NLP之相似语句识别--特征工程篇:bow+tfidf+svd+fuzzywuzzy+word2vec

Quora是一个海外知名的在线问答网站(类似中国的知乎、百度知道),Quora上有许多问题和答案,也容许用户协同编辑问题和答案.不过由于某些“你懂的”原因,在国内无法访问访问该网站。在2018年9月,据Quora报告称每个月有超过3亿人访问Quora,很多人都会问重复的问题,还有很多问题具有相同意图仅仅只是表达方式不一样。 例如,“如何进行网上购物?”和“网上购物的步骤有哪些?”类似这样的问题都是重复的问题,因为它们都有相同的意图,所以应该只回答一次就可以了。
Quora正非常努力地消除重复的问题,但是这非常困难,因为对于相同的意图,不同的人可能会有不同的表达方式。如何从不同的表达方式中识别出相同的意图这是一个非常具有挑战性的工作。今天我们就来对相似问题进行研究,并通过特征工程来丰富我们的词向量表达,丰富的词向量表达方式可以帮助我们提高模型的预测准确率多人不知道什么是特征工程,为什么要搞特征工程?在这里我就举一个形象一点的例子来帮助大家里面特征工程的重要性:大家都知道奶牛会产奶,不同的奶牛产的牛奶质量也不完全一样,有的口感好,质量高,有的口感差,质量也就差一点,那么牛奶质量的好坏取决于什么呢?牛奶质量主要取决于奶牛所吃的饲料,奶牛的饲料大致可分为粗饲料和精饲料两种,如果你只给奶牛喂粗饲料,那么奶牛所产的牛奶的质量可能就要差一点,但是如果你给奶牛喂粗饲料的时候同时配上精饲料,那么它产的奶的质量就要比只吃粗饲料的奶牛产的奶的质量要高。在这里我们可以把奶牛比作我们的算法模型,牛奶的质量比作模型的质量(预测准确率等指标),饲料就好比是我们的训练数据集(特征集)。奶牛吃饲料并产奶的过程就好比我们把训练数据喂给算法模型,模型就产生了预测的能力。此时模型预测能力的好坏就取决于我们所喂的训练数据(特征集),如果你只给模型喂当前的特征集,这就好比你只给奶牛喂粗饲料,那么模型的质量和牛奶的质量都不会高。因此我们要在当前特征集(粗饲料)的情况下,研发出更有价值的新的特征集(精饲料),这个过程我们就称之为特征工程,只有当我们的模型同时吃了“粗饲料”和“精饲料”,它产出“奶”的质量才会更好。我举的这个奶牛的例子不一定科学,但它能比较形象的帮助大家来理解什么是特征工程。
今天我们处理文本的特征工程会用到以下一些方法:
- basic
- BOW(词袋)
- tf-idf
- svd
- fuzzywuzzy
- distance
- word2vec
虽然我们这次处理的是英文的文本,但是相信通过对上述方法的学习,对我们日后处理中文文本也会有很好的借鉴作用。
数据
我们的数据来自于Kaggle,你可以在此下载,在train表中有3个主要字段:
- question1和question2:对问题的完整描述
- is_duplicate - 目标变量,如果question1和question2具有基本相同的含义,则为1,否则为0。
df = pd.read_csv('./data/quora/train.csv')
df = df.dropna(how="any").reset_index(drop=True)
print(len(df))
df.sample(5) 
总共有40多万条记录,下面我们看一下目标变量的分布情况:
print(df.groupby("is_duplicate")['id'].count())
df.groupby("is_duplicate")['id'].count().plot.bar()
看来大部分的问题都被标记为0,少部分被标记为1,下面我们随机抽取10条记录的question1和question2看看:
for i in df.sample(10).index:
print(df.question1[i])
print(df.question2[i])
print()
接下来我们删除不需要的字段:
df.drop(['id', 'qid1', 'qid2'], axis=1, inplace=True)特征工程
basic
基本特征工程包括计算question1和question2的长度,以及它们的长度差,计算每个question的字符数等,主要包含以下功能:
- 计算question1的长度
- 计算question2的长度
- 计算question1和question2的长度差
- 计算过滤掉空格后的question1的字符长度
- 计算过滤掉空格后的question2的字符长度
- 计算question1中的单词数量
- 计算question2中的单词数量
- 计算question1和question2中的常用单词数量
# 计算question1和question2的长度
df['len_q1'] = df.question1.apply(lambda x: len(str(x)))
df['len_q2'] = df.question2.apply(lambda x: len(str(x)))
