DytanVO:Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments 论文阅读
论文信息
题目:DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
作者:Shihao Shen, Yilin Cai, Wenshan Wang
来源:arXiv
时间:2023
Abstract
基于学习的视觉里程计(VO)算法受益于大容量模型和大量注释数据,在常见的静态场景中取得了显着的性能,但在动态、人口稠密的环境中往往会失败。
语义分割主要用于在估计相机运动之前丢弃动态关联,但代价是丢弃静态特征,并且很难扩展到看不见的类别。
在本文中,我们利用相机自我运动和运动分割之间的相互依赖,并表明两者可以在一个基于学习的框架中共同完善。
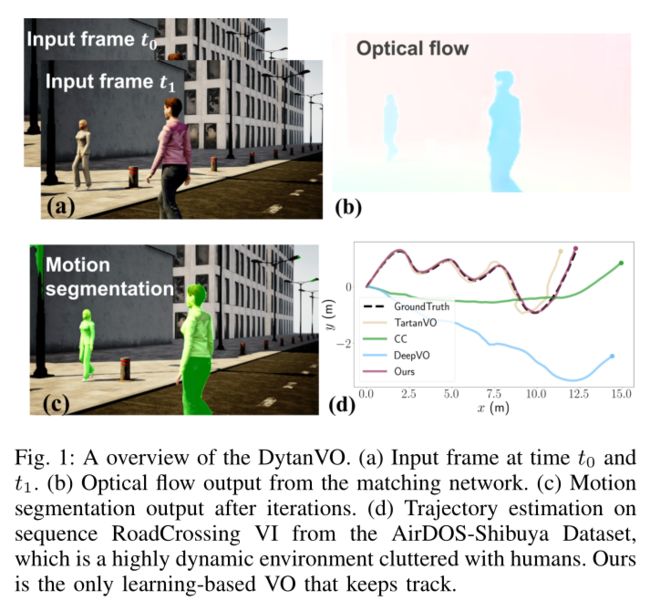
特别是,我们提出了 DytanVO,这是第一个处理动态环境的基于监督学习的 VO 方法。它实时获取两个连续的单目帧,并以迭代方式预测相机的自我运动。
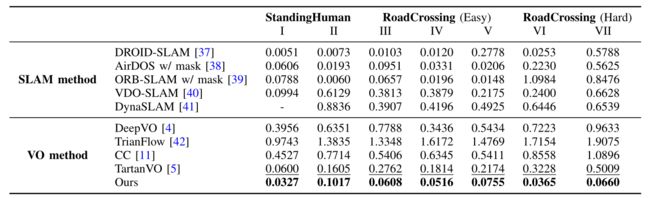
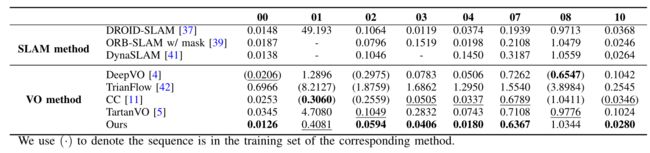
在现实动态环境中,我们的方法在 ATE 方面比最先进的 VO 解决方案平均提高了 27.7%,甚至在优化后端轨迹的动态视觉 SLAM 系统中具有竞争力。
Introduction
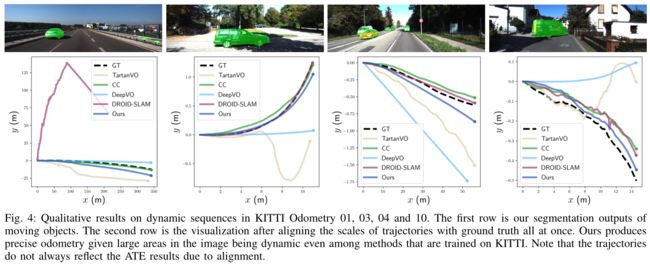
最近基于学习的方法[4]-[7]能够在更具挑战性的环境中胜过基于几何的方法,例如大运动、雾或雨效应以及缺乏特征。然而,如果不考虑独立移动的物体会导致照明或遮挡发生不可预测的变化,它们在动态环境中很容易失败。
为此,最近的工作利用大量的未标记数据,并采用自监督学习[8]、[9]或无监督学习[10]、[11]来处理动态场景。尽管它们在自动驾驶等特定任务上取得了出色的性能,但如果应用于非常不同的数据分布,例如微型飞行器(MAV),其运行时会进行汽车所不具备的激进且频繁的旋转,那么它们会产生更糟糕的结果。由于简单运动模式的数据存在偏差,无监督学习的泛化受到阻碍。因此,我们将动态 VO 问题作为监督学习来处理,以便模型可以将输入映射到复杂的自我运动基本事实,并且更具概括性。
为了识别动态物体,很大程度上依赖于物体检测或语义分割技术来掩盖所有可移动物体,例如行人和车辆[12]-[15]。在应用基于几何的方法之前,它们的关联特征将被丢弃。然而,在动态 VO 中利用语义信息存在两个问题。首先,用于语义分割的特定类别检测器在很大程度上依赖于外观线索,但并非每个可以移动的对象都存在于训练类别中,从而导致漏报。
其次,即使场景中的所有移动对象都在类别内,算法也无法区分“实际移动”与“静态但能够移动”。在动态 VO 中,静态特征对于鲁棒的自我运动估计至关重要,人们应该基于纯运动(运动分割)而不是启发式外观线索来分割对象。
运动分割利用连续帧之间的相对运动来消除 2D 运动场中相机运动的影响,并计算剩余光流以考虑运动区域。但矛盾的是,如果没有强大的分割,就无法在动态场景中正确估计自我运动。运动分割和自我运动估计之间存在着这种相互依赖,这种依赖在监督学习方法中从未被探索过。
