区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
目录
-
- 区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
-
- 效果一览
- 基本介绍
- 模型描述
- 程序设计
- 参考资料
效果一览

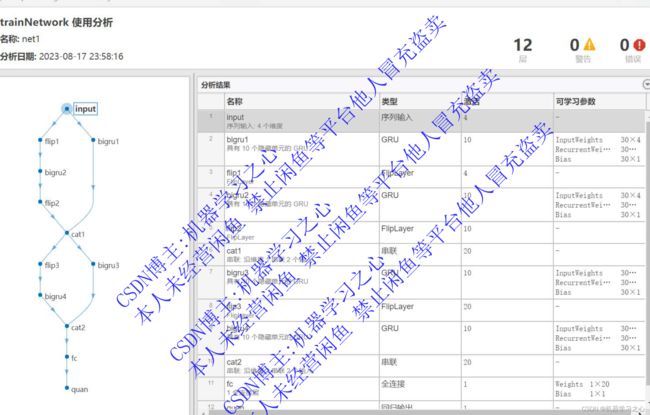

基本介绍
MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测。基于分位数回归的双向门控循环单元QRBiGRU的时间序列区间预测
(主要应用于风速,负荷,功率)(Matlab完整程序和数据)
运行环境matlab2020及以上,单变量时间序列预测。
excel数据,方便学习和替换数据。
模型描述
分位数回归是简单的回归,就像普通的最小二乘法一样,但不是最小化平方误差的总和,而是最小化从所选分位数切点产生的绝对误差之和。如果 q=0.50(中位数),那么分位数回归会出现一个特殊情况 - 最小绝对误差(因为中位数是中心分位数)。我们可以通过调整超参数 q,选择一个适合平衡特定于需要解决问题的误报和漏报的阈值。GRU 有两个有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。
程序设计
- 完整程序和数据获取方式(资源处下载):MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
% gru
layers = [ ...
sequenceInputLayer(inputSize,'name','input') %输入层设置
gruLayer(numhidden_units1,'Outputmode','sequence','name','hidden1')
dropoutLayer(0.3,'name','dropout_1')
gruLayer(numhidden_units2,'Outputmode','last','name','hidden2')
dropoutLayer(0.3,'name','drdiopout_2')
fullyConnectedLayer(outputSize,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
quanRegressionLayer('out',i)];
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% 参数设定
opts = trainingOptions('adam', ...
'MaxEpochs',10, ...
'GradientThreshold',1,...
'ExecutionEnvironment','cpu',...
'InitialLearnRate',0.001, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',2, ... %2个epoch后学习率更新
'LearnRateDropFactor',0.5, ...
'Shuffle','once',... % 时间序列长度
'SequenceLength',1,...
'MiniBatchSize',24,...
'Verbose',0);
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%
% 网络训练
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
y = Test.demand;
x = Test{:,3:end};
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% 归一化
[xnorm,xopt] = mapminmax(x',0,1);
xnorm = mat2cell(xnorm,size(xnorm,1),ones(1,size(xnorm,2)));
[ynorm,yopt] = mapminmax(y',0,1);
ynorm = ynorm';
% 平滑层
flattenLayer('Name','flatten')
% GRU特征学习
gruLayer(50,'Name','gru1','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
% GRU输出
gruLayer(NumOfUnits,'OutputMode',"last",'Name','bil4','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
dropoutLayer(0.25,'Name','drop3')
% 全连接层
fullyConnectedLayer(numResponses,'Name','fc')
regressionLayer('Name','output') ];
layers = layerGraph(layers);
layers = connectLayers(layers,'fold/miniBatchSize','unfold/miniBatchSize');
————————————————
版权声明:本文为CSDN博主「机器学习之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kjm13182345320/article/details/130447132
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/127931217
[2] https://blog.csdn.net/kjm13182345320/article/details/127418340
[3] https://blog.csdn.net/kjm13182345320/article/details/127380096