Redis - 使用+分布式
文章目录
- Redis
-
- 一、概述
-
- 1.1 首次安装
- 1.2 核心目录结构
- 1.3 命令大全
- 1.4 番外
- 二、基本操作
-
- Key
- String(字符串)
- Hash(键值对)
- List
- Set(无序唯一)
- SortedSet(有序集合)
- HyperLogLog(基数统计)
- GEO(地理位置)
- Bit(位图)
- Pub/Sub(发布/订阅)
- Transaction(事务)
- 服务器
- 客户端
- Script脚本
- 三、其他操作
-
- 3.1 持久化
-
- RDB
- AOF
- 操作方法
- 3.2 StreamMQ
- 3.3 主从复制
-
- 基本概念
- 命令参考
- 复制功能的运作原理
- 只读从服务器
- 部分重同步
- 数据安全:主限制写
- 3.4 Sentinel(哨兵模式)
-
- 基本概念
- 配置解析
- 主观下线和客观下线
- Sentinel默认定期执行的任务
- 自发现Sentinel及从服务器
- TILT模式
- 3.5 集群
-
- 数据共享
- 集群中的主从复制
- 集群创建案例
- SpringBoot下的配置
- 集群的哈希槽分片
- 四、Redis 6.0新特性
-
- 4.1 客户端缓存
- 4.2 I/O多线程(重要)
- 4.3 ACL
- 4.4 集群访问代理工具
- 4.5 布隆过滤器
- 五、其他
-
- 5.1 穿透/击穿/雪崩/预热/更新/降级
- 5.2 Pipeline管道操作
- 5.3 内存淘汰策略
- 5.4 过期删除策略
- 六、与SpringBoot的集成
-
- 6.1 依赖的导入
- 6.2 缓存所带来的问题
-
- 解决方案一:setnx+lua
- 解决方案二:Zookeeper
- 解决方案三:Redisson
- 6.3 数据库与缓存同步
- 七、Redisson
-
- 7.1 第一次/基本Api使用
- 7.2 分布式缓存锁-重入锁案例
- 更新中......
- over
Redis
一、概述
Redis(REmote DIctionary Server)是一个使用ANSI C编写的、开源的、支持网络的、基于内存的、可选持久化的键值对存储系统。在2013年5月之前,Redis的开发由VMware赞助;2013年5月至2015年6月,由Pivotal赞助;从2015年6月起,Redis的开发由Redis Labs赞助。根据数据库使用排行网站db-engines.com上的排名,Redis是目前最流行的键值对存储系统。
1.1 首次安装
Redis - 官方网址
Linux源码安装
wget http://download.redis.io/releases/redis-6.0.8.tar.gz
tar -zxvf redis-6.0.8.tar.gz
cd redis-6.0.8
make
cd src/
make install
./redis-server ../redis.conf
注意:如果c++版本过低,会在make时出现error
解决方案
Yum -y install gcc-c++
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
另外,在redis.conf的一些特殊的配置也需要弄一下
bind 0.0.0.0 # 访问限制
protected-mode no # 保护模式
port 16371 # 端口号
timeout 300 # 超时时间
daemonize yes # 是否支持后台启动
Docker 安装 Redis | 菜鸟教程 (runoob.com)
docker pull redis:latest
docker run -itd --name redis-test -p 6379:6379 redis
1.2 核心目录结构
(1)基本的数据结构
- 动态字符串sds.c
- 整数集合intset.c
- 压缩列表ziplist.c
- 快速链表quicklist.c
- 字典dict.c
- Streams的底层实现结构listpack.c和rax.c
(2)Redis数据类型的底层实现
- Redis对象object.c
- 字符串t_string.c
- 列表t_list.c
- 字典t_hash.c
- 集合及有序集合t_set.c和t_zset.c
- 数据流t_stream.c
(3)Redis数据库的实现
- 数据库的底层实现db.c
- 持久化rdb.c和aof.c
(4)Redis服务端和客户端实现
- 事件驱动ae.c和ae_epoll.c
- 网络连接anet.c和networking.c
- 服务端程序server.c
- 客户端程序redis-cli.c
(5)其他
- 主从复制replication.c
- 哨兵sentinel.c
- 集群cluster.c
- 其他数据结构,如hyperloglog.c、geo.c等
- 其他功能,如pub/sub、Lua脚本
1.3 命令大全
Redis 命令参考 — Redis 命令参考 (redisfans.com)
A:2013年更新
A:一个命令非常齐全的网站,里面包含不止是命令,还有很多例如主从复制的讲解等,是一个翻译网
Redis 命令参考 — Redis 命令参考 (redisdoc.com)
A:这个牛逼,2019年更新,不过大同小异
A:…回来看了一眼,两个文档好像没差
Redis 服务器 | 菜鸟教程 (runoob.com)
A:…还是菜鸟牛逼
1.4 番外
| 文章记录 |
|---|
| 面试官狂问Redis,清华大佬彻底讲透Redis底层原理,完整版现在免费分享给大家!_哔哩哔哩_bilibili |
| (14条消息) Redis_王义凯 的博客-CSDN博客 |
| Springboot使用RedisTemplate Cluster集群正确姿势 |
| 5分钟实现用docker搭建Redis集群模式和哨兵模式 - 程序员阿牛 - OSCHINA - 中文开源技术交流社区 |
二、基本操作
在redis中,能操作的对象有如下
Key