# 计算两个问题的长度差
df['diff_len'] = df.len_q1 - df.len_q2
# 计算两个问题的字符数量
df['len_char_q1'] = df.question1.apply(lambda x: len(''.join(set(str(x).replace(' ', '')))))
df['len_char_q2'] = df.question2.apply(lambda x: len(''.join(set(str(x).replace(' ', '')))))
# 计算两个问题的单词数
df['len_word_q1'] = df.question1.apply(lambda x: len(str(x).split()))
df['len_word_q2'] = df.question2.apply(lambda x: len(str(x).split()))
# 计算两个问题的常用单词数
df['common_words'] = df.apply(lambda x: len(set(str(x['question1']).lower().split()).intersection(set(str(x['question2'])
.lower().split()))), axis=1)
df
为了以后使用方便,我们将基本特征集记录为fs_basic:
fs_basic = df[['len_q1', 'len_q2', 'diff_len', 'len_char_q1',
'len_char_q2', 'len_word_q1', 'len_word_q2',
'common_words']]BOW(词袋)
关于BOW在我之前的多篇博客中均有使用及说明,这里不再详细阐述其原理,我们在这里使用的词袋模型为sklearn的CountVectorizer,为了以后使用方便,我们将bow特征集记录为fs_bow:
count_vect = CountVectorizer(analyzer='word', token_pattern=r'\w{1,}')
count_vect.fit(pd.concat((df['question1'],df['question2'])).unique())
trainq1_trans = count_vect.transform(df['question1'].values)
trainq2_trans = count_vect.transform(df['question2'].values)
fs_bow = scipy.sparse.hstack((trainq1_trans,trainq2_trans))
fs_bow.shape![]()

我们最后得到的词袋特征集fs_bow是一个稀疏矩阵,因为稀疏矩阵中存在大量的零元素,因次我们使用了scipy.sparse来存储稀疏矩阵(只存储非零元素)。
TF-IDF
关于TF-IDF在我之前的多篇博客中均有使用及说明,这里不再详细阐述其原理,我们在这里使用的tf-idf模型为sklearn的TfidfVectorizer,在这里我们所使用的tf-idf也可以分为两种类型:
- 基于word的tf-idf
- 基于字符的tf-idf
基于word的TF-IDF
tfidf_vect = TfidfVectorizer(analyzer='word',min_df=3,token_pattern=r'\w{1,}',ngram_range=(1,2),max_features=5000)
tfidf_vect.fit(pd.concat((df['question1'],df['question2'])).unique())
trainq1_trans = tfidf_vect.transform(df['question1'].values)
trainq2_trans = tfidf_vect.transform(df['question2'].values)
fs_tfidf_word = scipy.sparse.hstack((trainq1_trans,trainq2_trans)) 
基于字符的TF-IDF
tfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char',min_df=3, token_pattern=r'\w{1,}',ngram_range=(1,2), max_features=5000)
tfidf_vect_ngram_chars.fit(pd.concat((df['question1'],df['question2'])).unique())
trainq1_trans = tfidf_vect_ngram_chars.transform(df['question1'].values)
