解锁数据潜力:信息抽取、数据增强与UIE的完美融合
解锁数据潜力:信息抽取、数据增强与UIE的完美融合
1.信息抽取(Information Extraction)
1.1 IE简介
信息抽取是 NLP 任务中非常常见的一种任务,其目的在于从一段自然文本中提取出我们想要的关键信息结构。
举例来讲,现在有下面这样一个句子:
新东方烹饪学校在成都。
我们想要提取这句话中所有有意义的词语,例如:
| 机构 | 新东方烹饪学校 |
| 城市 | 成都 |
这个关键词提取任务就叫做**命名实体识别(Named Entity Recognition, NER)**任务,文中的「新东方烹饪学校」和「成都」就被称为实体(Entity)。
如果我们还想进一步的知道这些词语之间的关系,例如:
| 实体 1 | 关系名 | 实体 2 |
|---|---|---|
| 新东方烹饪学校 | 所在地 | 成都 |
这种提取实体之间关系的任务就叫做**关系抽取(Relation Extraction, RE)**任务。
1.2 信息抽取的几种方法
1.2.1 序列标注(Sequence Labeling)
序列标注通常是指对文中的每一个字(以下简称 token)进行分类,即本质是 token classification 任务。
我们对第一小节中的例子做序列标注任务,得到的结果如下:
| 新 | 东 | ... | 学 | 校 | 在 | 成 | 都 |
|---|---|---|---|---|---|---|---|
| B - 机构 | I - 机构 | I - 机构 * N | I - 机构 | I - 机构 | O | B - 城市 | I - 城市 |
可以看到,我们对句子中的每一个字(token)都打上了一个类别标签,我们期望模型要做的事就是去学会每一个字所属的类别是什么。
Note: 这里用的标注方法是「BIO 标记法」,其中「B-」代表该位置 token 是某一个实体词语(span)的起始 token;「I-」代表该位置 token 处于某一个词语的中间(或结尾),「O」则代表该位置 token 不在任何一个实体词语中。除了「BIO 标记法」外,还有许多其他的标注方式(如 BIOES 等),其本质思路都很类似。
1.2.2 指针网络(Pointer Network)
序列标注模型有一个天然的缺陷,无法解决解决实体重叠(overlap)的问题。
举例来讲,如果今天我们不仅要提取「机构」,还同时要提取「机构类型」,那么我们期望的提取结果应该为:
| 机构 | 新东方烹饪学校 |
| 机构类型 | 学校 |
| 城市 | 成都 |
可以看到,对于「学校」这两个字,即属于「新东方烹饪学校」(机构)这个词,也存在于「学校」(机构类型)这个词,那我们在给这两个字打标签的时候,究竟应该打成哪个类别呢?
| 新 | 东 | … | 学 | 校 | 在 | 成 | 都 |
|---|---|---|---|---|---|---|---|
| B - 机构 | I - 机构 | I - 机构 | ? | ? | O | B - 城市 | I - 城市 |
由此我们可以看到,因为在进行分类时我们通常对一个字(token)只赋予一个标签,这就导致了 token classification 不能很好的解决实体重叠(一字多标签)的复杂情况。
Note: 存在一些技巧可以解决该问题,例如可以从单字单分类(CE)衍生到单字多分类(BCE),这里不展开讨论。
指针网络(Pointer Network)通过分别对每一个实体单独做预测来解决了实体之前的重叠冲突问题。
例如,我们现在要同时预测「机构」和「机构类型」这两个实体,那么我们就可以设计一个多头网络(Multi-Head)来分别预测这两个实体的实体词。
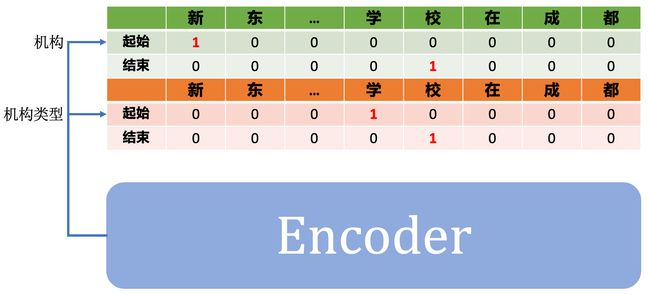
其中,
「机构」实体头中「起始」向量代表这一句话中是「机构」词语的首字(例子中为「新」);
