【计算机视觉 | 目标检测】目标检测中的评价指标 mAP 理解及计算(含示例)
文章目录
- 一、目标检测的评价指标
-
- 1.1 Precision
- 1.2 Recall
- 1.3 Average Precision(AP)
- 1.4 mean Average Precision(mAP)
- 1.5 Intersection over Union(IoU)
- 1.6 F1-score
- 二、基础知识
-
- 2.1 Precision
- 2.2 Recall
- 2.3 IoU
- 三、mAP 的计算
- 四、AP 计算的例子
一、目标检测的评价指标
在目标检测中,有几个常用的评价指标用于衡量算法的性能。以下是其中几个重要的评价指标:
1.1 Precision
Precision(精确率):Precision 衡量了在所有被检测为正样本的样本中,有多少是真正的正样本。
Precision 的计算公式为:Precision = TP / (TP + FP),其中 TP 是真正的正样本数量,FP 是将负样本错误地标记为正样本的数量。较高的 Precision 表示算法在正样本的判定上更准确。
1.2 Recall
Recall(召回率):Recall 衡量了在所有真正的正样本中,有多少被算法正确地检测出来了。
Recall 的计算公式为:Recall = TP / (TP + FN),其中 TP 是真正的正样本数量,FN 是错误地未能检测到的正样本数量。较高的 Recall 表示算法能够更好地检测出真实目标。
1.3 Average Precision(AP)
AP 是根据 Precision-Recall 曲线计算的面积。它对不同召回率下的 Precision 进行插值,并计算插值曲线下的面积。AP 是评估目标检测算法在不同召回率下的综合性能指标。
1.4 mean Average Precision(mAP)
mAP 是所有类别的 AP 值的平均值。它是评估多类别目标检测算法整体性能的重要指标。
1.5 Intersection over Union(IoU)
IoU 是用于衡量预测边界框与真实边界框之间重叠程度的指标。IoU 计算为预测框与真实框的交集面积除以它们的并集面积。IoU 通常用于确定预测框是否与真实框匹配。
1.6 F1-score
F1-score 是 Precision 和 Recall 的调和平均值,用于综合考虑算法的准确性和召回能力。
F1-score 计算公式为:F1-score = 2 * (Precision * Recall) / (Precision + Recall)。
需要注意的是,评价指标的选择和解释应该结合具体的任务和应用场景,综合考虑多个指标可以更全面地评估目标检测算法的性能。
二、基础知识
当评估分类或目标检测算法性能时,Precision(精确率)和 Recall(召回率)是两个重要的指标。它们用于衡量算法在识别目标时的准确性和召回能力。
2.1 Precision
- 定义:Precision 衡量了在所有被分类为正样本或检测为目标的样本中,有多少是真正的正样本或真实目标。
- 计算公式:Precision = TP / (TP + FP),其中 TP 是真正的正样本或目标数量,FP 是将负样本或非目标错误地标记为正样本或目标的数量。
