Rx.NET in Action 第三章学习笔记
3 C#函数式编程思想
本章内容包括
- 将 C# 与函数式技术相结合
- 使用委托和 lambda 表达式
- 使用 LINQ 查询集合
面向对象编程为程序开发提供了巨大的生产力。它将复杂的系统分解为类,使项目更易于管理,而对象则是一个个孤岛,你可以集中精力分别处理。然而,近年来其他范式编程也受到了关注,尤其是函数式编程。函数式编程语言和函数式思维方式极大地影响了 Rx 的设计和使用方式。具体地说,匿名类型、一阶函数和函数组成等函数式编程概念是 Rx 不可分割的一部分,在本书中以及在使用 Rx 的日常工作中,你会看到这些概念被大量使用。
函数式编程之所以受到关注,是因为函数式语言非常适合多线程应用程序。Rx 擅长创建异步和并发处理流水线,这也是受函数式思维的启发。虽然 C# 被认为是一种面向对象的语言,但经过多年的发展,它也增加了一些函数式编程的能力。
.NET甚至有一种自己的函数式编程语言,名为F#,它以与C#相同的方式运行在通用语言运行时(CLR)之上。使用函数式编程技术可以使代码更简洁、更易读,还可以改变编写代码时的思维方式,最终提高工作效率。Rx 在很大程度上受到函数式思维方式的影响,因此了解这些概念有助于更轻松地采用 Rx 思维方式。
本章中的概念对你来说可能并不陌生。如果你愿意,可以跳到下一章,但我鼓励你至少简要回顾一下这些概念,以唤起你的记忆。
3.1 函数式编程的优势
随着计算机科学的发展,新的语言和新的概念和技术不断出现。所有这些语言都有一个共同的目的:提高开发人员的工作效率和程序的健壮性。生产率和健壮性包括很多方面:更短的代码、可读的语句、内部资源管理等等。函数式编程语言也试图实现这些目标。尽管存在多种类型的函数式编程语言,每种语言都有其独特的特点,但我们可以看到它们的相似之处:
- 声明式编程风格——这是基于 "告诉什么,而不是怎么做 "的概念。
- 不变性——值不能被修改;相反,新值会被创建。
- 一等函数——函数是主要的构建模块。
在面向对象的语言中,开发人员将程序看作是相互交互的对象集合。这样就可以通过封装数据和与对象中数据相关的行为来创建模块化代码。这种模块化再次提高了开发人员的工作效率,并使程序更加健壮,因为开发人员在编写新代码或更改(或修复)现有代码时,更容易理解代码(需要记住的细节更少),并将精力集中在特定模块上。
3.1.1 声明式编程风格
在前两章中,你看到了声明式编程风格的示例。在这种风格中,你在编写程序语句时,只描述了你想要实现的结果,而不是指定如何实现。至于如何做才能达到最佳效果,则取决于环境。请看下面这个例子,它展示了命令式(“如何”)和声明式(“做什么”)的语句:
- 命令式——循环客户列表的每一个客户,提取客户的地点,并打印地点中的城市名称。
- 声明式——打印列表中每位客户的城市名称。

图 3.1 包含标题、标题和段落的简单网页
声明式风格使你更容易掌握所编写的代码,从而提高工作效率,并减少代码出错的可能性。下面代码块展示了声明式编程风格的另一个示例,这一次使用的是 HTML,可以生成如图 3.1 所示的内容。
要创建这个页面,你不必编写渲染逻辑或布局管理,也不必设置每个元素的位置。你只需编写以下简短的 HTML 代码 :
<html>
<head>
<title>this is the page titletitle>
head>
<body>
<h1>This is a Headingh1>
<p>This is a paragraph.p>
body>
html>
即使你不懂 HTML,也不难看出,这个示例只是声明了你想看到的结果,并没有涉及让浏览器实现这一结果的技术细节。使用 HTML 这样的声明式语言,你可以不费吹灰之力就创建一个复杂的页面。你肯定希望自己编写的 C# 代码也能达到同样的效果,在本章接下来的内容中,你将看到这方面的示例。你需要注意的一点是,由于你只说明了 “干什么”,而没有说明 “怎么做”,你怎么知道系统会发生什么?会不会有副作用?事实证明,函数式编程从一开始就解决了这个问题,接下来你就会看到。
3.1.2 不变性和副作用
请看这个方法,它会向控制台打印一条信息:
public static void WriteRedMessage(string message)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine(message);
}
不同的方法会产生不同的效果,有时会隐藏在代码中。如果更改方法签名,去掉方法名中的 Red 字样,如下面的代码所示,副作用仍然会发生:
public static void WriteMessage(string message)
但现在要预测这个方法会改变控制台输出颜色的副作用要困难得多。当然,副作用并不局限于控制台的颜色;它们还包括共享对象状态的改变,例如修改了项目列表(如上一章所述)。副作用会导致代码出现各种错误,例如,在并发执行中,代码会同时从两个地方(如线程)到达,从而导致竞赛条件。副作用还会导致代码更难跟踪和预测,从而使代码更难维护。
函数式编程语言从一开始就防止了副作用的产生,从而解决了副作用问题。在函数式编程中,每个对象都是不可变的。你无法修改对象的状态。在设置值后,它永远不会改变;相反,新的对象会被创建。对你来说,不变性的概念并不陌生。C# 中也存在不变性,例如字符串类型。例如,试着回答下一个程序将打印什么:
string bookTitle = "Rx.NET in Action";
bookTitle.ToUpper();
Console.WriteLine("Book Title: {0}", bookTitle);
如果你的答案是 “Rx.NET in Action”,那你就答对了。在 C# 中,字符串是不可变的。所有转换字符串内容的方法都不会真正改变字符串;相反,它们会根据修改内容创建一个新的字符串实例。前面的示例应该这样写:
string bookTitle = "Rx.NET in Action";
string uppercaseTitle = bookTitle.ToUpper();
Console.WriteLine("Book Title: {0}", uppercaseTitle);
这一版代码中调用 ToUpper 后,结果存储在新变量中。这个变量保存了一个不同的字符串实例,其中包含书名的大写值。
不变性意味着,调用一个函数的结果只与该函数的计算结果有关,程序员无需担心任何其他影响。这就消除了 bug 的一个主要来源,并使函数具有幂等性——用相同的输入调用函数时,无论调用一次还是多次,结果总是相同的。
关于并发性
从不变性中获得的幂等性使程序可确定和可预测,并使执行顺序变得无关紧要,因此非常适合并发执行。
正如你在前一章中所看到的,编写并发代码很难。当使用顺序代码并尝试并行运行时,可能会发现自己面临错误。如果使用无副作用且不可变的代码,这个问题就不存在了。从不同的线程运行代码不会导致任何同步问题,因为你没有什么需要同步的。使用函数式编程语言能让编写并发应用程序变得更容易,这就是为什么函数式编程语言近年来开始备受关注,并成为各种社区构建大规模并发应用的首选。众所周知,Twitter、LinkedIn 和 AT&T 等公司都在其系统中使用函数式编程语言。
3.1.3 一等函数
之所以使用函数式编程这个名称,是因为函数是你使用的基本构造。它是语言基元之一,就像 int 或字符串一样,与其他基元类型类似,函数是一等公民,这意味着它可以作为参数传递,也可以从函数中返回。下面是 F#(.NET 中的一种函数式编程语言)中的一个示例:
let square x = x * x
let applyAndAdd f x y = f(x) + f(y)
在这里,我们定义了一个函数 square,它可以计算参数的平方。然后,我们定义一个新函数 applyAndAdd,它接受三个参数:第一个参数f是一个函数,应用于其他两个参数(x,y),然后将结果相加。
注意 如果你觉得很困惑,不用担心。阅读本章其余部分 ,然后再回来阅读这一小节内容。
调用 applyAndAdd 函数时,如果将平方函数作为第一个参数传递,并将两个数字作为其他参数传递,就会得到两个平方的和。例如,apply-AndAdd square 5 3 输出数字 34,如图 3.2 所示。
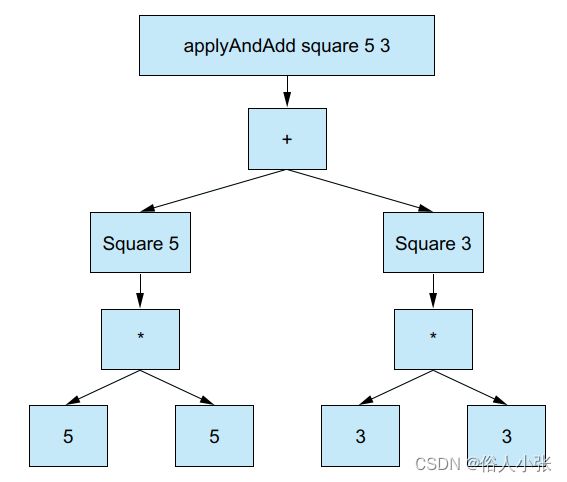
