李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:3/3 机器学习基本概念介绍
目录
- 3/3 机器学习基本概念介绍
-
- 快速了解機器學習基本原理
- 生成式學習的兩種策略:要各個擊破,還是要一次到位
- 能夠使用工具的AI:New Bing, WebGPT, Toolformer
- Brief Introduction of Deep Learning
- Gradient Descent
- Backpropagation
- 卷積神經網路 (CNN)
- 自注意力機制 (Self-attention) (下)
3/3 机器学习基本概念介绍
快速了解機器學習基本原理
机器学习 ≈ 机器自动寻找一个函数f
例如:
chatGPT:输入:“什么是机器学习”通过函数f,输出:“机”
Midjournery:输入:一只可爱的猫,通过函数f,输出:一张猫猫图片

根据函数的输出可以分为两类:Regression(回归)与Classification(分类)
- Regression:函数的输出是一个数值
例如:输入输入今天的PM2.5值、温度、臭氧量等,输出明天的PM2.5值 - Classification:函数的输出是一个类别(选择题)
例如:判断一封邮件是否为垃圾邮件
机器学习不断发展不再局限于上述分类,而是变为了更加复杂的Structured Learning
- Structured Learning:结构化学习,又称为Generative Learning生成式学习,生成有结构的物件(如影像、文句等)(联想:生成式学习就像是全职猎人里的暗黑大陆(乐)
chatGPT属于哪类?:把生成式学习拆解成多个分类问题
寻找函数的三步骤
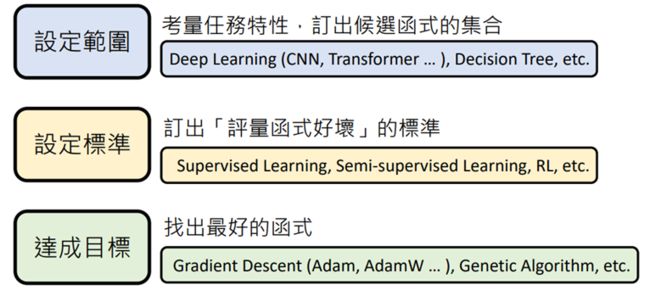
【前置作业】决定要找什么样的函数?(无关技术,取决于要做的应用)
(先放总结)
展开来讲:
-
Step1:选定候选函数的集合Model
深度学习中类神经网络的结构(如:CNN、RNN、Transformer等等)指的就是不同的候选函数集合,函数集合表示为H