- DEL 删除key
- DUMP 序列化给定 key ,并返回被序列化的值
- EXISTS 检查给定 key 是否存在
- EXPIRE 为给定 key 设置过期时间,以秒计
- EXPIREAT EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳
- KEYS 查找所有符合给定模式( pattern)的 key
- MIGRATE 将key原子性地从当前实例
剪切到目标实例的指定数据库上 - MOVE 将当前的数据库key移动到某个数据库,目标库有,则不能移动
- OBJECT
- PERSIST 移除 key 的过期时间,key 将持久保持
- PEXPIRE 设置 key 的过期时间以毫秒计
- PEXPIREAT 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计
- PTTL 以毫秒为单位返回 key 的剩余的过期时间
- RANDOMKEY 从当前数据库中随机返回一个 key
- RENAME 修改 key 的名称
- RENAMENX 仅当 newkey 不存在时,将 key 改名为 newkey
- RESTORE 反序列化给定的序列化值,并将它和给定的
key关联 - SORT 排序
- TTL 以秒为单位,返回给定 key 的剩余生存时间
- TYPE 返回 key 所储存的值的类型
- SCAN 迭代数据库中的数据库键
String(字符串)
- APPEND
- BITCOUNT
- BITOP
- DECR
- DECRBY
- GET
- GETBIT
- GETRANGE
- GETSET
- INCR
- INCRBY
- INCRBYFLOAT
- MGET
- MSET
- MSETNX
- PSETEX
- SET
- SETBIT
- SETEX
- SETNX
- SETRANGE
- STRLEN
Hash(键值对)
- HDEL
- HEXISTS
- HGET
- HGETALL
- HINCRBY
- HINCRBYFLOAT
- HKEYS
- HLEN
- HMGET
- HMSET
- HSET
- HSETNX
- HVALS
- HSCAN
List
- BLPOP
- BRPOP
- BRPOPLPUSH
- LINDEX
- LINSERT
- LLEN
- LPOP
- LPUSH
- LPUSHX
- LRANGE
- LREM
- LSET
- LTRIM
- RPOP
- RPOPLPUSH
- RPUSH
- RPUSHX
Set(无序唯一)
- SADD
- SCARD
- SDIFF
- SDIFFSTORE
- SINTER
- SINTERSTORE
- SISMEMBER
- SMEMBERS
- SMOVE
- SPOP
- SRANDMEMBER
- SREM
- SUNION
- SUNIONSTORE
- SSCAN
SortedSet(有序集合)
- ZADD
- ZCARD
- ZCOUNT
- ZINCRBY
- ZRANGE
- ZRANGEBYSCORE
- ZRANK
- ZREM
- ZREMRANGEBYRANK
- ZREMRANGEBYSCORE
- ZREVRANGE
- ZREVRANGEBYSCORE
- ZREVRANK
- ZSCORE
- ZUNIONSTORE
- ZINTERSTORE
- ZSCAN
HyperLogLog(基数统计)
- PFADD
- PFCOUNT
- PFMERGE
GEO(地理位置)
- GEOADD
- GEOPOS
- GEODIST
- GEORADIUS
- GEORADIUSBYMEMBER
- GEOHASH
Bit(位图)
- SETBIT
- GETBIT
- BITCOUNT
- BITPOS
- BITOP
- BITFIELD
Pub/Sub(发布/订阅)
- PSUBSCRIBE 订阅一个或多个符合给定模式的频道。
- PUBLISH 将信息发送到指定的频道。
- PUBSUB 查看订阅与发布系统状态。
- PUNSUBSCRIBE 退订所有给定模式的频道。
- SUBSCRIBE 订阅给定的一个或多个频道的信息。
- UNSUBSCRIBE 指退订给定的频道。
Transaction(事务)
- DISCARD 取消事务,放弃执行事务块内的所有命令
- EXEC 执行事务
- MULTI 开启事务
- UNWATCH 取消 WATCH 命令对所有 key 的监视
- WATCH 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
服务器
- BGREWRITEAOF 异步执行一个 AOF(AppendOnly File) 文件重写操作
- BGSAVE 在后台异步保存当前数据库的数据到磁盘
- CLIENT GETNAME
- CLIENT KILL 关闭客户端连接
- CLIENT LIST 获取连接到服务器的客户端连接列表
- CLIENT SETNAME 设置连接名称
- CONFIG GET
- CONFIG RESETSTAT
- CONFIG REWRITE
- CONFIG SET
- DBSIZE
- DEBUG OBJECT
- DEBUG SEGFAULT
- FLUSHALL 删除所有数据库的所有key
- FLUSHDB 删除当前数据库的所有key
- INFO获取 Redis 服务器的各种信息和统计数值
- LASTSAVE
- MONITOR
- PSYNC 部分重同步,用于复制功能(replication),Redis 2.8 或以上版本用这个
- SAVE 同步保存数据到硬盘
- SHUTDOWN 异步保存数据到硬盘,并关闭服务器
- SLAVEOF 将当前服务器转变为指定服务器的从属服务器
- SLOWLOG 管理 redis 的慢日志
- SYNC 用于复制功能(replication)的内部命令,用于同步主从服务器
- TIME
客户端
- AUTH
- ECHO
- PING
- QUIT
- SELECT
Script脚本
