Atlas 元数据管理
Atlas 元数据管理
1.Atlas入门
1.1概述
元数据原理和治理功能,用以构建数据资产的目录。对这个资产进行分类和管理,形成数据字典。
提供围绕数据资产的协作功能。
表和表之间的血缘依赖
字段和字段之间的血缘依赖
1.2架构图
导入和导出:

-
是针对元数据的导入和导出的
-
数据的导入和导出需要借助kafka
Metadata Source:元数据
下面以hive为例导入我们的数据。
Zookerper
hive
hadoop
kafka
atlas
安装部署是比较复杂的!
数据分类
Type System
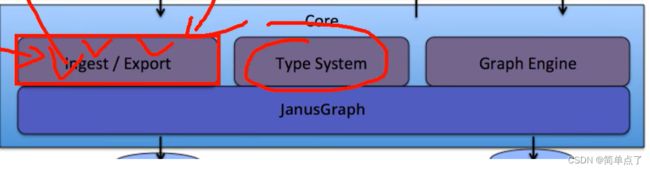
图引擎
表和表的血缘
字段和字段的血缘
Hbase,底层是KV结构的。直接用Hbase存储是不行的。
图结构,多个点多个线。图数据库,底层用的是Graph Engine
solr和es是差不多的,可以搜索数据的,可以查询元数据。
可以对接别的系统
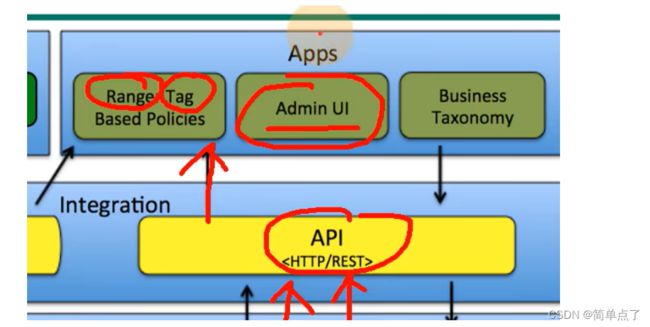
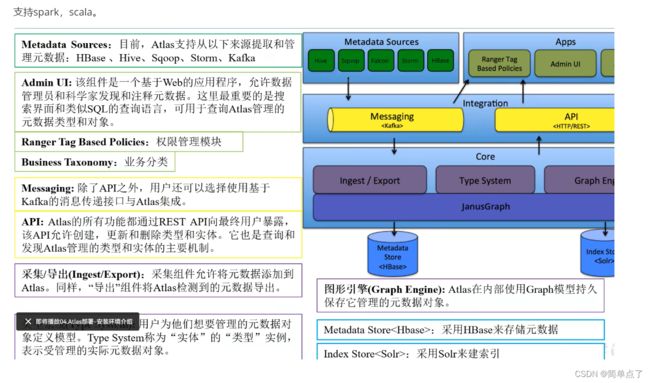
1.3Atlas2.0特性
使用hadoop3.0
Hive3.0 3.1
Hbase2.0
Solr7.5
Kafka2.0
1.4安装规划
1)Atlas 官网地址:Apache Atlas – Data Governance and Metadata framework for Hadoop
2)文档查看地址:Apache Atlas – Data Governance and Metadata framework for Hadoop
3)下载地址:Apache Downloads
1.5安装环境
自带Hbase和Solr,可以使用外部的Hbas和Solr。
Hadoop的组件:
-
HDFS
-
Yarn
-
HistoryServer
Zookeeper:存储元数据的
-
Kafka
-
HBase
-
Solr
Hive:给Atlas提供数据的
MySQL:提供Hive的数据存储的
Atlas:以上全部的启动完成之后才能启动Altlas
1.6复制四个虚拟机
修改主机ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
改主机名
vim /etc/hostname
reboot重启连接xshell
修改Windows的文件
192.168.6.100 hadoop100
192.168.6.101 hadoop101
192.168.6.102 hadoop102
192.168.6.103 hadoop103
192.168.6.104 hadoop104
192.168.6.105 hadoop105
192.168.6.106 hadoop106
192.168.6.107 hadoop107
192.168.6.108 hadoop108
192.168.6.109 hadoop109
192.168.6.200 gitlab-server将下面的文件全部导入到虚拟机中。
全部传递到/opt/software文件夹下。
当出现连接不上的情况就进行重启网络管理器
[root@node01 ~]# systemctl stop NetworkManager
[root@node01 ~]# systemctl disable NetworkManager
Removed symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service.
