http与https原理分析
概述
http(HyperText Transfer Protocol,超文本传输协议)协议是互联网中位于协议栈顶层最重要的网络协议之一,它规定了如何在互联网中传输超文本(含有指向其它文本文件链接的文本),而超文本是互联网中数据传输的主要形式。
https = http + secure(安全层),https是由http协议加上安全传输协议SSL/TLS组成的,用于在互联网中安全地传输数据。
下面我们就一起来看这两个协议的基本原理。
http篇
在了解http协议如何工作之前,我们首先需要对网络协议有一个整体的认识。
网络协议概述(基于五层网络协议)
所谓网络协议,就是用来规定如何在网络环境中传输数据的。网络协议是一个对等分层结构,各层划分没有严格规定,这里我们以常见的五层网络协议结构来讲解,协议分为以下几层:
- 应用层协议,如HTTP、FTP(文件传输协议)、SMTP(简单邮件传输协议)等
- 传(运)输层协议,最重要的包括TCP和UDP
- 网络层协议,主流协议是IP协议
- 数据链路层协议,如ALOHA、CSMA等
- 物理层协议,如RS-232-C、RS-449、V.35等
协议图示如下(图片来自网络):
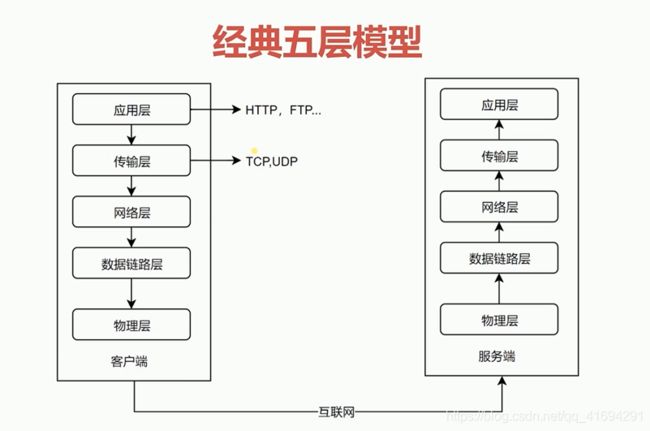
应用层协议负责两个进程的通信,传输层协议负责两台主机之间的通信,网络层协议负责数据在网络中的路由导航,数据链路层协议负责数据包在两台网络设备间的数据传输,而物理层定义了二进制数据是如何在物理媒介(如光纤、电缆以及无线传输等)中传递的。
假如我们现在输入了百度首页的网址,百度的服务器将返回它的首页(一般为index.html文件)。五层网络协议在数据传输中扮演的角色如下(假设TCP连接已经建立,TCP三次握手过程请参考浏览器(基于Chromium)运行机制剖析一文):
- 服务器封装一个http数据包,添加对该html文件的描述信息,如数据类型(这里是text/html)、压缩方式、发送日期、失效日期、方法类型、URL等,然后将首页以字符串格式作为响应正文填充到数据包的正文中。
- 操作系统按照TCP协议将上述数据包拆分成若干个更小的报文(防止某些请求独占带宽造成网络拥堵),并给每个报文都添加相应的描述参数,用于保证目标主机能正确将这些报文恢复成原始的http数据包。
- TCP协议调用IP协议进行报文的网络间传输。IP协议负责在网络中找到最合适的路由线路来传输这些报文(最典型的运行IP协议的设备就是路由器,它是数据在网络中传输的中转站,数据可能要经过多个路由器转发才能找到目标主机),IP协议可能根据不同的网络情况对数据包进行再次拆分(不同网络对数据包大小的限制可能不一样)。
- 当一个路由器根据IP协议找到下一个要发送到的路由设备时,就需要调用数据链路层协议,来负责两个路由设备之间的数据传输。数据链路层协议将数据包拆分成更小的数据帧,便于进行流量控制和差错校验,保证数据包最终正确到达下一个路由设备。
- 路由设备可能通过不同的媒介连接,如光纤、电缆、无线连接等,物理层协议负责定义如何在各种类型的媒介中传输二进制数据流(即0和1组成的数据流,在电缆中以高低电压表示,在光纤中则以光信号存在)。
数据传输过程如下(图片为手绘):

从整体上来看,服务器返回的数据经过http封装交给TCP协议,TCP协议将其拆分为多个数据包,使用IP协议在网络间寻找合适的路由线路来传递这些数据包,当这些数据包最终到达目标主机时,将按照拆分时的规则进行重组还原,最终得到原始的http数据包,浏览器解析这个http数据包,渲染页面。数据链路层用于控制每条链路的数据传输、物理层定义数据在不同媒介中的传输规则。网络协议的基本原理是,上层协议使用下层协议提供的功能,而下层协议为上层协议提供服务。
http协议的工作原理
简单介绍了五层协议的工作原理后,我们现在将目光聚焦于应用层的http协议(通常这是前端关注的核心,但使用nodejs时也可能包括传输层的TCP协议)。
如上所述,应用层协议负责两个进程之间的数据通信。因此如果两个进程都遵循http协议,那么这两个进程就可以使用http协议进行通信(这需要下面四层网络协议提供的服务)。通常客户端使用浏览器来启动和管理这个进程,而服务端一般使用web容器(如Apache的Tomcat等)来开启进程运行http协议。
一个http请求分为两个阶段:请求阶段和响应阶段。请求阶段,客户端通过浏览器封装一个符合http规范的http请求(只有按http规范封装的请求才能使用http规范解析,这也是协议的本质),然后借助TCP提供的服务,将其发送到服务器。服务器接收到该请求后,按照http规范解析该请求。响应阶段,服务器根据解析结果,找到客户端所请求的资源,同样将其按照http规范封装成数据包,借助TCP服务,将其返回客户端浏览器。浏览器以http规范解析数据包,得到响应数据,将其渲染到页面上。一次http请求至此完成。