- EVAL
- EVALSHA
- SCRIPT EXISTS
- SCRIPT FLUSH
- SCRIPT KILL
- SCRIPT LOAD
三、其他操作
3.1 持久化
就两种,一个是快照,一个是记录写操作命令,可以让从服务器代替主服务器进行持久化
RDB
在指定的时间间隔内生成数据集的时间点快照,在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中
-
优点
1、恢复大数据集时比AOF更快
2、进行备份时会fork出一个子线程,父线程不用进行这些磁盘I/O操作
3、文件小,内容紧凑
-
缺点
每次保存 RDB 的时候,Redis 都要
fork()出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时,fork()可能会非常耗时,造成服务器在某某毫秒内停止处理客户端,且会丢失一部分新产生的数据; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行fork(),但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失
AOF
记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集
修改 redis.conf 开启AOF - appendonly yes
-
优点
1、有序保存所有写操作
2、备份完整
-
缺点
1、文件体积大
2、备份速度慢
鉴于AOF备份的文件体积过大,可以执行BGREWRITEAOF命令,在不打断服务客户端的情况下对AOF备份文件进行重构优化
根据如上所属,其实redis官方也考虑到了这个问题,后期可能会开发出一个AOF+RDB的集合版本
操作方法
- SAVE
执行一个同步阻塞保存操作,将当前 Redis 实例的所有数据快照(snapshot)以 RDB 文件的形式保存到硬盘
- BGSAVE
执行一个异步非阻塞保存操作,执行之后立即返回 OK ,然后 Redis fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出
- BGREWRITEAOF
执行一个AOF文件 重写操作。重写会创建一个当前 AOF 文件的体积优化版本。
即使 BGREWRITEAOF 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 BGREWRITEAOF 成功之前不会被修改。
重写操作只会在没有其他持久化工作在后台执行时被触发
以下是 AOF 重写的执行步骤:
- Redis 执行
fork(),现在同时拥有父进程和子进程。- 子进程开始将新 AOF 文件的内容写入到临时文件。
- 对于所有新执行的写入命令,父进程一边将它们累积到一个内存缓存中,一边将这些改动追加到现有 AOF 文件的末尾: 这样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。
- 当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将内存缓存中的所有数据追加到新 AOF 文件的末尾。
- 搞定!现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。
- LASTSAVE
返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示
- redis-check-aof --fix
AOF文件出错时的一种拯救手段,一个修复工具
3.2 StreamMQ
Redis 5.0 版本新增加的数据结构,主要用于消息队列,虽然发布/订阅功能已经能完成消息队列,但是它有个致命的缺点 - 无法消息持久化
Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
Redis Stream | 菜鸟教程 (runoob.com)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
这里涉及到了RedisMQ和老牌RabbitMQ的一个对比
(13条消息) MQ对比之RabbitMQ & Redis_夜空中最亮的星-CSDN博客
RabbitMQ与Redis队列对比 - chinaboard - 博客园 (cnblogs.com)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
里面还有个键空间通知(keyspace notification)的知识点,我略过了
3.3 主从复制
基本概念
主要是用于主从的切换,但是这里的主从切换是另外一层概念
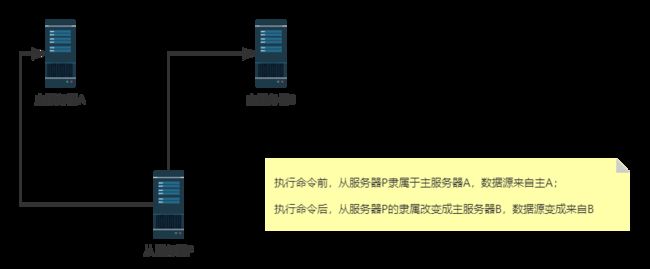
命令参考
-
SLAVEOF IP地址 端口号
将当前服务器转变为指定服务器的从属服务器
-
SLAVEOF NO ONE
关闭复制功能,把自己的身份(从属服务器)转变为主服务器(这里的主服务器不是指master)
-
ROLE
返回实例在复制中担任的角色,这个角色可以是
master、slave或者sentinel,并且还会返回如下信息,返回的是一个数组主服务器将返回属下从服务器的 IP 地址和端口。从服务器将返回自己正在复制的主服务器的 IP 地址、端口、连接状态以及复制偏移量。Sentinel将返回自己正在监视的主服务器列表。
复制功能的运作原理

在进行主从同步时,主从都是非阻塞状态,但是,从服务器进行数据恢复的时候,是阻塞的
可以通过复制功能来让主服务器免于执行持久化操作: 只要关闭主服务器的持久化功能, 然后由从服务器去执行持久化操作即可
只读从服务器
从 Redis 2.6 开始, 从服务器支持只读模式, 并且该模式为从服务器的默认模式。
只读模式由 redis.conf 文件中的 slave-read-only 选项控制, 也可以通过 CONFIG SET 命令来开启或关闭这个模式
部分重同步
当主从进行复制的时候,网络断了,需要重新从头到尾再复制一次吗?
