CIKM 2021 | DISENKGAT:知识图谱解耦表征学习

©PaperWeekly 原创 · 作者 | 吴俊康
学校 | 中国科学技术大学硕士生
研究方向 | 信息检索

论文标题:
DisenKGAT: Knowledge Graph Embedding with Disentangled Graph Attention Network
论文作者:
吴俊康(中国科学技术大学),石文焘(中国科学技术大学),曹雪智(美团),陈佳伟(中国科学技术大学),雷文强(新加坡国立大学),张富峥(美团),武威(美团),何向南(中国科学技术大学)
论文链接:
https://arxiv.org/pdf/2108.09628.pdf
收录会议:
CIKM 2021

摘要
知识图谱补全近年来受到学术界和业界的广泛关注。然而现有的方法只将图谱中的实体表征成单独的静态的一个向量,这限制了模型的表达能力,特别是难以捕捉图谱中的复杂的关系。基于此,我们提出了一个知识图谱解耦表征方法,将每个实体表征为多个独立的向量,从而提升模型的表达能力。一方面,我们在知识图谱卷积中引入关系感知信息聚合机制,促使表征的每个成分聚合到不同的信息,此部分实现了“微观解耦”;另一方面,我们通过添加互信息正则项来增强表征中每个成分之间的独立性,从而实现了“宏观解耦”。最后,我们在常用的两个基准数据集上验证了解耦表征可以有效的提升性能。

研究背景
知识图谱补全是知识图谱中最为基础且最为常见的任务之一,许多 AI 相关工作都需要依靠知识图谱的构建。现有模型(基于距离表征的模型、基于语义匹配的模型以及基于神经网络的模型)的常见思路是通过定义一个打分函数,期望其能较好地分辨出真实三元组与伪三元组;即真实样本的预测分数显著高于负样本。
我们研究过程中发现现有模型仍存在显著的问题:如一对多 (1-N)、多对一 (N-1) 与多对多关系(N-N)的预测。举例来说,如图 1 所示,国籍就是一种典型的多对一关系,即每个人都只有唯一的一种国籍,而成千上万的人都拥有相同的国籍。将询问(科比,职业,?)和询问(比尔盖茨,职业,?)进行分析举例,由于两人物的国籍均上美国,因此上述模型会将科比和比尔盖茨两实体拉近以共享国籍美国这一信息。而针对职业这一关系,两者差异巨大,直觉是应该疏远两者,并无明显相关性,显然静态且唯一的表征会显著影响图谱补全的效果。换言之,上述经典模型无法根据场景的动态变化生成不同的适应性表征。
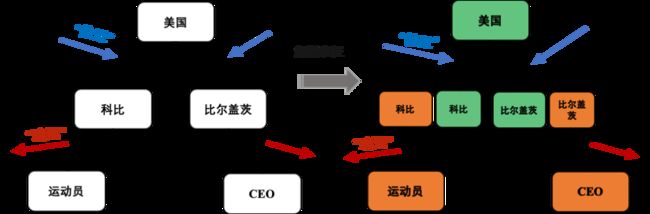
▲ 图1
针对上述案例中选取例子,本文总结现存模型的劣势如下:
1. 简单的聚合邻居信息无法有效提取建模关键的邻居边信息,其中邻居边信息往往蕴含着实际预测的场景。本文认为同一实体在不同场景下应当展现出不同的表征含义。
2. 上述模型往往忽视了实体嵌入表征背后往往存在隐因子的耦合。如下图2所示,科比和不同场景下的信息都有邻接关系,比如职业部分、荣誉部分、家庭信息以及地域信息。假设有一个询问时关于科比的儿子信息,显然我们期望模型将更多的重心侧重于他家庭属性下的邻居,如他的妻子以及他的女儿,而不是一些他的工作他的荣誉等无关主题等属性信息。
3. 根据上述两点,之前模型将会导致模型的可解释较低以及鲁棒性较低。现有模型生成的单一、静态化表征将导致其在提取邻居信息的过程中抹除了关键的结构信息和文本语义信息。
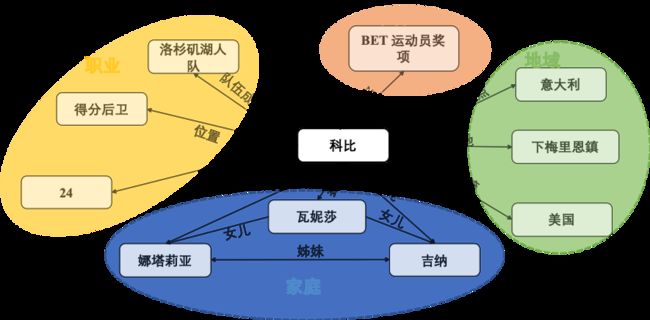
▲ 图2
在本文中,我们通过引入基于解耦表征的学习框架以解决上述问题。知识图谱解耦的核心思想为:通过将实体不同主题语义表示进行拆分解耦,根据给定查询针对性匹配相应主题化语义表示进行嵌入预测,以实现不同场景下动态化表示,从而有效解决复杂多语义知识图谱表示补全。