目的:缩小选择的范围;技巧性强
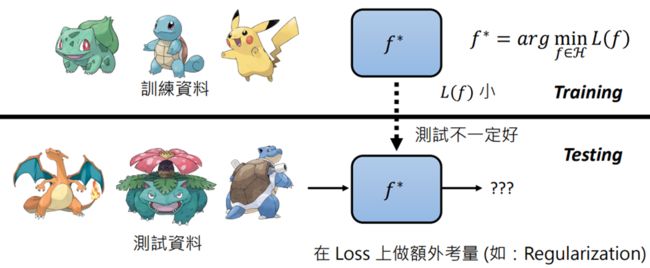
训练资料少时,L(f)小但测试差的函数就会多,这个时候画出集合范围要保守(小);反之测试数据多时,上述L(f)小但测试差的函数就会少
涉及的拓展知识:Convolutional Neural Network,CNN、Self-attention…… -
Step2:订出评价函数优劣的标准
使用函数Loss函数,将f做出输入,输入L函数:L(f),根据输出的大小,评价函数(越大越差)
L的计算过程取决于training data
常用方法:supervised Learning(全部都有标准答案),semi-supervised Learning(没有标准答案,要定义评量标准),RL(reinforcement Learning)等等
-
Step3:找出最好的函数,最佳化Optimization
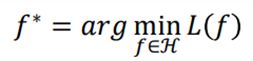
将集合H中的所有函数带入L中,寻找Loss最小值
常用方法:Gradient Descent(Adam,AdamW…),Genetic Algorithm等等
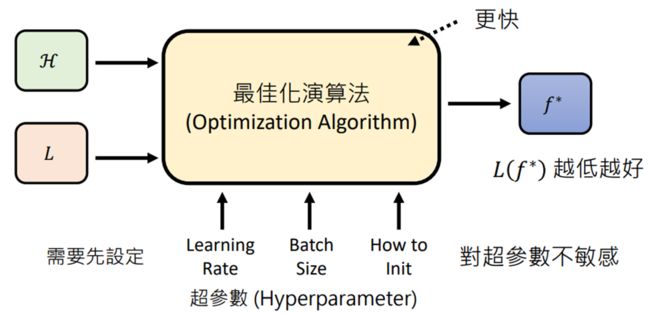
超参数:手调参数
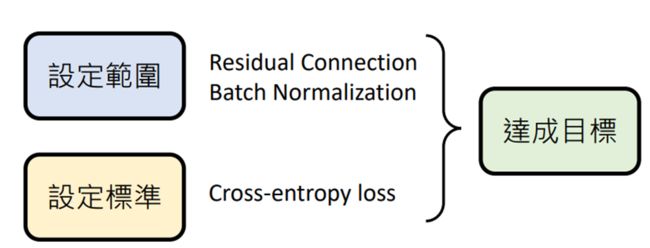
【注意】有时候每一步在选择方法时并不会选择所谓的“最优解”,原因是因为选择的方法的好是 能支援其他步骤
例如:在“设定范围“时,选择Residual Connection,虽然框选出的范围较大,但能在“达成目标”这步时选出真正最好的函数
生成式學習的兩種策略:要各個擊破,還是要一次到位
生成式学习:生成有结构的复杂物件

策略一:各个击破AR(Autoregressive Model)

策略二:一次到位NAR(Non-autoregressive Model)

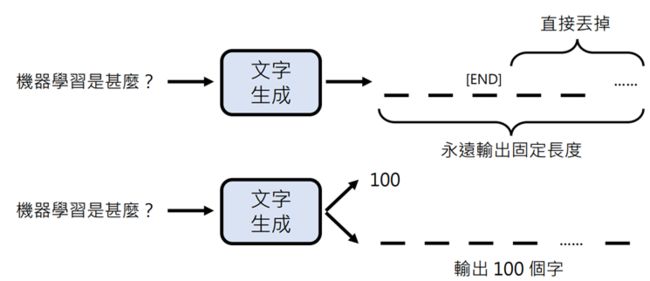
怎么保证生成固定长度的文字?
法一:若100个字前没出现终止符,直接截断
法二:先决定输出100个字,再输出
两个方式比较
- AR:速度慢,答案质量好,适合生成文字
- NAR:速度快,答案质量较差,适合生成图像
P.s.生成影像常用NAR的原因是:影像像素过多,AR太慢
结合两个方法(取长补短)
-
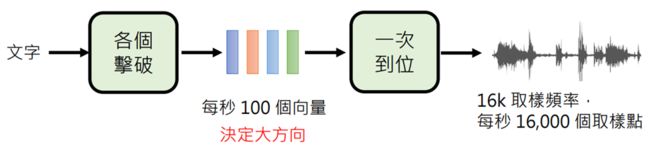
以语音合成为例:生成分为两个阶段,AR决定大方向,NAR生成最后产物
-
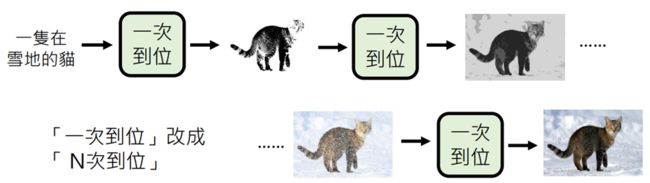
将“一次到位”改为“N此到位”(类似Diffusion Model)
能夠使用工具的AI:New Bing, WebGPT, Toolformer
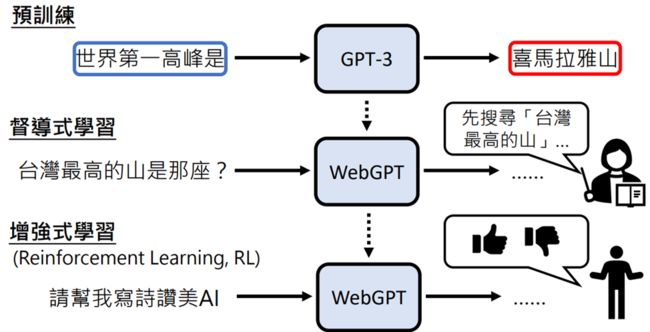
New Bing是有搜寻网络的,但什么时候进行搜寻是由机器自己决定的