「机构」实体中「结束」向量代表这一句话中时「机构」词语的尾字(例子中为「校」)。
通过「起始」和「结束」向量中的首尾字索引就能找到对应实体的词语。
可以看到,通过构建多头的任务,指针网络能够分别预测「机构」和「机构类型」中的实体词起始 / 终止位置,即「学校」这个词语在两个任务层中都能被抽取出来。
1.3. UIE —— 基于 prompt 的指针网络
1.3.1 UIE 中的 prompt 是什么?
多头指针网络能够很好的解决实体重叠问题,但缺点在于:不够灵活。
假定今天我们已经通过指针网络训练好了一个提取「机构」、「机构类型」的模型,即将交付时甲方突然提出一个新需求:我们想再多提取一个「机构简称」的属性。
草(一种植物)。
从 2.2 节中的示意图中我们可以看到,每一个实体类型会对应一个单独的网络头。
这就意味着我们不仅需要重标数据,还需要为新属性添加一个新的网络头,即模型结构会随着实体类型个数改变而发生变化。
那,能不能有一种办法去固定住模型的结构,不管今天来多少种类型要识别都能使用同样的模型结构完成呢?
我们思考一下,模型结构变化的部分是和实体类型强绑定的「头」部分。
而不同「头」之间结构其实是完全一样的:一个「起始」向量 + 一个「终止」向量。
既然「头」结构完全一样,我们能不能干脆直接使用一个「头」去提取不同实体类型的信息呢?
不同「头」之间的区别在于它们关注的信息不同:「机构头」只关注「机构」相关的实体词,「城市头」只关注「城市」相关的实体词。
那么我们是不是可以直接在模型输入的时候就告诉模型:我现在需要提取「某个头」的信息。
这个用来告诉模型做具体任务的参数就叫 prompt,我们把它拼在输入中一并喂给模型即可。
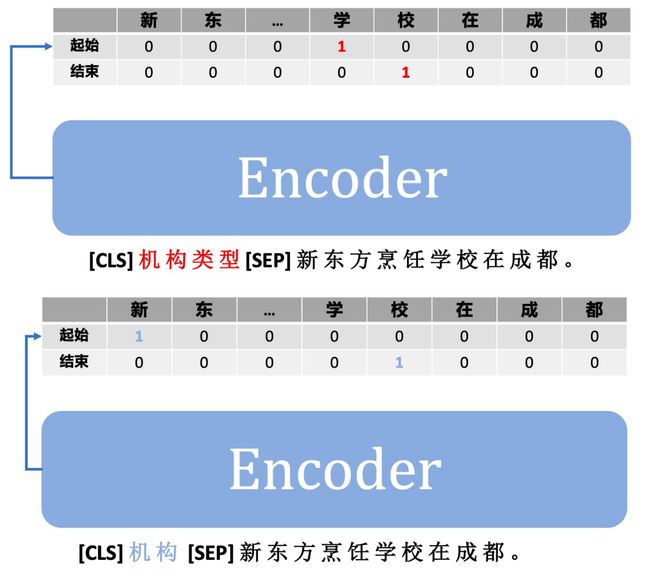
通过上图可以看到,我们将不同的「实体类型」作为 prompt 参数喂给模型,用于「激活」模型参数跟当前「实体类型」相关的参数,从而输出不同的抽取结果。
Note: 「通过一个输入参数去激活一个大模型中的不同参数,从而完成不同任务的思路」并不是首次出现,在 meta-learning 中也存在相关的研究,这里的 prompt 参数和 meta-parameter 有着非常类似的思路。
通过引入 prompt,UIE 也能很方便的解决实体之间的关系抽取(Relation Extraction)任务,例如:
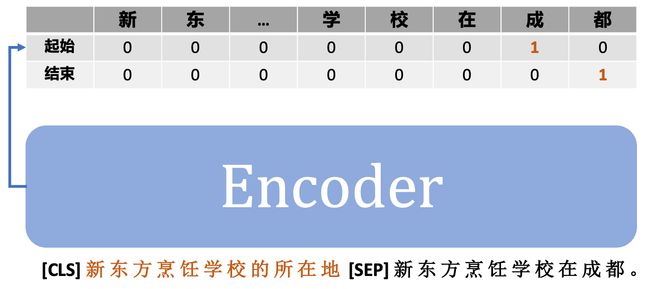
1.3.2 UIE 的实现
看完了基本思路,我们来一起看看 UIE 是怎么实现的吧。
- 模型部分
UIE 的模型代码比较简单,只需要在 encoder 后构建一个起始层和一个结束层即可:
class UIE(nn.Module):
def __init__(self, encoder):
"""
init func.