[root@node01 ~]# service network restart2.环境安装
2.1安装jdk
102中安装jdk
删除系统自带的Java
rpm -qa |grep -i java | xargs -n1 sudo rpm -e --nodeps
解压jdk
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境变量
cd /etc/profile.d/
创建一个自己的环境变量
sudo vim my_env.sh
输入下面的环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
使我们的环境变量生效
> 会自动地遍历profile下的sh为结尾的文件
source /etc/profile
查看Java的环境变量
2.2配置免密登录
.ssh目录下执行下面的语句
ssh-keygen -t rsa
回车三次
创建脚本
chmod 776 xsync
脚本内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
执行
xsync bin设置免费登录
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
解决root下无法识别xsync命令
sudo cp /home/atguigu/bin/xsync /usr/bin/
2.3hadoop的安装
解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
去解压后的目录
cd /opt/module/hadoop-3.1.3
修改配置文件
core-site.xml文件
fs.defaultFS
hdfs://hadoop102:8020
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
hadoop.http.staticuser.user
atguigu
hadoop.proxyuser.atguigu.hosts
*
hadoop.proxyuser.atguigu.groups
*
配置vim hdfs-site.xml
vim hdfs-site.xml
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
配置 vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
设置vim mapred-site.xml
mapreduce.framework.name
yarn
~ 编辑works文件输入下面的内容
hadoop102
hadoop103
hadoop104
配置历史服务器的地址
vim mapred-site.xml
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
配置日志得收集
vim yarn-site.xml
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
进行分发
xsync hadoop-3.1.3/
此时就完成了所有服务器中hadoop得安装了
编写一下环境变量
vim /etc/profile.d/my_env.sh
设置环境变量
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin 分发环境变量
sudo xsync /etc/profile.d/my_env.sh
环境变量生效
source /etc/profile设置一个完整得启动得脚本
myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
启动三个机器的hadoop
myhadoop.sh start

创建一个脚本查看三个脚本的内容
jpsall文件创建
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps $@ | grep -v Jps
done
rm -rf /opt/module/hadoop-3.1.3/logs/ /opt/module/hadoop-3.1.3/data/格式化
hdfs namenode -format下面是启动完成的
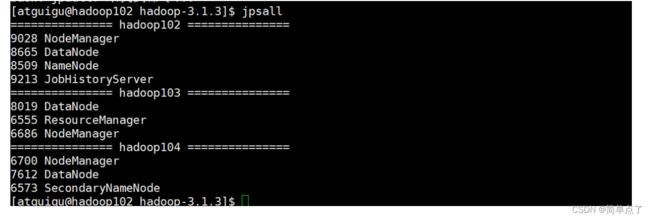
2.4安装MySQL
rpm -qa |grep mariadb
sudo rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64
tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
common安装
lib
额外的lib
client
server
初始化
mysqld --initialize --user=mysql
查看临时密码
cat /var/log/mysqld.log
systemctl start mysqld
mysql -uroot -p
show databases;
update user set host='%' where user='root';
2.5安装Hive
解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
改个名字
mv apache-hive-3.1.2-bin/ hive
修改环境变量
sudo vim /etc/profile.d/my_env.sh
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
环境变量生效
source /etc/profile
Hive的元数据配置
将MySQL的连接的驱动传递过去
cp mysql-connector-java-5.1.37.jar /opt/module/hive/lib/
修改conf下的配置
vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
000000
password to use against metastore database
修改启动文件
mv hive-env.sh.template hive-env.sh
放开下面的启动参数
export HADOOP_HEAPSIZE=1024
修改存储日志的地方‘
mv hive-log4j2.properties.template hive-log4j2.properties
设置一下的参数
property.hive.log.dir = /opt/module/hive/logs初始化hive服务