没有相关论文,但有类似的WebGPT,论文地址: https://arxiv.org/abs/2112.09332
- WebGPT回答生成过程:
- 输入”Which river is longer, the Nile or the Yangtze?”(翻译:拿一条河比较长,尼罗河还是扬子江?)
- WebGPT:提取关键字(如:”Nile vs Yangtze”、”nile length”、”Yangtze length”)
- 对关键字经行网络搜索,根据算法对搜索网页资料的部分段落进行收藏(注意只收藏文字段落,而不是整个网页)
- 整理生成答案(答案后会附上引用的网址)
Toolformer:學習使用工具的 AI,可以使用多種不同的工具(如搜索网络、计算机、翻译等)

如何在没有人类示范的情况下生成大量资料?
方法一:用另一个语言模型产生资料;方法二:验证语言模型生成的结果
使用Toolformer的结果
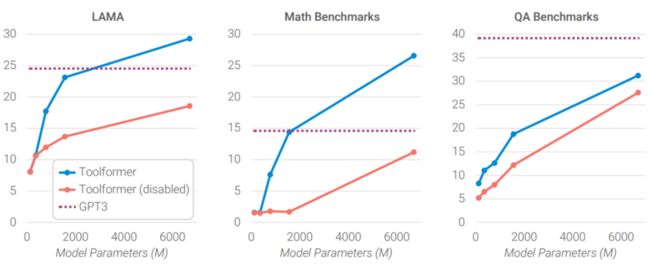
LAMA、Math Benchmarks、QA Benchmarks:data Set,问答资料集
橙线:测试时不允许呼唤API(使用工具)(保证实验的严谨性)
Brief Introduction of Deep Learning
先附上大致的时间线

简述,来自:https://blog.csdn.net/zyuPp/article/details/99288909
1958年:人们感觉人工智能要来了,因为linear model的出现,它可以做到一些稍微复杂的分类和预测问题,当时他们也叫这个技术为Perceptron,感知器
1969年:有人终于发现了linear model有缺点,研究了一下为什么“坦克与卡车”的图像分类为什么如此精确,原来是因为两组图片的拍照时间不一样,而机器是通过其亮度作为特征来分类的
1980年代:多层感知机MLP,尝试使用多层的感知机(与现在的deep learning基本没有差别)
1986年:出现了反向传播,但是发现超过3层就不太有用了
1989年:有人认为,一个隐藏层就足够成为任何的function,这段时间多层感知机被各种嫌弃,所以人们才给它换了个名字,就是深度学习
2006年:RBM initialization被认为是大突破,这个非常复杂,用于梯度下降初始化值,最后发现复杂但是没啥用
2009年:知道要用GPU来加速深度学习的模型训练
2011年:被用在语音辨识中,发现很好用
2012年:赢得了ILSVRC图像比赛,做图像的人也开始用Deep Learning(著名的AlexNet)
深度学习的三步骤:
Step1:define a set of function (function即Neural Network)
Step2:goodness of function
Step3:pick the best function
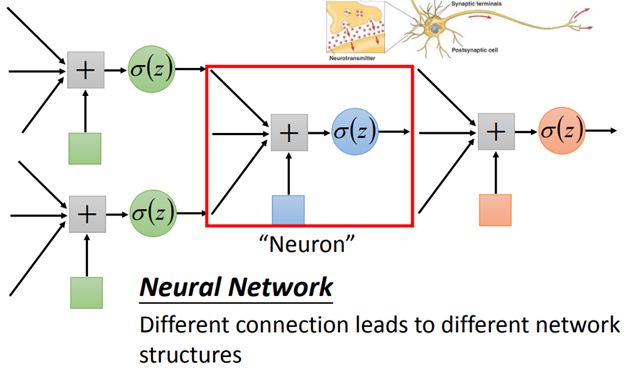
logistics regression将其连接,一个逻辑回归称为Neuron神经元,
不同的方法连接Neural Network就得到不同的结构structure,
每个logistics regression都有属于自己不同的weight权重,和bias偏移量,
weight和bias的集合称为network的函数θ
将neuron连接起来的方式有很多种(手动连接),其中
Fully Connect Feedforward Network(完全连接前馈神经网络)是最常见的
用一个最简单的示意图说明
两个输入:1,-1;6个neuron,两个一列
每个neuron都有一组weight和bias,例如蓝色(上)的weight是1与-2,bias是1
则1与-1输入后得输出为4,4通过sigmoid函数(为了将数值映射至0-1)得0.98