Args:
encoder (transformers.AutoModel): backbone, 默认使用 ernie 3.0
Reference:
https://github.com/PaddlePaddle/PaddleNLP/blob/a12481fc3039fb45ea2dfac3ea43365a07fc4921/model_zoo/uie/model.py
"""
super().__init__()
self.encoder = encoder
hidden_size = 768
self.linear_start = nn.Linear(hidden_size, 1)
self.linear_end = nn.Linear(hidden_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(
self,
input_ids: torch.tensor,
token_type_ids: torch.tensor,
attention_mask=None,
pos_ids=None,
) -> tuple:
"""
forward 函数,返回开始/结束概率向量。
Args:
input_ids (torch.tensor): (batch, seq_len)
token_type_ids (torch.tensor): (batch, seq_len)
attention_mask (torch.tensor): (batch, seq_len)
pos_ids (torch.tensor): (batch, seq_len)
Returns:
tuple: start_prob -> (batch, seq_len)
end_prob -> (batch, seq_len)
"""
sequence_output = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
position_ids=pos_ids,
attention_mask=attention_mask,
)["last_hidden_state"]
start_logits = self.linear_start(sequence_output) # (batch, seq_len, 1)
start_logits = torch.squeeze(start_logits, -1) # (batch, seq_len)
start_prob = self.sigmoid(start_logits) # (batch, seq_len)
end_logits = self.linear_end(sequence_output) # (batch, seq_len, 1)
end_logits = torch.squeeze(end_logits, -1) # (batch, seq_len)
end_prob = self.sigmoid(end_logits) # (batch, seq_len)
return start_prob, end_prob
- ** 训练部分**
训练部分主要关注一下 loss 的计算即可。
由于每一个 token 都是一个二分类任务,因此选用 BCE Loss 作为损失函数。
分别计算起始 / 结束向量的 BCE Loss 再取平均值即可,如下所示:
criterion = torch.nn.BCELoss()
...
start_prob, end_prob = model(input_ids=batch['input_ids'].to(args.device),
token_type_ids=batch['token_type_ids'].to(args.device),
attention_mask=batch['attention_mask'].to(args.device))
start_ids = batch['start_ids'].to(torch.float32).to(args.device) # (batch, seq_len)
end_ids = batch['end_ids'].to(torch.float32).to(args.device) # (batch, seq_len)
loss_start = criterion(start_prob, start_ids) # 起止向量loss -> (1,)
loss_end = criterion(end_prob, end_ids) # 结束向量loss -> (1,)
loss = (loss_start + loss_end) / 2.0 # 求平均 -> (1,)
loss.backward()
...
该项目将借用transformers库来实现paddlenlp版本中UIE,已实现:
-
UIE 预训练模型自动下载
-
UIE Fine-Tuning 脚本
-
信息抽取、事件抽取数据增强(DA)策略(提升 recall)
-
信息抽取、事件抽取自分析负例生成(Auto Neg)策略(提升 precision)
- 环境安装
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
pip install -r ../requirements.txt
torch
transformers==4.22.1
datasets==2.4.0
evaluate==0.2.2
matplotlib==3.6.0
rich==12.5.1
scikit-learn==1.1.2
requests==2.28.1
2. 数据集准备
项目中提供了一部分示例数据,数据来自DuIE数据集中随机抽取的100条,数据在 data/DuIE 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集构建prompt和content即可:
{"content": "谭孝曾是谭元寿的长子,也是谭派第六代传人", "result_list": [{"text": "谭元寿", "start": 4, "end": 7}], "prompt": "谭孝曾的父亲"}
{"content": "在圣保罗书院中学毕业后,曾钰成又在中学会考及大学入学考试中名列全港前十名", "result_list": [{"text": "曾钰成", "start": 12, "end": 15}], "prompt": "人物"}
{"content": "在圣保罗书院中学毕业后,曾钰成又在中学会考及大学入学考试中名列全港前十名", "result_list": [{"text": "圣保罗书院", "start": 1, "end": 6}], "prompt": "曾钰成的毕业院校"}
...