把函数作为参数,或者把函数作为返回值,称为高阶函数。使用高阶函数时,可以通过改变父函数使用的子函数来组成新函数,并为现有函数添加新的行为,如在 applyAndAdd示例。这样,你就可对其扩展,使其适应你的领域。
3.1.4 简而言之
本章前面提到的函数式编程,和函数式编程思维是一种强大工具,你应该掌握她:她会使你的代码更加简洁和精炼。
声明式编程可以隐藏实现本身的复杂性,让你专注于想要实现的结果。尽可能利用一阶函数和高阶函数的可组合性,它们充当了子功能代码的粘合剂。当程序的执行结果不再出现不确定性,则程序的表现力便会更出众。利用不可变的数据结构,可以保证函数总是以相同的,可预测的方式结束。
编写简洁的代码能让你在创建新代码或修改现有代码(即使是新代码)时更有效率。图 3.3 显示了提高工作效率的关键要素
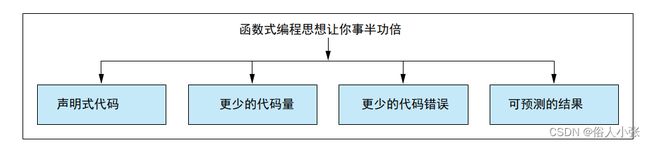
图 3.3 函数式编程的主要优点是提高工作效率。这里说明了提高工作效率的关键因素。
图 3.3 所示的关键要素是函数式编程的真正优势所在。了解这一点非常重要,这样你在使用 C# 编写程序时也能获得同样的优势。
3.2 委托和 lambda中的一等函数和高阶函数
委托和 lambda在 2002 年引入 C# 时,可以制作 “函数指针”,将其作为参数传递,或者作为类成员持有。这些函数指针被称为委托。多年来,C# 已成为一种多范式语言,不仅支持面向对象编程,还支持事件驱动编程或简单的过程编程。随着时间的推移,函数式编程也开始影响 C# 语言,而委托则成为支持函数成为 C# 语言一等公民的基本机制。
3.2.1 委托(delegate)
在 C# 中,委托(delegate)是一种类型,如同int是整数类型,byte是字节类型,但它不是定义值的类型,而是定义“方法”的类型。委托最常用于 .NET 事件,在本章中,你将看到如何使用它们,并利用函数式编程技术改善代码。
委托类型定义了**“方法”的确切签名**。例如,我先给出一个“方法”的 签名——**要求该“方法”能接收两个string参数并返回一个 bool值 **,接着我将形如此类参数和返回值的方法定义成一种委托。 图 3.4 显示了如何定义委托类型。

图 3.4 声明委托类型,定义了一种可接收两个string并返回bool‘的方法类型
创建委托类型后,便可创建委托实例,并传递要引用的“方法”,来引用具有相同签名的方法:
ComparisonTest delegateInstance = new ComparisonTest( <the method> );
假设你有一个类,其中包含两种字符串的比较方法:
class StringComparators
{
public static bool CompareLength(string first, string second)
{
return first.Length == second.Length;
}
public bool CompareContent(string first, string second)
{
return first == second;
}
}
接着,就可以用委托类型来引用比较“方法”(例中的CompareLength或CompareContent):
string s1 = "Hello"; string s2 = "World";
var comparators = new StringComparators();
ComparisonTest test = new ComparisonTest(comparators.CompareContent); Console.WriteLine("CompareContent returned: {0}", test(s1, s2));
test = new ComparisonTest(StringComparators.CompareLength); Console.WriteLine("CompareLength returned: {0}", test(s1, s2));
前面代码的输出示例如下:
CompareContent returned: False
CompareLength returned: True
从 C# 2.0 开始,创建委托变得更容易了。你只需将“方法”像变量赋值一样给委托变量(或参数)即可:
ComparisonTest test2 = comparators.CompareContent;
有了委托,你就可以创建类似于函数式编程语言的高阶函数。如下我们遍历两个集合中的项目,并借用委托传递过来的比较函数,来检查两个字符串数组是否相似。
清单 3.1 AreSimilar 方法使用委托作为参数
bool AreSimilar(string[] leftItems, string[] rightItems, ComparisonTest tester) { if (leftItems.Length != rightItems.Length) return false; for (int i = 0; i < leftItems.Length; i++) { if (tester(leftItems[i],rightItems[i]) == false) { return false; } } return true; }
该方法接收两个数组,并将两个数组的每对元素进行tester调用,以检查它们是否相似。tester指向一个“方法”,且这个“方法”是以参数的形式传递进来的。这里演示调用 AreSimilar 方法,并将 CompareLength 方法作为参数传递:
string[] cities = new[] { "London", "Madrid", "TelAviv" };
string[] friends = new[] { "Minnie", "Goofey", "MickeyM" };
Console.WriteLine("Are friends and cities similar? {0}",
AreSimilar(friends,cities, StringComparators.CompareLength));
该示例的输出结果如下:
Are friend and cities similar? True
3.2.2 匿名方法
至此,你会发现委托的问题在于必须去命名方法,即必须在代码中事先定义和命名一个方法的类型。这种负担会拖慢你的速度,从而降低你的工作效率。匿名方法是 C# 的一项功能,它可以将代码块作为委托实例传递:
ComparisonTest lengthComparer = delegate (string first, string second)
{
return first.Length == second.Length;
};
Console.WriteLine("anonymous method returned: {0}",
lengthComparer("Hello", "World"));
匿名方法允许将代码块作为委托参数使用:
AreSimilar(friends, cities,
delegate (string s1, string s2) { return s1 == s2; });
匿名方法的出现,使得在 C# 程序中创建高阶函数更加容易,并可重复利用现有代码,就像前面例子中的 AreSimilar 方法一样。你可以反复使用该方法,并传递不同的比较方法,从而提高程序的扩展性。
闭包(捕获变量)
匿名方法是在一个作用域(如方法作用域或类作用域)中创建的。匿名方法的代码块可以访问该作用域中可见的任何内容——变量、方法和类型等。举个例子:
int moduloBase = 2;
var similarByMod=AreSimilar(friends, cities, delegate (string s1, string s2)
{
return ((str1.Length % moduloBase) == (str2.Length % moduloBase));
});
在这里,匿名方法使用了一个在外层作用域中声明的变量。这个 moduloBase的变量被称为捕获变量,它的生命周期与使用它的匿名方法的生命周期相同。
使用捕获变量的匿名方法称为闭包。即使在创建捕获变量的作用域结束后,闭包仍可使用该变量:
ComparisonTest comparer;