schematool -initSchema -dbType mysql -verbose次数MySQL数据库就创建成功了。此时MySQL表就创建成功了。
登录hive客户端
CREATE TABLE test_user (
id STRING COMMENT '编号',
name STRING COMMENT '姓名',
province_id STRING COMMENT '省份名称'
) COMMENT '用户表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
yarn中可以产看到运行的进度
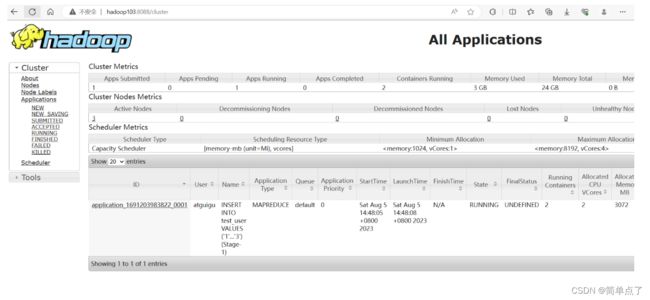

此时在hdfs上有对应的数据
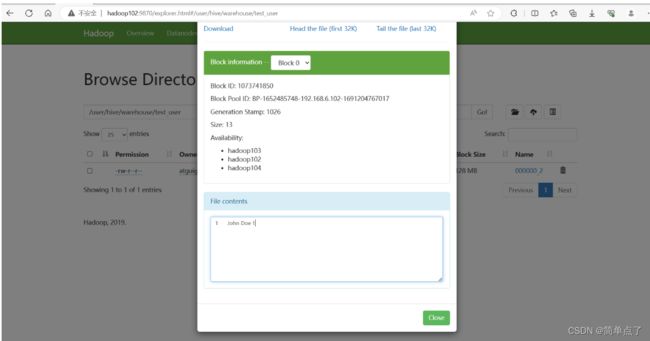

如何解决中文注释的乱码问题
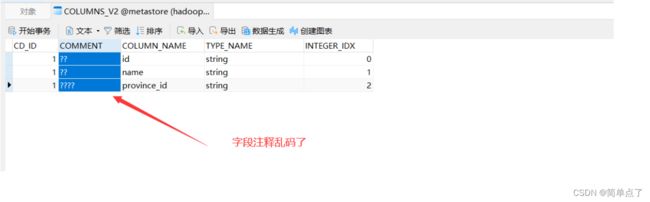
将列改为中文
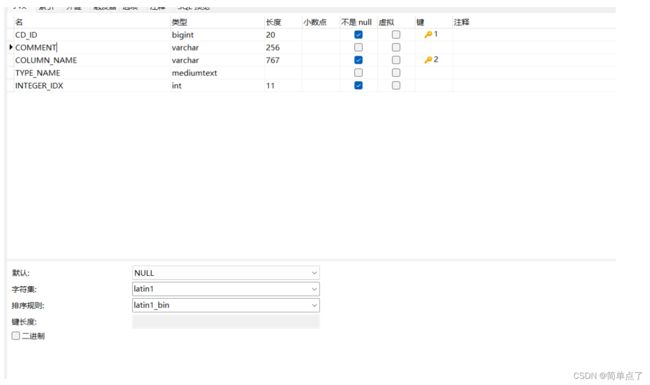
修改配置文件
jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true;characterEncoding=UTF-8 2.6Zookeeper部署
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
修改名字
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
在/opt/module/zookeeper-3.5.7/zkData下的myid文件下设置对应的编号
分别为2 3 4
修改zookeeper的配置文件
mv zoo_sample.cfg zoo.cfg
数据保存的地方
dataDir=/opt/module/zookeeper-3.5.7/zkData
#下面为集群的模式
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
分发一下数据
xsync zookeeper-3.5.7/
zookeeper的bin下创建zk.sh脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo "===================== $i ======================="
ssh $i "source /etc/profile && /opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo "===================== $i ======================="
ssh $i "source /etc/profile && /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
;;
"status")
for i in hadoop102 hadoop103 hadoop104
do
echo "===================== $i ======================="
ssh $i "source /etc/profile && /opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
;;
*)
echo "Input Args Error..."
;;
esac安装成功的状态 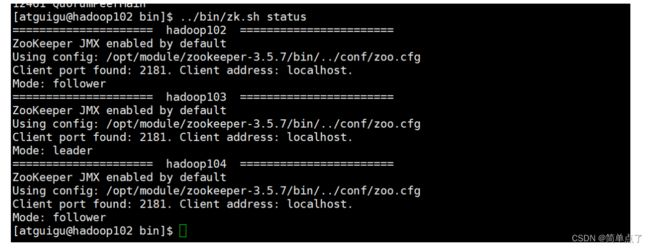
2.7Kafka安装
解压
tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
改个名字
mv kafka_2.11-2.4.1/ kafka
创建logs目录
mkdir logs
修改kafka的配置文件
broker.id=0
delete.topic.enable=true
log.dirs=/opt/module/kafka/data
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
修改环境变量
sudo vim /etc/profile.d/my_env.sh
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
环境变量生效
source /etc/profile
分发
xsync kafka/ 修改server.properties中的配置,分别设置不同的唯一的标识符
分发环境变量
sudo xsync /etc/profile.d/my_env.sh
设置环境变量生效
source /etc/profile创建kafka启动的脚本
cd ~/bin
chmod 777 ./kf.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties "
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
};;
esac
设置这个文件的执行的权限
chmod 777 kf.sh
启动所有的kafka服务
kf.sh start
必须先启动zookeeper才能启动kafka

查看kafka的进程状态
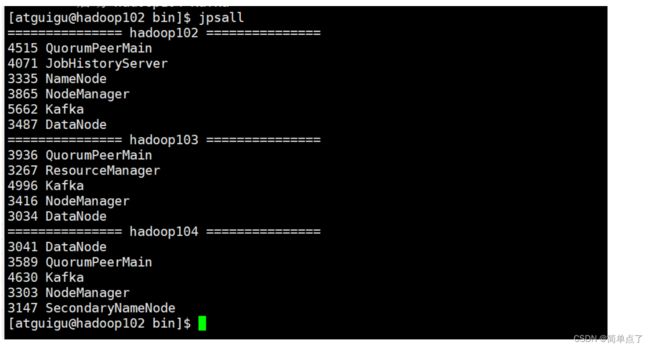
测试一下kafka的进行
创建kafka的topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka \ --create --replication-factor 3 --partitions 1 --topic first
查看所有的
kafka-topics.sh --zookeeper hadoop102:2181/kafka --list查看当前服务器中所有的topic
[atguigu@hadoop102 bin]$ kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
[atguigu@hadoop102 bin]$
创建topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --topic first --partitions 3 --replication-factor 3
实例:
[atguigu@hadoop102 bin]$ kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --topic first --partitions 3 --replication-factor 3
Created topic first.