研究现状和相关工作
3.1 知识图谱补全
现有知识图谱补全模型可分为三类:基于距离表征的模型、基于语义匹配的模型以及基于神经网络的模型。三者都遵循定义一个打分函数衡量真实样本合理性与否的研究范式。后续根据其缺乏对图结构信息的挖掘,逐步引入图神经网络(GCN)[2][3][4],并形成一个“encoder-decoder”的研究范式,即在 encoder 中通过 GCN 挖掘图结构信息,后续 decoder 中利用现有的打分函数进行预测。然而现有模型仍然是建模单一静态化实体表征,无法有效解决一对多(1-N)、多对一(N-1)与多对多关系(N-N)的预测。
近两年部分模型也尝试解决上述问题,如 [5][6][7] 等提供了 relation-specific projections 帮助实体根据 relation 进行特异性嵌入。而 Coke[8] 则是引入 transformer 动态化挖掘上下位信息。FAAN[9] 利用动态注意力网络与 transformer 有效匹配查询实体。尽管上述问题已经存在部分尝试,如何从解耦角度进行思考解决仍没有正式的讨论。
3.2 解耦表征学习
解耦表征学习是通过挖掘数据背后隐因子的分离化表征从而有效建模复杂场景,其相应应用已经在文本、计算机视觉等有大量尝试。而在图 (graph) 领域,DisenGCN[10] 是首次在图数据挖掘中引入解耦的思想,其通过一个邻居循迹策略(neighborhood routing strategy)对图子语义信息进行了尝试建模。后续为解决其缺乏解耦因子分散的独立性限制,IPGDN[11] 和 ADGCN[12] 分别利用 Hilbert-Schmidt Independence Criterion (HSIC) 以及对抗网络对其进行正则化限制。核心是保证各个子语义表示互相独立,防止训练过程中子语义表示再次耦合。上述模型均为简单同构图中的尝试,DisenHAN[13] 则是专注在异构图解决上述问题。

模型介绍
4.1 问题定义
给定一张残缺知识图谱,期望通过对其进行学习以实现残缺边的预测,如给定头实体 和边 进行真实尾实体的预测 。值得注意的是,现有任务往往是转变为一个排名任务,即期望通过打分函数 ,对真实样本的预测情况优于负样本。
4.2 基于解耦表征学习的图谱补全框架
本任务提出的模型整体框架如图 3.1 所示:整体模型包含三个关键部分:1)关系感知信息聚合机制,此部分实现了微观解耦;2)独立性限制,此部分通过添加互信息正则项实现了宏观解耦;3)动态打分预测。其中每种通道(颜色)代表一种特定的子部分信息,并且不同通道之间保持独立。最终的结果需要根据各通道的预测结果再根据当前场景与各通道的相似程度判断给出最终的预测分数排名。

