 100
update emp2 set dep_id=300 where dep_id=3; # 子表无法更新外键(报错)
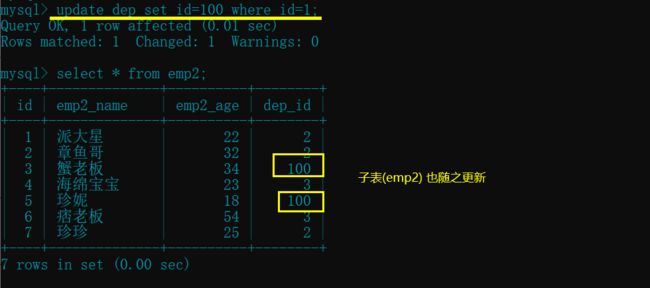
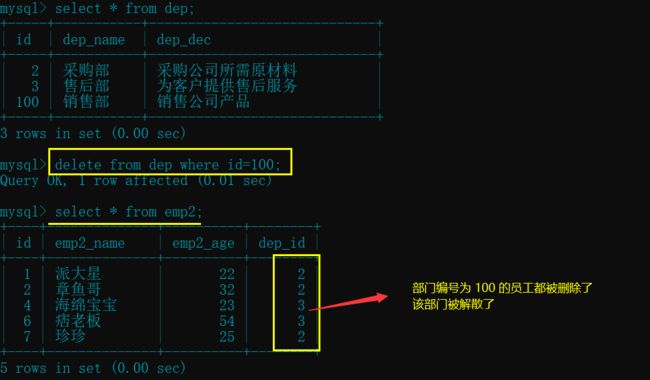
- **删除(delete)**主表的记录, 子表中对应的记录也随之解散
delete from dep where id=100; # 删除 id 为 100 的记录(销售部门)
select * from emp2; # 查看 emp2 受到的影响
7.如何找到两张表之间的关系(诀窍)(分析步骤)
- 步骤一 : 先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段可以 foreign key 右表一个字段(通常是id)
- 步骤二 : 再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段可以 foreign key 左表一个字段(通常是id)
- 结论 :
多对一 : 如果只有步骤1成立,则是左表多对一右表, 如果只有步骤2成立,则是右表多对一左表
多对多 : 如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表(中间表)来专门存放二者的关系
一对一 : 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然, 这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
8.建立表之间的关系
- 多对一(或一对多) 关系建立
上面的"员工表(emp)"与"部门表(dep)"就是多对一的关系
- 多对多
场景演示 : 作者和书的对应关系
对应关系 : 一个作者可以写多本书, 一本书也可以对应多个作者(合著) , 双向的一对多,即多对多
关联方式 : 设置外键(froeign key), 并使用一张中间表建立两表的联系

设计思路 : 创建一张中间表(au_bo), au_bo的一个id对应多个图书表(book)的id, 也对应作者表(author)的多个id, 反过来则是多对一, 于是我们就可以在au_bo表内设置两个外键foreign key 来分别关联book表的id和author表的id
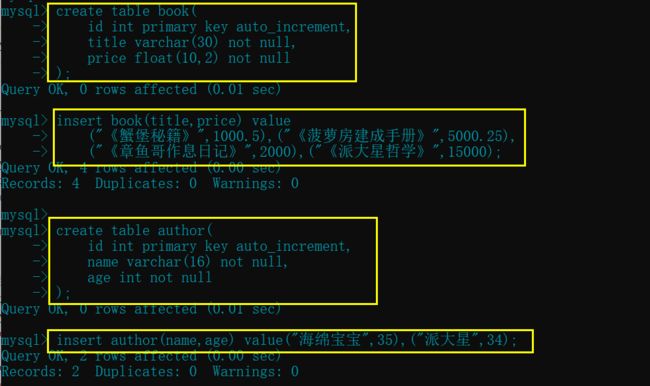
先创建"book"和"author"两张表,并插入值
create table book(
id int primary key auto_increment,
title varchar(30) not null,
price float(10,2) not null
);
insert book(title,price) value
("《蟹堡秘籍》",1000.5),("《菠萝房建成手册》",5000.25),
("《章鱼哥作息日记》",2000),("《派大星哲学》",15000);
create table author(
id int primary key auto_increment,
name varchar(16) not null,
age int not null
);
insert author(name,age) value("海绵宝宝",35),("派大星",34);
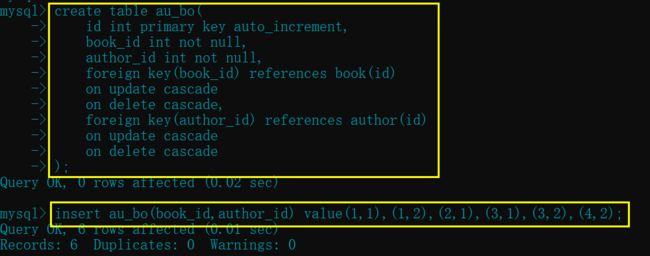
再创建中间表"au_bo", 并设置外键建立联系
create table au_bo(
id int primary key auto_increment,
book_id int not null,
author_id int not null,
foreign key(book_id) references book(id) # 设置外键
on update cascade
on delete cascade, # 设置级联更新和删除
foreign key(author_id) references author(id) # 设置外键
on update cascade
on delete cascade # 设置级联更新和删除
);
insert au_bo(book_id,author_id) value(1,1),(1,2),(2,1),(3,1),(3,2),(4,2);
select * from book;
select * from author;
select * from au_bo;

- 一对一
场景演示 : 一个人要去公司入职一个部门, 入职后就是员工, 部门对应的这个人是唯一的, 不可能有两个一模一样的人, 而这名员工对应的就这一个部门, 还比如一张身份证对应一个人
注意 : 一定得保证设置外键的字段唯一, 外键健在哪一方都可以, 建议建在查询频率较高的表中
创建"people"表,并插入内容
create table card(
id int primary key auto_increment,
phone int not null,
ID_card varchar(19) not null
);
insert card(phone,ID_card) value
(458796,"3675454567855544555"),
(784555,"3732458220113245979"),
(458755,"2332214578621525545");
创建"card"表,并插入内容
create table people(
id int primary key auto_increment,
name varchar(16) not null,
sex enum("male","female") default "male",
card_id int not null unique,
foreign key(card_id) references card(id)
on update cascade
on delete cascade
);
insert people(name,sex,card_id) value
("shawn","male",1),
("song","female",2),
("xing","male",3);
select * from people;
select * from card;


—end—