doccano导出数据如下所示:
{"text": "谭孝曾是谭元寿的长子,也是谭派第六代传人", "entities": [{"id": 42517, "label": "人物", "start_offset": 0, "end_offset": 3, "text": "谭孝曾"}, {"id": 42518, "label": "人物", "start_offset": 4, "end_offset": 7, "text": "谭元寿"}], "relations": [{"id": 0, "from_id": 42517, "to_id": 42518, "type": "父亲"}]}
...
可以运行 doccano.py 来将标注数据(doccano)转换为训练数据(prompt)。
3. 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python train.py \
--pretrained_model "uie-base-zh" \
--save_dir "checkpoints/DuIE" \
--train_path "data/DuIE/train.txt" \
--dev_path "data/DuIE/dev.txt" \
--img_log_dir "logs/" \
--img_log_name "UIE Base" \
--batch_size 32 \
--max_seq_len 256 \
--learning_rate 5e-5 \
--num_train_epochs 20 \
--logging_steps 10 \
--valid_steps 100 \
--device cuda:0
正确开启训练后,终端会打印以下信息:
...
0%| | 0/1 [00:00<?, ?ba/s]
100%|██████████| 1/1 [00:00<00:00, 6.91ba/s]
100%|██████████| 1/1 [00:00<00:00, 6.89ba/s]
global step 10, epoch: 1, loss: 0.00244, speed: 2.08 step/s
global step 20, epoch: 1, loss: 0.00228, speed: 2.17 step/s
global step 30, epoch: 1, loss: 0.00191, speed: 2.17 step/s
global step 40, epoch: 1, loss: 0.00168, speed: 2.14 step/s
global step 50, epoch: 1, loss: 0.00149, speed: 2.11 step/s
global step 60, epoch: 1, loss: 0.00138, speed: 2.15 step/s
global step 70, epoch: 2, loss: 0.00123, speed: 2.29 step/s
global step 80, epoch: 2, loss: 0.00112, speed: 2.12 step/s
global step 90, epoch: 2, loss: 0.00102, speed: 2.15 step/s
global step 100, epoch: 2, loss: 0.00096, speed: 2.15 step/s
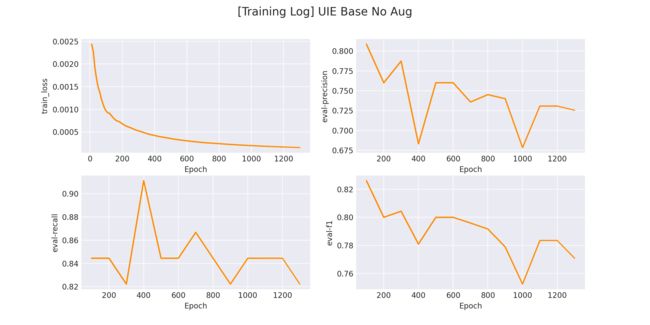
Evaluation precision: 0.80851, recall: 0.84444, F1: 0.82609
best F1 performence has been updated: 0.00000 --> 0.82609
...