- 解释:Precision 告诉我们,当算法判断某个样本为正样本或目标时,有多大概率它是正确的。较高的 Precision 表示算法在正样本或目标的判定上更准确。
2.2 Recall
- 定义:Recall 衡量了在所有真正的正样本或目标中,有多少被算法正确地检测出来了。
- 计算公式:Recall = TP / (TP + FN),其中 TP 是真正的正样本或目标数量,FN 是错误地未能检测到的正样本或目标数量。
- 解释:Recall 告诉我们算法在找出真实目标方面的能力。较高的 Recall 表示算法能够更好地检测出真实目标。
精确率和召回率之间存在一种权衡关系。增加阈值可以提高精确率,但可能会导致召回率降低,因为更少的样本被分类为正样本或目标。降低阈值可以提高召回率,但可能会导致精确率降低,因为更多的样本被分类为正样本或目标。
精确率和召回率经常一起使用,以综合评估算法的性能。同时考虑这两个指标可以帮助我们了解算法的分类或检测能力,并找到适合特定任务需求的平衡点。
在某些情况下,比如类别不平衡的数据集中,仅使用精确率或召回率可能会导致评估结果不准确。因此,使用其他指标如 F1-score(精确率和召回率的调和平均值)、AP(平均精确率)等能够提供更全面的性能评估。
2.3 IoU
在目标检测中即计算预测边界框与 GT 边界框的重叠程度。
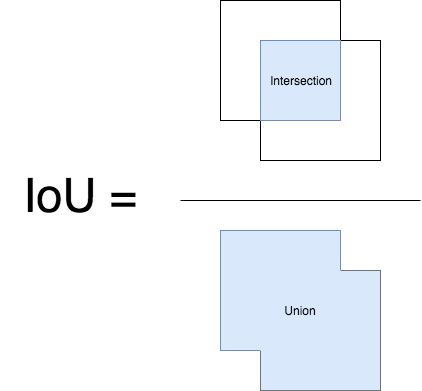
IoU(Intersection over Union)是目标检测中常用的评价指标,用于衡量预测边界框与真实边界框之间的重叠程度。它是通过计算两个边界框的交集面积除以它们的并集面积得到的。
具体而言,IoU 的计算公式如下:
IoU = Intersection Area / Union Area
其中,Intersection Area 是预测边界框与真实边界框的交集面积,而 Union Area 是它们的并集面积。
IoU 的取值范围是0到1,其中0表示没有重叠,1表示完全重叠。
IoU 在目标检测中具有重要的应用,常用于以下几个方面:
- 用于判断目标检测算法的预测结果是否正确,通常通过设置 IoU 阈值来决定预测框是否与真实框匹配。
- 在训练目标检测算法时,用于计算正样本与预测框之间的 IoU,以确定哪些预测框是与真实目标重叠较好的正样本。
- 在评估目标检测算法性能时,常用 IoU 作为指标之一,用于衡量算法的准确性和召回能力。
需要注意的是,IoU 只关注边界框之间的重叠程度,不考虑其它因素,如类别信息。因此,对于多类别目标检测任务,通常会结合 IoU 与类别预测的准确性来综合评估算法性能。
三、mAP 的计算
参考文献:
https://blog.csdn.net/NooahH/article/details/90140912
首先要计算每一类的 AP(Average Precision)。比如我们计算 person 这一类的 AP。
这里有一组测试集图片,每张图片都事先标记或未标记出 person,这样我们就有了 person 的 GT(Ground Truth)边界框。
在每张测试图片输入模型后会得到一系列 person 类的预测边界框,每个边界框都附带有一个置信度。(注意当我们计算 person 的 AP 时就只关注这一类的边界框,不考虑其他类的,即使该图片中存在如 dog 类的 GT 边界框。)
将每张测试集中的图片进行检测后会得到一系列预测边界框集合,之后将该预测边界框集合按照置信度降序排序。