{
int moduloBase = 2;
comparer = delegate (string s1, string s2)
{
Console.WriteLine("the modulo base is: {0}", moduloBase);
return ((s1.Length % moduloBase) == (s2.Length % moduloBase));
};
moduloBase = 3;
}
//到此已经离开了moduloBase变量的作用域
var similarByMod = AreSimilar(new[] { "AB" }, new[] { "ABCD" }, comparer);
Console.WriteLine("Similar by modulo: {0}", similarByMod);
运行这个示例时,会得到以下有趣的输出结果:
the modulo base is: 3
Similar by modulo: False
尽管匿名方法的创建作用域和使用作用域不同,但匿名方法仍然可以访问在创建作用域中声明的变量。不仅如此,匿名方法看到的值是该变量最后持有的值。这引出了一个强大的结论:
-
闭包使用的捕获变量的值是在方法执行时评估的,而不是在声明时评估的。
-
译者注:这句话其实直接翻译,很难理解。简单说就是,闭包执行时才会去使用捕获变量,此时变量的值是多少取决于闭包执行之前的代码,之前把变量赋值成多少,闭包里面的捕获变量就是多少。下面的例子中就演示了闭包执行前,i变量已经通过for语句后变成了5,此时再去执行闭包,当然就只能打印出来5。
-
捕获变量时常会引起混乱,因此请参考这个示例,并尝试确定将打印什么:
public delegate void ActionDelegate();
var actions = new List<ActionDelegate>();
for (var i = 0; i < 5; i++)
{
actions.Add(delegate () { Console.WriteLine(i); });
}
foreach (var act in actions) act();
本例的输出结果可能与你的预期不同。这段代码没有打印数字 0 至 4,而是打印了 5 次数字 5。这是因为在执行每个操作时,都会读取 i 的值,而 i 的值就是在循环的最后一次迭代中得到的值,即 5。
3.2.3 lambda 表达式
为了更简单地创建匿名方法,你可以使用 C# 3.0 中引入的 lambda表达式语法。通过 lambda 表达式,你可以创建更简洁、更接近函数式风格的匿名方法。
下面示例既使用匿名方法语法又使用 lambda 表达式编写的匿名方法:
ComparisonTest x = (s1,s2) => s1==s2 ;
ComparisonTest y = delegate (string s1,string s2) { return s1 == s2; };
lambda 表达式以参数列表的形式书写,后面跟 =>,而 => 后面跟一个表达式或语句块。
如果 lambda 表达式只接收一个参数,则可以省略括号:
x => Console.WriteLine(x);
lambda 表达式会自动对参数进行类型推断。不过,你也可以明确写入参数的类型:
ComparisonTest x = (string s1, string s2) => s1==s2 ;
通常情况下,你希望 lambda 表达式简明扼要,但有时候 lambda 表达式用一条语句可能搞不定。如果 lambda 包含多个表达式,则需要使用大括号,并明确写入return语句,告知编译器有返回值:
() =>
{
Console.WriteLine("Hello");
Console.WriteLine("Lambdas");
return true;
};
Rx 中大量使用 Lambda 表达式,因为它们使处理流水线变得简短而富有表现力,这一点很酷!但仍然需要为不同的方法签名创建不同的委托类型,这很麻烦。所以我们通常不会创建新的委托类型,而是使用 Action 和 Func.
3.2.4 Func 和 Action
委托类型是一种定义方法签名的方式,你可以将其作为返回参数,或作为变量使用。大多数情况下,你并不希望每次为了某种方法签名,就定义一种新的委托类型;其实你只是想表明需求。例如,以下两种委托类型除了使用的名称外都是一样的:
public delegate bool NameValidator(string name);
public delegate bool EmailValidator(string email);
由于两个委托类型定义相同,因此可以将两者设置为相同的 lambda 表达式:
NameValidator nameValidator = (name) => name.Length > 3;
EmailValidator emailValidator = (email) => email.Length > 3;
你本意是根据功能(检查姓名和电子邮件地址的有效性)来命名这两个委托类型。其实完全可以换个名称:
public delegate bool OneParameterReturnsBoolean(string parameter);
如上,你就有了一个可重复使用的委托类型,但它只适用于你定义的代码,这就需要一个标准的实现。.NET Framework 提供了名为 Func<…> 和 Action<…> 的可重用委托类型定义:
-
Func 是一种委托类型,它有返回值,也有参数。
-
Action 是有参数无返回值的委托类型。
.NET Framework 包含 17 个 Func 和 Action 定义,每个定义用于引用方法接收的不同数量的参数。Func 和 Action 类型位于 mscorlib 程序集的 System 名称空间下。
要引用一个无参数且无返回值的方法,你可以使用以下 Action 定义:
public delegate void Action();
有两个参数且无返回值的方法,则使用 Action 的定义:
public delegate void Action<in T1, in T2>(T1 arg1, T2 arg2);
要使用 Action 委托,需要指定参数类型。如下是使用Action 遍历集合,并对每个项目进行操作的方法示例:
public static void ForEachInt(IEnumerable<int> collection,Action<int> action)
{
foreach (var item in collection)
{
action(item);
}
}
然后,可在代码中这样调用 ForEachInt 方法:
var oddNumbers = new[] { 1, 3, 5, 7, 9 };
ForEachInt(oddNumbers, n => Console.WriteLine(n));
上述代码将打印 oddNumbers 集合中的所有数字。你可以使用不同的集合和不同的Action来使用 ForEachInt 方法。由于 Action 委托是通用的,因此你可以使用它来创建通用版本的 ForEach:
public static void ForEach<T>(IEnumerable<T> collection, Action<T> action)
{
foreach (var item in collection)
{
action(item);
}
}
现在,你可以对任何集合使用 ForEach:
//CLR 使用类型推断,自动认定是。
ForEach(new[] { 1, 2, 3 }, n => Console.WriteLine(n));
ForEach(new[] { "a", "b", "c" }, n => Console.WriteLine(n));
ForEach(new[] { ConsoleColor.Red, ConsoleColor.Green, ConsoleColor.Blue},
n => Console.WriteLine(n));
因为 Console.WriteLine 是一种可以接受任意数量参数的方法,所以可写如下:
ForEach(new[] { 1, 2, 3 }, Console.WriteLine);