• 引入了一种新颖的基于学习的VO,以利用相机自我运动、光流和运动分割之间的相互依赖性。
• 我们引入了一个迭代框架,其中自我运动估计和运动分割可以在实时应用的时间限制内快速收敛。
• 在基于学习的 VO 解决方案中,我们的方法无需微调即可在现实动态场景中实现最先进的性能。此外,我们的方法的性能甚至可以与优化后端轨迹的视觉 SLAM 解决方案相媲美。
Methodology
Dataset
基于 TartanVO [5] 构建的数据集,我们的方法在处理多种类型场景(例如汽车、MA V、室内和室外)的动态环境时保持其泛化能力。
除了将相机内在函数作为网络的额外层以适应[5]中探讨的各种相机设置之外,我们还根据具有广泛多样性的大量合成数据来训练我们的模型,这被证明能够促进轻松适应现实世界[27]-[29]。
我们的模型在 TartanAir [27] 和 SceneFlow [30] 上进行训练。前者包含超过 400,000 个数据帧,仅包含静态环境中的光流和相机姿态的地面实况。后者在高度动态的环境中提供 39,000 帧,每个轨迹都具有向后/向前传递、不同的对象和运动特征。
Architecture
我们的网络架构如图2所示
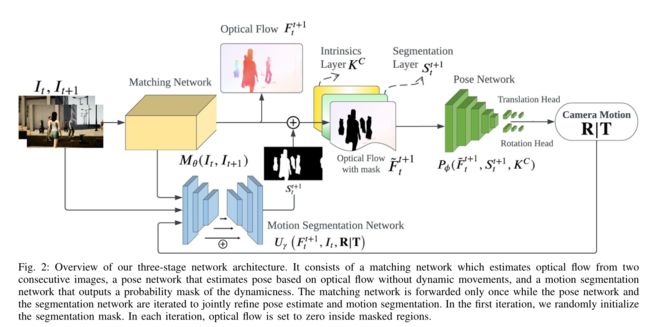
它是基于TartanVO的。我们的方法采用两个连续的未失真图像 I t 、 I t + 1 I_t、I_{t+1} It、It+1 并输出相对相机运动 δ t t + 1 = ( R ∣ T ) δ^{t+1}_t = (R|T) δtt+1=(R∣T),其中 T ∈ R 3 T ∈ R^3 T∈R3 是 3D 平移, R ∈ S O ( 3 ) R ∈ SO(3) R∈SO(3) 是 3D 旋转。
我们的框架由三个子模块组成:匹配网络、运动分割网络和姿势网络。
我们使用匹配网络 M θ ( I t , I t + 1 ) M_θ (I_t, I_{t+1}) Mθ(It,It+1) 从两个连续图像估计密集光流 F t t + 1 F_t^{t+1} Ftt+1。该网络是基于PWC-Net[31]构建的。
运动分割网络 U γ U_γ Uγ 基于轻量级 U-Net [32],输入包括:相对相机运动输出、 R ∣ T R|T R∣T、基于 M θ M_θ Mθ 的光流以及原始输入帧。它输出属于或不属于动态对象的每个像素的概率图 z t t + 1 z^{t+1}_t ztt+1 ,该概率图经过阈值处理并转换为二进制分割掩模 S t t + 1 S^{t+1}_t Stt+1 。然后将光流与掩模和本征层 K C K^C KC堆叠,再将掩模区域内的所有光流设置为零,即 F t t + 1 F^{t+1}_t Ftt+1 。
最后一个是姿态网络 P ϕ P_\phi Pϕ,以 ResNet50 [33] 作为主干,它接收前面的堆栈,并输出相机运动
Motion segmentation
早期使用运动分割的动态 VO 方法依赖于对极几何和刚性变换 [12]、[26] 产生的纯粹几何约束,以便它们可以对旨在考虑移动区域的残余光流进行阈值处理。然而,在两种情况下它们很容易出现灾难性的失败:
(1)仅在单目线索的情况下,无法从背景中识别 3D 中沿极线移动的点;