http协议的实现
请求阶段
大致了解了http协议的工作原理后,我们就可以更深入地分析http协议是如何封装数据的了。首先来看一个http请求的结构:

一个http请求包含4部分,分别是请求行、请求头部、一个空行和请求数据。下面分别来看:
- 请求行。首先是请求方法,常见的如get、post、head、delete、put、options等,不同的方法代表不同的请求目的。然后是URL,表示请求的资源地址。协议版本,表示使用的http协议版本。
- 请求头部。请求头部是关于本次请求的一些描述,如Accept(允许的响应类型)、Accept-Encoding(使用的压缩方法)、Cookie(客户端身份信息)、User-Agent(客户端使用的浏览器参数描述)等,服务端需要这些参数来解析请求。
- 一个空行。用于隔离头部和请求数据。
- 请求数据。当客户端需要向服务器提交某些数据时(如一个表单),浏览器就会将这些数据封装为请求数据供服务器解析使用。
一个http请求就封装好了,现在只需要把这个数据包交给TCP协议,就可以传输到指定的服务器(服务器地址借助DNS域名系统可以得到,浏览器运行机制一文中有介绍)。服务器收到这个数据包后,按照同样的规则,分别解析出请求行、请求头部和请求数据,这样请求阶段就完成了。
响应阶段
服务器收到请求后,会根据请求的内容进行处理,得到需要返回给客户端的数据。接下来服务器就需要按照http协议规范将这些数据封装成一个http响应。http响应的结构与http请求有所不同:
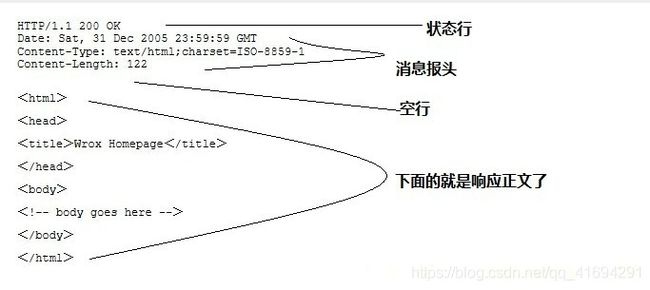
这就是一个典型的http响应。同样分为四部分:状态行、消息报头、空行和响应正文。
- 状态行。描述了本次http请求的状态信息。首先是使用的http协议版本,然后是一个状态码(描述了请求的状态,200表示请求被正确响应),最后是一个状态描述字符串OK。
- 消息报头。关于该响应的参数描述,如Content-length(响应数据长度)、Content-type(响应类型)、Date(发送日期)、Server(服务器类型)等。客户端根据这些参数来决定如何解析响应消息以及后续如何缓存资源。
- 一个空行。用来隔离响应头和响应正文。
- 响应正文。服务器返回给客户端的消息正文。
客户端接收到该响应消息后,按照上述规则解析出数据。如果是资源文件(如HTML页面、js文件、css文件等),浏览器将通知Browser进程进行读取;如果是普通的http请求,将调用对应的回调函数来处理返回的数据。
现在一次http请求就完成了。客户端通过一次http请求,从服务端拿到了需要的数据。在加载一个页面时,通常会发送大量的http请求来获取所有需要加载的资源,包括静态资源文件及用于加载页面数据的异步请求等。
关于http状态码的补充说明
在http响应头的第一行总会带上一个关于本次请求状态描述的状态码(如200)。http请求有时并不能正确获取到数据,这其中的原因有很多,而每一个状态码就对应一种请求的状态,这样便于技术人员检查本次http请求哪里出了问题。一般情况下,1xx表示请求未完成,需要后续操作;2xx表示请求被正确处理;3xx表示重定向,即当前请求可能被定向到别的位置去处理;4xx表示客户端的请求异常,如请求的资源不存在(状态码404);5xx表示服务器异常,通常是服务器内部出错。完整的状态码如下(来自菜鸟教程):
100 Continue 继续。客户端应继续其请求
101 Switching Protocols 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议
200 OK 请求成功。一般用于GET与POST请求
201 Created 已创建。成功请求并创建了新的资源
202 Accepted 已接受。已经接受请求,但未处理完成
203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档
205 Reset Content 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域
206 Partial Content 部分内容。服务器成功处理了部分GET请求
300 Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择
301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302 Found 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
303 See Other 查看其它地址。与301类似。使用GET和POST请求查看