ForEach(new[] { "a", "b", "c" }, Console.WriteLine);
ForEach(new[] { ConsoleColor.Red, ConsoleColor.Green, ConsoleColor.Blue},
Console.WriteLine));//注意这里的变化
当需要有返回值的委托时,应使用 Func 类型。该类型(与 Action 相似)接收可变数量的泛型参数,这些泛型参数与委托所定义的方法的参数类型相对应。与 Action 不同的是,在 Func 定义中,最后一个泛型参数是返回值的类型:
public delegate TResult Func<in T1,…,T16, out TResult>(T1 arg,…,T16 arg16);
无参数的 Func:
public delegate TResult Func<out TResult>();
使用 Func,你可以扩展 ForEach 方法的实现,使其接受过滤器(也称为谓词)。过滤器也是一个方法,它接受一个项目并返回一个布尔值,表示该项目是否有效:
public static void ForEach<T>(IEnumerable<T> collection, Action<T> action,
Func<T, bool> predicate)
{
foreach (var item in collection)
{
if (predicate(item))
{
action(item);
}
}
}
将过滤器传入ForEach中,可以实现对集合中的个别项进行操作,例如,只打印偶数:
var numbers = Enumerable.Range(1,10);
ForEach(numbers, n => Console.WriteLine(n), n => (n % 2 == 0));
有了 Action 和 Func,就可以任意构建可扩展的类和方法,而无需修改代码。这很好地实现了开放关闭原则(Open Close Principle,OCP),即一个类型应该对扩展开放,但对修改关闭。遵循 OCP 等设计原则可以改进代码,使其更具可维护性。
3.2.5 综合使用
值得高兴的是,像Strategy(策略模式)、Command(命令模式) 和 Factory(工厂模式)(仅举几例)等已知的设计模式都可以通过 Func 和 Action 以不同的方式表达,而且开发者仅需编写少量代码。
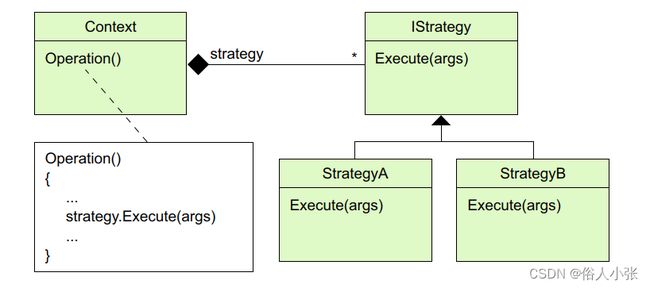
图 3.5 Strategy(策略模式)类图。可以通过提供不同的strategy(策略)类来达到扩展上下文的操作。
以策略设计模式为例,它的目的是通过把操作封装在对象中来扩展算法。图 3.5 显示了 策略设计模式的类图。在这种设计模式中,有一个Context 类负责执行操作 。而操作的处理算法或者逻辑被封装在外部,也就是由一个实现 IStrategy 接口的类来实现。
策略设计模式应用在工作流中的节点功能扩展时,非常有用。她给代码的使用者提供了更好的控制能力。许多程序包括 .NET Framework 本身都使用了这种模式,例如 IComparer 接口。
IComparer 接口是 System.Collections.Generic 命名空间的一部分,用于比较两个相同类型的对象。IComparer 接口的一个典型用法是在 List 的排序方法中使用。首先,创建一个新的 IComparer 派生类:
class LengthComparer : IComparer<string>
{
public int Compare(string x, string y)
{
if (x.Length == y.Length)
{
return 0;
}
return (x.Length > y.Length) ? 1 : -1;
}
}
//你可以这样排序
var words = new List<string> { "ab", "a", "aabb", "abc" };
words.Sort(new LengthComparer());
Console.WriteLine(string.Join(", ", words));
这种排序的输出结果是集合 { “a”, “ab”, “abc”, “aabb” };
这样做效果很好,但也很烦人,因为每次要创建新的比较方法时,都需要创建一个新的类。相反,你可以利用 Func 的强大功能,创建一个通用的 IComparer,并根据自己的需要进行调整:
class GenericComparer<T> : IComparer<T>
{
private Func<T, T, int> CompareFunc { get; set; }
public GenericComparer(Func<T,T,int> compareFunc)
{
CompareFunc = compareFunc;
}
public int Compare(T x, T y)
{
return CompareFunc(x,y);
}
}
在某种程度上,它是 IComparer 和 Func 之间的适配器。要使用它,需要将所需的比较代码作为 lambda 表达式(或委托)传递给它:
var words = new List<string> { "ab", "a", "aabb", "abc" };
words.Sort(new GenericComparer<string>((x, y) =>
(x.Length == y.Length)
? 0
: (x.Length > y.Length) ? 1 : -1));
有了 IComparer 的通用版本,您就可以快速创建新的比较代码,并将其放在调用位置附近的代码,以便随时读取,而且更加简洁。
将 Func 用作工厂
Func 风格可以使另一种模式,且更简短、更有趣,那就是懒加载模式,在这种模式中,Func 被用作工厂(对象创建者)。所谓 “懒加载”,就是不提前创建对象,而是在使用时及时创建。
HeavyClass可能需要很长时间才能创建,或者持有很多资源,因此需要延迟从系统中获取资源的时间。下面是一个HeavyClass在另一个类中使用的例子。只有当代码中的某些内容试图使用HeavyClass时,才会创建HeavyClass对象:
class HeavyClass
{
//这是一个功能繁重的类,创建起来需要很长时间
}
class ThinClass
{
private HeavyClass _heavy;
public HeavyClass TheHeavy
{
get
{
if (_heavy == null)
{
_heavy = new HeavyClass();
}
return _heavy;
}
}
public void SomeMethod()
{
var myHeavy = TheHeavy;
//其余代码使用 myHeavy
}
}
这段代码有几个问题。首先,它是可重复的;如果你有 10 个懒加载类型,你就需要创建 10 次相同的 if-create-return 序列,而重复的代码容易出错,也很无聊。其次,你又忘了并发和同步(很多人都会忘,所以别难过)。如果有其他人帮你处理这些事情,情况就会好得多,幸运的是,有一个工具可以解决这个问题。
在 System 命名空间中,你可以找到 Lazy 类,它的作用是验证实例是否已经创建,如果没有,则创建它(有且仅一次)。在我们的示例中,可以使用 Lazy,如图所示:
class ClassWithLazy
{
Lazy<HeavyClass> _lazyHeavyClass = new Lazy<HeavyClass>();
public void SomeMethod()
{
var myHeavy = _lazyHeavyClass.Value;
//Rest of code that uses myHeavy
}
}
但如果 HeavyClass 构造函数需要参数,或者创建过程比较复杂,该怎么办呢?为此,您可以传递一个 Func 来执行对象的创建并返回:
Lazy<HeavyClass> _lazyHeavyClass = new Lazy<HeavyClass>(() =>
{
var heavy = new HeavyClass(...); //创建带有参数的HeavyClass对象和初始化代码。
...