反复进行上述运算
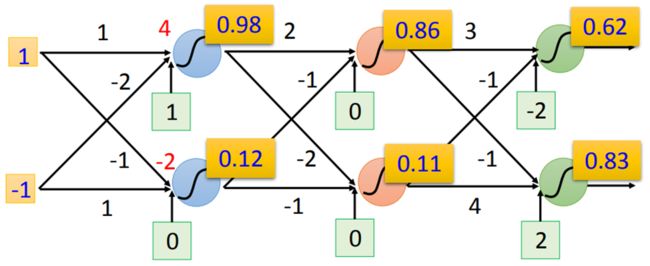
上述就是一个function,如果用向量来表示输入输出,则可得

但如果是不知道参数(weight & bias),则称为一个function set
一般化一个network的示意图
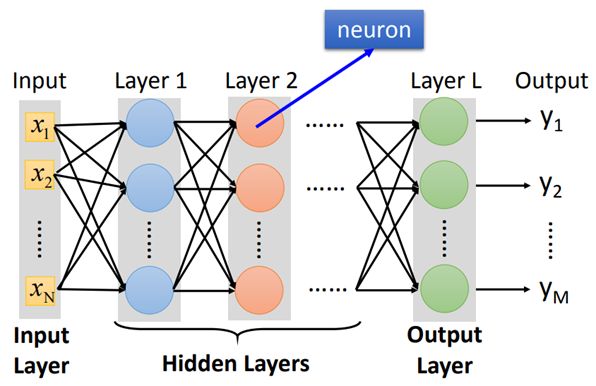
大家关于”Deep”的定义各不相同(多少层算Deep呢)一些著名的Deep Network