不不不
Redis 2.8 或以上版本已经可以做部分重同步,类似于断点续传,用的是PSYNC命令
从 Redis 2.8 开始, 在网络连接短暂性失效之后, 主从服务器可以尝试继续执行原有的复制进程(process), 而不一定要执行完整重同步操作。
这个特性需要主服务器为被发送的复制流创建一个内存缓冲区(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个复制偏移量(replication offset)和一个主服务器 ID (master run id), 当出现网络连接断开时, 从服务器会重新连接, 并且向主服务器请求继续执行原来的复制进程:
- 如果从服务器记录的主服务器 ID 和当前要连接的主服务器的 ID 相同, 并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面, 那么主服务器会向从服务器发送断线时缺失的那部分数据, 然后复制工作可以继续执行。
- 否则的话, 从服务器就要执行完整重同步操作。
数据安全:主限制写
从 Redis 2.8 开始, 为了保证数据的安全性, 可以通过配置, 让主服务器只在有至少 N 个当前已连接从服务器的情况下, 才可以执行写命令
不过, 因为 Redis 使用异步复制, 所以主服务器发送的写数据并不一定会被从服务器接收到, 因此, 数据丢失的可能性仍然是存在的。
以下是这个特性的运作原理:
- 从服务器以每秒一次的频率 PING 主服务器一次, 并报告复制流的处理情况。
- 主服务器会记录各个从服务器最后一次向它发送 PING 的时间。
- 用户可以通过配置, 指定网络延迟的最大值
min-slaves-max-lag, 以及执行写操作所需的至少从服务器数量min-slaves-to-write
如果至少有 min-slaves-to-write 个从服务器, 并且这些服务器的延迟值都少于 min-slaves-max-lag 秒, 那么主服务器就会执行客户端请求的写操作。
你可以将这个特性看作 CAP 理论中的 C 的条件放宽版本: 尽管不能保证写操作的持久性, 但起码丢失数据的窗口会被严格限制在指定的秒数中。
另一方面, 如果条件达不到 min-slaves-to-write 和 min-slaves-max-lag 所指定的条件, 那么写操作就不会被执行, 主服务器会向请求执行写操作的客户端返回一个错误。
以下是这个特性的两个选项和它们所需的参数:
min-slaves-to-writemin-slaves-max-lag
3.4 Sentinel(哨兵模式)
基本概念
在默认情况下, Sentinel 使用 TCP 端口 26379 (普通 Redis 服务器使用的是 6379 )
Redis Sentinel Documentation – Redis
Redis 的 Sentinel 系统用于管理多个 Redis 服务器
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器
运行一个哨兵也非常简单,redis官方包已经把哨兵集成一块了,就一个命令
./redis-sentinel ../sentinel.conf
配置解析
运行一个 Sentinel 所需的最少配置如下所示
sentinel monitor mymaster 127.0.0.1 6379 2
# 监视一个名为 mymaster 的主服务器,IP 地址为 127.0.0.1,端口号为 6379
# 这个主服务器判断为失效至少需要 2个Sentinel同意
# 不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数Sentinel的支持, 才能发起一次自动故障迁移
sentinel down-after-milliseconds mymaster 60000
# 指定 Sentinel 认为服务器已经断线所需的毫秒数
# 不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移:只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线, 这时自动故障迁移才会执行。
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 3
# 在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长
主观下线和客观下线
很好理解
主观下线:单台哨兵对服务器的决断,觉得他出现问题下线了
客观下线:集群哨兵对服务器的决断,是真正的会执行下线后的动作,是投票后的决断
客观下线条件
只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
Sentinel默认定期执行的任务
1、Sentinel每秒向 主、从、Sentinel 实例发送PING命令
2、Sentinel每10秒向 主、从、Sentinel 实例发送INFO命令,如果被标记了主观下线,那时间就变成每秒
3、如果一个主服务器被标记主观下线,那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态,然后进行投票是否标记为客观下线
4、如果投票结果大多数认为没下线,那客观下线状态会移除
服务器对PING命令的有效回复可以是以下三种回复的其中一种:
- 返回
+PONG。 - 返回
-LOADING错误。 - 返回
-MASTERDOWN错误。
自发现Sentinel及从服务器
我们不用特意去配置哨兵的地址或者从服务器的地址给这台哨兵,它自己会通过发布/订阅功能自动发现其他Sentinel,而且会向主服务器询问其他从服务器
Sentinel只有订阅功能
TILT模式
Sentinel 很依赖计算机的时间功能,如果系统时间出现故障,那 Sentinel 也会出现问题
如果发现系统不对劲,那 Sentinel 会进入 TILT模式
当 Sentinel 进入 TILT 模式时, 它仍然会继续监视所有目标, 但是:
- 它不再执行任何操作,比如故障转移。
- 当有实例向这个 Sentinel 发送
SENTINEL is-master-down-by-addr命令时, Sentinel 返回负值: 因为这个 Sentinel 所进行的下线判断已经不再准确。如果 TILT 可以正常维持 30 秒钟, 那么 Sentinel 退出 TILT 模式
3.5 集群
用不专业的话讲,就是一群服务器拼一起用,数据互通
数据共享
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现
集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个哈希槽, 其中
- 节点 A 负责处理
0号至5500号哈希槽 - 节点 B 负责处理
5501号至11000号哈希槽 - 节点 C 负责处理
11001号至16384号哈希槽
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了
- 与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了
集群中的主从复制
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000 号的哈希槽。
Redis 集群
不保证数据的强一致性: 在特定条件下, Redis 集群可能会丢失已经被执行过的写命令
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
集群创建案例
Redis 集群由多个运行在集群模式(cluster mode)下的 Redis 实例组成, 实例的集群模式需要通过配置来开启, 开启集群模式的实例将可以使用集群特有的功能和命令。
以下是一个包含了最少选项的集群配置文件示例:
pidfile "/var/run/redis_16371.pid"
port 16371
cluster-enabled yes
cluster-config-file nodes-16371.conf
cluster-node-timeout 15000
appendonly yes #AOF
文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf 。