return heavy;
});
委托是 C# 的一项强大功能。多年来,它们的主要用途是处理事件,但自从 Action 和 Func 被引入后,您可以看到如何使用它们来提供更短、更易读和更简洁的代码,从而取代经典模式。
不过,还是少了点什么。当你添加 ForEach 等新方法时,感觉有点像在编程代码。因为你创建了一个类静态方法,所以在使用时,感觉并不是自然的面向对象风格。你更愿意在你想要运行它的对象上使用常规方法。这便引出了扩展方法。
3.3 使用扩展方法的方法链
函数式编程之所以简洁明了、声明性强,原因之一是使用了函数组合和方法链——即一个接一个地调用函数,使第一个函数的输出成为下一个函数的输入。由于函数是一等公民,因此函数的输出本身也可以是一个函数。使用 Rx 编写的查询也是以同样的构成方式编写的,查询看起来就像一个英文句子,因此使用起来很有吸引力。要了解如何在 C# 代码中添加这种链式行为,首先需要了解扩展方法。
3.3.1 使用扩展方法扩展类型行为
在面向对象编程中,定义类时可以包含状态(字段、属性等)和方法。但在编译后,就再也无法对其进行扩展,也不能增加方法或者属性,除非更改代码再编译。但有时,你可能就需要给已有的类添加方法(无论是您创建的类还是您可以访问的类,如想给.NET Framework库标准类增加)。现在提供了一个新的方案,你可以创建一个新类,然后添加一些方法,这些方法接受你要扩展的类作为参数,整个过程与面向过程式编程类似。
此方式称为扩展方法,是.NET新增的一项功能,允许向已有类型 "添加 "方法。为类型添加方法并不意味着改变类型;相反,扩展方法从语法上看,仍然是在原对象实例上调用方法,但编译器会将调用自动地转为调用扩展方法。我们演示一下 ForEach 的实现:
static class Tools
{
public static void ForEach<T>(IEnumerable<T> collection、
Action<T> action)
{
//ForEach 实现
}
}
调用 ForEach 时,需要传一个集合参数,该集合将被ForEach循环处理。我们希望在使用扩展方法后,ForEach 的调用就会像下面的示例代码一样。请注意,这个示例只是演示,还不能正确编译:
var numbers = Enumerable.Range(1,10);
numbers.ForEach(x=>Console.WriteLine(x));
在编译时,编译器会把对象的方法调用改为调用静态方法。
创建扩展方法的具体过程如下:
-
创建一个静态类。
-
创建一个公共或内部静态方法。
-
在第一个参数前添加 this 字样。
方法中第一个参数的类型,需要是你扩展的类型(此例是IEnumerable类型)。下面我们将 ForEach 方法修改一下,使其成为真正的扩展方法:
public static void ForEach<T>(this IEnumerable<T> collection,
action<T> action)
{
//ForEach实现
}
现在,您可以在所有实现 IEnumerable 的类型上运行 ForEach 方法了。
使用扩展方法和使用普通方法一样,可以接收参数和返回值。试试自己能否创建一个检查偶数的扩展方法。下面是我的解决方案:
namespace ExtensionMethodsExample
{
static class IntExtensions
{
public static bool IsEven(this int number)
{
return number % 2 == 0;
}
}
}
按照惯例,包含扩展方法的类名以Extensions后缀命名(如 StringExtensions 和 CollectionExtensions)。
要使用创建的扩展方法,须使用 using 语句添加声明扩展类的命名空间(同一命名空间可省略):
using ExtensionMethodsExample;
namespace ProgramNamespace
{
class Program
{
static void Main(string[] args)
{
int meaningOfLife = 42;
Console.WriteLine("is the meaning of life even:{0}",
meaningOfLife.IsEven());
}
}
}
处理空值
因为扩展方法是普通方法,所以它们甚至可以对空值起作用。让我给你演示一下。要检查字符串是空值还是空值,可以使用 String 的静态方法 IsNullOrEmpty:
String str = "";
Console.WriteLine("is str empty: {0}", string.IsNullOrEmpty(str));
你可以创建一个新的扩展方法,在对象本身执行相同的检查:
static class StringExtensions
{
public static bool IsNullOrEmpty(this string str)
{
return string.IsNullOrEmpty(str);
}
}
你可以这样使用它:
string str = "";
Console.WriteLine("is str empty: {0}", str.IsNullOrEmpty());
注意,调用的是变量 str 本身。现在想想在这种情况下会发生什么:
String str = null;
Console.WriteLine("is str empty: {0}", str.IsNullOrEmpty());
代码不会崩溃,你可以看到打印的这条信息:
is str empty: true
是不是很巧妙,即使你像执行实例方法一样执行 IsNullOrEmpty,但如果没有实例,它仍能正确运行。让我们进一步讨论扩展方法如何帮助你创建流畅的接口。
3.3.2 流畅接口(Fluent Interface)和方法链(method chaining)
流畅接口(fluent interface)一词是由 Eric Evans 和 Martin Fowler 提出的,用来描述一种连续调用方法的接口风格。例如,System.Text.StringBuilder 类提供了如下接口:
StringBuilder sbuilder = new StringBuilder();
var result = sbuilder
.AppendLine("Fluent")
.AppendLine("Interfaces")
.AppendLine("Are")
.AppendLine("Awesome")
.ToString();
StringBuilder 在构建字符串方面高效方法,提供了追加和插入子串的方法。在前面的代码示例中,你连续调用字符串生成器上的方法,直到最后的方法——本例中是 ToString,过程中并不用来回写变量名。这种调用像链条一样,故称为方法链(method chaining)。
有了流畅的接口,你就能获得更流畅的代码,感觉自然且可读。StringBuilder 之所以可以创建方法链,是因为它是故意这样定义的。你看一下它的方法签名,就会发现它们的返回类型都是 StringBuilder :
public StringBuilder AppendLine(string value);
public StringBuilder Insert(int index, string value, int count);
:
public StringBuilder AppendFormat(string format, params object[] args);
从 StringBuilder 方法返回的就是 StringBuilder 本身——同一个实例。StringBuilder 是结果字符串的容器,每次调用,都会改变内部数据结构,帮助形成结果字符串。所以方法执行后,每次都返回相同的 StringBuilder 实例,就可以继续调用。
这一切如此美好,我们应该感谢 .NET 团队创建了这么好的交互界面,但如果你需要的类没有提供这样的交互界面怎么办呢?如果你无法访问源代码,也无法更改源代码,怎么办呢?这时扩展方法就派上用场了。让我们以 List 为例。
List 提供了一种向其中添加项的方法:
public class List<T> : IList<T>,...
{
. . .
public void Add(T item);
. . .
}
List 的 Add 方法添加项目后返回 void,因此要添加项目,必须按以下所示编写:
var words = new List<string>();
words.Add("This");
words.Add("Feels");
words.Add("Weird");
其实完全可以省略变量名,以减少输入并节省体力。首先,您将在 List 类型上创建一个扩展方法,该方法将执行 Add 但随后返回List:
public static class ListExtensions
{
public static List<T> AddItem<T>(this List<T> list, T item)
{
list.Add(item);
return list;
}
}
现在,您可以流畅的向列表中添加内容了:
var words = new List<string>();
words.AddItem("This")
.AddItem("Feels")
.AddItem("Weird");
这看起来更简洁,如果将 this 参数改为更抽象的参数,扩展方法将适用于更多类型。您可以更改 AddItem 扩展方法,以便在实现 ICollection 接口类型上运行该方法:
public static ICollection<T> AddItem<T>(this ICollection<T> list, T item)
这里有个有趣的现象,抽象类型中居然可以添加方法,因为在面向对象语言中,不能在接口中添加方法实现。如果希望给所有实现接口(如 ICollection)的类型都提供一个方法(如 AddItem),必须在每个子类型中自己实现该方法,或者创建一个公共基类,所有子类型都从该基类继承。这两种选择都不理想,有时甚至是不可能的,因为在 .NET 中不存在多类继承。没有多类继承意味着,如果您实现了多个接口,每个接口都有一个或多个方法,这时如果想在所有子类中共享一个实现,需要给每个接口创建一个基类,并全部继承。这是不可能的。
而扩展方法使其成为可能。如果该类型实现了多个接口,并且这些接口都有自己的扩展方法,那么子类型也将拥有这些方法,这就是一种虚拟多重继承。
需要强调的是,要创建一个流畅的接口,不一定要返回与方法链起点相同的实例,甚至不一定要返回与方法链起点相同的类型。每个方法调用都可以返回不同的类型,上一个方法的返回类型,将成为下一个方法调用的类型。
当你在具体和抽象类型上添加越来越多的扩展方法时,你就可以用它们来创建自己的语言,接下来你将看到这一点。
3.3.3 创建语言
扩展方法允许在现有类型上添加新方法,而无需打开类型代码修改。结合方法链技术,您可以创建各种方法,用描述您的领域的语言表达您想要实现的目标。
以单元测试中编写断言的方式为例。单元测试是一段执行代码并断言结果符合预期的代码。下面是一个用 MSTest 编写的简单测试,用于检查字符串结果:
[TestMethod]
public void NonFluentTest()
{
...
