XXL-Job学习笔记
一 下载网址
- Releases · xuxueli/xxl-job · GitHub
二 目录结构
- doc:xxl-job的文档资料,包括了数据库的脚本(后面要用到)
- xxl-job-core:公共jar包依赖
- xxl-job-admin:调度中心,项目源码,是Springboot项目,可以直接启动
- xxl-job-executor-samples:执行器,是Sample实例项目,里面的Springboot工程可以直接启动,也可以在该项目的基础上进行开发,也可以将现有的项目改造成为执行器项目
三 表介绍
xxl_job的数据库里有如下几个表:
- xxl_job_group:执行器信息表,用于维护任务执行器的信息
- xxl_job_info:调度扩展信息表,主要是用于保存xxl-job的调度任务的扩展信息,比如说像任务分组、任务名、机器的地址等等
- xxl_job_lock:任务调度锁表
- xxl_job_log:日志表,主要是用在保存xxl-job任务调度历史信息,像调度结果、执行结果、调度入参等等
- xxl_job_log_report:日志报表,会存储xxl-job任务调度的日志报表,会在调度中心里的报表功能里使用到
- xxl_job_logglue:任务的GLUE日志,用于保存GLUE日志的更新历史变化,支持GLUE版本的回溯功能
- xxl_job_registry:执行器的注册表,用在维护在线的执行器与调度中心的地址信息
- xxl_job_user:系统的用户表
四 部署XXL-Job步骤
4.1 xxl-job-admin目录配置文件 application.properties
- 配置数据库连接
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=xdclass.net
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver4.2 配置 xxl.job.accessToken(后续要配置客户端接入配置token)
xxl.job.accessToken=xdclass.net4.3 访问地址
- 地址:ip:8080/xxl-job-admin
- 默认账号密码:admin / 123456
5 分布式调度XXL-Job UI菜单模块介绍
-
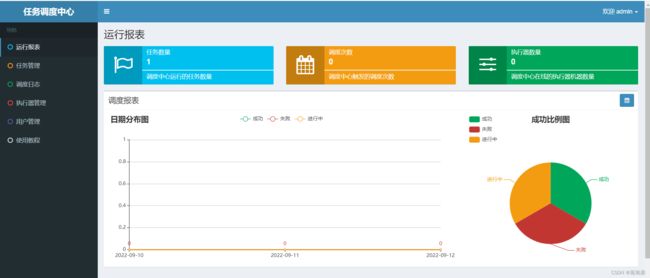
运行报表
-
以图形化来展示了整体的任务执行情况
- 任务数量:能够看到调度中心运行的任务数量
- 调度次数:调度中心所触发的调度次数
- 执行器数量:在整个调度中心中,在线的执行器数量有多少
-
-
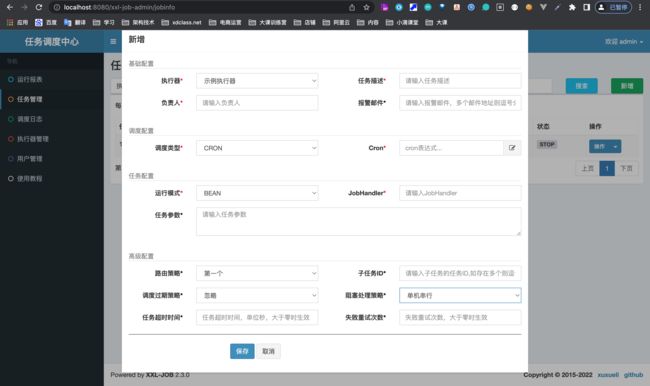
任务管理(配置执行任务)
-
示例执行器:所用到的执行器
-
任务描述:概述该任务是做什么的
-
路由策略:
- 第一个:选择第一个机器
- 最后一个:选择最后一个机器
- 轮询:依次选择执行
- 随机:随机选择在线的机器
- 一致性HASH:每个任务按照Hash算法固定选择某一台机器,并且所有的任务均匀散列在不同的机器上
- 最不经常使用:使用频率最低的机器优先被使用
- 最近最久未使用:最久未使用的机器优先被选举
- 故障转移:按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标的执行器并且会发起任务调度
- 忙碌转移:按照顺序来依次进行空闲检测,第一个空闲检测成功的机器会被选定为目标群机器,并且会发起任务调度
- 分片广播:广播触发对于集群中的所有机器执行任务,同时会系统会自动传递分片的参数
-
Cron:执行规则
-
调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等
-
JobHandler:定义执行器的名字
-
阻塞处理策略:
- 单机串行:新的调度任务在进入到执行器之后,该调度任务进入FIFO队列,并以串行的方式去进行
- 丢弃后续调度:新的调度任务在进入到执行器之后,如果存在相同的且正在运行的调度任务,本次的调度任务请求就会被丢弃掉,并且标记为失败
- 覆盖之前的调度:新的调度任务在进入到执行器之后,如果存在相同的且正在运行的调度任务,就会终止掉当前正在运行的调度任务,并且清空队列,运行新的调度任务。
-
子任务ID:输入子任务的任务id,可填写多个
-
任务超时时间:添加任务超时的时候,单位s,设置时间大于0的时候就会生效
-
失败重试次数:设置失败重试的次数,设置时间大于0的时候就会生效
-
负责人:填写该任务调度的负责人
-
报警邮件:出现报警,则发送邮件
-
-
调度日志
- 这里是查看调度的日志,根据日志来查看任务具体的执行情况是怎样的
-
执行器管理
- 这里是配置执行器,等待执行器启动的时候都会被调度中心监听加入到地址列表
-
用户管理
- 可以对用户的一些操作
6 整合XXL-JOB
6.1 添加XXL-Job依赖
com.xuxueli
xxl-job-core
2.3.0
6.2 配置文件
#----------xxl-job配置--------------
logging.config=classpath:logback.xml
#调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
#执行器token,非空时启用 xxl-job, access token
xxl.job.accessToken=xdclass.net
# 执行器app名称,和控制台那边配置一样的名称,不然注册不上去
xxl.job.executor.appname=xdclass-shop
# [选填]执行器注册:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。
#从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
#[选填]执行器IP :默认为空表示自动获取IP(即springboot容器的ip和端口,可以自动获取,也可以指定),多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务",