4.3 解耦转换
本课题提出的模型希望学习出的表征能够实现解耦,即每部分表征代表不同的含义。具体来说,对于实体 ,本文假设它的表征由 个独立因子共同决定,如 ,其中 ,表示实体 在第 部分的表征。为了实现上述目标,我们首先将初始的实体表征矩阵映射到不同的隐空间当中,从而更好地帮助挖掘节点特征中的不同语义。

其中,实体的初始化表征是通过各实体表征通过 个独立的映射矩阵 得到的,σ 是非线性激活函数, 是节点的特征。
4.4 关系感知信息聚合
在解耦思想下,我们期望在聚合邻居信息时仅仅使用与当前主题最为相关的部分邻居,并非所有邻居实体。如图 2 科比知识图谱中,倘若给出查询其家庭信息,妻子、女儿等邻居应当赋予更高权重。因此,我们需要回答的问题是:如何定义当前场景下最相关的邻居子集呢?与同构图中的邻居循迹策略不同的是,知识图谱中连接边的信息对主题的定义至关重要。因此在聚合过程中应当显式融入邻居边信息以更好地实现解耦。

此部分, 是一个信息融合操作; 代表着从邻居 与边 共同作用下聚合得到的信息。本文中我们通过四种操作实现 ,包括减法、乘法、交叉作用与循环卷积。
为了更好地捕捉实体 与实体 之间关于子表征 的相关性,我们提出一个关系感知注意力机制来衡量两实体该部分重要性程度。这里同样为了简化操作,并且基于假设:两实体如果在第 个子表征十分相似,则两者相连的关系很大程度上是由于因子 造成的。我们采用点积(dot-product)注意力机制,具体表示如下:
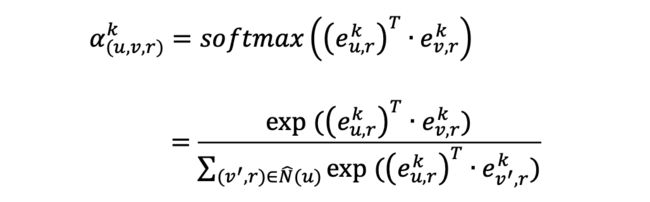
上述公式中 ,代表实体 在关系感知 的超平面中子表征。
在得到上述注意力分数后,我们可以从邻居实体中聚合信息并且更新中心实体各子部分表征,其中 代表实体通过 层信息聚合后得到的最终表征:
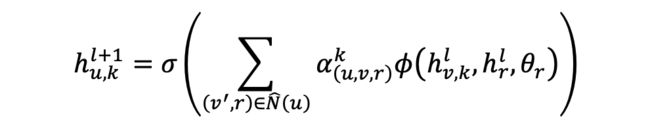
与上述公式类似,此处 代表关系 在第 层的表征。我们同样适用一个 layer-wise 的线性变换用于更新连接边表征。
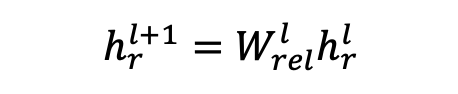
总结本部分模型,关系感知聚合策略保证了 倾向于聚合至一个较紧的空间中,使得各部分相似语义表征相近。我们将此部分解耦机制称之为微观解耦。
4.5 独立性限制
