复现论文ChineseBERT(ONTONOTES数据集)
记录一下自己复现论文《ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information》的过程,最近感觉老在调包,一天下来感觉什么也没干,就直播记录一下跑模型的过程吧
事前说明,这是跑项目的实况,如果是想当教程看,建议跳着看
自己电脑环境如下:
- 显卡:3060TI
- CUDA : 11.0
- CUDAToolkit : 8.0.2
- tensorflow : 2.4.0
- pytorch : 1.7.0
首先使用Conda创建一下项目的虚拟环境
conda create -n ChineseBERT python=3.8
进入环境
conda activate ChineseBERT
用Pycharm打开项目并切换到刚刚新建的环境

找到requirements.txt文件,在环境中一个一个安装

安装的时候,发现torch版本装不到这么低的

然后就装了项目简介中的版本,(发现自己要跑的OntoNotes 4.0数据集正好也需要装这个版本,nice)

pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
然后打开作者的文档OntoNotes NER task,下载对应的数据集

然后新建一个名为ONTONOTES_DATA_PATH的文件夹,把解压后的文件放进去

找到tasks/OntoNotes/OntoNotes_trainer.py文件,尝试第一次运行

果不其然会报错,好像是numpy版本不匹配的问题,搜一下

看了一眼自己装的numpy版本,果然高一点

然后直接
pip uninstall numpy
pip install numpy==1.23.4
再跑一次!
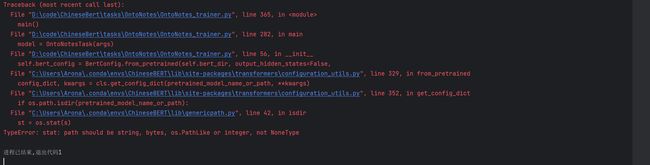
好消息,刚刚的错误解决了。新的错误好像是路径格式的问题?难道是我刚刚路径那没配好?
又看了一遍文档,好像是我ChineseBERT-base模型没下,赶紧去下载一下
然后按照文档中说的,也把模型文件都放在CHINESEBERT_PATH这个文件夹中(我猜的

配置完如下

再跑一次试试!

emmm待我研究一下…又看了眼文档,好像是跑错文件了?
应该是要运行chinesebert_base.sh文件,再运行之前需要修改两个个参数,把这两个位置的地址换成自己的。(啊我终于理解作者的意思了,不是要新建一个ONTONOTES_DATA_PATH的文件夹啊,是要把这个地址修改成自己的…)
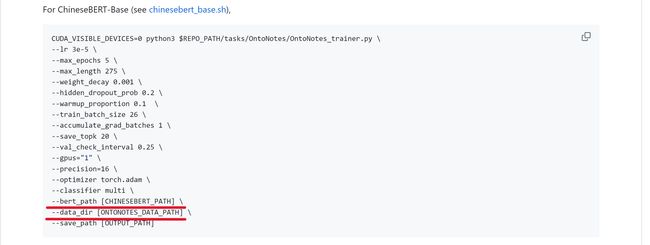
改到一半的时候发现,好像这其他路径也得该啊,而且这个是在Linux的环境下运行的,不管了先用git跑试试,改完路径后结果如下

配置一下Pycharm,让其可以直接用git
走起!

emmm闪一下就没了,什么情况
在chinesebert_base.sh脚本最后加入以下代码以便查看运行情况
# 使用read命令达到类似bat中的pause命令效果
echo 按任意键继续
read -n 1
echo 继续运行
运行情况如下

啊?没东西输出吗?看了一下路径,好像是Windows和Linux的路径不一样,Linux下路径是/,Win下应该是\\
再跑一次!

啊???(黑人问号.jpg)
试试把.sh文件转成.bat的,搜了一下网上居然还有一键自动转换的网址,太赞了
转换完的.bat脚本如下
@echo off
SET "TIME=0711"
SET "FILE_NAME=ontonotes_glyce_base"
SET "REPO_PATH=D:\code\ChineseBert"
SET "BERT_PATH=..\..\CHINESEBERT_PATH"
SET "DATA_DIR=..\..\ONTONOTES_DATA_PATH"
SET "SAVE_TOPK=20"
SET "TRAIN_BATCH_SIZE=26"
SET "LR=3e-5"
SET "WEIGHT_DECAY=0.001"
SET "WARMUP_PROPORTION=0.1"
SET "MAX_LEN=275"
SET "MAX_EPOCH=5"
SET "DROPOUT=0.2"
SET "ACC_GRAD=1"
SET "VAL_CHECK_INTERVAL=0.25"
SET "OPTIMIZER=torch.adam"
SET "CLASSIFIER=multi"
SET "OUTPUT_DIR=..\\..\\outputs/chinesebert\\%TIME%\\%FILE_NAME%_%MAX_EPOCH%_%TRAIN_BATCH_SIZE%_%LR%_%WEIGHT_DECAY%_%WARMUP_PROPORTION%_%MAX_LEN%_%DROPOUT%_%ACC_GRAD%_%VAL_CHECK_INTERVAL%"
mkdir "-p" "%OUTPUT_DIR%"
export "PYTHONPATH="%PYTHONPATH%:%REPO_PATH%""
python3 "%REPO_PATH%\\tasks\\OntoNotes\\OntoNotes_trainer.py"
"--lr" "%LR%"
"--max_epochs" "%MAX_EPOCH%"
"--max_length" "%MAX_LEN%"
"--weight_decay" "%WEIGHT_DECAY%"
"--hidden_dropout_prob" "%DROPOUT%"
"--warmup_proportion" "%WARMUP_PROPORTION%"
"--train_batch_size" "%TRAIN_BATCH_SIZE%"
"--accumulate_grad_batches" "%ACC_GRAD%"
"--save_topk" "%SAVE_TOPK%"
"--bert_path" "%BERT_PATH%"
"--data_dir" "%DATA_DIR%"
"--save_path" "%OUTPUT_DIR%"
"--val_check_interval" "%VAL_CHECK_INTERVAL%"
"--gpus=1"
"--precision=16"
"--optimizer" "%OPTIMIZER%"
"--classifier" "%CLASSIFIER%"
echo "按任意键继续"
read "-n" "1"
echo "继续运行"
运行一下试试!