xxl.job.executor.ip=
# [选填]执行器端口号:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
#执行器日志文件存储路径,需要对该路径拥有读写权限;为空则使用默认路径
xxl.job.executor.logpath=./data/logs/xxl-job/executor
#执行器日志保存天数
xxl.job.executor.logretentiondays=306.3 XxlJobConfig
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private final Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses:}")
private String adminAddresses;
@Value("${xxl.job.accessToken:}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
*
* org.springframework.cloud
* spring-cloud-commons
* ${version}
*
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}6.4 每日任务
/**
* 每日任务
* 每日凌晨1点执行
*
* @author Chopper
*/
public interface EveryDayExecute {
/**
* 执行每日任务
*/
void execute();
}
6.5 每刻任务
/**
* 每分钟任务
*
* @author Chopper
*/
public interface EveryFifteenMinuteExecute {
/**
* 执行
*/
void execute();
}6.6 每小时任务
/**
* 每小时任务
*
* @author Chopper
*/
public interface EveryHourExecute {
/**
* 执行
*/
void execute();
}6.7 每分钟任务
/**
* 每分钟任务
*
* @author Chopper
*/
public interface EveryMinuteExecute {
/**
* 执行
*/
void execute();
}6.8 定时器任务
/**
* 定时器任务
*
* @author Chopper
* @version v1.0
*/
@Slf4j
@Component
public class TimedTaskJobHandler {
@Autowired(required = false)
private List everyMinuteExecutes;
@Autowired(required = false)
private List everyHourExecutes;
@Autowired(required = false)
private List everyDayExecutes;
@Autowired(required = false)
private List everyFifteenMinuteExecute;
/**
* 每分钟任务
*
* @throws Exception
*/
@XxlJob("everyMinuteExecute")
public ReturnT everyMinuteExecute(String param) {
log.info("每分钟任务执行");
if (everyMinuteExecutes == null || everyMinuteExecutes.size() == 0) {
return ReturnT.SUCCESS;
}
for (int i = 0; i < everyMinuteExecutes.size(); i++) {
try {
everyMinuteExecutes.get(i).execute();
} catch (Exception e) {
log.error("每分钟任务异常", e);
}
}
return ReturnT.SUCCESS;
}
/**
* 每15分钟任务
*
* @throws Exception
*/
@XxlJob("everyFifteenMinuteExecute")
public ReturnT everyFifteenMinuteExecute(String param) {
log.info("每15分钟任务执行");
if (everyFifteenMinuteExecute == null || everyFifteenMinuteExecute.size() == 0) {
return ReturnT.SUCCESS;
}
for (int i = 0; i < everyFifteenMinuteExecute.size(); i++) {
try {
everyFifteenMinuteExecute.get(i).execute();
} catch (Exception e) {
log.error("每15分钟任务异常", e);
}
}
return ReturnT.SUCCESS;
}
/**
* 每小时任务
*
* @throws Exception
*/
@XxlJob("everyHourExecuteJobHandler")
public ReturnT everyHourExecuteJobHandler(String param) {
log.info("每小时任务执行");
if (everyHourExecutes == null || everyHourExecutes.size() == 0) {
return ReturnT.SUCCESS;
}
for (int i = 0; i < everyHourExecutes.size(); i++) {
try {
everyHourExecutes.get(i).execute();
} catch (Exception e) {
log.error("每小时任务异常", e);
}
}
return ReturnT.SUCCESS;