304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
305 Use Proxy 使用代理。所请求的资源必须通过代理访问
306 Unused 已经被废弃的HTTP状态码
307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向
400 Bad Request 客户端请求的语法错误,服务器无法理解
401 Unauthorized 请求要求用户的身份认证
402 Payment Required 保留,将来使用
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
405 Method Not Allowed 客户端请求中的方法被禁止
406 Not Acceptable 服务器无法根据客户端请求的内容特性完成请求
407 Proxy Authentication Required 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权
408 Request Time-out 服务器等待客户端发送的请求时间过长,超时
409 Conflict 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突
410 Gone 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置
411 Length Required 服务器无法处理客户端发送的不带Content-Length的请求信息
412 Precondition Failed 客户端请求信息的先决条件错误
413 Request Entity Too Large 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息
414 Request-URI Too Large 请求的URI过长(URI通常为网址),服务器无法处理
415 Unsupported Media Type 服务器无法处理请求附带的媒体格式
416 Requested range not satisfiable 客户端请求的范围无效
417 Expectation Failed 服务器无法满足Expect的请求头信息
500 Internal Server Error 服务器内部错误,无法完成请求
501 Not Implemented 服务器不支持请求的功能,无法完成请求
502 Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
505 HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理
https篇
使用http协议,我们已经能正确地在网络间传输数据了(需要依赖下层协议提供的服务)。但是网络之间的数据传递通常是不够安全的,有很多技术手段可以在数据传输的过程中截获数据。如果我们请求的是百度的首页,那么被截获当然没什么影响。但是假如我们正在进行银行卡支付,我们的卡号跟密码都需要通过网络传输,这些数据一旦被截获了,那么后果可想而知。所以,为了能在网络间安全地传输数据,我们需要对数据进行加密,这样即使数据传输过程中被截获,也无法破解出我们的银行卡号和密码。于是在http协议的下层又出现了一个新的安全层协议,通常使用SSL或TLS,http加上这个安全层,就是我们所说的https,安全层的职责就是为http提供加密服务。
最简单的加密过程如下:
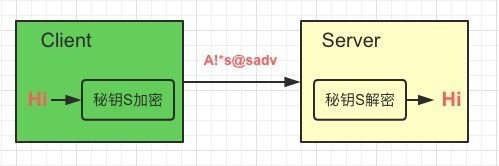
最简单的加密算法如Base64,虽然算得上是一种加密算法,但实际上一般被认为只是一种压缩算法。因为任何由它加密的数据,都可以用它自身解密,而它本身又是完全公开的,因此毫无安全性可言。
目前最常用的加密算法分为两类:对称加密和非对称加密。
对称加密使用一组很长的二进制数(通常为1024位或2048位)进行加密,我们把这个二进制数称为密钥,它是由若干个随机数经过一定的算法计算出来的。使用这个密钥,对称加密算法可以把原始数据处理成完全无法阅读的数据流,但是只要用这个密钥,按照加密规则反向解密,就可以还原出原始数据。这就是说只要通信双方都有该密钥,就可以进行正常通信,并且即使数据被截获,没有密钥也无法知道传输的数据内容。这个密钥通常由客户端生成。
对称加密过程如下:

那么问题就来了,通信双方如何同时安全地拿到这个密钥呢?这实际上是个自相矛盾的问题。
如果将密钥直接放在网络间进行传输,那有很大的风险会被截获,之后进行的加密传输都不再安全(因为截获了密钥的第三方也可以解密出数据)。如果对密钥进行再次加密,那么将陷入一个死循环(为了加密上一个密钥,我们又必须生成新的密钥,这样将无休无止…)。