然后对于某一张测试集图片,我们计算在该图片上 person 类的预测边界框与 GT 边界框重叠程度(即 IoU),如果 IoU 大于设定阈值(IoU 阈值的典型值为0.5)则将该边界框标记为 TP,否则标记为 FP。
对测试集中每张图片的预测边界框均进行如上操作(注意:在计算某一张图片的预测框时会从预测框集合中选取该图片的预测框)。由此会判定预测边界框集合中每个预测边界框属于 TP 或者 FP。
如下面3张图,我们要检测人脸,蓝色框表示 GT,绿色框表示预测边界框,旁边的红色数字为置信度:


可以得出有3个 GT(GT1,GT2,GT3),3个预测框(BBox1,BBox2, BBox3)。
- 我们按照置信度降序排序预测框,这里的预测框正好是降序排序的。
- 对每张图片中的预测框计算 IoU,可以看出 BBox1 标记为 TP,BBox2 标记为 FP,BBox3 标记为 TP。
- 之后计算不同recall情况下 precision 值。前1个框,即 BBox1,计算precision = TP / (TP + FP) = 1 / (1 + 0) = 1,recall = TP / # GT = 1 / 3。(#GT 指的是测试集中所有 GT 数目,这里即为3)同理前2个框,即 BBox1,BBox2,计算 precision = 1 / (1 + 1) = 0.5,recall = 1 / 3。前3个框,即 BBox1,BBox2,BBox3,计算 precision = 2 / (2 + 1) = 2 / 3,recall = 2 / 3。我们就有了一组recall、precision值[(1 / 3, 1), (1 / 3, 0.5), (2 / 3, 2 / 3)]
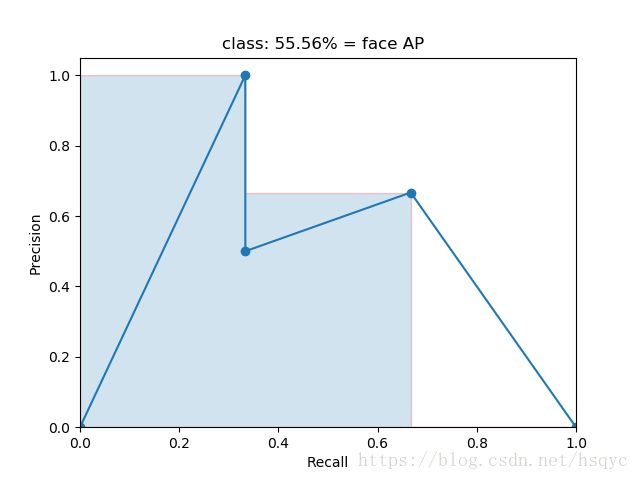
- 绘制 PR 曲线如下图,然后每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是 AP 值。这里:

按照如上方法计算其他所有类的 AP,最后取平均值即为 mAP(mean Average Precision):
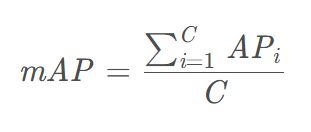
其中 C C C 表示总类别数目, A P i AP_i APi 表示第 i i i 类的 AP 值。
四、AP 计算的例子
比如说我们的测试集中类 A 的 GT 有 7 个,经过目标检测模型预测到了 10 个边界框,经过上次排序及判断操作,有如下结果:

按照 confidence 降序排序。从上表 TP 可以看出我们预测正确 5 个(TP = 5),从 FP 看出预测错误 5 个(FP = 5)。除了表中已预测到的 5 个 GT,还有 2 个 GT 并未被预测出来(FN = 2)。
接下来计算 AP,计算前 * 个 BBox 得到的 precision 和 recall :
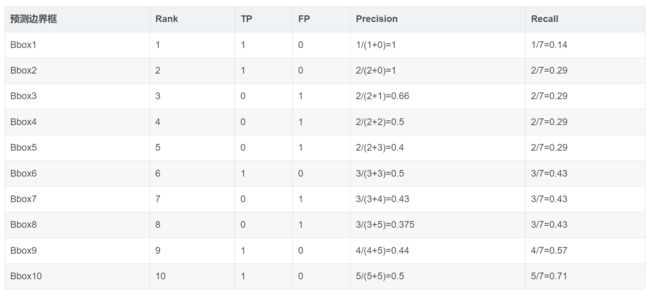
在计算 precision 和 Recall 时 Rank * 指的是前 * 个预测边界框的 TP 和 FP 之和。
同样可以通过绘制 PR 曲线计算线下面积,如下图所示:
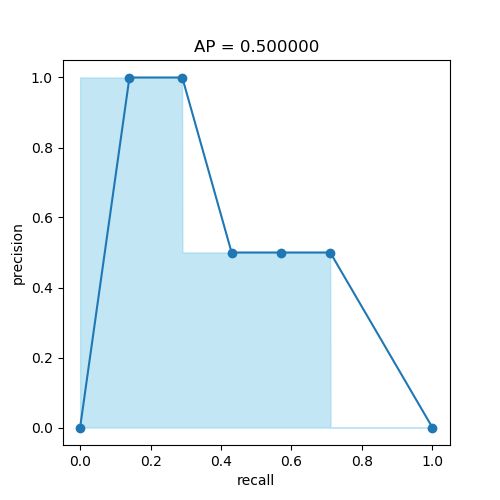
AP值即浅蓝色图形的面积,蓝色折线为recall、precision点。
![]()