trainq2_trans = tfidf_vect_ngram_chars.transform(df['question2'].values)
fs_tfidf_char = scipy.sparse.hstack((trainq1_trans,trainq2_trans))
TF-IDF模型所用的参数请参考我之前的几篇博客或者官方文档,这里不再详细阐述。
SVD
我们在TF-IDF特征集的基础上可以使用SVD模型,从而可以进一步来降低TF-IDF特征集的维度:
svd_word = TruncatedSVD(n_components=180)
fs_svd_word = svd_word.fit_transform(fs_tfidf_word)
svd_char = TruncatedSVD(n_components=180)
fs_svd_char = svd_word.fit_transform(fs_tfidf_char)
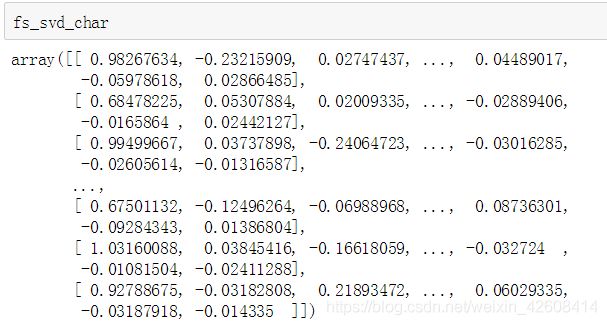

经过SVD降维后,tf-idf特征集的维度降到了180维。
fuzzywuzzy
fuzzywuzzy是python的一个用来进行模糊字符串匹配的工具,它的基本原理是基于计算两个相似字符串之间的编辑距离,fuzzywuzzy提供了多种比率(ratio)来描述两个字符串之间的相似程度。主要包含以下几种比率:
- QRatio
- WRatio
- Partial ratio
- Partial token set ratio
- Partial token sort ratio
- Token set ratio
- Token sort ratio
我们看看下面几个例子:
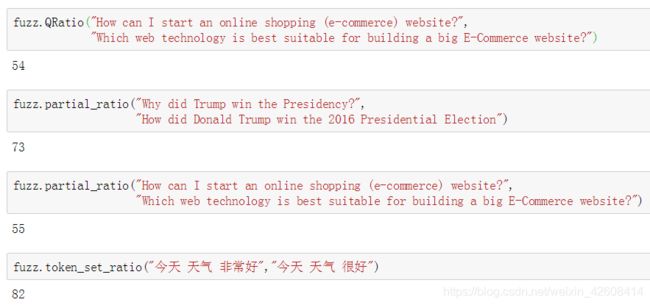
根据fuzzywuzzy返回的ratio值越高,说明两个字符串越相似。下面就让我们在原始数据上计算一下fuzzywuzzy的各自ritio:
df['fuzz_ratio'] = df.apply(lambda x: fuzz.ratio(str(x['question1']), str(x['question2'])), axis=1)
df['fuzz_partial_ratio'] = df.apply(lambda x: fuzz.partial_ratio(str(x['question1']),str(x['question2'])), axis=1)
df['fuzz_partial_token_set_ratio'] = df.apply(lambda x:fuzz.partial_token_set_ratio(str(x['question1']),str(x['question2'])), axis=1)
df['fuzz_partial_token_sort_ratio'] = df.apply(lambda x:fuzz.partial_token_sort_ratio(str(x['question1']),str(x['question2'])), axis=1)
df['fuzz_token_set_ratio'] = df.apply(lambda x:fuzz.token_set_ratio(str(x['question1']),str(x['question2'])), axis=1)
df['fuzz_token_sort_ratio'] = df.apply(lambda x: fuzz.token_sort_ratio(str(x['question1']),str(x['question2'])), axis=1)为了便于以后的使用,我们将fuzzywuzzy的特征集记为fs_fuzz:
fs_fuzz = df[['fuzz_ratio', 'fuzz_partial_ratio',
'fuzz_partial_token_set_ratio', 'fuzz_partial_token_sort_ratio',
'fuzz_token_set_ratio', 'fuzz_token_sort_ratio']]
fs_fuzz
Distance
接下来我们将另外一个距离特征集,我们将计算question1和question2之间的各种空间距离,主要包括:
- 余弦距离(Cosine distance)
- 曼哈顿距离(Manhattan distance)
- Jaccard 距离
- 堪培拉距离(Canberra distance)
- 欧式距离( Euclidean distance)
- 闵可夫斯基的距离(Minkowski distance)
- 布雷柯蒂斯距离(Bray-Curtis distance)
在计算距离之前我们要先将question1和question2中的问题句子进行向量化处理,因此我们要定义一个将句子向量化的函数,然后再将question1和question2进行向量化:
def sent2vec(s):