在银行业务中实际上存在一种解决方案:在你办理了银行卡后,银行会附带给你一个U盘(一般称为U盾),里面就带有上述密钥,而银行本身自然也保留有该密钥。于是你和银行可以不通过网络传输同时拿到密钥,这样就保证了安全性(但是这样做的成本恐怕只有银行能接收)。
为了能在网络中安全地传输密钥,安全层用到了一种被称为非对称加密的算法:RSA算法(该算法甚至被称为密码学的基石算法)。该算法的特点是:加密和解密使用不同的密钥,加密时使用的称作公钥,而解密时使用的称作私钥。公钥和私钥是成对出现的,使用某个公钥加密的数据,只能使用与之对应的私钥解密,同样的,使用私钥加密的数据也只能用公钥来解密(后面介绍数字签名时会用到)。
非对称加密的原理如下:
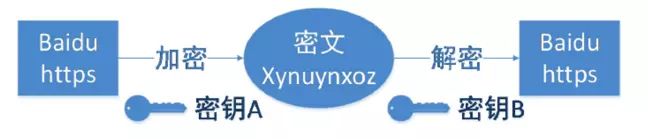
回到上述问题,我们知道,使用对称加密算法无法在网络间安全地传输密钥。而非对称加密算法就是为了解决这个问题的。
假如现在某个服务器已经拥有了一对公钥和私钥。当我们访问服务器时,服务器就会把公钥返回给我们,我们使用这个公钥对我们的密钥加密后发送给服务器,服务器收到加密后的密钥,使用私钥进行解密,就可以得到我们在对称加密算法中生成的密钥了。并且即使这个密钥中途被截获了,没有私钥也是无法解析出该密钥的。
一个很明显的问题是,既然非对称加密本身是安全的,那么我们为什么只用它来加密一个密钥,而不是直接使用非对称加密来传输数据呢?原因也很简单,因为非对称加密算法运算量非常大,对CPU的消耗是巨大的,加密解密时间非常长,根本无法接受。而对称加密相对来说更加轻量,加密解密速度相对较快。另外,非对称加密无法加密大于公钥长度的数据,也就是说,如果非对称加密的公钥长度为1024位,那么它只能加密长度不超过1024位的数据。所以我们的策略就是,用非对称加密来传输对称加密的密钥,一旦双方都拿到了密钥,之后的通信全部使用该密钥进行对称加密。
非对称加密的过程用到了一个重要的算法 - RSA算法。作为https最核心的算法,RSA算法的安全性直接决定了整个https的安全性。下面我们就一起看一下https是如何借助RSA算法来进行密钥传输的。
https请求过程
不同于http请求的简单过程,https需要经过多次交互,才能建立一个安全的连接。大致过程如下(图片来自网络,这里只是原理图,实际的过程比这要复杂一些):

https的请求过程如下:
- 首先客户端需要使用http协议先向服务端发送一条消息,请求服务端的公钥和证书。与此同时,客户端会附带上一个自己生成的随机数(生成对称加密的密钥需要三个随机数,这是其中一个)。
- 然后服务端向客户端返回公钥和一个证书(用于证明服务端的身份,关于证书的作用后面有详细介绍,它是https安全性的保障),并附带一个随机数字(第二个随机数字)。证书包含了网站运营商的注册信息和数字签名,客户端通过比对内置于浏览器的第三方机构信息验证证书的有效性,防止出现域名劫持(即该服务器的域名被某个恶意网站劫持,这样当你输入域名后,访问的就是这个第三方网站的服务器,而不是你想要访问的服务器,俗称钓鱼网站)。公钥就是提供给客户端用来加密的。
- 最后客户端将生成第三个随机数字,称作“预主密钥”,客户端将这个“预主密钥”使用服务端发送来的公钥进行加密,然后传递给服务器。
- 现在客户端和服务端已经各自持有三个随机数字,分别是客户端的第一次发送的随机数字和“预主密码”,以及服务端产生的随机数字。双方将使用同样的算法,以这三个随机数字作为参数,来计算出主密钥,这个主密钥最终将用来进行通信时的对称加密(使用三个随机数字可以增强随机性,更深层的原理属于密码学范畴,不再深入探讨)。
经过上述步骤,客户端和服务端已经安全地拿到了进行对称加密所需的密钥。双方将使用这个密钥,对每次发送的http请求进行对称加密,以防止数据被盗取。
在某些场景(如银行业务)中,不仅客户端需要验证服务端的身份,服务端也需要验证客户端的身份(防止冒名办理业务),这样就需要客户端向服务端提供能证明自己身份的“证书”。这部分不再详述,感兴趣的可以自行查阅资料。
https证书简介
网站运营商使用从某些特定的权威机构申请到的证书来证实自己的身份。在申请证书时,运营商需要向权威机构提供自己的域名、网站用途等相关信息,审核通过后,该机构将向运营商颁发一个数字证书,证书内包含了该网站运营商的注册信息和一个用于网站防伪的数字签名(同时提供用于非对称加密的一对公钥和私钥)。如下面是百度的证书信息(所有https开头的网站,都可以点击网址前面的小锁来查看证书):

点击查看证书信息如下:

还可以点击查看详细信息,里面包含了所有的注册信息,以及使用的加密算法,密钥长度等信息。
上面我们说到,证书中还会包含一个数字签名,那么这个数字签名是用来做什么的呢?