(2)纯几何方法无法容忍噪声光流和不太准确的相机运动估计,这在我们的框架中很可能在前几次迭代中发生。
因此,根据[34],为了处理上述歧义,我们在通过光学扩展[35]将2D光流升级为3D后,将成本图明确建模为分割网络的输入,根据尺度变化估计相对深度重叠的图像块。成本图针对共面和共线运动模糊性进行定制,这些模糊性会导致基于几何的运动分割中的分割失败。
Interactive refine camera motion(迭代细化相机运动)
我们在算法 1 中概述了迭代框架。在推理过程中,匹配网络仅转发一次,而姿态网络和分割网络则迭代以共同细化自我运动估计和运动分割。在第一次迭代中,分割掩模使用[36]随机初始化。

停止迭代的标准很简单,就是两次迭代之间的 R|T 的旋转和平移差异小于预设阈值 β。我们没有将固定常数阈值概率映射到分割掩码中,而是预先确定一个衰减参数,该参数随着时间的推移凭经验降低输入阈值,以阻止早期迭代中不准确的掩码,同时在以后的迭代中采用精致的掩码。
直观上,在早期迭代期间,估计的运动不太准确,这导致分割输出中出现误报(将高概率分配给静态区域)。然而,由于光流图仍然提供足够的对应关系,无论从中删除非动态区域, P ϕ P_\phi Pϕ 都能够稳健地利用与 F t t + 1 F^{t+1}_t Ftt+1 连接的分割掩模 S t t + 1 S^{t+1}_t Stt+1 ,并输出合理的相机运动。在以后的迭代中, U γ U_γ Uγ预计会输出越来越精确的概率图,使得光流图中的静态区域不再“浪费”,因此 P ϕ P_{\phi} Pϕ可以相应提高。

在实践中,我们发现 3 次迭代足以细化相机运动和分割。为了消除任何歧义,1 次迭代过程由一次 M θ M_θ Mθ 前向过程和一次具有随机掩码的 P ϕ P_{\phi} Pϕ 前向过程组成,而 3 次迭代过程由一次 Mθ 前向过程、两次 U γ U_γ Uγ 前向过程和 3 个 P ϕ P_{\phi} Pϕ 前向过程组成。
Supervision
我们训练我们的姿势网络,使其能够抵抗大面积的误报。在没有任何动态对象的训练数据上,我们采用cow-mask[36]来创建足够随机但局部连接的分割模式,因为运动分割可以在图像中的任何尺寸、任何形状和任何位置发生,同时表现出局部可解释的结构与移动物体的类型相对应。此外,我们将 curriculum learning 应用到姿势网络中,逐渐将 SceneFlow 中动态区域的最大百分比从 15%、20%、30%、50% 增加到 100%。由于 TartanAir 仅包含静态场景,因此我们相应地调整牛面具的大小。
我们在相机运动损失 LP 上监督我们的网络。
在单目设置下,我们只能恢复最大尺度的相机运动。我们按照[5],在计算到地面实况的距离之前对平移向量进行归一化。给定地面真实运动 R ∣ T R|T R∣T:

我们的框架也可以以端到端的方式进行训练,在这种情况下,目标变成光流损失 L M L_M LM 、相机运动损失 L P L_P LP 和运动分割损失 L U L_U LU 的聚合损失,其中 L M L_M LM 是之间的 L1 范数预测流和地面真实流,而 L U L_U LU 是预测概率和分割标签之间的二元交叉熵损失。
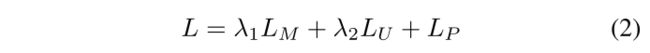
Experiment