删除topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka --delete --topic first发送消息
kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
实例:
[atguigu@hadoop104 config]$ kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>1
>2
>3
>4
>5
消费消息
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
实例:
[atguigu@hadoop103 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
1
2
3
4
5

2.8Hbase的安装部署
zookeeper必须正常部署。
必须先启动hadoop。依赖于hdfs。
解压
tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module/
重命名
mv hbase-2.0.5/ hbase
设置环境变量
sudo vim /etc/profile.d/my_env.sh
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
环境变量生效
source /etc/profile
修改配置文件
cd conf
设置外部的zookeeper
sudo vim hbase-env.sh
export HBASE_MANAGES_ZK=false
修改hbase-site.xml,指定zk的位置
sudo vim hbase-site.xml
hbase.rootdir
hdfs://hadoop102:8020/HBase
hbase.cluster.distributed
true
hbase.master.port
16000
hbase.zookeeper.quorum
hadoop102,hadoop103,hadoop104
hbase.zookeeper.property.dataDir
/opt/module/zookeeper-3.4.10/zkData
下面是我配置的配置文件的内容
hbase.rootdir
hdfs://hadoop102:8020/HBase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop102,hadoop103,hadoop104
修改regionservers
sudo vim regionservers
输入下面的内容
hadoop102
hadoop103
hadoop104
分发hbase
xsync hbase/
分发环境变量
sudo xsync /etc/profile.d/my_env.sh
设置环境变量生效
source /etc/profile启动hbase
启动hbase
start-hbase.sh
停止hbase
stop-hbase.sh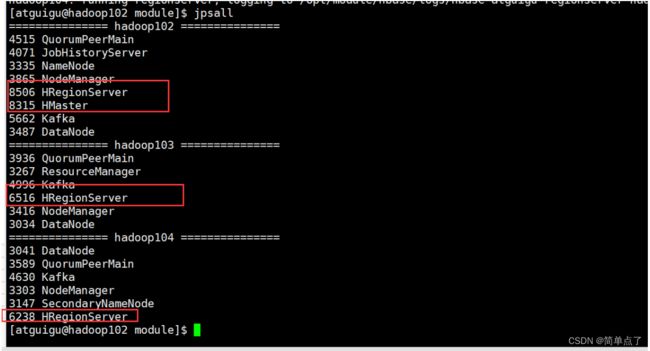
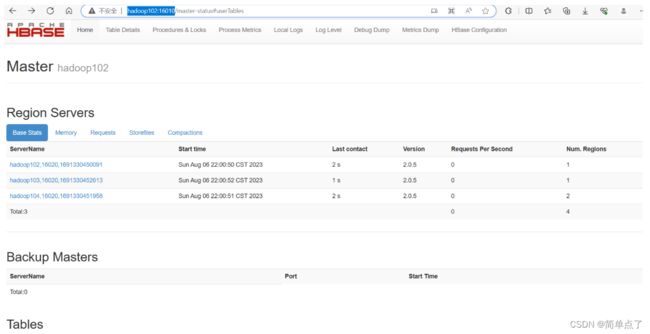
访问Master: hadoop102可以查看集群的信息
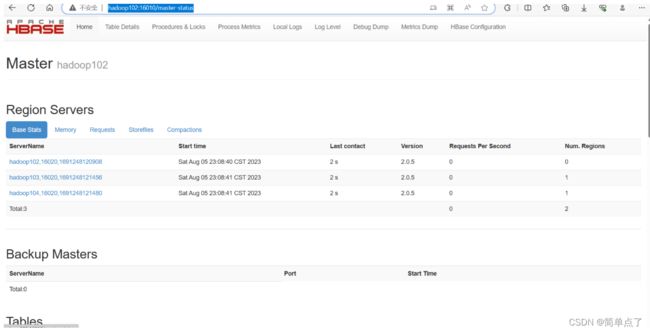
2.9Solr
需要一个索引数据库,并没有采用es。因为atlas底层采用的是solr。
三个主机分别都添加用户solr
sudo useradd solr
设置密码为solr
echo solr | sudo passwd --stdin solr

解压
tar -zxvf solr-7.7.3.tgz -C /opt/module/
修改名称为solr
mv solr-7.7.3/ solr
