【NLP】文本摘要的SOTA模型及简单代码实现
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
一、什么是文本摘要?
二、文本摘要的应用场景介绍
三、SOTA模型简介
四、文本摘要模型训练微调的代码实现
1.PEGASUS模型
4.GPT-3模型
五、总结
一、什么是文本摘要?
文本摘要是将一段长文本缩减为一段简短的内容要点的过程。它可以帮助人们快速地了解一篇文章或一段文字的主要内容,节省时间和精力。文本摘要通常分为两种类型:提取式摘要和生成式摘要。
提取式摘要使用文本中已有的句子或段落来生成摘要。这种方法通常涉及到对文本进行语言处理和关键词提取,然后从中选择最重要或最相关的内容。
生成式摘要则是从头开始生成一段新的摘要内容,而不是仅仅从原文中提取已有的句子或段落。这种方法通常涉及到使用机器学习算法或深度学习模型对文本进行理解和总结,然后根据这些理解和总结来生成新的内容。
在自然语言处理领域,文本摘要任务是一个非常重要的研究方向,因为它可以帮助人们更高效地获取信息并节省时间。
二、文本摘要的应用场景介绍
文本摘要在各种领域中都有广泛的应用场景,以下是一些常见的应用场景:
-
新闻报道:新闻机构可以使用自动化文本摘要技术来生成文章的概要,以便更好地利用有限的版面和读者的时间。
-
学术研究:学术研究人员可以使用自动文本摘要技术来快速了解大量论文的主要内容,并选择他们感兴趣的论文进行更详细的阅读。
-
商业分析:商业分析人员可以使用自动化文本摘要技术在短时间内对大量商业报告和公告进行摘要,以便更好地理解市场趋势、竞争情况和重要发展。
-
法律文件:律师可以使用文本摘要技术来对法律文件进行摘要,以便更好地理解客户的案件和制定有效的策略。
-
医学研究:医学研究人员可以使用文本摘要技术快速了解大量医学文献的主要内容,从而更好地了解最新的研究进展和医学实践。
总之,文本摘要在各种领域中都有应用,可以帮助人们更快地获取所需信息,并更好地理解文本的主要内容。
三、SOTA模型简介
目前在文本摘要领域,SOTA(State-of-the-art)模型包括以下几种:
-
PEGASUS: PEGASUS是一种使用无监督方式训练的语言模型,被证明在多项NLP任务中表现优异,特别是在文本摘要任务中。这种模型的优势在于使用了新颖的预训练目标,以及新的反向预训练技术,可以训练比Bert更大的模型。
-
T5 (Text-To-Text Transfer Transformer):T5是一个基于Transformer的预训练模型,具有出色的通用性能。T5最初是为文本生成任务(如摘要、翻译、问答等)而设计的,但它已经显示出适用于各种其他任务,例如信息抽取、情感分析和图像分类。
-
BART (Bidirectional and Auto-Regressive Transformer):BART是一种序列到序列模型,使用了Transformer的自注意力机制以及双向编码器。在各种任务中都表现出了非常好的性能,包括文本摘要。BART采用了一种预训练和微调的方式,在大规模语料库上进行预训练,然后对新任务进行微调。
-
GPT-3:GPT-3是一种基于Transformer的模型, 预训练了13亿个参数,是目前已知最大的NLP模型。GPT-3在语言生成、机器翻译、问答等任务上表现出色,但在文本摘要任务中表现还不够理想。
综上所述,当前在文本摘要领域,BART、T5、PEGASUS等预训练模型取得了较好的效果。
四、文本摘要模型训练微调的代码实现
1.PEGASUS模型
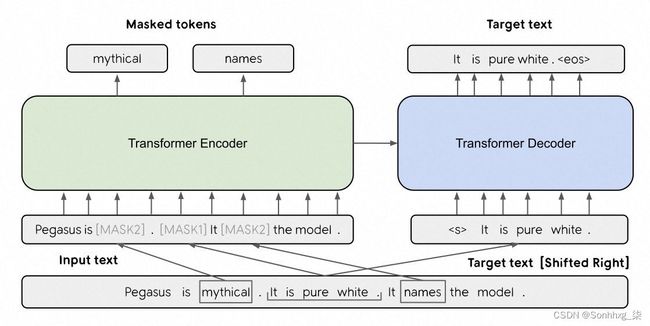
以下是一个简单的PEGASUS模型的PyTorch代码实现,带有注释解释各个部分的作用:
import torch
import transformers
class PegasusSummarizer(torch.nn.Module):
def __init__(self, model_name):
super().__init__()
#加载预训练的模型
self.model = transformers.PegasusForConditionalGeneration.from_pretrained(model_name)
#获取tokenizer以进行文本编码
self.tokenizer = transformers.PegasusTokenizer.from_pretrained(model_name)
def forward(self, input_text):
#编码输入文本以生成输入IDs
input_ids = self.tokenizer.encode(input_text, return_tensors='pt')
#使用PEGASUS模型对输入IDs执行摘要
summary_ids = self.model.generate(input_ids)
#解码摘要IDs以生成输出文本
summary_text = self.tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return summary_text在这个实现中,我们定义了一个PegasusSummarizer类,它接受一个预训练PEGASUS模型的名称作为参数,在初始化中加载了预训练模型并获得相应的tokenizer对象。在forward方法中,我们编码输入文本以生成输入IDs,然后使用PEGASUS模型对其进行摘要处理,并将结果解码为摘要文本。
PEGASUS的微调模型代码Pytorch实现
import torch
import transformers
from torch.utils.data import DataLoader, Dataset
import argparse
#定义PEGASUS微调模型
class PegasusFineTuner(torch.nn.Module):
def __init__(self, model_name):
super().__init__()
# 加载预训练的PEGASUS模型
self.tokenizer = transformers.PegasusTokenizer.from_pretrained(model_name)
self.model = transformers.PegasusForConditionalGeneration.from_pretrained(model_name)
def forward(self, inputs):
#获取encoder输入及attention mask(遮蔽器)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
#使用模型生成摘要
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids
)
return outputs.loss, outputs.logits
#定义加载数据集的类
class MyDataset(Dataset):
def __init__(self, data_path):
#从文件中读取数据
with open(data_path) as f:
self.data = f.readlines()
#初始化tokenizer
self.tokenizer = transformers.PegasusTokenizer.from_pretrained('google/pegasus-xsum')
#提取摘要和文本
