Pytorch学习笔记:ResNet
Pytorch学习笔记:ResNet
- 1.残差块
- 2.残差网络结构
-
- 2.1 虚线与实线连接
- 2.2 Batch Normalization
- 3.网络搭建
-
- 3.1 18,34层网络的残差块
- 3.2 50,101,152层网络的残差块
- 3.3 ResNet的搭建
-
- 3.3.1 conv_1的搭建
- 3.3.2 _make_layer构建conv_2-conv_5
- 4.训练文件
主要参考b站up霹雳吧啦Wz视频,感谢up主做的极其详细并对小白友好的精彩分享。
代码来自up主的Github仓库开源项目,侵权删。
1.残差块
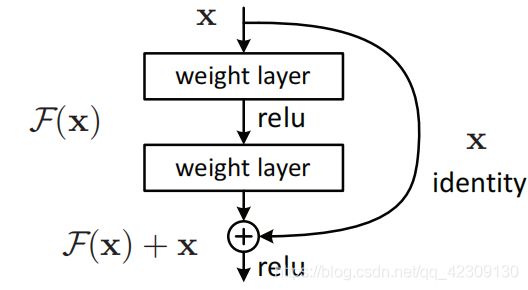
输入为X,前馈输出F(X)与一条直连通道的值X进行汇合相加后F(X)+X->H(X),经过RELU激活层获得最终输出。
一种比较能接受的解释:
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如原来是从5.1到5.2,映射F’的输出增加了1/51=2%,而对于残差结构从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整影响更大(因为基数更小),所以效果更好。解释的传送门
残差块的提出是为了解决网络退化问题,显然从上面的分析可知,残差的学习会比原来的映射学习更容易,从而能够训练更深的网络。
2.残差网络结构
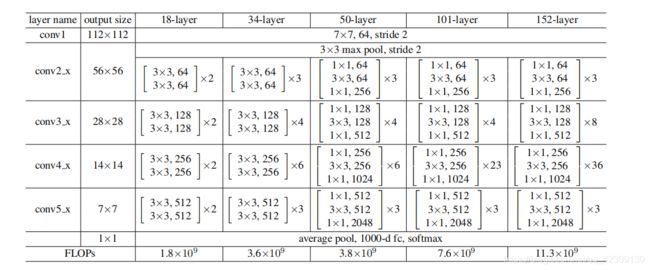
残差网络由conv1,conv2_x,conv3_x,conv4_x,conv5_x五层组成,通过调整conv2_x,conv3_x,conv4_x,conv5_x中残差块的数量即可搭建不同深度的残差网络。
由上表可知,18层和34层ResNet的残差块是由双卷积层构成的,并且两层卷积核的个数一致,不同类型的块之间过渡时,图像的宽高减半,深度加倍。50层,101层和152层ResNet的残差块是由三卷积层构成的,首尾是1×1卷积层,中间是3×3卷积层,因为引入1×1卷积可以降维,所以在搭建更深的网络时用选用这种类型的残差块会更好,三层残差块的前两个卷积层深度相同,第三个卷积层深度是之前的4倍,不同类型的块之间过渡时,宽高减半,深度减半。两种残差块的结构如下图所示。
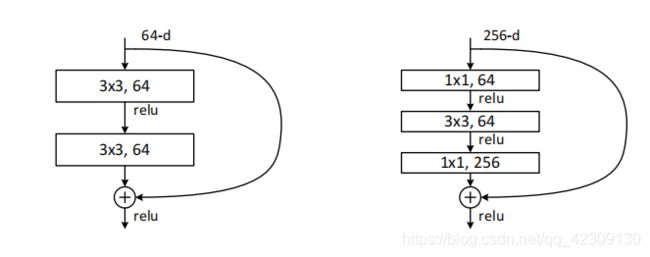
| 残差块 | 双层型 | 三层型 |
|---|---|---|
| 块内层数 | 2 | 3 |
| 层间深度变化 | 翻倍 | 减半 |
| 层间size变化 | 减半 | 减半 |
| 层内块深度变化 | 不变 | 前两层不变,第三层翻4倍 |
层间是指从conv_2过渡到conv_3层这种跨层的变化,层内是指conv_2,3,4,5层内参数一样(实线虚线可能不一样)的残差块间过渡,层内块深度变化是指conv_2,3,4,5中的残差块的每个卷积层的深度,即卷积核个数的变化。
2.1 虚线与实线连接
虚线表示不能直连,直线表示可以输入可以通过直连通道直接与输出相加。在conv_3,conv_4,conv_5的结构中,为了统一直连通道与前馈通道的尺寸与深度,第一个残差块总是虚线连接。
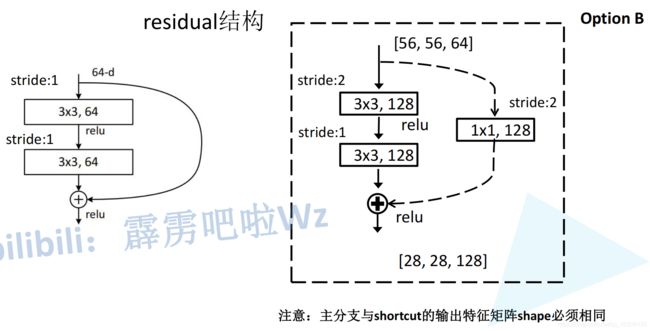
上图右图为conv_3中的两层残差块(18,34层网络模块)的虚线连接,输入的图像为[64,56,56],输出为[128,28,28],故在直连通道首先要进行长宽的压缩,其次要进行深度的扩展,使用步长为2,尺寸为1的128个卷积核可实现。此外,前馈通道中也要使用步长为2的卷积核来压缩尺寸,如第一层卷积层。当在conv_3中继续传播时,通过padding操作可以对齐尺寸,深度也均已调整为128,故后续采用实线连接残差块即可。
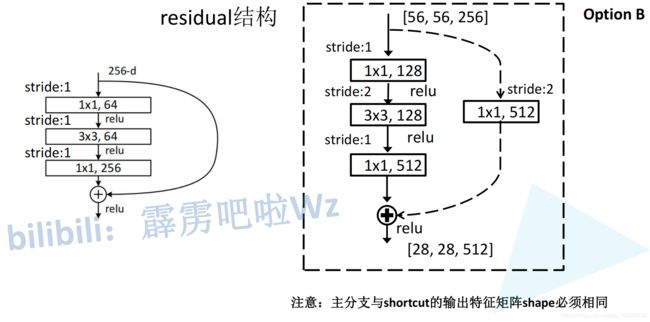