words = str(s).lower()
words = word_tokenize(words)
words = [w for w in words if not w in stop_words]
words = [w for w in words if w.isalpha()]
M = []
for w in words:
try:
M.append(model[w])
except:
continue
M = np.array(M)
v = M.sum(axis=0)
return v / np.sqrt((v ** 2).sum())
#创建question1的句向量
question1_vectors = np.zeros((df.shape[0], 300))
for i, q in enumerate(tqdm_notebook(df.question1.values)):
question1_vectors[i, :] = sent2vec(q)
#创建question2的句向量
question2_vectors = np.zeros((df.shape[0], 300))
for i, q in enumerate(tqdm_notebook(df.question2.values)):
question2_vectors[i, :] = sent2vec(q)完成了question1和question2的向量化以后,我们就可以开始计算question1和question2之间的空间距离了:
df['cosine_distance'] = [cosine(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['cityblock_distance'] = [cityblock(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['jaccard_distance'] = [jaccard(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['canberra_distance'] = [canberra(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['euclidean_distance'] = [euclidean(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['minkowski_distance'] = [minkowski(x, y, 3) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]
df['braycurtis_distance'] = [braycurtis(x, y) for (x, y) in zip(np.nan_to_num(question1_vectors), np.nan_to_num(question2_vectors))]偏度和峰度
偏度(Skewness)和峰度(Kurtosis)是统计学里面用来检验数据分布形态的两个重要指标,偏度是指偏离正太分布的程度(是否存在长尾),峰度是指数据分布的峰值(均值)是否突兀或是平坦。我们会使用scipy.stats的skew和kurtosis这两个方法来计算偏度和峰度:
#计算偏度和峰度
df['skew_q1vec'] = [skew(x) for x in np.nan_to_num(question1_vectors)]
df['skew_q2vec'] = [skew(x) for x in np.nan_to_num(question2_vectors)]
df['kur_q1vec'] = [kurtosis(x) for x in np.nan_to_num(question1_vectors)]
df['kur_q2vec'] = [kurtosis(x) for x in np.nan_to_num(question2_vectors)]为了便于以后的使用,我们将空间距离和偏度与峰度的特征集记为fs_distance :
fs_fuzz = df[['fuzz_ratio', 'fuzz_partial_ratio',
'fuzz_partial_token_set_ratio', 'fuzz_partial_token_sort_ratio',
'fuzz_token_set_ratio', 'fuzz_token_sort_ratio']]
fs_fuzz
word2vec
一般来说,Word2vec模型是两层神经网络,它将文本语料库作为输入并输出该语料库中每个单词的向量。经拟合后,具有相似含义的词的向量彼此接近,也就是说,词义相近的单词之间的距离要比那些词义不同的词之间的距离要小。