在 logs/UIE Base.png 文件中将会保存训练曲线图:
4. 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
if __name__ == "__main__":
from rich import print
sentences = [
'谭孝曾是谭元寿的长子,也是谭派第六代传人。'
]
# NER 示例
for sentence in sentences:
ner_example(
model,
tokenizer,
device,
sentence=sentence,
schema=['人物']
)
# SPO 抽取示例
for sentence in sentences:
information_extract_example(
model,
tokenizer,
device,
sentence=sentence,
schema={
'人物': ['父亲'],
}
)
NER和事件抽取在schema的定义上存在一些区别:
-
NER的schema结构为
List类型,列表中包含所有要提取的实体类型。 -
信息抽取的schema结构为
Dict类型,其中Key的值是所有主语,Value对应该主语对应的所有属性。 -
事件抽取的schema结构为
Dict类型,其中Key的值是所有事件触发词,Value对应每一个触发词下的所有事件属性。
python inference.py
得到以下推理结果:
[+] NER Results:
{
'人物': ['谭孝曾', '谭元寿']
}
[+] Information-Extraction Results:
{
'谭孝曾':
{
'父亲': ['谭元寿']
},
'谭元寿': {
'父亲': []
}
}
5. 数据增强(Data Augmentation)
信息抽取/事件抽取的数据标注成本较高,因此我们提供几种针对小样本下的数据增强策略。
包括:
-
正例:SwapSPO、Mask Then Fill
-
负例:自分析负例生成(Auto Neg)
所有实现均在 Augmenter.py 中,为了便于使用,我们将其封装为 web 服务以方便调用:
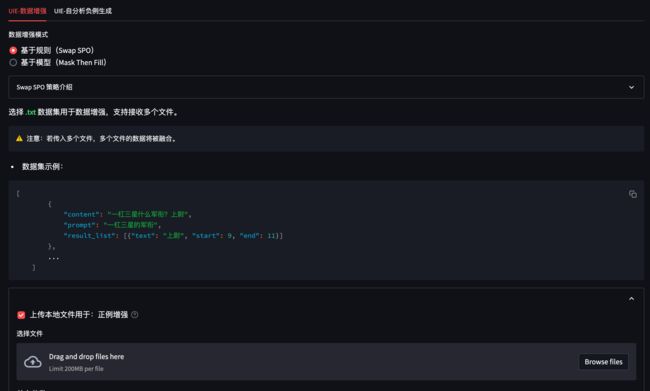
平台使用 streamlit 搭建,因此使用前需要先安装三方包:
pip install streamlit==1.17.0
随后,运行以下命令开启标注平台:
streamlit run web_da.py --server.port 8904
在浏览器中访问 ip + 端口(默认8904)即可打开标注平台。
5.1 正例:SwapSPO 策略介绍
Swap SPO 是一种基于规则的简单数据增强策略。
将同一数据集中相同 P 的句子分成一组,并随机交换这些句子中的 S 和 O。
- 策略输入:
《夜曲》 是 周杰伦 作曲 的一首歌。
《那些你很冒险的梦》 是当下非常火热的一首歌,作曲 为 林俊杰。
- Swap SPO 后的输出:
《夜曲》 是当下非常火热的一首歌,作曲 为 周杰伦。
5.2 正例:Mask Then Fill 策略介绍
Mask Then Fill 是一种基于生成模型的信息抽取数据增强策略。
对于一段文本,我们其分为「关键信息段」和「非关键信息段」,包含关键词片段称为「关键信息段」。
下面例子中标粗的为 关键信息片段,其余的为 非关键片段。
大年三十 我从 北京 的大兴机场 飞回 了 成都。
我们随机 [MASK] 住一部分「非关键片段」,使其变为:
大年三十 我从 北京 [MASK] 飞回 了 成都。
随后,将该句子喂给 filling 模型(T5-Fine Tuned)还原句子,得到新生成的句子:
大年三十 我从 北京 首都机场作为起点,飞回 了 成都。
Note: filling 模型是一个生成模型,示例中我们使用中文 T5 微调得到 DuIE 数据集下的模型(暂未开源)。您可以参考 这里 微调一个更适合您自己数据集下的 filling 模型,并将训练好的模型路径填写至 web_da.py 中对应的位置。
...
device = 'cpu' # 指定设备
generated_dataset_height = 800 # 生成样本展示高度
max_show_num = 500 # 生成样本最大保存行数
max_seq_len = 128 # 数据集单句最大长度
batch_size = 128 # 负例生成时的batch_size
filling_model_path = '这里' # fine-tuned filling model
...