上图右图为conv_3中的三层残差块(50,101,152层网络模块)的虚线连接,输入的图像为[256,56,56],输出为[512,28,28],故在直连通道首先要进行长宽的压缩,其次要进行深度的扩展,使用步长为2,尺寸为1的512个卷积核可实现。此外,前馈通道中也要使用步长为2的卷积核来压缩尺寸,如第二层卷积层。当在conv_3中继续传播时,通过padding操作可以对齐尺寸,深度也均已调整为512,故后续采用实线连接残差块即可。
2.2 Batch Normalization
如同机器学习进行数据标准化,深度学习中也存在Batch Normalization草做,以每个batch为单位,对一个batch中的所有图像的每个channel分别求均值和标准差用于标准化,加速收敛,具体说明见如下传送门。该操作通常用于卷积与激活层之间,
Batch Normalization传送门
3.网络搭建
3.1 18,34层网络的残差块
图解实线与虚线区别见2.1章节,该模块要能通过参数设定同时起到实线与虚线连接的功能。
class BasicBlock(nn.Module):
expansion = 1
#expansion是与三层残差块对应,三层残差块的最后一层深度会翻4倍
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
"""
传入参数包括输入图像的深度,输出图像的深度,卷积步长默认是1,是否进行下采样
"""
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
#两层型残差块的卷积核深度即为输入图像的深度,卷积核个数即为输出的深度,且均为3*3卷积核
#第一层的卷积核步长当进行下采样时为2,故这里定为stride
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
几点说明:
1.该残差结构要能实现虚线与实线的功能,通过downsample控制是否进行下采样,如果不为None则要进行下采样(表示虚线结构),为None则为实线结构。
2.BatchNorm2d要先填入channel数初始化,并且加在卷积与池化层之间,在第二个卷积层进行输出时要先把前馈与直连通道相加再通过ReLU层。
3.虚线结构与实线结构的第一层卷积层的步长不同,必须是可调整的参数,默认参数设置为1,采用虚线连接时设置为2。
3.2 50,101,152层网络的残差块
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
#取4是因为第三层的深度会翻4倍
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
#out_channel是指第1,2层的深度,width_per_group是指?,其余与2层残差块一致
width = int(out_channel * (width_per_group / 64.)) * groups
#width是指一通计算以后第1,2层的深度,理论上应该与out_channel相等
"""
算例:以conv_3实线结构为例
"""
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
#第二层的卷积核步长当进行下采样(虚线连接)时为2,故这里定为stride
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
#第三层要注意深度翻4倍
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
几点说明:
1.虚线结构与实线结构的第二层卷积层的步长不同,必须是可调整的参数,默认参数设置为1,采用虚线连接时设置为2,其余层步长均为1。
2.根据Python面向对象的规则,在类内声明expansion变量后,类内的函数使用该变量即调用self.expansion。
3.3 ResNet的搭建
3.3.1 conv_1的搭建
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
"""
block:残差块的类型
