《大数据之路》阅读笔记--数据同步
数据同步
同步方式主要分为三种:直连同步、数据文件同步和数据库日志解析同步。
直连同步
直连同步是指直接使用ODBC/JDBC接口的方式直接连接数据库来拉取数据,这种方式对源系统的性能影响较大,不适合大数据量的情况。

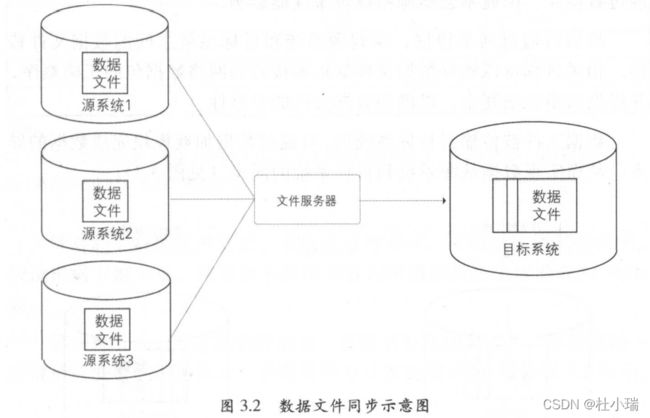
数据文件同步
数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如FTP服务器传输到目标系统后,加载到目标数据库系统中。当源数据来自多个不同的数据库系统时这种方式比较好。
在使用数据文件同步时,同时还会同步一个校验文件,保证文件的完整性。另外,在从源数据到数据文件的过程可以进行压缩和加密。
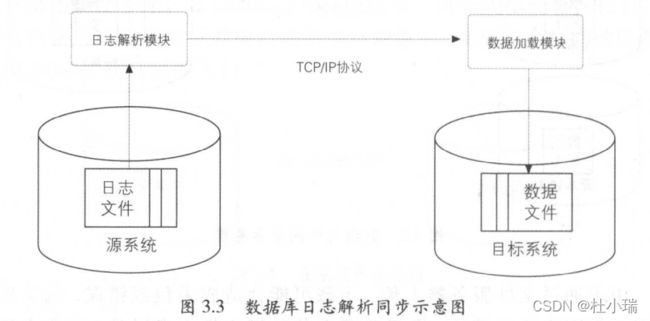
数据库日志解析同步
可以通过解析日志文件获取发生变更的数据,从而实现增量同步。读取归档日志是在操作系统层面完成的,不会对源系统造成太大影响。数据文件的传输可以通过网络协议进行传输。传输到目标系统后再将数据加载导入到目标系统。
数据同步的问题及解决方案
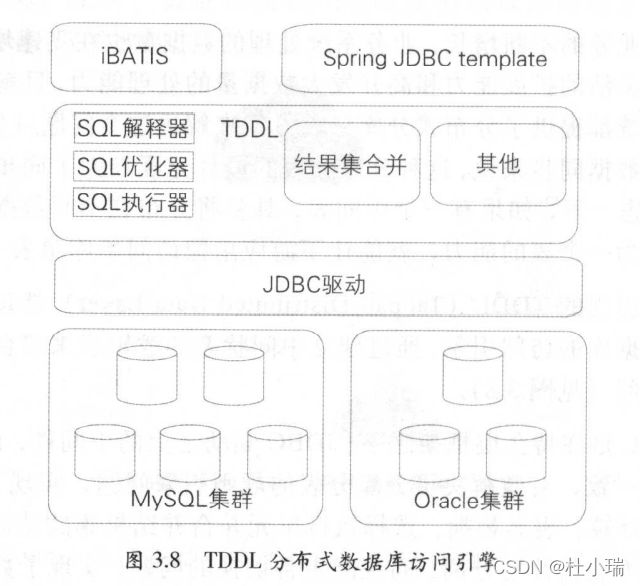
分库分表的处理
阿里的TDDL(TaoBao Distributed Data Layer)是一个分布式的数据库访问引擎,通过建立中间状态的逻辑表来整合统一分库分表的访问。
高效同步和批量同步
批量同步会遇到工作量大且重复多,另外数据源比较多学习成本高。解决方式是将不同数据源的数据同步配置透明化。
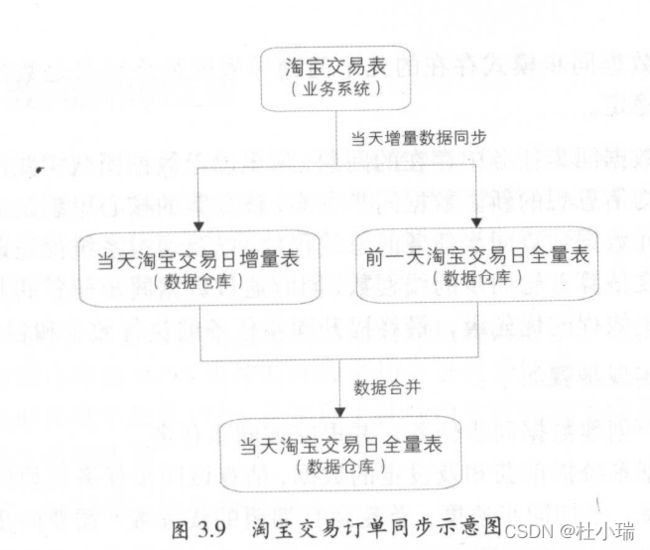
增量与全量同步的合并
全量同步就是每次同步都是将业务数据库中全部的数据同步到数据仓库,而增量同步则是同步的业务数据库数据的变化。
全量同步的逻辑比较简单,但是如果数据量特别大,那么效率会很低。因此可以采用增量和全量结合的方式获取当天的全量数据,将当前的增量与前一天的全量数据进行合并得到当天的全量数据。
同步性能的处理
简单来说就是解决同步任务的运行资源分配不均以及运行优先级的问题。解决方案为将数据拆分为数据块,一个线程处理一个数据块,另外有限处理等待时间最长,优先级最高的任务。
数据漂移的处理
数据漂移是指ODS表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。数据漂移主要是由于时间戳不准确引起的。
比如淘宝双十一前一天11:59:59的交易订单漂移到了12日,主要就是因为下单支付后调用支付宝接口支付的过程有延迟,也就是说在业务过程中会产生多个时间戳。为了解决这个问题,可以获取后一天15分钟的数据,并且限制多个业务过程(下单、支付、成功)都是11日的,然后按照数据库中表的更新时间戳升序排列,获取每个订单首次变更的那条记录。
另外还可以获取前一天最后15分钟和后一天开始15分钟的数据做全外连接。