Matrix operation矩阵运算神经网络
将上述例子用矩阵运算表示(能提高大型运算的效率和速度)
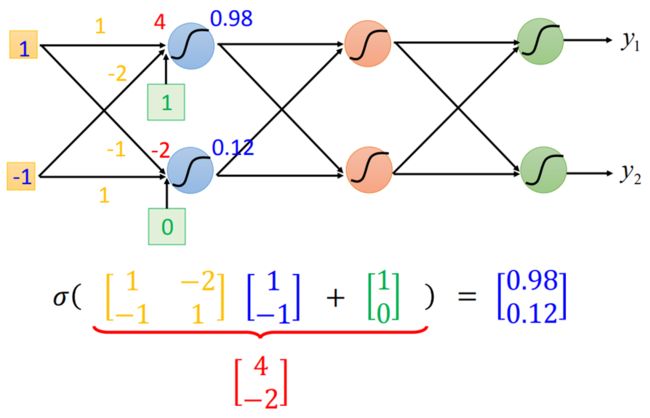
则整个neural network的运算可以等同于一连串的matrix操作
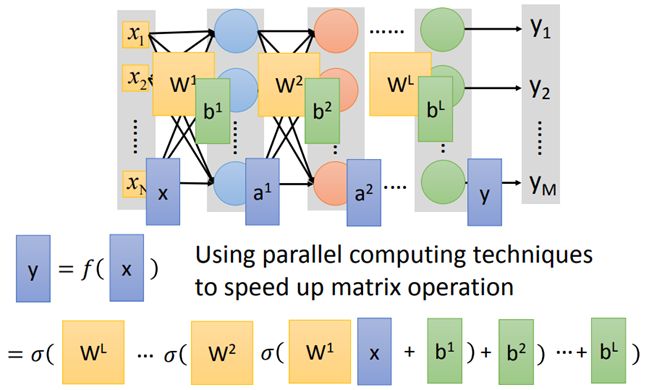
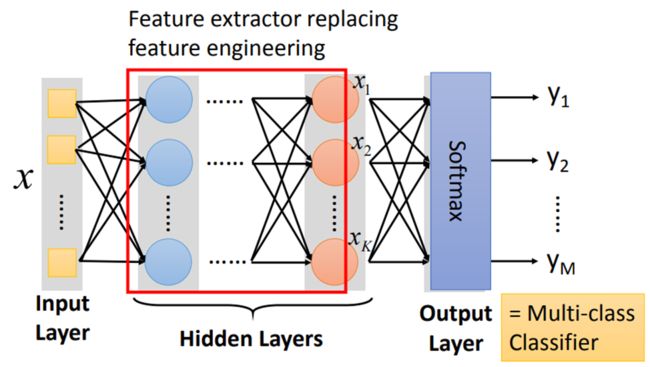
network通过hidden Layers(隐藏层)来提取特征,替代了原来的特征工程(即手动选择特征),在隐藏层最后一层输出的就是新的特征,而输出层就拿着这些新的特征作为输入,通过一个多分类器(softmax函数),得到最后输出y
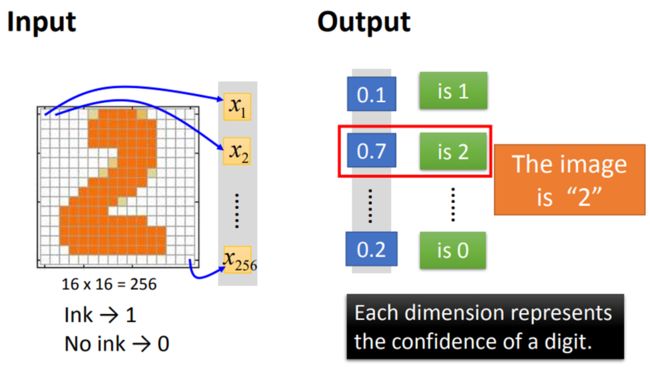
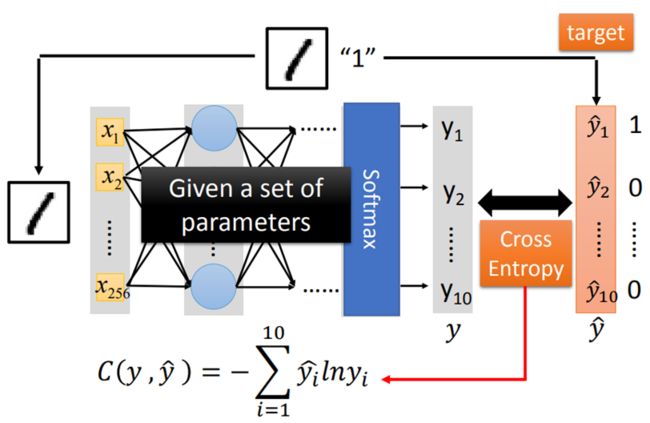
【举个例子:识别手写数字2】
输入一张16×16(256)像素大小的图片:输入维数为256(x1 ~ x256)
输出手写数字的数值0~9:输出维数为10(y1 ~ y10,输出y1表示数值为1,以此类推)
Step1:Neural Network
设计示意图如下
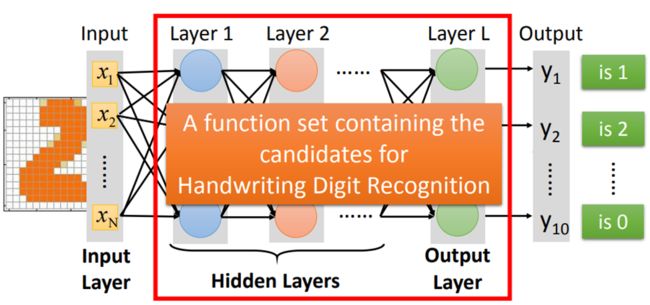
红色框中表示一个function set,其中每一个function都能用于做手写数字识别,只是有优劣差异
接下来的工作就是使用gradient descent,寻找一个最合适的function
最关键的是设计neural network的结构structure
Q&A