将当前文件夹的全部的权限都给solr
-R 表示递归执行
sudo chown -R solr:solr /opt/module/solr
sudo chown -R atguigu:atguigu /opt/module/solr
/opt/module/solr/bin/solr start

以管理员的身份去修改solr下的配置文件
sudo vim solr.in.sh
修改下面的内容
ZK_HOST="hadoop102:2181,hadoop103:2181,hadoop104:2181"
分发
xsync solr/处于安全的考虑不推荐采用root的用户进行启动,需要采用自己创建的用户进行启动,solr。

启动
sudo chmod -R 777 /opt/module/solr/
sudo -i -u solr /opt/module/solr/bin/solr start
假设出现打开文件的限制得话运行下面得内容
打开 /etc/security/limits.conf 文件:
sudo vi /etc/security/limits.conf
在文件末尾添加以下行来设置软限制和硬限制:
* soft nofile 65536
* hard nofile 65536下面是启动的集群的可视化配置的界面
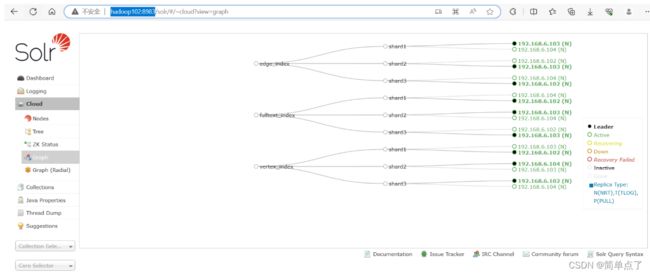
访问下面的地址可以查看solr的管理的界面http://hadoop102:8983/solr/#/~cloud?view=nodes
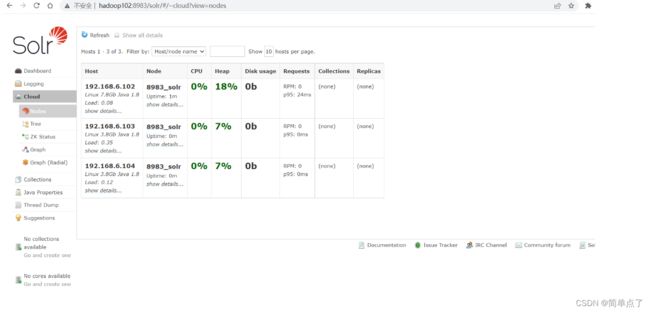
2.10atlas安装
安装不复杂,配置是复杂得
解压
tar -zxvf apache-atlas-2.1.0-bin.tar.gz -C /opt/module/
改个名字
mv apache-atlas-2.1.0/ atlas
配置Hbase
-
修改内容atlas-application.properties
atlas.graph.storage.hostname=hadoop102:8181,hadoop103:8181,hadoop104:8181
- 修改atlas-env.sh中得内容
#hbase连接地址
export HBASE_CONF=/opt/module/hbase/conf
atlas集成solr
-
修改内容atlas-application.properties
atlas.graph.index.search.solr.zookeeper-url=hadoop102:8181,hadoop103:8181,hadoop104:8181- 修改atlas-env.sh中得内容
#hbase连接地址
export HBASE_CONF=/opt/module/hbase/conf
3.Atlas安装和配置
3.1集成Hbase
我们目前安装的是基本的server的包。
安装不复杂,配置是复杂得
解压
tar -zxvf apache-atlas-2.1.0-bin.tar.gz -C /opt/module/
改个名字
mv apache-atlas-2.1.0/ atlas
配置Hbase
-
conf下修改内容atlas-application.properties
atlas.graph.storage.hostname=hadoop102:2181,hadoop103:2181,hadoop104:2181- 修改conf下的atlas-env.sh中得内容
#hbase连接地址
export HBASE_CONF_DIR=/opt/module/hbase/conf
3.2集成solr
atlas集成solr
-
修改conf下的atlas-application.properties
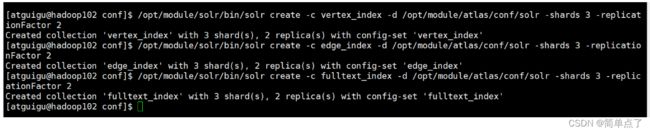