5.3 负例:自分析负例生成(Auto Neg)策略介绍
信息抽取中通常会存在 P混淆 的问题,例如:
王文铭,76岁,是西红市多鱼村的大爷。
当我们同时生成 年龄 和 去世年龄 这种非常近义的 prompt 进行抽取时,可能会出现 误召回 的情况:
prompt: 王文铭的年龄 answer: 76岁 -> 正确
prompt: 王文铭的去世年龄 answer: 76岁 -> 错误
因此,我们基于一个已训练好的模型,自动分析该模型在 训练集 下存在哪些易混淆的 P,并为这些 P 自动生成负例,以提升模型的 Precision 指标。
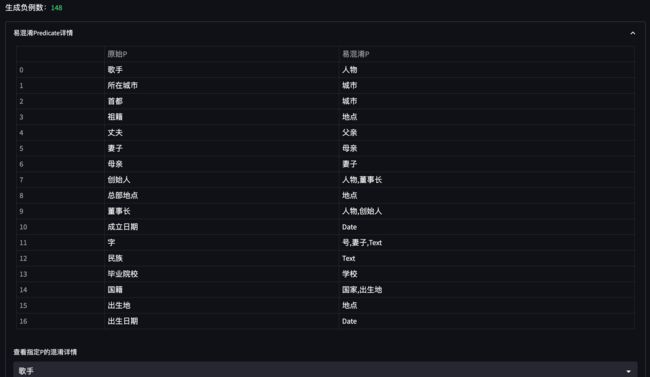
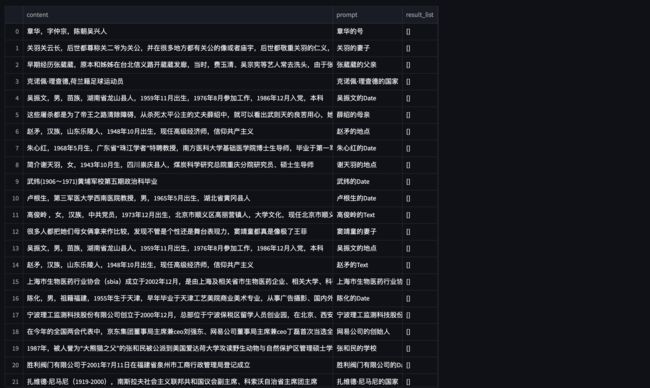
将新生成的负例加入 原始训练数据集,重新训练模型即可。
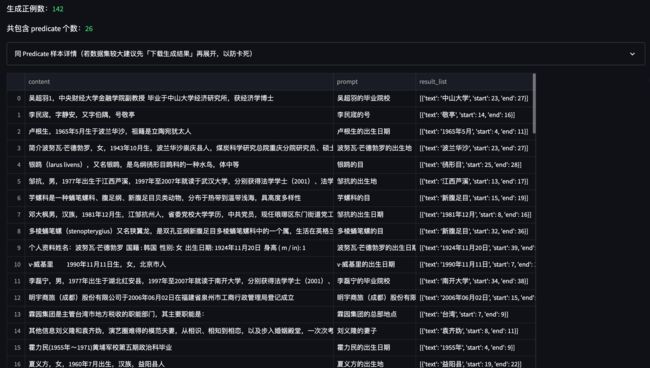
5.4 各种 DA 策略的实验效果
在 DuIE 100 条数据下测试,各种 DA 策略的效果如下所示(以下 P / R / F1 均取 F1 最高的 Epoch 指标):
| DA Policy | Precision(best) | Recall(best) | F1(best) |
|---|---|---|---|
| baseline | 0.8085 | 0.8444 | 0.8260 |
| Swap SPO | 0.8409(↑) | 0.8222 | 0.8314(↑) |
| Auto Neg | 0.8297(↑) | 0.8666(↑) | 0.8478(↑) |
| Mask Then Fill | 0.9000(↑) | 1.0000(↑) | 0.9473(↑) |
| Mask Then Fill & Auto Neg | 0.9777(↑) | 0.9777(↑) | 0.9777(↑) |
-
原作者实现地址:https://github.com/universal-ie/UIE
-
paddle官方:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
-
https://github.com/HarderThenHarder/transformers_tasks/blob/main/UIE
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。