在复杂多关系图中(如知识图谱),我们期望不同语义空间中的子表征相互尽可能独立,即降低彼此直接依赖。类似的思想已经曾在 [12][13] 提出,分别从距离相关与 Hilbert-Schmidt Independence Criterion(HSIC)两个角度进行思考控制。但本文认为控制线性相关是无法满足复杂场景下的依赖关系,因此根据互信息是衡量两个随机变量非线性相关性的一个基本量,它对实现真正意义上解耦具有深刻意义。本文采用互信息最小化对不用语义间相关性进行控制。
虽然上述想法看似简单,但解决方案是十分复杂且具有挑战性的。由于高维度向量的互信息且无先验知识的情况下,无法计算出互信息的取值。借助 2020 ICML 的工作 CLUB[14] 的思想,本文采用一种对比对比对数比上界的估计来实现解耦。核心思想为借助对比正负样本之间的差异从而对互信息上界进行估计。
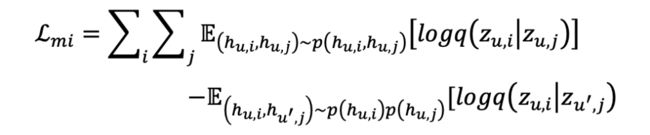
值得注意的是, 且 Q 同时用于训练最小化真实条件概率 与变分条件概率 之间的 KL 散度。
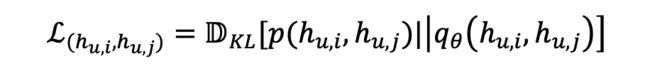
总结来说,通过上述操作可以实现不同语义空间能够捕捉到极其不同的语义,为我们解耦模型埋下铺垫。同时我们将上述控制变量之间互信息即作为正则化项的方式称之为宏观解耦。宏观解耦很大程度上保证了各语义空间都具有显著的代表性与独特性。
4.6 动态打分
语义嵌入水平预测:打分函数本文采用现有三类经典打分函数。后续实验证明我们模型可以适配于多种有代表性的打分函数且均有显著提升,此部分我们以常见的 ConvE 模型为例:
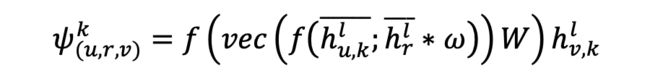
其中,, 代表着原有的 重造后的 2D 表征结果。* 即为卷机操作。整个公式用于衡量给定三元组第 k 语义空间中的有效性预测概率。
关系感知融合:为了使本文模型能够适应于给定模型,我们在解码器部分之后加入了注意力评分模块 。我们假设,在关系感知语义子空间当中,最佳匹配当前语义环境的语义表征应当“更接近于”该语义空间中连接边的表征。
举例来说,我们认为询问(科比,球队队员,?)该残缺三元组时,我们模型应当更多关注从“职业”主题相关的邻居中聚合邻近信息。而职业主题邻居关系包含多个近似三元组,其中如(科比,球员号码,24)、(科比,位置,得分后卫)将和“球队队员”该连接边具有“更密切”的联系与相似性。因此,通过关系感知聚合模型共享语义映射矩阵 ,可以帮助我们彻底将不同语义子表征进行拆分,并且有效进行分离与计算。

其中 与 分别代表着经历过 L 层信息传播后,实体与边第 k 子语义空间的最终嵌入表征。最终预测结果如下:
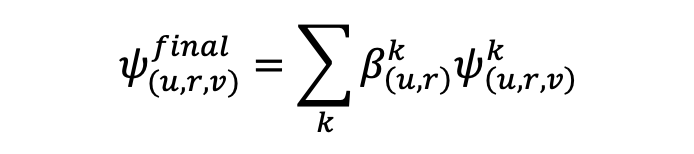