节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
要让集群正常运作至少需要三个主节点,不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点。
# 先把redis跑起来
redis-1/src/redis-server redis-1/redis.conf
redis-2/src/redis-server redis-2/redis.conf
redis-3/src/redis-server redis-3/redis.conf
redis-4/src/redis-server redis-4/redis.conf
redis-5/src/redis-server redis-5/redis.conf
redis-6/src/redis-server redis-6/redis.conf
# 集群连接
./redis-cli --cluster create --cluster-replicas 1 127.0.0.1:16371 127.0.0.1:16372 127.0.0.1:16373 127.0.0.1:16374 127.0.0.1:16375 127.0.0.1:16376
# 不要用127.0.0.1 会出事,在集群连接的时候就出事了
./redis-cli --cluster create --cluster-replicas 1 192.168.247.173:16371 192.168.247.173:16372 192.168.247.173:16373 192.168.247.173:16374 192.168.247.173:16375 192.168.247.173:16376
集群创建成功后,有如下提示
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
查看一下集群状态
# 使用-c进行集群连接
[root@centos7-01 src]# ./redis-cli -c -p 16371
127.0.0.1:16371> CLUSTER SLOTS
1) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 16371
3) "3c75bbaf00ee2cea2fd7990f00fdc7cd052803a7"
4) 1) "127.0.0.1"
2) (integer) 16374
3) "eba3239f5f0c02278c1f53da7e1a949aa1498a7c"
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 16372
3) "a32228703d5f8b66b28a770b06eb48f1bf30f2cc"
4) 1) "127.0.0.1"
2) (integer) 16375
3) "592b9c4e3930d91ebdb8faeb4502deb875aeacf2"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 16373
3) "56963cf7ea8e37162ae95657606e3ec48771c123"
4) 1) "127.0.0.1"
2) (integer) 16376
3) "1464e2c266eb9538893818aacc90ce7c09c8eaec"
SpringBoot下的配置
spring:
application:
name: service-item
redis:
# host: 47.106.207.254
# port: 6379
# database: 0
cluster:
nodes: 192.168.247.177:16371,192.168.247.177:16372,192.168.247.177:16373,192.168.247.177:16374,192.168.247.177:16375,192.168.247.177:16376
maxRedirects: 3
集群的哈希槽分片
执行以下命令可以开始一次重新分片操作:
./redis-trib.rb reshard 127.0.0.1:7000
你只需要指定集群中其中一个节点的地址, redis-trib 就会自动找到集群中的其他节点
四、Redis 6.0新特性
4.1 客户端缓存
看不太懂用处
4.2 I/O多线程(重要)
FAQ – Redis
Redis系列(十六)、Redis6新特性之IO多线程_王义凯 的CSDN博客
为什么Redis以前是单线程
什么是Redis的I/O多线程
Redis的核心并发框架采用的是Netty,其实这里的多线程就是Netty的多线程Reactor模式
它的性能瓶颈在哪呢?
当 socket 中有数据时,Redis 会通过系统调用将数据从内核态拷贝到用户态,供 Redis 解析用。这个拷贝过程是阻塞的,数据量越大拷贝的延迟越高,时间消耗也越大,糟糕的是这些操作都是单线程处理的
所以引入了多线程Redis,读写任务拆分出来给一组独立的线程执行
4.3 ACL
用户权限管理,访问Redis的用户可以进行数据授权,根据权限来进行不同的操作,保障数据安全性
4.4 集群访问代理工具
我们去访问一个集群时,不需要知道它的具体节点个数和主从身份,可以直接通过代理进行访问,就像访问单机一样丝滑
4.5 布隆过滤器
常用于判断某个元素是否在一个集合中
五、其他
5.1 穿透/击穿/雪崩/预热/更新/降级
Redis系列(二十)、缓存穿透、击穿、雪崩、预热、更新、降级_王义凯 的博客-CSDN博客
| 概念 | 解决方案 | |
|---|---|---|
| 缓存穿透 | 当查询Redis中没有的数据时,该查询会下沉到数据库层,同时数据库层也没有该数据 |
1.在接口访问层对用户进行校验判断,防止恶意流量;;2.利用布隆过滤器,将数据库层有的数据key存储在位数组中,以判断访问的key在底层数据库中是否存在;;3.京东的hotkeys开源框架也可以;;4.redisson框架 |
| 缓存击穿 | 跟穿透的区别就是,数据库层有数据,大量查询下沉到数据库,使其压力剧增 |
1.热点key延长过期时间或永不过期,做好高并发接口;;2.互斥锁 |
| 缓存雪崩 | 缓存击穿的大面积版,所有的key几乎都过期了 |
1.分散key的过期时间;;2.对于一定要在固定时间让key失效的场景(例如每日12点准时更新所有最新排名),可以在固定的失效时间时在接口服务端设置随机延时,将请求的时间打散,让一部分查询先将数据缓存起来 |
| 数据预热 | 系统刚上线时,缓存数据为空,容易造成上面的几种情况 |
1.提前把热key存储起来;;2.写个批处理任务定时往缓存扔key |
| 更新 | 主要是缓存和数据库数据一致性问题如何保证 | 内容太多,写在下面 |
| 降级 | 把不重要的任务先暂时降级停止,例如双11的时候淘宝不让修改送货地址的数据,保证下单功能正常 | 没有解决方案,是一种取舍,资源有限 |
关于缓存与数据库数据一致性的解决方案
Redis与数据库一致性问题分析_diweikang的博客-CSDN博客
- 先更新数据库,再更新缓存(不考虑,并发下会存在脏数据)
- 先删除缓存,再更新数据库(一般用这个,+延迟双删)
- 先更新数据库,再删除缓存
5.2 Pipeline管道操作
Redis默认每次执行请求都会创建和断开一次连接池的操作,如果想执行多条命令的时候会在这件事情上消耗过多的时间,因此我们可以使用Redis的管道来一次性发送多条命令并返回多个结果,节约发送命令和创建连接的时间提升效率
就是通过批处理的形式一次性发送很多条命令
5.3 内存淘汰策略
Redis系列(十七)、Redis中的内存淘汰策略和过期删除策略_王义凯 的博客-CSDN博客
当内存不足时,Redis会根据相应的策略淘汰部分的keys,以保证写入成功。当无淘汰策略时或没有找到适合淘汰的key时,Redis直接返回out of memory错误
我们可以在Redis设置内存的最大值
## 配置文件
maxmemory <bytes>
下面的写法均合法:
maxmemory 1024000
maxmemory 1GB
maxmemory 1G
maxmemory 1024KB
maxmemory 1024K
maxmemory 1024MB
...
