论文阅读 - SegFormer
文章目录
- 1 概述
- 2 模型说明
-
- 2.1 总体结构
- 2.2 Hierarchical Transformer Encoder
- 2.3 Lightweight All-MLP Decoder
- 3 SegFormer和SETR的比较
- 参考资料
1 概述
图像分割任务和图像分类任务是非常相关的,前者是像素级别的分类,后者是图像级别的分类。基于分类这样的思想,为图像分割设计的FCN横空出世,并且这个结构影响了之后许多的模型。也正因为分割和分类的相似性,以往的研究都是将分类的backbone作为分割的backbone,专门为分割任务设计backbone是一个活跃中的领域。
Vision Transformer(ViT)作为backbone在图像分类任务的成功使得SETR第一次尝试将ViT引入到图像分割任务上,并且有着非常好的效果。但是,ViT有三个局限性,一是ViT只输出一个单尺度的低分辨率特征,这对分类是够用的,但是对分割是不够用的;二是ViT对于高分辨率的图像输入,计算复杂度非常高,这对于高分辨率的图像分割是致命的;三是Position Encdoer的存在使得输入分辨率是固定的,无法改变。Pyramid Vision Transformer针对前两点局限性做了改进,但是都是在encoder上下功夫,忽略了decoder。
SegFormer对于transformer-based分割网络的encoder和decoder都做了改进,主要贡献是
(1)设计了不需要Position Encdoer(PE-free)的encoder,即可支持任意分辨率的输入
(2)设计了轻量高效的decoder
SegFormer改变Backbone的层数可以得到B0~B5六种量级的模型,其效果和性能如下图1-1所示。SegFormer-B0的参数量是FCN-R50的十分之一不到,但是效果却超过了FCN-R50;SegFormer-B4的参数量是SETR的五分之一,但是效果却超过了SETR。从图中可以看出,是对其他模型任意维度的实力碾压。
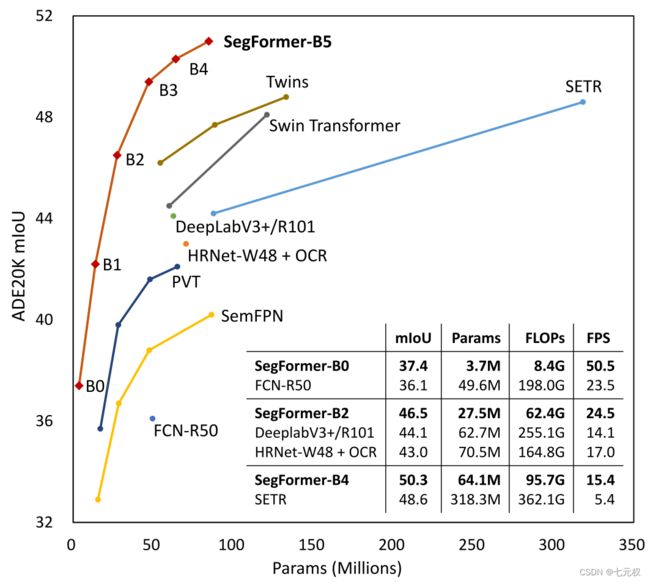
实际使用也可以感受到SegFormer的效果强大,因此专门写一篇博客记录一下。
2 模型说明
2.1 总体结构
SegFormer的总体结构如下图2-1所示。总体可以看成一个encoder+decoder的结构。
输入一个 H × W × 3 H \times W \times 3 H×W×3的image,首先将他分成 4 × 4 4 \times 4 4×4大小的patch,这一点和ViT不同(ViT分成 16 × 16 16 \times 16 16×16的patch),较小的patch更加适合稠密的预测任务。然后将这些patchs输入到Transformer多层编码器中来获得多层的feature map,再将这些feature maps作为ALL-MLP的输入来预测mask,通过解码器产生的feature map的分辨率是 H / 4 × W / 4 × N c l s H/4 \times W/4 \times N_{cls} H/4×W/4×Ncls。 N c l s N_{cls} Ncls就是最终的预测类别数量。
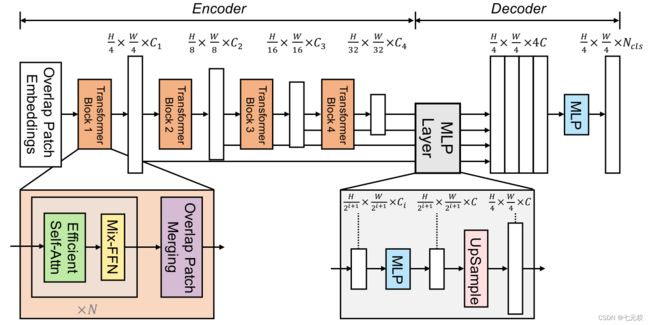
接下来较详细地说明一下每一个模块。
2.2 Hierarchical Transformer Encoder
作者将其设计的Encoder称为Mix Transformer encoders(MiT),根据backbone的层数不同,分为MiT-B0~MiT-B5。MiT-B0是轻量级的预测模型,MiT-B5是性能最好的也是最大的模型。设计MiT的部分灵感来自于VIT,但针对语义分割做了量身定制和优化。
MiT共有四个特点:
(1)Hierarchical Feature Representation
不像ViT只能获得单一的feature map,MiT的目标就是输入一张image,产生和CNN类似的多层次的feature maps。通常这些多层的feature maps提供的高分辨率的粗特征和低分辨率的精细特征可以提高语义分割的性能。
用数学语言来表达就是
输入: H × W × 3 H \times W \times 3 H×W×3;输出: H 2 i + 1 × W 2 i + 1 × C , i ∈ { 1 , 2 , 3 , 4 } , C i + 1 > C i \frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C, i \in \{1,2,3,4\}, C_{i+1} > C_i 2i+1H×2i+1W×C,i∈{1,2,3,4},Ci+1>Ci
(2)Overlapped Patch Merging