blocks_num:每个conv_x(x=1,2,3,4)layer,对应conv_2,conv_3,conv_4和conv_5中的残差块数量
num_classes:类别数量
include_top:此处暂时不管
width_per_group:不用管
"""
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
上半段代码完成了对conv_1的搭建,并通过_make_layer函数完成对conv_2-conv_5的搭建,并对每个卷积层权重采用kaiming初始化,同时根据自定义类别对全连接层进行初始化。_make_layer是一个输入block类型,channel(第一层卷积核的个数),block_num(块的数量)以及卷积步长来进行网络搭建的类内函数,下面介绍该函数。
3.3.2 _make_layer构建conv_2-conv_5
def _make_layer(self, block, channel, block_num, stride=1):
#这里的channel是第一层的卷积核个数,block_num是块数
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
通过if stride != 1 or self.in_channel != channel * block.expansion来判断是否构建下采样层,条件为步长不为1或者输入输出通道数不一致(18,34残差块与50,101,152残差块),两层残差块与三层残差块的扩展因子分别为1和4,故三层残差块在输入时会被检测到输入输出通道数不一致从而添加一个虚线连接。经过虚线连接后输出的特征图的形状参数已被调整好,经过该layer的后续同类型残差块后形状参数不再发生变化,也就不再需要虚线连接。
使用_make_layer函数时,只需要给定残差块的类型,是否需要增加虚线连接(通过设置步长以及残差块的类型来决定),并给出残差块第一层卷积层的深度,即可完成一个layer的搭建。
在构建ResNet34时残差块取BasicBlock, conv_x(x=2,3,4,5)的残差块数量分别为[3, 4, 6, 3],该指令传到ResNet类中,调用以下四条命令。
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
对于conv2,因为前馈通道的输出特征图尺寸和深度与输入保持一致,不需要虚线连接。对于conv_3,第一个残差块的前馈通道的输出特征图尺寸和深度与输入不一致,故需要进行虚线连接(下采样),使得该层第一个残差块的输出形状参数等于该层的最终输出,从而可以采用直连。对conv_4,5的分析同理。
前向传播代码:
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
最后是34层与50层残差网络的搭建命令。
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
4.训练文件
因为直接训练ResNet比较困难,所以通常会采用迁移学习来进行网络的训练。
先下载在ImageNet上训练好的ResNet34的权重并载入模型,但是预加载的模型是一个1000分类的模型,而我们实验所用的数据是一个5分类的简单数据集,需要进行如下修改:
#加载模型参数
net.load_state_dict(torch.load(model_weight_path, map_location=device))
in_channel = net.fc.in_features#获取最后一个全连接层的输入深度
net.fc = nn.Linear(in_channel, 5)#修改全连接层的输出向量长度为5,因为花分类数据集就5类
params = [p for p in net.parameters() if p.requires_grad]#初始化优化器
optimizer = optim.Adam(params, lr=0.0001)
即可进行迁移学习,并且当第一个epoch迭代完毕时,分类精度已经达到90%!

充分展示了迁移学习的强大能力。预测文件同之前的网络。