self.summaries = [line.split('\t')[0].strip() for line in self.data]
self.texts = [line.split('\t')[1].strip() for line in self.data]
def __getitem__(self, idx):
#编码文本以生成输入IDs
input_text = self.texts[idx]
input_ids = self.tokenizer.encode(input_text, return_tensors='pt', truncation=True, padding='max_length', max_length=512)
#编码摘要以生成标签IDs
summary_text = self.summaries[idx]
summary_ids = self.tokenizer.encode(summary_text, return_tensors='pt', truncation=True, padding='max_length', max_length=64)
#返回字典类型的数据
return {'input_ids':input_ids.squeeze(0), 'attention_mask':(input_ids != 0).squeeze(0), 'labels':summary_ids.squeeze(0)}
def __len__(self):
return len(self.data)
#定义训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, batch_data in enumerate(train_loader):
#将数据移到指定计算设备上
batch_data = {k:v.to(device) for k, v in batch_data.items()}
#清零梯度
optimizer.zero_grad()
#向前传递批量数据以获得损失
loss, _ = model(batch_data)
#向后传递损失并更新权重
loss.backward()
optimizer.step()
#每隔一定间隔打印训练状态信息
if batch_idx % 10 == 0:
print('Epoch {}\tBatch [{}/{}]\tLoss: {:.4f}'.format(
epoch, batch_idx * len(batch_data['input_ids']), len(train_loader.dataset),
loss.item()))
if __name__ == '__main__':
#设置GPU或CPU作为计算设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default='train.csv', help='path to the training data')
parser.add_argument('--model_name', type=str, default='google/pegasus-xsum', help='name of the pre-trained model')
parser.add_argument('--batch_size', type=int, default=16, help='size of each batch for training')
parser.add_argument('--num_epochs', type=int, default=10, help='number of epochs for training')
args = parser.parse_args()
#加载模型并移动到指定设备上
model = PegasusFineTuner(args.model_name).to(device)
#加载数据集并使用DataLoader迭代数据
train_dataset = MyDataset(args.data)
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
#定义AdamW优化器并开始训练
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
for epoch in range(1, args.num_epochs + 1):
train(model, device, train_loader, optimizer, epoch)2.T5 模型
以下是使用T5模型进行文本摘要的PyTorch代码示例:
import torch
import transformers
# 定义T5FineTuner类
class T5FineTuner(torch.nn.Module):
def __init__(self, model_name):
super().__init__()
# 加载预训练的T5模型
self.tokenizer = transformers.T5Tokenizer.from_pretrained(model_name)
self.model = transformers.T5ForConditionalGeneration.from_pretrained(model_name)
def forward(self, inputs):
# 获取encoder输入及attention mask(遮蔽器)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
# 使用模型生成摘要
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids
)
return outputs.loss, outputs.logits
# 定义加载数据集的类
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data_path, max_length):
# 从文件中读取数据
with open(data_path) as f:
self.data = f.readlines()
# 初始化tokenizer
self.tokenizer = transformers.T5Tokenizer.from_pretrained('t5-small')
# 限制输入和输出长度
self.max_length = max_length
def __getitem__(self, idx):
# 编码文本以生成输入IDs
input_text = self.data[idx].strip()
input_ids = self.tokenizer.encode(input_text, return_tensors='pt', truncation=True, padding='max_length', max_length=self.max_length)
# 返回字典类型的数据
return {'input_ids': input_ids.squeeze(0), 'attention_mask': (input_ids != 0).squeeze(0)}
def __len__(self):
return len(self.data)