实验分析
本文数据集采用图谱补全两个最为通用的数据集:FB15k-237 以及 WN18RR。
5.1 主实验
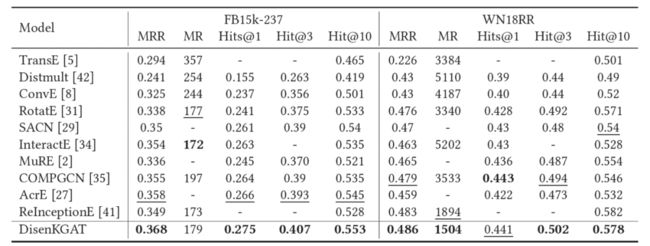
整体效果上,本模型较现有模型有明显提升,其中针对与本文最相近的 Baseline(COMPGCN),本模型在 F15k-237 上效果突出,而 WN18RR 上 mean rank 指标提升更为显著。这与本文动机相符:即 Freebase 数据集拥有 237 种类型边,具有更为丰富的语义信息,适合解耦;而 WN18RR 数据集边类型为 11 种,可分为上下位与同义词两种类型,语义单一。
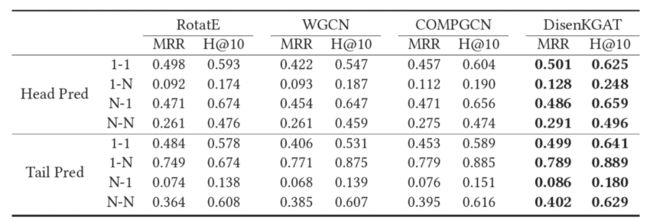
将边的类型分成一对一、一对多、多对一以及多对多分析,GCN-based 模型(WGCN 与 COMPGCN)由于融合了图结构信息,其在复杂类型边上效果显著,而 RotatE 可以有效建模识别出关系模式中对称/反对称、反转和合成等四种结构关系,对于简单类型边(一对一)效果更好。本模型依靠动态化建模能力其无论是简单类型边还是复杂类型边都有显著提升。
5.2 消融实验
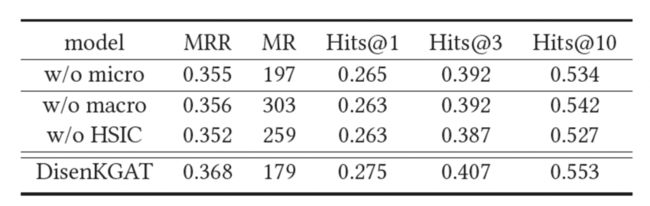
无微观解耦效果下降显著,主要是缺少多子语义表征嵌入以及动态性聚合帮助其生成包含“簇”(主题)的邻居子集,模型退化为一般的基于 GCN 的图谱补全模型。无宏观解耦,则无法保证子语义表征的分离与差别化,实验中发现无独立性限制会到导致其自身训练过程中信息再次杂糅耦和,丧失解耦意义。
更换其他独立性正则项(如 HISC),效果下降更为明显,即知识图谱的独特性。
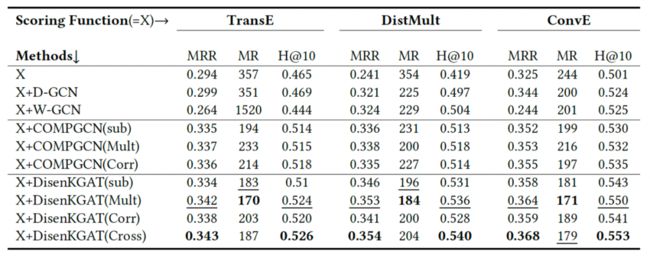
本模型作为知识图谱解耦表征框架,可适配多种打分函数与融合方式,均有显著提升。
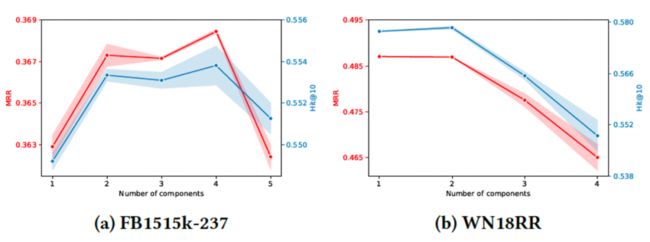
为探究不同数据集子语义 K 值影响,调整k值发现:FB15k-237 由于丰富的语义关系,其呈现先升后降的趋势。当 K 值过大,我们认为主题数量过多将导致主题划分过于精细化,细粒度过深,无法保证每个隐因子携带其关键信息,并且造成信息融合过拟合了 。WN18RR 由于语义简单,因此 k 值增大效果持续下降。
5.3 案例分析
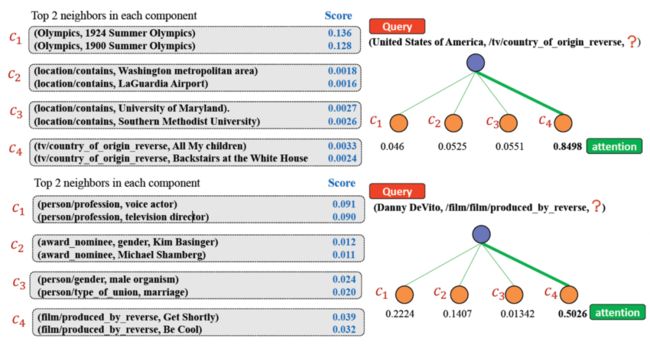
我们还分析了不同实体子语义权重最高的两个邻居信息,实验发现各个语义有较强的主题信息,且不同主题具有显著差异性。同时由于不同语义(通道)信息彼此共享,因此两个相关联实体在部分语义主题一致。