## 命令行
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
127.0.0.1:6379> config set maxmemory 1GB
OK
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "1073741824"
在缓存的内存淘汰策略中有FIFO、LRU、LFU三种,其中LRU和LFU是Redis在使用的
Redis的淘汰策略有如下这些
- volatile-lru:设置了过期时间的key使用LRU算法淘汰
- allkeys-lru:所有key使用LRU算法淘汰
- volatile-lfu:设置了过期时间的key使用LFU算法淘汰
- allkeys-lfu:所有key使用LFU算法淘汰
- volatile-random:设置了过期时间的key使用随机淘汰
- allkeys-random:所有key使用随机淘汰
- volatile-ttl:设置了过期时间的key根据过期时间淘汰,越早过期越早淘汰
- noeviction:默认策略,当内存达到设置的最大值时,所有申请内存的操作都会报错(如set,lpush等),只读操作如get命令可以正常执行
使用下面的参数maxmemory-policy配置淘汰策略
## 配置文件
maxmemory-policy noeviction
## 命令行
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
127.0.0.1:6379> config set maxmemory-policy allkeys-random
OK
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-random"
5.4 过期删除策略
上述的情况是处于内存已满的淘汰策略,那么内存未满的时候如何进行优化内存呢
这里有两个知识点
-
Redis过期Key的清理
当Redis的Key过期时,不会立刻从内存进行删除,而是同时通过如下两种策略进行清理
惰性删除:Key过期时不会立刻清理,而是当下次被访问这个Key的时候检查过期时间,过期则清理
定期删除:通过定时扫描过期的Key进行批量清理
-
RDB/AOF的过期删除策略
进行存储备份数据时,不会把过期的Key也存储进去
但是如果在AOF模式下,当Key进行了清理的时候,也会发送Del指令给AOF清理过期的Key
六、与SpringBoot的集成
6.1 依赖的导入
第一步永远都是依赖,先看看有哪些依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
dependency>
<dependency>
<groupId>org.redissongroupId>
<artifactId>redisson-spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
接下来就是使用,最初关于第一个redisTamplate的依赖,我们要做一个配置类进行相关的设置。
例如序列化的问题,这个配置类我归类到工具文件夹下了
6.2 缓存所带来的问题
缓存一般是用来缓解数据库的访问压力,提高访问速度,处理不当会造成许多问题
- 缓存穿透
- 缓存击穿
- 缓存雪崩
以上问题,都可以使用同步锁来限制缓存对数据库的访问,但是在分布式系统中,同步锁无法锁住分布式请求,所以需要使用redisson分布式锁,来完成数据库的访问代码
本地锁只能锁住同一工程内的资源,在分布式系统里面都存在局限性
分布式锁解决方案
- Redis set nx:只有在键不存在的时候才能对键进行操作
- redisson:分布式锁的框架,是基于上面那个东东,原理差不多
解决方案一:setnx+lua
使用 redis 的特性 redisTemplate.opsForValue().setIfAbsent
set key value px milliseconds nx也行
这些实现方式有几个要点
- value具有唯一性
- 解锁验证value,不要解错锁了
import com.ljm.util.ResultToOut;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.Arrays;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* 测试Redis灵不灵
*
* @author 李家民
*/
@RestController
@RequestMapping("/api/item")
public class TestController {
@Resource
RedisTemplate redisTemplate;
/**
* 就当这个数据在数据库
* 模拟
*/
public static Map<String, String> dbMap;
/**
* 缓存测试 - redisTemplate.opsForValue().setIfAbsent
*
* @return
*/
@RequestMapping("/test")
public ResultToOut test(HttpServletRequest request) {
// 来了一个请求
String requestHeader = request.getHeader("User-Agent");
System.out.println("user:" + requestHeader + " is coming");
// 查询缓存
String redisData = (String) redisTemplate.opsForValue().get("test" + ":" + "ljmNum01");
// 判断是否有数据
if (redisData == null) {
// 加入分布式锁
String uuid = UUID.randomUUID().toString();
Boolean OK = redisTemplate.opsForValue().setIfAbsent("imLockKey", uuid, 2, TimeUnit.SECONDS);
// 为什么这里是OK呢,因为 setIfAbsent 如果发现已经存在value,则会set失败,并且在这里设置了超时时间,不会有线程一直握着这个锁
if (OK) {
System.out.println("user成功拿到分布式锁 :" + requestHeader);
// 查询DB ...... 在缓存无果的情况下,访问db,所以要使用分布式锁限制对db的访问频率
String dbValues = dbMap.get("test" + ":" + "ljmNum01");
// 如果数据库有数据才继续,这是为了防止恶意流量
if (null != dbValues) {
// 同步缓存
redisTemplate.opsForValue().set("test" + ":" + "ljmNum01", "imValues01");
} else {
// 数据库里面没有这个数据,可能是恶意流量,搞他
redisTemplate.opsForValue().set("我是key", "你想干嘛?", 10, TimeUnit.SECONDS);
}
/**
* 拿了锁别忘记释放,方法有两种
* 1.普通释放
* 2.lua脚本释放
*/
/**
// 1.普通释放
String uuidCheck = (String) redisTemplate.opsForValue().get("imLockKey");