# 定义训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, batch_data in enumerate(train_loader):
# 将数据移到指定计算设备上
batch_data = {k:v.to(device) for k, v in batch_data.items()}
# 清零梯度
optimizer.zero_grad()
# 向前传递批量数据以获得损失
loss, _ = model(batch_data)
# 向后传递损失并更新权重
loss.backward()
optimizer.step()
# 每隔一定间隔打印训练状态信息
if batch_idx % 10 == 0:
print('Epoch {}\tBatch [{}/{}]\tLoss: {:.4f}'.format(
epoch, batch_idx * len(batch_data['input_ids']), len(train_loader.dataset),
loss.item()))
if __name__ == '__main__':
# 设置GPU或CPU作为计算设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default='train.txt', help='path to the training data')
parser.add_argument('--model_name', type=str, default='t5-small', help='name of the pre-trained model')
parser.add_argument('--batch_size', type=int, default=16, help='size of each batch for training')
parser.add_argument('--num_epochs', type=int, default=10, help='number of epochs for training')
parser.add_argument('--max_length', type=int, default=512, help='maximum length of input and output sequences')
args = parser.parse_args()
# 加载模型并移动到指定设备上
model = T5FineTuner(args.model_name).to(device)
# 加载数据集并使用DataLoader迭代数据
train_dataset = MyDataset(args.data, args.max_length)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
# 定义AdamW优化器并开始训练
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
for epoch in range(1, args.num_epochs + 1):
train(model, device, train_loader, optimizer, epoch)在这个例子中,我们首先定义了用于微调T5的模型,并在初始化中加载了预训练模型和tokenizer。我们还定义了一个MyDataset类,用于从文件中读取数据,并使用tokenizer对其进行编码。然后,我们定义了一个训练函数,在每个epoch中迭代数据并更新模型参数。我们使用AdamW优化器作为优化器,并使用DataLoader从MyDataset中读取数据进行训练。
3.BART模型
以下是使用BART进行文本摘要的PyTorch代码实现:
import torch
import transformers
# 定义BARTFineTuner类
class BARTFineTuner(torch.nn.Module):
def __init__(self, model_name):
super().__init__()
# 加载预训练的BART模型
self.tokenizer = transformers.BartTokenizer.from_pretrained(model_name)
self.model = transformers.BartForConditionalGeneration.from_pretrained(model_name)
def forward(self, inputs):
# 获取encoder输入及attention mask(遮蔽器)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
# 使用模型生成摘要
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=input_ids[:, :-1].contiguous(),
labels=input_ids[:, 1:].contiguous()
)
return outputs.loss, outputs.logits
# 定义加载数据集的类
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data_path, max_source_length, max_target_length):
# 从文件中读取数据
with open(data_path) as f:
self.data = f.readlines()
# 初始化tokenizer
self.tokenizer = transformers.BartTokenizer.from_pretrained('facebook/bart-large-cnn')
# 限制输入和输出长度
self.max_source_length = max_source_length
self.max_target_length = max_target_length
def __getitem__(self, idx):
# 划分输入和输出文本,并将其编码以生成输入IDs和输出IDs
input_text, output_text = self.data[idx].strip().split('\t')
input_ids = self.tokenizer.encode(
input_text, return_tensors='pt',
truncation=True, padding='max_length',
max_length=self.max_source_length
)
output_ids = self.tokenizer.encode(
output_text, return_tensors='pt',
truncation=True, padding='max_length',
max_length=self.max_target_length
)
# 返回字典类型的数据
return {'input_ids': input_ids.squeeze(0), 'attention_mask': (input_ids != 0).squeeze(0),
'target_ids': output_ids.squeeze(0)}
def __len__(self):
return len(self.data)
# 定义训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, batch_data in enumerate(train_loader):
# 将数据移到指定计算设备上
batch_data = {k: v.to(device) for k, v in batch_data.items()}