atlas.graph.index.search.solr.zookeeper-url=hadoop102:2181,hadoop103:2181,hadoop104:2181在solr中创建三个collection
/opt/module/solr/bin/solr create -c vertex_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
/opt/module/solr/bin/solr create -c edge_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
/opt/module/solr/bin/solr create -c fulltext_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
下面是创建collection的效果图
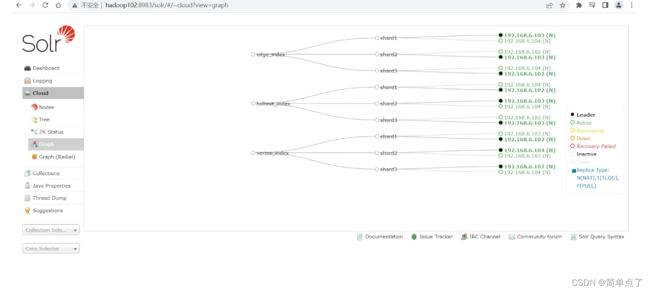
通过前端的界面查看创建的collection
-
此时atlas中的元数据的信息就可以存储到solr中去了
3.3集成Kafka
修改atlas-application.properties配置文件中的内容
下面是改好的内容。
######### Notification Configs #########
atlas.notification.embedded=false
atlas.kafka.data=/opt/module/kafka/data
atlas.kafka.zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
atlas.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:90923.4atlas Server配置
在conf下的atlas-application.properties配置文件中进行下面的修改
######### Server Properties #########
atlas.rest.address=http://hadoop102:21000
atlas.server.run.setup.on.start=false
atlas.audit.hbase.zookeeper.quorum=hadoop102:2181,hadoop103:2181,hadoop104:2181放开下面的注释
conf下的atlas-log4j.xml
3.5集成Hive
atlas可以实时的获取atlas中的元数据。
在conf下的atlas-application.properties最后面加入下面的内容。
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary下面去Hive的conf下的hive-site.xml中加入下面的参数。配置hive hook。
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
安装Hive Hook
安装文件在atlas中的源程序中。
tar -zxvf apache-atlas-2.1.0-hive-hook.tar.gz 
现在需要将上面的这两个文件夹复制到atlas的目录下。
cp -r ./* /opt/module/atlas/
[atguigu@hadoop102 conf]$ sudo vim hive-env.sh
添加下面的内容
export HIVE_AUX_JARS_PATH=/opt/module/atlas/hook/hive
拷贝一份配置文件到hive的配置文件目录下
sudo cp atlas-application.properties /opt/module/hive/conf/
3.6Atlas的启动和登录
hadoop启动
zookeeper启动
kafka启动