借助于ViT中的Patch Merging,可以很容易的将特征图的分辨率缩小两倍,但这是通过组合non-overlapping的图像或特征块,它不能保持这些patch周围的局部连续性。作何使用overlapping的图像来融合,这样就可以保证patch周围的局部连续性了。
为此本文设置的三个参数K,S,P。K是patch size,S是stride,P是padding。在实验中分别设K,S,P为(7,4,3)和(3,2,1)的参数来执行overlapping的图像的融合过程并得到和non-overlapping图像融合一样大小的feature。
(3)Efficient Self-Attention
论文作者认为,网络的计算量主要体现在自注意力机制层上。为了降低网路整体的计算复杂度,作者在自注意力机制的基础上,添加缩放因子 R R R,来降低每一个自注意力机制模块的计算复杂度。
本来自注意力机制可以表示为
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d h e a d ) V Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt{d_{head}}})V Attention(Q,K,V)=Softmax(dheadQKT)V
其中, Q Q Q, K K K和 V V V的维度都是 N × C N \times C N×C。这样的计算复杂度是 O ( N 2 ) O(N^2) O(N2)的, N = H × W N=H \times W N=H×W。对于大分辨率的图片,计算复杂度一下子就上去了。
作何引入了缩放因子 R R R来减小计算复杂度,如下式所示
K ^ = R e s h a p e ( N R , C ⋅ R ) ( K ) K = L i n e a r ( C ⋅ R , C ) ( K ^ ) \hat{K} = Reshape(\frac{N}{R}, C \cdot R)(K) \\ K = Linear(C \cdot R, C)(\hat{K}) K^=Reshape(RN,C⋅R)(K)K=Linear(C⋅R,C)(K^)
其中, R e s h a p e Reshape Reshape表示将 K K K的维度从 ( N , C ) (N, C) (N,C)变为 ( N R , C ⋅ R ) (\frac{N}{R}, C \cdot R) (RN,C⋅R),Linear表示一个卷积,将 K ^ \hat{K} K^的维度从 ( N R , C ⋅ R ) (\frac{N}{R}, C \cdot R) (RN,C⋅R)变为了 ( N R , C ) (\frac{N}{R}, C) (RN,C)。因此,最终 K K K的shape变为了 ( N R , C ) (\frac{N}{R}, C) (RN,C)。由于实际情况下, K K K和 V V V的取值是相同的,因此, V V V的维度也变为了 ( N R , C ) (\frac{N}{R}, C) (RN,C)。
经过这样的变换后, A t t e n t i o n Attention Attention计算时的复杂度就从 O ( N 2 ) O(N^2) O(N2)降为了 O ( N 2 / R ) O(N^2/R) O(N2/R)。
实际情况下,浅层分辨率大, R R R较大,反之深层的 R R R较小。从stage-1到stage-4, R R R的取值为 [ 64 , 16 , 4 , 1 ] [64, 16, 4, 1] [64,16,4,1]。
(4)Mix-FFN
ViT使用位置编码PE(Position Encoder)来插入位置信息,但是插入的PE的分辨率是固定的,这就导致如果训练图像和测试图像分辨率不同的话,需要对PE进行插值操作,这会导致精度下降。为了解决这个问题CPVT使用了 3 × 3 3 \times 3 3×3的卷积和PE一起实现了data-driver PE。
作者认为语义分割中PE并不是必需的。故引入了一个 Mix-FFN,考虑了zero padding经过卷积后是会泄露一定程度的位置信息的,起到了PE的作用,故直接在 FFN (feed-forward network)中使用 一个 3 × 3 3 \times 3 3×3的卷积,MiX-FFN可以表示如下:
x o u t = M L P ( G E L U ( C o n v 3 × 3 ( M L P ( x i n ) ) ) ) + x i n x_{out} = MLP(GELU(Conv_{3 \times 3}(MLP(x_{in})))) + x_{in} xout=MLP(GELU(Conv3×3(MLP(xin))))+xin