if (!StringUtils.isEmpty(uuidCheck) && uuidCheck.equals(uuid)) {
redisTemplate.delete("imLockKey");
}
*/
// 2.lua脚本释放
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 设置lua脚本返回的数据类型
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
// 设置lua脚本返回类型为Long
redisScript.setResultType(Long.class);
redisScript.setScriptText(script);
redisTemplate.execute(redisScript, Arrays.asList("imLockKey"), uuid);
} else {
// 这个else是,如果其他线程拿了锁在操作,那就让其他线程自旋回源程序
// return getSkuById(skuId);没理解
// 我觉得是递归回去当前的代码
}
}
return ResultToOut.ok(redisData);
}
}
上面的代码还是有缺陷的,我抛出两个问题给大家
- redisTemplate.opsForValue().setIfAbsent是原子性操作吗
- redisTemplate.opsForValue().get也是原子性操作吗
当线程1执行完判断是否为自己的锁的时候 是自己的锁 但恰巧锁过期
线程2去拿锁 线程1继续执行 此时线程1把线程2的锁干掉了
删除锁和判断之间缺乏原子性
相信聪明的你已经发现了,我觉得这个角度比较刁钻,我也没有特地研究过是不是原子性,但是风险就摆在这里,我也懒得去研究,所以,用redisson去吧
上面的方案可以套用AOP的代码,让你的编码更清新更爽
解决方案二:Zookeeper
Zookeeper实现分布式锁_forever-and-ever的博客-CSDN博客
这个解决方案主要还是利用Zookeeper节点特性:临时顺序节点(EPHEMERAL_SEQUENTIAL)
- 在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
- Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
- 这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
- Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
- …
解决方案三:Redisson
第七章节有专门的解释,这个挺高级的
这个配置类是集群部署模式,也有单节点的,代码是不一样的,具体看看手册
我也是研究了蛮久的,先做一个案例出来
spring:
application:
name: redisson-demo
redis:
# host: 47.106.207.254
# port: 6379
# database: 0
cluster:
nodes: 192.168.247.177:16371,192.168.247.177:16372,192.168.247.177:16373,192.168.247.177:16374,192.168.247.177:16375,192.168.247.177:16376
maxRedirects: 3
pom依赖弄进去,然后做一个简单的配置类
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Redisson的配置类
* 那些具体的配置信息直接看使用手册
*
* @author 李家民
*/
@Configuration
public class RedissonConfig {
@Bean(name = "redissonClient")
public RedissonClient redissonClient() {
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000)
.addNodeAddress
("redis://192.168.247.177:16371",
"redis://192.168.247.177:16372",
"redis://192.168.247.177:16373",
"redis://192.168.247.177:16374",
"redis://192.168.247.177:16375",
"redis://192.168.247.177:16376"
).setTimeout(5000);
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}
然后直接用起来,RedissonClient通过自动装配获取
我发现这个Redisson真的是博大精深,我要专门开多一个章节进行记录
6.3 数据库与缓存同步
1
七、Redisson
这个Redisson使用手册非常好用!!!!必看!!!!!!!
| 文章 |
|---|
| Redisson 使用手册-在线教程-面试哥 (mianshigee.com) |
| 集成版本确认/redisson-spring-boot-starter at master · redisson/redisson (github.com) |
| Redlock:Redis分布式锁最牛逼的实现 - 简书 (jianshu.com) |
| Redisson实现Redis分布式锁的N种姿势 - 简书 (jianshu.com) |
| 那个使用手册好用,老手直接看手册 |
| Redisson实现分布式锁(1)—原理 - 雨点的名字 - 博客园 (cnblogs.com) |
| Redisson实现分布式锁(2)—RedissonLock - 雨点的名字 - 博客园 (cnblogs.com) |
| Redisson实现分布式锁(3)—项目落地实现 - 雨点的名字 - 博客园 (cnblogs.com) |
7.1 第一次/基本Api使用
环境配置的三大步骤
- 依赖导入
- 配置类/启动类
- 注入,开始使用
前面两步在上面都写了有了,这里就不重复写了,这个篇章是专注于对Redisson的使用
查询集群中所有的key
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissonDemoForSpringBootApplication.class)
public class RedDemo {
@Resource
RedissonClient redissonClient;
@Test
public void t1() {
RKeys clientKeys = redissonClient.getKeys();
Iterable<String> stringIterable = clientKeys.getKeys();
for (String a : stringIterable) {
System.out.println(a);
}
}
}
这里我发现一个很有意思的事情,我做的是一个6节点的集群,查询出来的key居然存在重复,且在Linux处的redis客户端删除只删掉了一个,我怀疑是因为分片存储+哈希槽的特性,但是还是有待观察,毕竟这只是一个判断猜测
这里我遇到了一个序列化问题的报错,具体的可以看看我的《Java学习中的问题记录》
数据序列化-Redisson 使用手册-面试哥 (mianshigee.com)