在atlas的bin目录下执行下面的命令
启动命令
./atlas_start.py
关闭命令
./atlas_stop.py 启动的时间是比较长的。
错误日志的地方
![]()

atlas管理界面的地址http://hadoop102:21000/
账户:admin
密码:admin
jpsall如果出现一个Atlas的进程的话就是启动成功了。
UI界面加载的时候时候还需要加载一段的时间。
tail -f application.log 
登录上之后
可以进行元数据的管理和查询以及血缘关系的查询。
3.7atlas的作用
-
同步Hive中的元数据。并构建元数据实体之间的关联关系。
-
对所存储的元数据建立索引,最终用户提供数据血缘查看及元数据检索等功能。
Atlas在安装的时候需要进行一次元数据的全量的导入。后续会使用HIve Hook进行同步Hive中的元数据。
全量导入只需要一次。
3.8元数据的导入
进入下面的目录
/opt/module/atlas/hook-bin
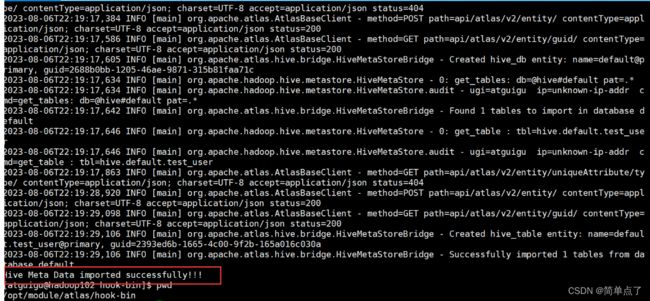
输入下面的命令导入
./import-hive.sh
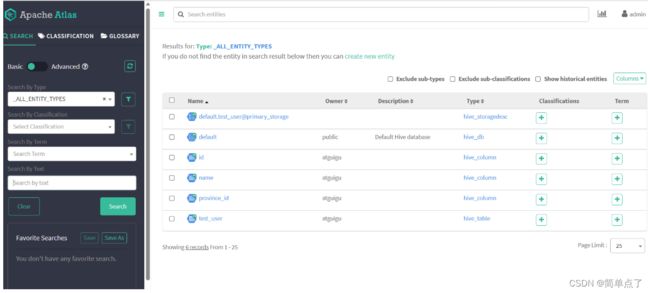
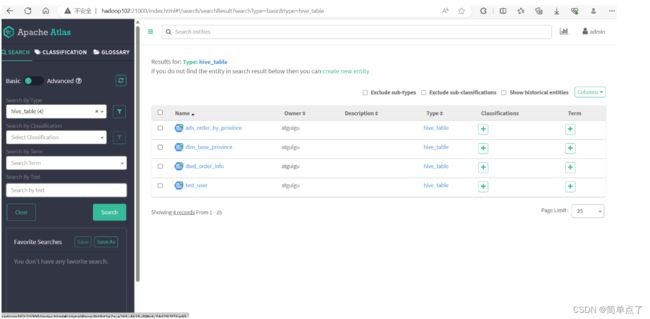
查看导入的表。
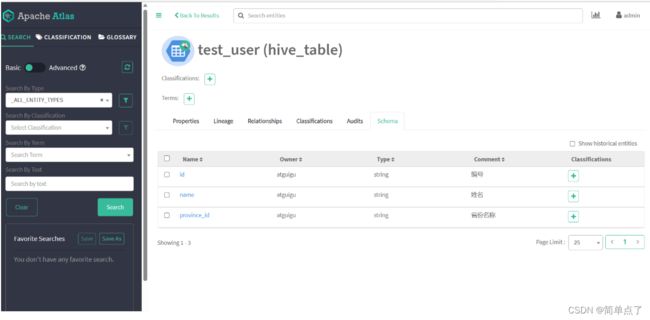
3.9查看血缘关系
订单信息表
CREATE TABLE dwd_order_info (
`id` STRING COMMENT '订单号',
`final_amount` DECIMAL(16,2) COMMENT '订单最终金额',
`order_status` STRING COMMENT '订单状态',
`user_id` STRING COMMENT '用户 id',
`payment_way` STRING COMMENT '支付方式',
`delivery_address` STRING COMMENT '送货地址',
`out_trade_no` STRING COMMENT '支付流水号',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`expire_time` STRING COMMENT '过期时间',
`tracking_no` STRING COMMENT '物流单编号',
`province_id` STRING COMMENT '省份 ID',
`activity_reduce_amount` DECIMAL(16,2) COMMENT '活动减免金额',
`coupon_reduce_amount` DECIMAL(16,2) COMMENT '优惠券减免金额',
`original_amount` DECIMAL(16,2) COMMENT '订单原价金额',
`feight_fee` DECIMAL(16,2) COMMENT '运费',
`feight_fee_reduce` DECIMAL(16,2) COMMENT '运费减免'
) COMMENT '订单表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
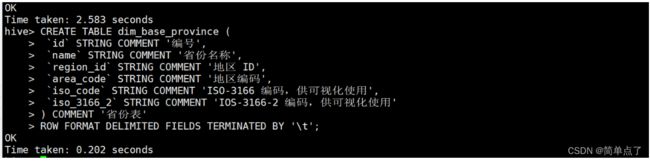
地区维度表
CREATE TABLE dim_base_province (
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省份名称',
`region_id` STRING COMMENT '地区 ID',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT 'ISO-3166 编码,供可视化使用',