因为第三方机构是完全公开的,任何网站运营商都可以去申请数字证书。假设某个钓鱼网站也向第三方机构申请了一个合法的证书,然后该网站劫持了某个域名,并替换了原来的公钥,就会变成下面的情况:

钓鱼网站现在劫持了这个域名,然后将原本的公钥替换为自己申请的证书中的公钥,那么之后我们使用这个假的公钥加密的信息都会被钓鱼网站用自己的私钥解密出来。这样钓鱼网站就可以成功劫持数据。
为了解决这个问题,https使用了数字签名。第三方注册机构在生成数字证书的时候,会使用为网站运营商提供的私钥将注册信息进行加密作为该网站的数字签名(因此证书内同时包含注册信息和数字签名)。由于非对称加密算法中,使用某个私钥加密的数据只有使用对应的公钥才能解密,所以当钓鱼网站替换了公钥之后,客户端使用这个假公钥就不能正确解密数字签名,浏览器会提示证书验证失败,网站可能是钓鱼网站,这样就保证了网站的安全性。

因为生成一个证书的过程相当繁琐,所以一般申请证书都是要收费的。对于无法承担或者没必要申请证书的网站建设者,也可以使用https的设计原理,自行生成证书(自己生成一张证书大概只需要几分钟,可以使用windows或Linux命令行生成,感兴趣的请自行查阅),使用该证书同样可以进行数据加密。唯一的问题在于,由于不是权威机构颁发,浏览器无法验证证书的合法性,因此这样的证书只能保证每次数据传输的安全性,但无法排除钓鱼网站替换公钥的风险。
总结
http作为应用层最重要的协议之一,严格定义了两个进程如何进行数据通信,可以说是互联网设计中重要的基石之一,多多学习http相关的知识对于网站开发和调试将大有裨益。https包含了大量密码学知识,为网络安全提供了保障,但是从实际情况来看,https有自己的问题存在:
- 性能消耗大。https为了进行密钥交换,需要额外增加三次握手,并且RSA算法的运算量相当大(整个握手过程中,使用该算法计算密钥的时间大约占了总时间的90%),因此我们能明显感觉到,使用https协议的网站加载更慢。
- RSA算法并非绝对可靠。RSA算法的设计基于一个前提,那就是对极大整数做因式分解极其困难。比如很难将下面这个数分解成两个整数的乘积:
12301866845301177551304949
58384962720772853569595334
79219732245215172640050726
36575187452021997864693899
56474942774063845925192557
32630345373154826850791702
61221429134616704292143116
02221240479274737794080665
351419597459856902143413
等于
33478071698956898786044169
84821269081770479498371376
85689124313889828837938780
02287614711652531743087737
814467999489
×
36746043666799590428244633
79962795263227915816434308
76426760322838157396665112
79233373417143396810270092
798736308917
事实上,这大概是人类已经分解的最大整数(232个十进制位,768个二进制位)。
比它更大的因数分解,还没有被报道过,因此目前被破解的最长RSA密钥就是768位。
一旦有人找到快速分解极大整数(如目前RSA算法的密钥长度一般为1024位或2048位)的方法,或者计算机的运算能力可以提升到足够强大(可能数十万倍),RSA算法的可靠性将无法得到保证,这也意味着https将不再可靠。
http和https协议实际上并不像本文介绍的那么简单,作为互联网的基石协议,它们包含了太多的细节,这里只是从整体上对两者作了介绍。想要更深入了解,还需要大量的学习和实践。