}
/**
* 每日任务
*
* @throws Exception
*/
@XxlJob("everyDayExecuteJobHandler")
public ReturnT everyDayExecuteJobHandler(String param) {
log.info("每日任务执行");
if (everyDayExecutes == null || everyDayExecutes.size() == 0) {
return ReturnT.SUCCESS;
}
for (int i = 0; i < everyDayExecutes.size(); i++) {
try {
everyDayExecutes.get(i).execute();
} catch (Exception e) {
log.error("每分钟任务异常", e);
}
}
return ReturnT.SUCCESS;
}
}
6. 9 示例
import cn.lili.modules.search.service.EsGoodsIndexService;
import cn.lili.timetask.handler.EveryFifteenMinuteExecute;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class IndexOrderTaskExcecute implements EveryFifteenMinuteExecute {
@Autowired
private EsGoodsIndexService esGoodsIndexService;
@Override
public void execute() {
log.info("====IndexOrderTaskExcecute=====,每隔15分钟生成一次索引");
esGoodsIndexService.init();
}
}7. XXL-Job海量数据处理-分片任务
7.1 需求
- 有一个任务需要处理100W条数据,每条数据的业务逻辑处理要0.1s
- 对于普通任务来说,只有一个线程来处理 可能需要10万秒才能处理完,业务则严重受影响
- 案例:双十一大促,给1000万用户发营销短信
7.2 什么是分片任务
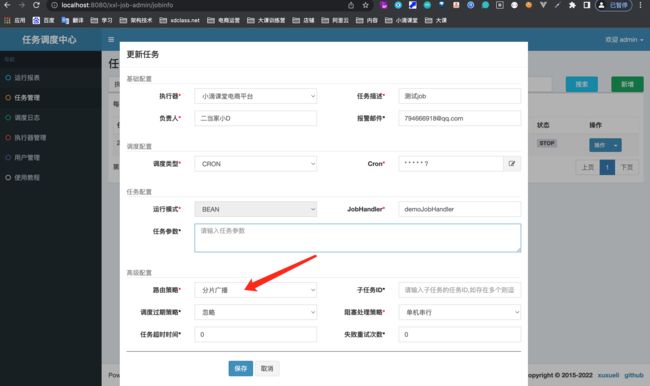
- 执行器集群部署,如果任务的路由策略选择【分片广播】,一次任务调度将会【广播触发】对应集群中所有执行器执行一次任务,同时系统自动传递分片参数,执行器可根据分片参数开发分片任务
- 需要处理的海量数据,以执行器为划分,每个执行器分配一定的任务数,并行执行
- XXL-Job支持动态扩容执行器集群,从而动态增加分片数量,到达更快处理任务
- 分片的值是调度中心分配的
// 当前分片数,从0开始,即执行器的序号
int shardIndex = XxlJobHelper.getShardIndex();
//总分片数,执行器集群总机器数量
int shardTotal = XxlJobHelper.getShardTotal();7.3 解决思路
-
如果将100W数据均匀分给集群里的10台机器同时处理,
-
每台机器耗时,1万秒即可,耗时会大大缩短,也能充分利用集群资源
-
在xxl-job里,可以配置执行器集群有10个机器,那么分片总数是10,分片序号0~9 分别对应那10台机器。
-
分片方式
- id % 分片总数 余数是0 的,在第1个执行器上执行
- id % 分片总数 余数是1 的,在第2个执行器上执行
- id % 分片总数 余数是2 的,在第3个执行器上执行
- ...
- id % 分片总数 余数是9 的,在第10个执行器上执行
路由策略
7.4 编码实战
-
- 选择为【分片广播】
- 需求:100个用户,分片处理
- 新增job测试案例
/** * 2、分片广播任务 */ @XxlJob("shardingJobHandler") public void shardingJobHandler() throws Exception { // 当前分片数,从0开始,即执行器的序号 int shardIndex = XxlJobHelper.getShardIndex(); //总分片数,执行器集群总机器数量 int shardTotal = XxlJobHelper.getShardTotal(); XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal); // 业务逻辑 for (int i = 0; i < shardTotal; i++) { if (i == shardIndex) { log.info("第 {} 片, 命中分片开始处理", i); } else { log.info("第 {} 片, 忽略", i); } } }根据id进行分片取模(部署3个执行器)
/** * 2、分片广播任务 */ @XxlJob("shardingJobHandler") public void shardingJobHandler() throws Exception { // 当前分片数,从0开始,即执行器的序号 int shardIndex = XxlJobHelper.getShardIndex(); //总分片数,执行器集群总机器数量 int shardTotal = XxlJobHelper.getShardTotal(); XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal); ListallUserIds = getAllUserIds(); allUserIds.forEach(obj -> { if (obj % shardTotal == shardIndex) { log.info("第 {} 片, 命中分片开始处理用户id={}",shardIndex,obj); } }); } private List getAllUserIds() { List ids = new ArrayList<>(); for (int i = 0; i < 100; i++) { ids.add(i); } return ids; }