`iso_3166_2` STRING COMMENT 'IOS-3166-2 编码,供可视化使用'
) COMMENT '省份表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
插入之后
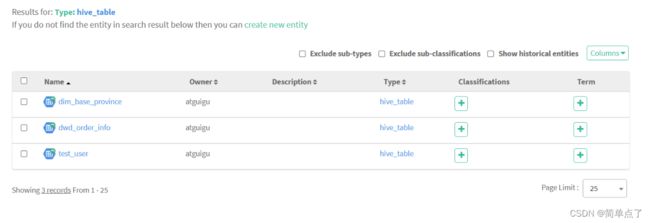
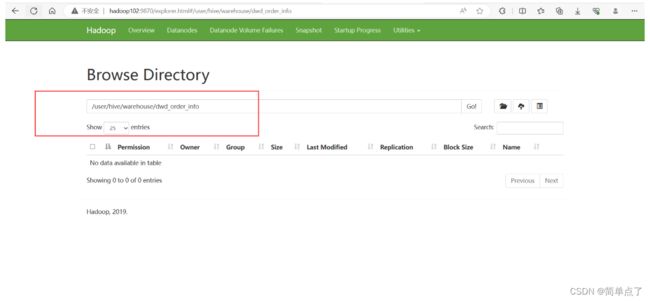
将资料里面提前准备好的数据 order_info.txt 和 base_province.txt 上传到两张 hive 表的 hdfs 路径下
在下面的目录中上传我们的数据
需求指标
1)根据订单事实表和地区维度表,求出每个省份的订单次数和订单金额 2)建表语句
CREATE TABLE `ads_order_by_province` (
`dt` STRING COMMENT '统计日期',
`province_id` STRING COMMENT '省份 id',
`province_name` STRING COMMENT '省份名称',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '国际标准地区编码',
`iso_code_3166_2` STRING COMMENT '国际标准地区编码',
`order_count` BIGINT COMMENT '订单数',
`order_amount` DECIMAL(16,2) COMMENT '订单金额'
) COMMENT '各省份订单统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
数据装载
insert into table ads_order_by_province
select
'2021-08-30' dt,
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.iso_3166_2,
count(*) order_count,
sum(oi.final_amount) order_amount
from dwd_order_info oi
left join dim_base_province bp
on oi.province_id=bp.id
group by bp.id,bp.name,bp.area_code,bp.iso_code,bp.iso_3166_2;
下面是血缘关系图。
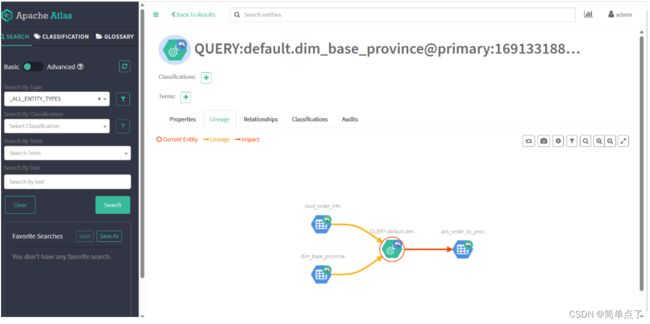
查看字段下单量的血缘族谱。
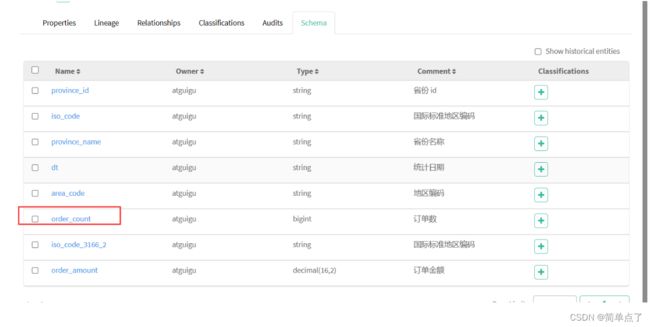
下面是字段的血缘关系。
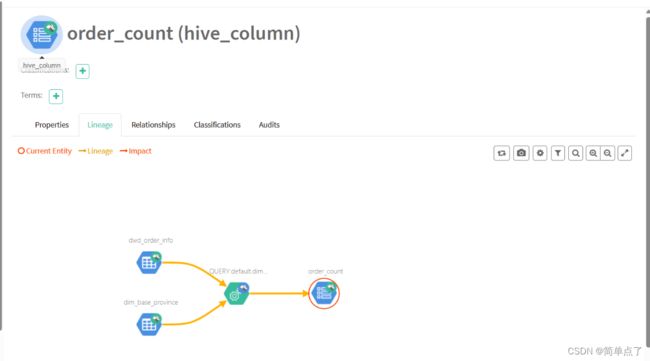
4.网址
4.1Atlas
http://hadoop102:21000/
账号:admin
密:admin
4.2Solr
http://hadoop102:8983/
4.4Hadoop
http://hadoop102:9870/
4.5Yarn
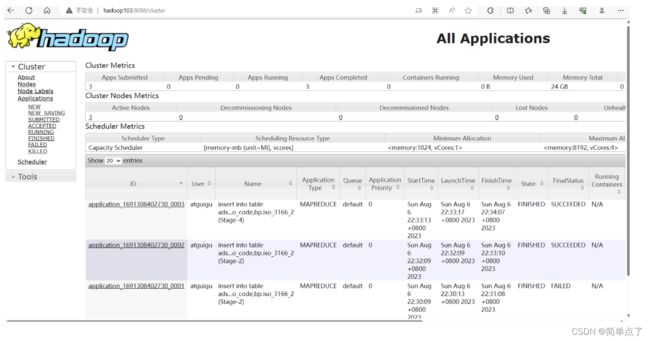
http://hadoop103:8088/
5.启动命令
启动Hadoop::只在102上执行
myhadoop.sh start
MySQL
默认是启动的
hive::只在102上执行
执行hive就可以
zookeeper启动:只在102上执行
cd /opt/module/zookeeper-3.5.7/bin
./zk.sh start
kafka启动:只在102上执行
cd ~/bin
kf.sh start
启动hbase:只在102上执行
cd /opt/module/hbase/bin
启动
start-hbase.sh
停止
stop-hbase.sh
solr三个机器上分别执行
/opt/module/solr/bin/solr start