如今,Word2vec已成为自然语言处理问题的标准,并且通常它为信息检索任务提供了非常有用的帮助。我们将使用Google新闻媒介。这是在Google新闻语料库中的预训练Word2vec模型。你可以在这里下载这个预训练的语料库(https://pan.baidu.com/s/1UNE1W60JUN6HuaRMvwNMHg 提取码:ya5b )。 如果你使用来自Google新闻语料库的预训练向量,则其中的所有单词(如“德国”,“柏林”,“法国”和“巴黎”)都可以用300维向量表示。当我们对这些单词使用Word2vec表示时,我们从“柏林”的向量中减去“德国”的向量再加上“法国”的向量,我们将得到一个与“巴黎”的向量非常相似的向量,即:
V("柏林") - V(“德国”) + V("法国") ≈ V("巴黎")
如过想对Word2vec进一步了解,请阅读这个和这个
因此,Word2vec模型承载了向量中单词的含义。这些载体所携带的信息对我们的任务构成了非常有用的特征。要加载Word2vec向量,我们要使用Gensim:
import gensim
from gensim.models import Word2Vec
wmd_model = gensim.models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin.gz', binary=True)
norm_wmd_model = gensim.models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin.gz', binary=True)WMD(Word Mover's Distance)
WMD是一种评估两个文档之间的“距离”的方法,它可以用于检索内容相似的问题,比如对应某些博客的推荐系统中,可以给用户推荐与用户当前所看的博客内容相似的其他博客,这时就用的WMD技术。如果你想进一步了解如何使用WMD,那么可以阅读这个文档。下面我们先定义两个个测量文档之间距离的函数:
def wmd(q1, q2):
q1 = str(q1).lower().split()
q2 = str(q2).lower().split()
stop_words = stopwords.words('english')
q1 = [w for w in q1 if w not in stop_words]
q2 = [w for w in q2 if w not in stop_words]
return model.wmdistance(q1, q2)
def norm_wmd(q1, q2):
q1 = str(q1).lower().split()
q2 = str(q2).lower().split()
stop_words = stopwords.words('english')
q1 = [w for w in q1 if w not in stop_words]
q2 = [w for w in q2 if w not in stop_words]
return norm_model.wmdistance(q1, q2)参数norm_wmd表示对word2vec向量进行标准化处理(归一化)。那么我们将对question1和question2的word2vec向量进行两种方式处理即,不使用归一化和使用归一化。最后为了便于以后使用,我们将WMD的特征集记为fs_wmd:
model = gensim.models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin.gz', binary=True)
df['wmd'] = df.apply(lambda x: wmd(x['question1'], x['question2']), axis=1)
norm_model = gensim.models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin.gz', binary=True)
norm_model.init_sims(replace=True)
df['norm_wmd'] = df.apply(lambda x: norm_wmd(x['question1'], x['question2']), axis=1)
fs_wmd=df[['wmd','norm_wmd']]
fs_wmd 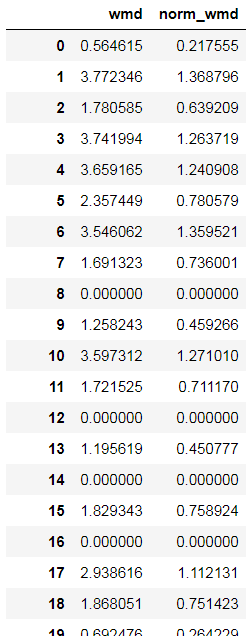
总结
到目前为止我们已经为我们的“奶牛”准备了以下几种“饲料”:
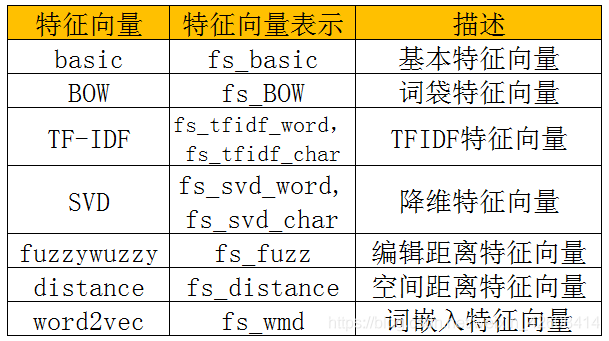
总共有7种类的特征向量,9个特征向量集。接下来我们要将这些特征向量集进行各种组合,然后我们会在下一篇博客中,将他们“喂”给我们的算法模型(XGBoost),并评估我们的模型在“吃”了这些“饲料”后的表现会如何。
完整代码可以在这里下载
