Hive的窗口函数与行列转换函数及JSON解析函数
1. 系统内置函数
查看系统内置函数:show functions ;
显示内置函数的用法: desc function lag; – lag为函数名
显示详细的内置函数用法: desc function extended lag;
1.1 行转列
行转列是指多行数据转换为一个列的字段。
Hive行转列用到的函数
concat(str1,str2,...) 字段或字符串拼接
concat_ws('分割符',str1,str2,...) 将字段或字符串按分割符号拼接
collect_set(column1), 收集某个字段的值,进行去重汇总,产生Array类型,即将某列数据转换成数组
行转列函数的应用:将星座和血型相同的人归类到一起
原数据

脚本
with t1 as (
select name, concat(constellation,',', blood_type) as cb
from constellation
)
select cb,concat_ws(',',collect_set(name)) as names from t1
group by cb;
行转列后的结果

1.2 列转行
explode(col):将hive一列中复杂的array或者map结构拆分成多行。
explode(ARRAY) 数组的每个元素生成一行
explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列
脚本
select explode(names) name from constellation_01;
列转行后执行结果
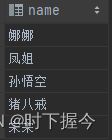
lateral view 和 split, explode等UDTF一起使用。explode能够将一列数据拆分成多行,形成一张临时表,与原表进行聚合
select cb,name
from constellation_01
lateral view explode(names) constellation_01_temp as name;
1.3 窗口函数
不仅展示窗口计算的字段,也展示原字段
源数据
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
执行脚本
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/datas/business.txt" into table business;
执行结果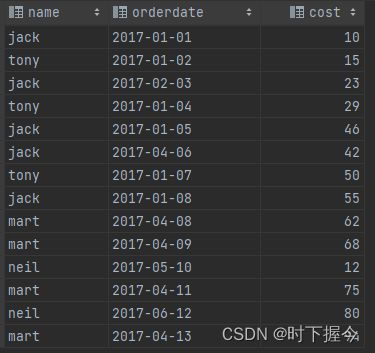
1.3.1 聚合开窗函数
窗口函数和聚合函数的结合使用

执行脚本
select name,orderdate,cost,
count(*) over(partition by month(orderdate)),-- 顾客信息及每月总购买人数
sum(cost) over(partition by month(orderdate)), -- 顾客信息及每月总购买金额
sum(cost) over(partition by month(orderdate) order by orderdate rows between unbounded preceding and current row), -- 起点到当前行的累加金额
sum(cost) over(partition by month(orderdate) order by orderdate rows between 1 preceding and current row), -- 前一行 和 当前行
sum(cost) over(partition by month(orderdate) order by orderdate rows between current row and 1 following), -- 当前行 和 后一行
sum(cost) over(partition by month(orderdate) order by orderdate rows between 1 preceding and 1 following), -- 前一行 到 后一行
sum(cost) over(partition by month(orderdate) order by orderdate rows between current row and unbounded following) -- 当前行到后面所有行
from business
计算结果
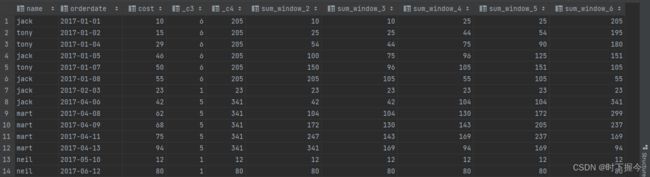
1.3.2 排序开窗函数
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
执行脚本
select name,orderdate,cost,
row_number() over (partition by month(orderdate) order by cost desc), -- 按花费金额由多到少排序,依次编号
rank() over (partition by month(orderdate) order by cost desc), -- 按花费金额由多到少排序,相等的排名会留下空位
dense_rank() over (partition by month(orderdate) order by cost desc) -- 按花费金额由多到少排序,相等的排名不会留下空位
from business;
计算结果
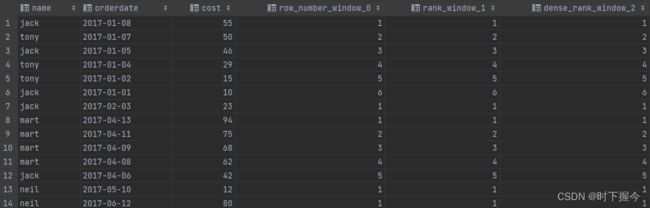
1.3.3 lag和lead函数
LAG(col,n): 往前第n行第col列的数据
LEAD(col,n):往后第n行第col列的数据
执行脚本
select name,orderdate,cost,
lag(orderdate,1) over(partition by month(orderdate) order by orderdate), -- 上一次购买日期(往前第n行数据)
lead(orderdate,1)over(partition by month(orderdate) order by orderdate) -- 下一次购买日期(往后第n行数据)
from business;
计算结果

1.4 JSON解析函数
hive中内置的json_tuple()函数,可以将json数据解析成普通的结构化数据表
源数据
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
执行脚本
create table t_json(json string);
load data local inpath "/export/data/datawarehouse/movie.txt" overwrite into table t_json;
create table movie_rate
as
select json_tuple(json,'movie','rate','timeStamp','uid') as (movie,rate,ts,uid) from t_json;
执行结果