Q:怎么决定network的层数和neuron的数量?
A:不断尝试+直觉的
p.s. DL让我们从手动提特征转化到设计网络结构
很难去定义一个好的,合适的特征,倒不如让机器自己去尝试,再让人去选择,例如对于语音识别和影像识别,深度学习是个好的方法,因为特征工程提取特征并不容易
Q:能否自动设计结构?
A:进化人工神经网络(Evolutionary Artificial Neural Networks)但是这些方法并不是很普及
Q:可以自己设计网络结构吗?
A:可以。CNN就是不错设计结构,卷积神经网络
Step2:定义Loss函数
例如输入手写数字“1”,得到一组十维限量输出yi(理想输出是y^ 1000000000)
计算y与y^的Cross Entropy(交叉熵),手动调整参数,以求得C的最小值
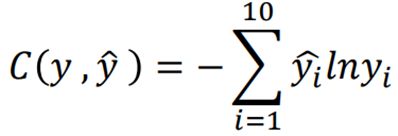
其余的training data同理,输入后计算Cost,
将每一个function的Cost求和,得Loss值,
去除function set 中Loss值最小的function即可
Step3:寻找最优function
(我们的老朋友)Gradient descent
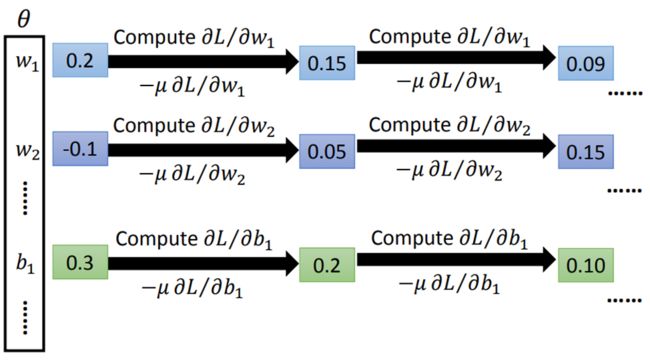
当计算量很大,以及计算很复杂时,我们也不会自己去计算,而是通过一些toolkit去计算

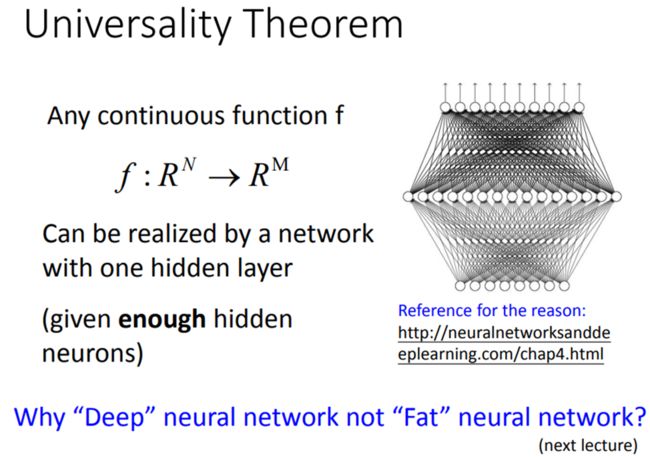
有一个通用理论:对于任何一个连续的函数,都可以用足够多的隐藏层来表示。(若为真是否只需一层网络即可,deep只是噱头)