太痛了!好像又是路径的问题?检查了一下确实是路径的错误
把上述OUTPUT_DIR的地址换成下面的
SET "OUTPUT_DIR=..\..\outputs\chinesebert\%TIME%\%FILE_NAME%_%MAX_EPOCH%_%TRAIN_BATCH_SIZE%_%LR%_%WEIGHT_DECAY%_%WARMUP_PROPORTION%_%MAX_LEN%_%DROPOUT%_%ACC_GRAD%_%VAL_CHECK_INTERVAL%"
再跑亿次!

我再康康…好像那个网站转换的有问题
求助了一下万能的chatGPT
@echo off
set TIME=0711
set FILE_NAME=ontonotes_glyce_base
set REPO_PATH=D:\code\ChineseBert
set BERT_PATH=..\..\CHINESEBERT_PATH
set DATA_DIR=..\..\ONTONOTES_DATA_PATH
set SAVE_TOPK=20
set TRAIN_BATCH_SIZE=26
set LR=3e-5
set WEIGHT_DECAY=0.001
set WARMUP_PROPORTION=0.1
set MAX_LEN=275
set MAX_EPOCH=5
set DROPOUT=0.2
set ACC_GRAD=1
set VAL_CHECK_INTERVAL=0.25
set OPTIMIZER=torch.adam
set CLASSIFIER=multi
set OUTPUT_DIR=..\..\outputs\chinesebert\%TIME%\%FILE_NAME%_%MAX_EPOCH%_%TRAIN_BATCH_SIZE%_%LR%_%WEIGHT_DECAY%_%WARMUP_PROPORTION%_%MAX_LEN%_%DROPOUT%_%ACC_GRAD%_%VAL_CHECK_INTERVAL%
mkdir %OUTPUT_DIR%
set PYTHONPATH=%PYTHONPATH%;%REPO_PATH%
python %REPO_PATH%\tasks\OntoNotes\OntoNotes_trainer.py ^
--lr %LR% ^
--max_epochs %MAX_EPOCH% ^
--max_length %MAX_LEN% ^
--weight_decay %WEIGHT_DECAY% ^
--hidden_dropout_prob %DROPOUT% ^
--warmup_proportion %WARMUP_PROPORTION% ^
--train_batch_size %TRAIN_BATCH_SIZE% ^
--accumulate_grad_batches %ACC_GRAD% ^
--save_topk %SAVE_TOPK% ^
--bert_path %BERT_PATH% ^
--data_dir %DATA_DIR% ^
--save_path %OUTPUT_DIR% ^
--val_check_interval %VAL_CHECK_INTERVAL% ^
--gpus="1" ^
--precision=16 ^
--optimizer %OPTIMIZER% ^
--classifier %CLASSIFIER%
pause
重新跑一下!

chatGPT牛逼!看来格式是转换对了,下面就是调包的问题了
看这个错应该是这个pypinyin包没装,装一下试试
pip install pypinyin
![]()
但是环境里应该有了鸭,难道是跑的时候不在这个环境吗
单独跑了一下这个文件,并没有报错!

感觉我的推理是正确的,查了一下如何在bat文件中选择环境
%切换到ChineseBert环境%
CALL activate ChineseBert
将这段代码放在执行Python文件前面

然后走起!

这???这是跑起来了???有戏有戏
等了一会也没反应,看了下说明,好像说是模型没训练初始化?
又等了一会

难…难道再等等?好像又说CUDA和Pytorch不匹配?(但我之前专门按照官网装的鸭
还说我什么model.example_input_array或者input_array属性没设置
首先解决一下CUDA和Pytorch的版本匹配问题,再次检查一下作者提供的Pytorch安装代码,发现和我CUDA版本是不匹配的,看来这个需要自己修改一下,不能无脑复制

我自己的CUDA

于是直接重装吧
先卸载
pip uninstall torch
再安装
pip3 install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/cu110/torch_stable.html
在跑一次试试!

跑起来了?!!!!!Ohhhhhhhh
等了一下午,终于跑出了结果了

作者的结果如下
| Model | Test Precision | Test Recall | Test F1 |
|---|---|---|---|
| BERT | 79.69 | 82.09 | 80.87 |
| RoBERTa | 80.43 | 80.30 | 80.37 |
| ChineseBERT | 80.03 | 83.33 | 81.65 |
不知道为什么test_precision这一项结果略低一点,其他结果相差不是很大