Python Pandas操作
文章目录
-
- 一、索引操作
- 二、四则运算
- 三、Pandas画图
- 四、文件读取与存储
- 五、缺失值处理
- 六、去重
- 七、数据离散化
- 八、数据合并
- 九、交叉表与透视表
- 十、分组聚合
- 十一、写入Excel不同Sheet页
一、索引操作
针对DataFrame的索引,有三种检索方式:
- 直接使用索引值;
- loc:先行后列,索引值
- iloc:先行后列,索引值的下标
首先创建一个DataFrame
df = pd.DataFrame({
"class":[1,2,3],
"name":['john','mary','sam'],
'age':[18,19,20]
},index=['class1','class2','class3'])
df['class']['class1']
df.loc['class1':'class2','name']
df.iloc[:2,:]
二、四则运算

算术运算
某列值加10
data['close'].add(10).head()
逻辑运算
\>、\<、|、&
data['open'] > 20 #返回的是布尔型
data[data['open'] > 20] #返回值
#考虑到优先级问题,在进行多次判断时,需要加上括号
data[(data['open'] > 20) & (data['open'] < 24)]
逻辑运算函数
data.query('open<24 & open >20').head()
#判断值是否在指定列中,返回的是布尔值
data['open'].isin([23.53,23.85])
data[data['open'].isin([23.53,23.85])]
统计运算
data.sum() #求和
data.median() #计算中位数
data.mean() #平均值
data.mode() #众数
data.idxmax() #最大值索引
data.idxmin() #最小值索引
累计统计函数
cumsum -->计算前1/2/3/.../n个数的和
cumprod -->计算前1/2/3/.../n个数的积
cummax -->计算前1/2/3/.../n个数的最大值
cummin -->计算前1/2/3/.../n个数的最小值
stock_rise = data['p_change']
#统计价格
stock_rise = stock_rise.cumsum()
#可以直接使用plot进行绘图
stock_rise.plot()
plt.show()
自定义运算
apply + lambda
data[['open','close']].apply(lambda x:x.max()-x.min(),axis = 1)
三、Pandas画图
kind:指定图类型
DataFrame.plot(x=None,y=None,kind='line')
line --> 折线图
bar --> 条形图
barh --> 旋转条形图
hist --> 直方图
pie --> 饼图
scatter --> 散点图
四、文件读取与存储
csv
读取
DataFrame.read_csv(path=None,seq=',',usecols=)
seq:指定分隔符,默认’,';
usecols:指定读取的列名,列表形式
例如:
pd.read_csv('./stock_day.csv',usecols=['open','high'])
写入
#指定写入的列,是否需要索引列
data2[:10].to_csv('./test.csv',columns=['open'],index=False)
HDF5
有限选择使用HDF5文件存储:
- HDF5在存储时支持压缩,使用的方式是blosc,这个是速度最快也是pandas默认支持的;
- 使用压缩可以提高磁盘的利用率,节省空间;
- HDF5还是跨平台的,可以轻松迁移到hadoop上使用;
读取
pandas.read_hdf(path_or_buff,key=None,**kwargs)
key:读取的键
写入
保存的文件是 xxx.h5格式
to_hdf(path,key)
JSON
读取
pd.read_json()
写入
对象.to_json()
在进行写入和读取时,需要注意的参数:
orient:按照指定方式进行读写
lines:是否按照行读取和写入,一般为True。
五、缺失值处理
判断是否有缺失值
#检验DataFrame中是否有缺失值,有的话,返回True
np.any(df.isnull())
#检验DataFrame中是否有缺失值,有的话,返回False
np.all(df.notnull())
删除缺失值:dropna()
df.dropna()
替换缺失值:fillna(value,inplace=True)
inplace:是否在原数据(DataFrame)上替换。
1.缺失值为空值的:None
#以平均值填充
df["Revenue (Millions)"].fillna(value=movie["Revenue"].mean(),inplace=True)
针对数据量过多,无法判断缺失值在哪一列时:
#遍历各列,找出存在null值的列替换:
for i in movie.columns:
if np.any(movie[i].isnull()) == True:
#print(i)
movie[i].fillna(value =movie[i].mean(),inplace=True)
2.缺失值是其他符号
把符号替换为None后处理
df= df.replace(to_replace="?",value=np.NaN)
六、去重
df["Director"].unique()
df["Director"].drop_duplicates()
七、数据离散化
含义:根据数据的属性,把其划分为不同的离散区间,用符号或者整数代表每个区间的属性。
例如:

转换为:

这里以股票涨跌幅为例:

pd.qcut(data,q):
a.对数据进行分组将数组分组,一般会与value_counts搭配使用,统计每组的个数;
b.q:大致分为多少组
c.series.value_counts():统计分组次数
自动分组:
#将股票涨跌幅数据进行分组
data_p = data["p_change"]
qcut_r = pd.qcut(data_p,10)
#每组的个数
qcut_r.value_counts()
自定义分组:
#指定分组间隔
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
#分组
cut_r = pd.cut(data_p,bins=bins)
#计算分组后的各组个数
cut_r.value_counts()
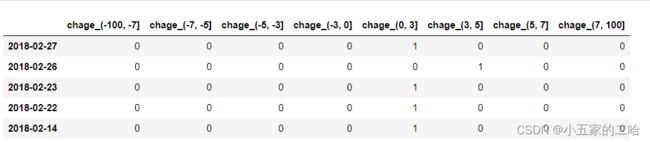
股票涨跌幅分组数据变成one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1,所以又称为热编码。
pd.get_dummies(data,prefix=None)
prefix:给各列标题附加一个前缀,用’_'拼接。
pd.get_dummies(cut_r,prefix="change")
八、数据合并
pandas.concat([data1,data2],axis=1)
axis=1:列合并 -->类似于SQL中的 join
axis=0:行合并 -->类似于SQL中的 union() (默认)
pandas.merge(left,right,how='inner',on=None,left_on=None,right_on=None)
how:连接方式:left,right,inner(默认),outer。
对应SQL中的join方式:
left --> left join
right --> right join
inner --> join
outer --> full join
九、交叉表与透视表
pd.crosstab()–>返回具体数量
对象.pivot_table()–>返回占比情况
#把Object类型的时间,转换为时间格式
time = pd.to_datetime(data.index)
#找到对应日期为周几
data['week'] = time.weekday
#根据判断赋值:如果大于0,为1;小于0,为0
data['p_n'] = np.where(data['p_change']>0,1,0)
#交叉表:pd.crosstab()-->返回具体数量
count = pd.crosstab(data['week'],data['p_n'])
#算数运算,先求和
sum = count.sum(axis=1)
#求百分占比:法一
per = count.div(sum,axis=0)
#stacked是否进行堆积展示
per.plot(kind="bar",stacked=True)
#求百分占比:法二。对象.pivot_table()-->返回占比情况
data.pivot_table(['p_n'],index='week')

十、分组聚合
DataFrame.groupby(key,as_index=False)
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
#按照color进行分组,对price1求平均值
col.groupby(['color'])["price1"].mean()
#找出要计算的列,转换为series类型,然后分组就平均值
col['price1'].groupby(col['color']).mean()
#分组列,是否作为index
col.groupby(['color'],as_index = False)["price1"].mean()
#多个分组
col.groupby(['color','object']).count()
需要注意的是,如果只是简单的进行分组,即col.groupby(['color'])["price1"]或者col.groupby(['color'])输出的是地址值,没有具体的数据,需要进行基本运算后(mean/count/sum等),才可以得出结果。
除此之外,如果我们想查看每个分组后的结果,我们可以遍历获取值,例如:
for i,j in col.groupby(['color']):
print('分组名称:',i)
print('分组结果:',j)
得到的结果:

十一、写入Excel不同Sheet页
一般的写入方式相信大家都已经基本掌握,这里介绍如何同时写入Excel文件中不同sheet页中的方式。
我们主要是通过pandas.ExcelWriter来保存我们需要写入的文件地址。
#首先确定要写入的文件地址。
file_path = 'D:/Test/test.xlsx'
#设置写入地址
writePath = pd.ExcelWriter(file_path,engine='xlsxwriter')
#不同文件写入。index=False:去掉索引
df1.to-excel(writePath,index=False,sheet_name='test1')
df2.to-excel(writePath,index=False,sheet_name='test2')