在实验中作者展示了 3 × 3 3 \times 3 3×3的卷积可以为transformer提供PE。作者还是用了depth-wise convolution提高效率,减少参数。
2.3 Lightweight All-MLP Decoder
SegFormer集成了轻量级的MLP Decoder,减少了很多不必要的麻烦。使用这种简单编码器的关键点是作者提出的多级Transformer Encoder比传统的CNN Encoder可以获得更大的感受野。也就是这个decoder使用其他的encoder达不到SegFormer这么好的效果。
ALL-MLP由四步组成。第一,从MIT中提取到的多层次的feature,记作 F i F_{i} Fi,通过MLP层统一channel层数。第二, F i F_{i} Fi被上采样到四分之一大小,然后再做一次concat操作。第三,MLP对concat之后的特征进行融合。最后,另一个MLP对融合的特征进行预测,输出分辨率为 H 4 × W 4 × N c l s \frac{H}{4} \times \frac{W}{4} \times N_{cls} 4H×4W×Ncls。
F ^ i = L i n e a r ( C i , C ) ( F i ) , ∀ i F ^ i = U p s a m p l e ( W 4 , W 4 ) ( F ^ i ) , ∀ i F = L i n e a r ( 4 C , C ) ( C o n c a t ( F ^ i ) ) M = L i n e a r ( C , N c l s ) ( F ) \hat{F}_i = Linear(C_{i}, C)(F_{i}), \forall i \\ \hat{F}_i = Upsample(\frac{W}{4}, \frac{W}{4})(\hat{F}_i ), \forall i \\ F = Linear(4C, C)(Concat(\hat{F}_i )) \\ M = Linear(C, N_{cls})(F) F^i=Linear(Ci,C)(Fi),∀iF^i=Upsample(4W,4W)(F^i),∀iF=Linear(4C,C)(Concat(F^i))M=Linear(C,Ncls)(F)
能够使用这样轻量的decoder,得益于encoder的感受野加大。使用有效感受野ERF作为一个可视化和解决的工具来说明为什么MLPdecoder表现是非常有效的在Transformer上。下图2-2所示,对比deeplabv3+和SegFormer的四个解码器阶段和编码器头的部分的可视化图。

结论为
1)即使在最深的阶段,deeplabv3+的ERF还是非常小;
2)SegFormer的编码器自然地产生local attentions,类似于较低阶段的卷积,同时能够输出高度non-local attentions,有效地捕获编码器第四阶段的上下文;
3)将图片放大,MLP的MLPhead阶段(蓝框)明显和Stage-4阶段(红框)的不同,可以看出local attentions更多了。
CNN中感受野有限的问题只能通过增加上下文模块来提升精度,像ASPP模块,但是这样会让网络变得更复杂。本文中的decoder设计受益于transformer中的non-local attention,并且在不导致模型变复杂的情况下使得感受野变大。但是相同的decoder接在CNN的backbone的时候效果并不是很好,因为Stage4的感受野有限。
3 SegFormer和SETR的比较
与SETR相比,SegFormer含有多个更有效和强大的设计:
(1)SegFormer只在imageNet-1K上做了预训练,SETR中的ViT在更大的imageNet-22K做了预训练。
(2)SegFormer的多层编码结构要比ViT的更小,并且能同时处理高分辨率的粗特征和低分辨率的精细特征,相比SETR的ViT只能生成单一的低分辨率特征。
(3)SegFormer中去掉了位置编码,所以在test时输入image的分辨率和train阶段分辨率不一致时也可以得到较好的精度,但是ViT采用固定的位置编码,这会导致当test阶段的输入分辨率不同时,会降低精度。
(4)SegFormer中decoder的计算开销更小更紧凑,而SETR中的decoder需要更多的 3 t i m e s 3 3 times 3 3times3卷积。
SegFormer和其他分割模型在ADE20K和Cityscapes数据集上的效果对比如下图2-3所示。

参考资料
[1] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
[2] MedAI #32: Simple & Efficient Design for Semantic Segmentation with Transformers | Enze Xie