string actual = "ABCDEFGHI";//actual中存储了你测试的信息
Assert.IsTrue(actual.StartsWith("AB")); //每一个断言检查一种条件,你想让结果满足所有条件
Assert.IsTrue(actual.EndsWith("HI"));
Assert.IsTrue(actual.Contains("EF"));
Assert.AreEqual(9,actual.Length);
}
您使用的断言具有技术性和通用性,您可以通过使用更流畅的接口来改进它们,例如优秀的 FluentAssertions 库 (www.fluentassertions.com) 提供的接口。这是添加 FluentAssertion 语法后的同一个测试:
[TestMethod]
public void FluentTest()
{
...
String actual = "ABCDEFGHI";
actual.Should().StartWith("AB")
.And.EndWith("HI")
.And.Contain("EF")
.And.HaveLength(9);
}
这个版本的断言会检查相同的条件,但由于使用了流畅接口,使用的语法更像句子。
FluentAssertions 库为断言添加了一个 DSL。它为字符串类型添加了一个扩展方法,该方法会返回一个具有流畅接口的对象,而流畅接口则充当断言生成器。
public static StringAssertions Should(this string actualValue);
调用 Should 方法时,会创建一个 StringAssertion 类型的对象,并将要检查的字符串传递给该对象。从那时起,所有断言都由 StringAssertion 维护。
像这里用于断言的 DSL 使代码变得简洁和具有声明性。另一个重要而强大的 DSL 是 LINQ 提供的 DSL,它为 .NET 中的集合提供了通用查询功能。
3.4 使用 LINQ 查询集合
扩展方法和方法链技术使您能够为各种领域创建 DSL,即使原始类型本身没有实现流畅接口。关系数据库查询是一个长期存在领域语言的领域。在关系数据库中,可以使用 SQL 以简短和声明的方式查询表。下面是一个 SQL 的示例,它可以按姓氏排序,获取所有居住在美国的雇员信息:
SELECT * --
FROM Employees
WHERE Country=’USA’
ORDER BY LastName
正如您所看到的,SQL 使用的语法简短而具有声明性;您只需说明所需的结果,然后让数据库为您执行获取所需结果的过程。如果.NET也有这样的功能,岂不更好?.NET确实有。
LINQ 是一组标准处理器,可用于对任何数据源进行查询。数据源可以是 XML 文档、数据库、字符串或任何 .NET 集合。只要数据源是实现了 IEnumerable 接口的类,就可以使用 LINQ 进行查询。
IQueryable
IEnumerable 并不是 LINQ 唯一的目标接口。IQueryable 是一个特殊的接口,可以直接针对数据源查询,并把对数据库执行的 LINQ 查询将被转换为 SQL。
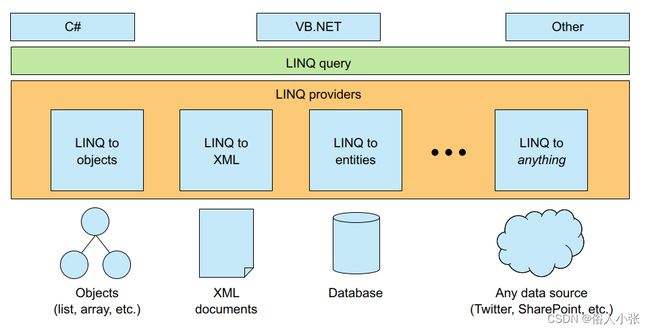
图 3.6 LINQ 架构:对于每种类型的数据源,LINQ 提供者都会将 LINQ 查询转换为最适合数据源的查询语言。
3.4.1 LINQ 看起来像什么?
LINQ 是由扩展方法组成的,这些扩展方法对源进行操作以建立查询。
这些方法通常被称为处理器(Operator)。下面是一个简单的程序,它使用 LINQ 对整数列表进行查询,找出所有大于 10 的奇数,并在每个奇数上添加数值 2 之后,将它们排序且不重复地返回:
using System.Collections.Generic;
using System.Collections.Generic;
using System.Linq;//为 LINQ 命名空间添加 using 语句,以导入所有 LINQ 处理器。
namespace LINQExamples
{
class Program
{
static void Main(string[] args)
{
var numbers = new List<int> { 1, 35, 22, 6, 10, 11 };
var result = numbers.Where(x => x % 2 == 1) //过滤,只保留奇数元素
.Where(x => x > 10)//过滤,只保大于10的元素
.Select(x => x+2)//将每个元素加2
.Distinct()//统计所有元素,去掉重复元素
.OrderBy(x => x);//根据元素大小排序,OrderBy需要传入一个比较方法的委托,此处用元素自身值的大小进行比较
foreach (var number in result)
{
Console.Write("{0}", number);
}
Console.WriteLine();
}
}
}
查询是通过创建处理器方法链来执行的,因此每个项目都会逐一通过处理器链中的处理器,并被收集到最终结果中。在我们的例子中,最终结果打印为 1337,因为只有 35 和 11 可以通过筛选器,然后在转换为 37 和 13 后进行排序。图 3.7 中的查询流程描述了在 LINQ 中创建方法链的可组合性。

图 3.7 LINQ 查询的可组合性 。LINQ 由一组流水线和过滤器组成。从概念上讲,每个处理器的输出都会成为下一个处理器的输入,直到得到最终结果。
使用 LINQ 处理器创建方法链功能强大,但并不总是清晰直观。相反,你可以使用查询表达式语法,它提供了一种类似于 SQL 结构的声明式语法。下面的示例显示了本章前面的同一个查询,只不过这次是查询表达式:
using System;
using System.Collections.Generic;
using System.Linq;
namespace LINQExamples
{
class Program
{
static void Main(string[] args)
{
var numbers = new List<int> { 1, 35, 22, 6, 10, 11 };
var result =
from number in numbers//LINQ 查询表达式以 from ... in 开头,帮助 IntelliSense 了解查询的类型。
where number % 2 == 1
where number > 10
orderby number
select number+2;//select 关键字指定最终结果中的元素,必须位于查询语法的末尾。
var distinct = result.Distinct();//不能嵌入的 LINQ 处理器(如 Distinct)应使用扩展方法。
foreach (var number in distinct)
{
Console.Write("{0}", number);
}
}
}
}
请注意示例中的几点。首先,它以 from . … in 子句开始,以 select 结束;这是标准结构。其次,并非所有操作符都能像 Distinct 一样嵌入查询表达式语法中。您需要在查询表达式内部或外部以方法调用的形式添加它们。
一般来说,您可以在查询表达式内部调用任何方法。最后,查询表达式是编译器提供的语法糖,但使用它可以让事情变得更简单,例如在嵌套查询和连接的情况下。
3.4.2 链接查询和连接(join)
通过查询表达式语法,您可以轻松将两个集合进行连接(join),并对结果进行处理。假设您创建了一个程序,其中包含书籍集合和作者集合,现要求在每本书名旁边显示该作者的名字。您可以使用 LINQ 这样做:
var authors = new[] {
new Author(1, "Tamir Dresher"),
new Author(2, "John Skeet")
};
var books = new[] {
new Book("Rx.NET in Action", 1),
new Book("C# in Depth", 2),
new Book("Real-World Functional Programming", 2)
};
var authorsBooks =
from author in authors
from book in books
where book.AuthorID == author.ID
select author.Name + " wrote the book: " + book.Name;
foreach (var authorBooks in authorsBooks)
{
Console.WriteLine(authorBooks);