Redisson默认使用FstCodec,官方的介绍是“10倍于JDK序列化性能而且100%兼容的编码”
我们从上面的结果发现,它可能可以代替掉redisTemplate,我们接下来验证一下猜想
import com.ljm.RedissonDemoForSpringBootApplication;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.redisson.api.RBucket;
import org.redisson.api.RFuture;
import org.redisson.api.RKeys;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissonDemoForSpringBootApplication.class)
public class RedDemo {
@Resource
RedissonClient redissonClient;
@Test
public void t1() {
try {
// 查询集群中所有的key
RKeys clientKeys = redissonClient.getKeys();
Iterable<String> stringIterable = clientKeys.getKeys();
for (String a : stringIterable) {
System.out.println(a);
}
System.out.println("**************************");
// 获取一个key的桶对象
RBucket<Object> test01ForRb = redissonClient.getBucket("test01");
test01ForRb.set("test01isValue");
String o = (String) test01ForRb.get();
System.out.println(o);
// 获取一个key的桶对象 但是这里演示异步操作
RBucket<Object> springBootTest01ForRb = redissonClient.getBucket("SpringBootTest01", new StringCodec());
RFuture<Object> async = springBootTest01ForRb.getAsync();
// 为什么让她睡呢 因为是异步结果返回 所以可以等待一下让程序拿个true
Thread.sleep(5000);
System.out.println("isSuccess() True Or False? :" + async.isSuccess());
} catch (Exception e) {
e.printStackTrace();
}
}
}
7.2 分布式缓存锁-重入锁案例
看看流程先
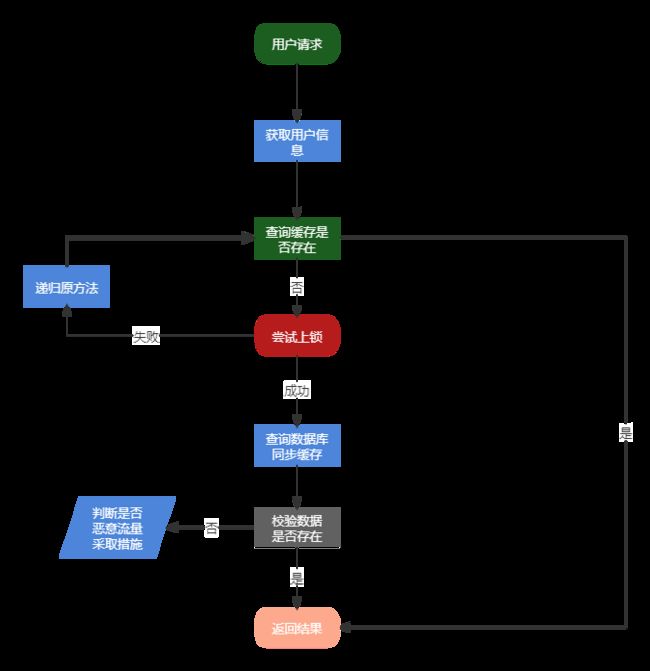
具体代码
import com.ljm.service.ItemService;
import org.redisson.api.RLock;
import org.redisson.api.RMap;
import org.redisson.api.RedissonClient;
import org.redisson.codec.SerializationCodec;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* @author 李家民
*/
@RestController
@RequestMapping("/api/item")
public class ItemApiController {
@Resource
ItemService itemService;
@Resource
RedissonClient redissonClient;
@RequestMapping("/item/{skuId}")
Map<String, Object> item(@PathVariable(value = "skuId") Long skuId
, HttpServletRequest request
) {
// 远程IP,即客户端IP
String addr = request.getRemoteAddr();
System.out.println("用户:" + addr + " 进行了访问");
// 先查询缓存有没有
RMap<String, Object> getItem = redissonClient.getMap("getItem:" + skuId, new SerializationCodec());
boolean empty = getItem.isEmpty();
if (empty) {
// 数据为空 查询数据库
// 加入分布式锁
RLock lock = redissonClient.getLock("Item:getItem:" + skuId);
try {
boolean tryLock = lock.tryLock(30, 10, TimeUnit.SECONDS);
if (tryLock) {
// 我拿到了锁
System.out.println(addr + ":我拿到了锁");
try {
// 查询数据库
Map<String, Object> dbMap = itemService.getItem(skuId);
if (!dbMap.isEmpty()) {
// 同步缓存
System.out.println(addr + ":同步缓存");
Set<Map.Entry<String, Object>> entrySet = dbMap.entrySet();
for (Map.Entry<String, Object> itemMap : entrySet) {
getItem.put(itemMap.getKey(), itemMap.getValue());
}
System.out.println(addr + ":同步成功 返回数据");
return getItem;
} else {
// 防止恶意流量 防止缓存穿透
System.out.println("根本就没有这个数据 你想干嘛?");
Map<String, Object> badMaps = new HashMap<>(1);
return badMaps;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("lock.unlock()");
lock.unlock();
}
} else {
// 请求如果没有拿到锁 递归回去 直至有了结果return
item(skuId, request);
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("返回空数据 一般是到不了这一步的");
return null;
} else {
// 数据存在 直接缓存返回
System.out.println("数据存在 直接缓存返回");
Set<Map.Entry<String, Object>> entrySetRedis = getItem.entrySet();
for (Map.Entry<String, Object> tempMap : entrySetRedis) {
getItem.put(tempMap.getKey(), tempMap.getValue());
}
return getItem;
}
}
}
其实都是一个套路
更新中…
1