总结
在此工作中,我们分析了现有图谱补全的劣势,尝试通过解耦的角度对其进行分析建模,同时提出了一种图谱解耦表征学习框架(DisenKGAT)。其同时考虑了微观解耦与宏观解耦两方面,且模型可较为灵活的融入现有各种模型。从可解释性方面,本模型均展现了不错的优势。

参考文献
[1] Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for semantic role labeling. arXiv preprint arXiv:1703.04826(2017)
[2] Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, IvanTitov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European semantic web conference. Springer, 593–607.
[3] Chao Shang, Yun Tang, Jing Huang, Jinbo Bi, Xiaodong He, and Bowen Zhou.2019. End-to-end structure-aware convolutional networks for knowledge base completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33.3060–3067.
[4] Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha Talukdar. 2019.Composition-based multi-relational graph convolutional networks. ICLR2020.
[5] Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun Zhao. 2015. Knowledge graph embedding via dynamic mapping matrix. In ACL2015
[6] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. AAAI2016.
[7] Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. AAAI2015
[8] Quan Wang, Pingping Huang, Haifeng Wang, Songtai Dai, Wenbin Jiang, JingLiu, Yajuan Lyu, Yong Zhu, and Hua Wu. 2019. Coke: Contextualized knowledge graph embedding. arXiv preprint arXiv:1911.02168(2019).
[9] Jiawei Sheng, Shu Guo, Zhenyu Chen, Juwei Yue, Lihong Wang, Tingwen Liu, and Hongbo Xu. 2020. Adaptive Attentional Network for Few-Shot Knowledge Graph Completion. arXiv preprint arXiv:2010.09638(2020).
[10] Jianxin Ma, Peng Cui, Kun Kuang, Xin Wang, and Wenwu Zhu. 2019. Disentangled graph convolutional networks. In International Conference on Machine Learning. PMLR, 4212–4221.
[11] Yanbei Liu, Xiao Wang, Shu Wu, and Zhitao Xiao. 2020. Independence promoted graph disentangled networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 4916–4923.
[12] Shuai Zheng, Zhenfeng Zhu, Zhizhe Liu, Shuiwang Ji, and Yao Zhao. 2021. Adversarial Graph Disentanglement. arXiv preprint arXiv:2103.07295(2021).
[13] Yifan Wang, Suyao Tang, Yuntong Lei, Weiping Song, Sheng Wang, and MingZhang. 2020. DisenHAN: Disentangled Heterogeneous Graph Attention Network for Recommendation. CIKM2020.
[14] Pengyu Cheng, Weituo Hao, Shu yang Dai, Jiachang Liu, Zhe Gan, and Lawrence Carin. 2020. CLUB: A Contrastive Log-ratio Upper Bound of Mutual Information. 2020ICML.
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