}
该查询将每个作者与每本书进行关联,类似于笛卡尔积。如果book.AuthorID 与author.ID相同,则select一个字符串表示。该程序的输出如下:
Tamir Dresher wrote the book: Rx.NET in Action
John Skeet wrote the book: C# in Depth
John Skeet wrote the book: Real-World Functional Programming
严格来讲,这个例子其实一种分组计算,为此你应该使用 LINQ 的Group处理器,但这超出了本章的讨论范围。
有时候,我不想Select处理器返回字符串;而是想把作者和书Select到一个新的对象中。但你可能要问,那是否需要单独定义一个类型来存储呢?答案:不用。您可以使用匿名类。
3.4.3 匿名类型
作为支持 LINQ 的一部分,C# 的一大特色是可以创建匿名类型。匿名类型是在创建对象时预先在代码中定义的类型。该类型由编译器根据为对象分配的属性生成。图 3.8 展示了如何创建一个带有两个属性(string和DateTime)的匿名类型。
匿名类型由编译器生成,你不能自己使用它。编译器很聪明,知道如何生成了两个匿名类型

图 3.8 具有两个属性的匿名类型
属性相同,它们就是同一类型。在查找作者书籍的示例中,你为每对作者和书籍创建了一个字符串;相反,你可以创建一个将这两个属性封装在一起的对象:
var authors = new[] {
new Author(1, "Tamir Dresher"),
new Author(2, "John Skeet"),
};
var books = new[] {
new Book("Rx.NET in Action", 1),
new Book("C# in Depth", 2),
new Book("Real-World Functional Programming", 2),
};
//创建一个匿名类型,包含作者和书籍两个属性。如果没有指定属性名称,编译器将生成与变量名相同的名称。
var authorsBooks =
from author in authors
from book in books
where book.AuthorID == author.ID
select new {author, book};
//在匿名类型定义的作用域中,智能提示和编译器可以访问内部属性。
foreach (var authorBook in authorsBooks)
{
Console.WriteLine("{0} wrote the book: {1}" ,
authorBook.author.Name,
authorBook.book.Name);
}
匿名类型仅在创建它的作用域中可见,所以不能把它当返回值或者传递给其他方法,不过也有办法,你把它转成object就可以了。
关键字 var专门用来接受匿名类型的变量。因为匿名类型是由编译器生成的,所以你不能创建该类型的变量;var 允许你创建这些变量,并让编译器推导出类型,如图 3.9 所示。
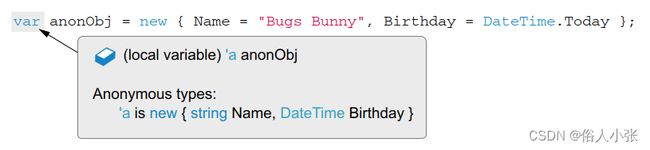
图 3.9 对匿名类型使用 var。编译器和 IntelliSense 知道如何推断出生成的真实类型。
匿名类型与 Tuple
.NET提供了另一种可用于即时创建属性包(称为项)的类型:Tuple<>类。.NET Framework 支持最多包含 7 个元素的元组,但您可以传递 8 个元素作为元组,这样您就可以获得无限多个项。
下面是如何创建一个有两个项的元组:一个字符串和一个日期时间:
Tuple<string, DateTime> tuple = Tuple.Create("Bugs Bunny", DateTime.Today);Tuple.Create(创建)工厂方法可以接收参数,如希望在元组中包含的项数。
与匿名类型一样,Tuple 数据结构是即时创建新类型的通用方法,但与匿名类型不同的是,Tuple 项的访问基于项的位置。要读取之前创建的 Tuple 中的值,需要知道它是 Tuple 中的第二个项:
var theDateTime = tuple.Item2;这样做会降低 tuple 的可读性,而且容易出错。
与匿名类型不同,Tuple 可以从方法中返回或作为参数传递,但我建议您不要这样做。在这种情况下,更好的办法是创建一个类来实现这一目的,从而使你的代码类型安全、可读性强、错误少。
3.4.4 LINQ 处理器
LINQ 处理器赋予了 LINQ 强大的功能,并使其极具吸引力。大多数处理器都用于实现 IEnumerable 接口的集合,这使得它具有广泛性和通用性。标准查询处理器的数量很多。如果要涵盖所有处理器,需要的篇幅将超过一章,因此本节将介绍几个最常用的处理器。如果您对此感兴趣,我建议您查看 MSDN 网站上的 101 LINQ 示例(https://code.msdn.microsoft.com/ 101-LINQ-Samples-3fb9811b)。Rx 一直被称为 LINQ to Events,事实上,LINQ 处理器已被调整为支持可观测变量,因此你可以在本书的其余部分看到并学习到更多关于这些处理器的内容。表 3.1 列出了我认为重要的处理器,并按描述其目的的类别进行了分类。
| 类别 | 查询处理器 | 描述 |
|---|---|---|
| Aggregation | Count | 返回集合中的条目数 |
| Max | 返回集合中最大的项目 | |
| Min | 返回集合中最小的项目 | |
| Element operations | First | 返回集合中的第一个条目,如果集合为空,则会出错 |
| FirstOrDefault | 返回集合中的第一个项目,如果集合为空,则返回默认值 | |
| Single | 返回集合中存在的单个项目,如果集合为空或存在多个项目,则会出错 | |
| SingleOrDefault | 返回集合中存在的单个项目,如果存在多个项目,则抛出错误。如果集合为空,将返回默认值。 | |
| Filtering | OfType | 返回集合中可转换为 TResult 的项目 |
| Where | 根据作为参数提供的条件过滤列表 | |
| Grouping data | GroupBy | 根据指定的键选择器函数分组项目 |
| Join | Join | 根据键连接两个集合 |
| GroupJoin | 按键连接两个序列,按匹配的键对结果分组,然后返回分组结果和键的集合 | |
| Partitioning | Skip | 跳过指定数量的项目;结果集合包含未跳过的项目 |
| Take | 结果只包含集合中的第一个项目,并按指定的项目数进行筛选 | |
| Projection | Select | 以传递的 Func 参数中指定的形式将项目投影到集合中 |
| SelectMany | 将每个项投影到集合中,并将所有返回的集合平铺为一个集合 | |
| Quantifier operations | All | 确定集合中的所有元素是否都满足条件 |
| Any | 确定集合中的任何元素是否满足条件 | |
| Contains | 确定集合中是否包含一个项目 | |
| Set operations | Distinct | 返回每个项只出现一次的集合 |
| Except | 接收两个集合并返回第一个集合中不属于第二个集合的元素 | |
| Intersect | 接收两个集合并返回两个集合中都存在的元素 | |
| Sorting | OrderBy | 按键返回升序排序的集合 |
| OrderByDescending | 按键返回降序排序的集合 |
3.4.5 通过延迟执行提高效率
LINQ 简洁易读,但速度快吗?答案是(就像编程中的大多数事情一样),这取决于具体情况。LINQ 并不总是查询集合的最佳解决方案,但大多数情况下你不会注意到其中的差别。LINQ 也在延迟执行模式下工作,这会影响性能和理解。请看下一个示例,并尝试回答将打印哪些数字:
var numbers = new List<int>{1, 2, 3, 4};
var evenNumbers =
from number in numbers
where number%2 == 0
select number;
numbers.Add(6);//数字 6 是在创建查询后添加的。
foreach (var number in evenNumbers)
{
Console.WriteLine(number);
}
正确答案是 2、4 和 6 会打印出来。怎么可能呢?你是在添加数字 6 之前创建查询的;evenNumbers 集合不是应该只包含数字 2 和 4 吗?