# 清零梯度
optimizer.zero_grad()
# 向前传递批量数据以获得损失
loss, _ = model(batch_data)
# 向后传递损失并更新权重
loss.backward()
optimizer.step()
# 每隔一定间隔打印训练状态信息
if batch_idx % 10 == 0:
print('Epoch {}\tBatch [{}/{}]\tLoss: {:.4f}'.format(
epoch, batch_idx * len(batch_data['input_ids']), len(train_loader.dataset),
loss.item()))
if __name__ == '__main__':
# 设置GPU或CPU作为计算设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default='train.txt', help='path to the training data')
parser.add_argument('--model_name', type=str, default='facebook/bart-large-cnn', help='name of the pre-trained model')
parser.add_argument('--batch_size', type=int, default=4, help='size of each batch for training')
parser.add_argument('--num_epochs', type=int, default=3, help='number of epochs for training')
parser.add_argument('--max_source_length', type=int, default=1024, help='maximum length of input sequences')
parser.add_argument('--max_target_length', type=int, default=128, help='maximum length of output sequences')
args = parser.parse_args()
# 加载模型并移动到指定设备上
model = BARTFineTuner(args.model_name).to(device)
# 加载数据集并使用DataLoader迭代数据
train_dataset = MyDataset(args.data, args.max_source_length, args.max_target_length)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
# 定义AdamW优化器并开始训练
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
for epoch in range(1, args.num_epochs + 1):
train(model, device, train_loader, optimizer, epoch)在这个例子中,我们首先定义了用于微调BART的模型,并在初始化中加载了预训练模型和tokenizer。我们还定义了一个MyDataset类,用于从文件中读取数据,并使用tokenizer对其进行编码。然后,我们定义了一个训练函数,在每个epoch中迭代数据并更新模型参数。我们使用AdamW优化器作为优化器,并使用DataLoader从MyDataset中读取数据进行训练。
4.GPT-3模型
以下是使用GPT-3进行文本摘要的PyTorch代码实现:
import openai
import torch
# OpenAI API key
openai.api_key = "YOUR_API_KEY"
# 定义GPT3FineTuner类
class GPT3FineTuner(torch.nn.Module):
def __init__(self, model_name_or_id):
super().__init__()
# 初始化OpenAI GPT-3模型
self.model_name_or_id = model_name_or_id
def forward(self, inputs):
input_text = inputs['input_text']
# 使用OpenAI API生成摘要
response = openai.Completion.create(
engine=self.model_name_or_id,
prompt=input_text,
max_tokens=1024,
n = 1,
stop=None,
temperature=0.7,
)
summary_text = response.choices[0].text.strip()
return summary_text
if __name__ == '__main__':
# 设置GPU或CPU作为计算设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--model_name_or_id', type=str, default='text-davinci-002', help='name or ID of the GPT-3 model')
args = parser.parse_args()
# 加载模型并移动到指定设备上
model = GPT3FineTuner(args.model_name_or_id).to(device)
# 输入原始文本
input_text = "这是一段原始文本,需要进行摘要。"
# 生成摘要
summary_text = model({'input_text': input_text})
# 打印生成的摘要
print(summary_text)在这个例子中,我们使用OpenAI API进行文本摘要任务。我们首先定义一个GPT3FineTuner类,在初始化中设置OpenAI API密钥和GPT-3模型名称或ID。然后,我们定义了一个forward函数,该函数将输入文本传递给OpenAI API以生成摘要,并返回生成的摘要。最后,在主函数中,我们加载模型并使用输入文本调用forward函数以生成摘要,并打印输出。
五、总结
文本摘要技术在过去几十年中已经有了很大的发展。最开始的文本摘要方法是基于统计方法的提取式摘要,这种方法主要是利用关键词和短语出现频率、位置和语境等信息来确定文本中最具代表性的句子和段落。
随着机器学习技术和自然语言处理技术的发展,文本摘要技术也发生了很大变化。近年来,深度学习技术已成为自动化文本摘要领域的重要推动力量。由于深度学习模型被证明能够更好地理解和生成文本,因此深度学习模型在生成式摘要方面表现出更好的结果。
目前,基于深度学习的生成式摘要方法已经成为文本摘要任务中的主流方法,包括循环神经网络、变换器模型和预训练语言模型等。同时,提取式摘要方法也在不断改进和优化,涉及到更高级别的语义分析和自然语言处理技术。这些技术的不断发展和完善,使得文本摘要在各个领域中都有更广泛的应用和更高的准确率。
总之,随着技术的不断发展和研究的深入,文本摘要技术将会进一步提升其效率和准确性,并被广泛应用于各个领域。