LINQ 中的延迟执行意味着查询只在有需求时才进行评估。需求是指对集合进行显式遍历(如 foreach)或调用内部操作符(如 Last 或 Count)。
要了解延迟执行的工作原理,您需要了解 C# 如何使用 yield 来创建迭代器。
yield 关键字
yield 关键字可在返回 IEnumerable 或 IEnumerator 的方法中使用。在方法内部使用 yield return 时,其返回的值是返回集合的一部分,如下例所示:
static IEnumerable<string> GetGreetings()
{
yield return "Hello";
yield return "Hi";
}
private static void UnderstandingYieldExample()
{
foreach (var greeting in GetGreetings())
{
Console.WriteLine(greeting);
}
}
使用 yield return 和 yield break,就无需通过自己实现 IEnumerable 和 IEnumerator 来手动创建迭代器;相反,您可以将创建集合元素的逻辑都放在返回集合的方法中。一个典型的例子是生成无穷序列,如斐波那契序列。我们要做的就是在保存序列中前两个项的方法中保存两个变量。每迭代一次,就会通过将前两项相加并更新其值来生成一个新项:
IEnumerable<int> GenerateFibonacci()
{
int a = 0;
int b = 1;
yield return a;
yield return b;
while (true)
{
b = a + b;
a = b - a;
yield return b;
}
}
正如你所看到的,yield 可以在循环内使用,也可以在常规的顺序代码中使用。包含 yield 的方法由外部控制。每次在输出 IEnumerable 的 Enumerator 上调用 MoveNext 方法时,返回 IEnumerable 的方法都会恢复并继续执行,直到到达下一个 yield 语句或结束。在幕后,编译器生成了一个状态机,它跟踪方法的位置,并知道如何过渡到下一个状态以继续执行。
译者注:yield颠覆了我对传统代码执行顺序的理解。这东西本质上就是一个懒驴,你要是要数,那我就先给你算一个出来,然后就挺着,啥活不干。除非你明确告诉他,我还要下一个数。简单说就是推着就走,不推就停的这么个玩意。不过yield的确是一种非常高级的语法糖,如果自己要编写代码完全实现这种效果,是非常麻烦的。
LINQ 处理器(大部分)是以迭代器的形式实现的,因此它们的代码会在所查询的集合中的每个项目上懒散地执行。下面是 Where处理器的修改版本,以解释这一点。修改后的 Where 处理器在检查每个项目时都会打印一条信息:
static class EnumerableDefferedExtensions
{
public static IEnumerable<T> WhereWithLog<T>(this IEnumerable<T> source,
Func<T, bool> predicate)
{
foreach (var item in source)
{
Console.WriteLine("Checking item {0}", item);
if (predicate(item))
{
yield return item;
}
}
}
}
现在,您将在一个集合上使用 WhereWithLog,并验证谓词不是一次性用于所有项,而是以迭代的方式使用:
var numbers = new[] { 1, 2, 3, 4, 5, 6 };
var evenNumbers = numbers.WhereWithLog(x => x%2 == 0);
Console.WriteLine("before foreach");
foreach (var number in evenNumbers)
{
Console.WriteLine("evenNumber:{0}",number);
}
程序输出结果:
before foreach
Checking item 1
Checking item 2
evenNumber:2
Checking item 3
Checking item 4
evenNumber:4
Checking item 5
Checking item 6
evenNumber:6
您可以看到,在每个生成的项目之间,外层 foreach 循环都会打印一条信息。在构建 LINQ 处理器方法链时,每个项目都会经过所有处理器,然后由遍历查询结果的代码处理,然后下一个项目会经过该方法链。
延迟执行对性能有很好的影响。如果你只需要查询结果中有限的几个项,那么你就不需要为那些你不关心的项支付查询执行时间。
延迟执行还允许你动态建立查询,因为在迭代查询之前不会对查询进行评估。您可以添加越来越多的操作符,而不会产生副作用:
var numbers = new[] { 1, 2, 3, 4, 5, 6 };
var query = numbers.Where(x => x%2 == 0);
if (/*指定判断条件*/)
{
query = query.Where(x => x > 5);//如果条件成立了,query中会加入新处理器
}
if (/*其他判断条件*/)
{
query = query.Where(x => x > 7);
}
foreach (var item in query) //执行到此时,query才真正开始进行评估,也就是真正开始使用处理器去循环原始集合,找到符合条件的元素
{
Console.WriteLine(item);
}
译者注:作者这里用了一个动词,英文叫evaluate,翻译成中文是评估。它其实是想表达,在使用linq时,不管你指定了多么复杂的处理器或者过滤器等。其实在指定时,linq是不做任何处理的。例如代码query.Where(x => x > 5),这一行瞬间就执行过去了,才不管你query有多少元素,因为linq底层压根没去循环处理数据。那这一行干啥了?可以理解成在query中的处理器队列中,增了一个where处理器,判断算法是大于5。那什么时候开始处理数据呢,在foreach (var item in query)这一行开始的,而作者就把linq真正开始干活的时点叫做评估。
3.5 小结
C# 作为一种面向对象的语言于 2002 年问世。从那时起,C# 收集了其他语言的特点和风格,成为一种多范式语言。
-
函数式编程风格旨在创建声明式的简洁代码,简短易读。
-
使用 C# 所采用的声明式编程风格、一等函数和简洁编码等技术可以提高您的工作效率。
-
在 C# 中,您可以使用委托来提供一流的高阶函数。
-
可重用的 Action 和 Func 类型可帮助您将函数表达为参数。
-
匿名方法和 lambda 表达式可让您轻松使用这些方法,并将代码作为参数发送。
-
在 C# 中,您可以使用方法链技术来构建特定域语言(DSL) 来表达您编程的领域。
-
扩展方法可以让您在无法获得类型源代码或无法使用类型源代码的情况下,轻松地为类型添加功能。当您无法访问类型源代码或不想修改其代码时,扩展方法可以方便地为类型添加功能。
-
要实现方法链,请使用流畅接口和扩展方法。
-
LINQ 使对集合的查询变得超级简单,它的抽象可以允许针对不同的底层资源库,执行相同的查询。
-
您可以使用 LINQ 进行筛选集合的简单查询,也可以进行将两个集合连接起来的复杂查询。
-
匿名类型可简化查询,因为它提供了内联创建类型的功能。创建类型,用于存储仅在作用域内可见的查询结果。
-
推迟执行(Deferred execution)允许程序在使用查询结果时现去执行,而不是在创建查询时执行。
-
下一章将讨论创建 Rx 查询的第一部分,以及创建Observable(可观察序列),每个 Rx 查询都是基于他实现的,因此将介绍它的基础知识。