【山河送书第七期】:《强化学习:原理与Python实战》揭秘大模型核心技术RLHF!
《强化学习:原理与Python实战》揭秘大模型核心技术RLHF!
- 一·图书简介
- 二·RLHF是什么?
- 三·RLHF适用于哪些任务?
- 四·RLHF和其他构造奖励模型的方法相比有何优劣?
- 五·什么样的人类反馈才是好反馈?
- 六·如何减小人类反馈带来的负面影响?
- 七·购买链接
- 八·参与方式
- 九·往期赠书回顾
一·图书简介

RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)虽是热门概念,并非包治百病的万用仙丹。本问答探讨RLHF的适用范围、优缺点和可能遇到的问题,供RLHF系统设计者参考。
二·RLHF是什么?
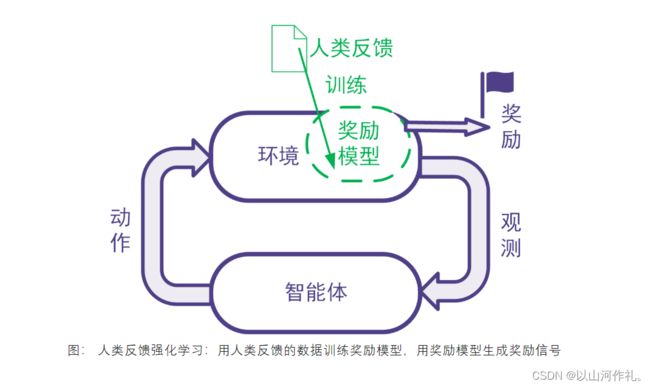
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习,示意图如下。
三·RLHF适用于哪些任务?
RLHF适合于同时满足下面所有条件的任务:
- 要解决的任务是一个强化学习任务,但是没有现成的奖励信号并且奖励信号的确定方式事先不知道。为了训练强化学习智能体,考虑构建奖励模型来得到奖励信号。
- 反例:比如电动游戏有游戏得分,那样的游戏程序能够给奖励信号,那我们直接用游戏程序反馈即可,不需要人类反馈。
- 反例:某些系统奖励信号的确定方式是已知的,比如交易系统的奖励信号可以由赚到的钱完全确定。这时直接可以用已知的数学表达式确定奖励信号,不需要人工反馈。
- 不采用人类反馈的数据难以构建合适的奖励模型,而且人类的反馈可以帮助得到合适的奖励模型,并且人类来提供反馈可以在合理的代价(包括成本代价、时间代价等)内得到。如果用人类反馈得到数据与其他方法采集得到数据相比不具有优势,那么就没有必要让人类来反馈。

四·RLHF和其他构造奖励模型的方法相比有何优劣?
奖励模型可以人工指定,也可以通过有监督模型、逆强化学习等机器学习方法来学习。RLHF使用机器学习方法学习奖励模型,并且在学习过程中采用人类给出的反馈。
比较人工指定奖励模型与采用机器学习方法学习奖励模型的优劣:
这与对一般的机器学习优劣的讨论相同。机器学习方法的优点包括不需要太多领域知识、能够处理非常复杂的问题、能够处理快速大量的高维数据、能够随着数据增大提升精度等等。机器学习算法的缺陷包括其训练和使用需要数据时间空间电力等资源、模型和输出的解释型可能不好、模型可能有缺陷、覆盖范围不够或是被攻击(比如大模型里的提示词注入)。
比较采用人工反馈数据和采用非人工反馈数据的优劣:
人工反馈往往更费时费力,并且不同人在不同时候的表现可能不一致,并且人还会有意无意地犯错,或是人类反馈的结果还不如用其他方法生成数据来的有效,等等。我们在后文会详细探讨人工反馈的局限性。采用机器收集数据等非人工反馈数据则对收集的数据类型有局限性。有些数据只能靠人类收集,或是用机器难以收集。这样的数据包括是主观的、人文的数据(比如判断艺术作品的艺术性),或是某些机器还做不了的事情(比如玩一个AI暂时还不如人类的游戏)。
五·什么样的人类反馈才是好反馈?
好的反馈需要够用:反馈数据可以用来学成奖励模型,并且数据足够正确、量足够大、覆盖足够全面,使得奖励模型足够好,进而在后续的强化学习中得到令人满意的智能体。
这个部分涉及的评价指标包括:对数据本身的评价指标(正确性、数据量、覆盖率、一致性),对奖励模型及其训练过程的评价指标、对强化学习训练过程和训练得到的智能体的评价指标。
好的反馈需要是可得的反馈。反馈需要可以在合理的时间花费和金钱花费的情况下得到,并且在成本可控的同时不会引发其他风险(如法律上的风险)。
涉及的评价指标包括:数据准备时间、数据准备涉及的人员数量、数据准备成本、是否引发其他风险的判断。
六·如何减小人类反馈带来的负面影响?
针对人类反馈费时费力且可能导致奖励模型不完整不正确的问题,可以在收集人类反馈数据的同时就训练奖励模型、训练智能体,并全面评估奖励模型和智能体,以便于尽早发现人类反馈的缺陷。发现缺陷后,及时进行调整。
针对人类反馈中出现的反馈质量问题以及错误反馈,可以对人类反馈进行校验和审计,如引入已知奖励的校验样本来校验人类反馈的质量,或为同一样本多次索取反馈并比较多次反馈的结果等。
针对反馈人的选择不当的问题,可以在有效控制人力成本的基础上,采用科学的方法选定提供反馈的人。可以参考数理统计里的抽样方法,如分层抽样、整群抽样等,使得反馈人群更加合理。
对于反馈数据中未包括反馈人特征导致奖励模型不够好的问题,可以收集反馈人的特征,并将这些特征用于奖励模型的训练。比如,在大规模语言模型的训练中可以记录反馈人的职业背景(如律师、医生等),并在训练奖励模型时加以考虑。当用户要求智能体像律师一样工作时,更应该利用由律师提供的数据学成的那部分奖励模型来提供奖励信号;当用户要求智能体像医生一样工作时,更应该利用由医生提供的数据学成的那部分奖励模型来提供奖励信号。
上述内容摘编自《强化学习:原理与Python实战》,经出版方授权发布。(ISBN:978-7-111-72891-7)
七·购买链接
京东链接:https://item.jd.com/13815337.html
八·参与方式
抽奖方式:评论区随机抽取五位小伙伴免费送出!!
参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,我爱Python!”
(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间:2023-08-21 20:00:00
九·往期赠书回顾
【山河赠书第一期】:《Python从入门到精通(微课精编版》三本
【山河赠书第二期】:《零基础学会Python编程(ChatGPT版》一本
【山河赠书第三期】:《Python机器学习:基于PyTorch和Scikit-Learn 》四本
【山河送书第四期】:《Python之光:Python编程入门与实战》五本
【山河送书第五期】:《码上行动:利用Python与ChatGPT高效搞定Excel数据分析》三本
【山河送书第六期】:《码上行动:零基础学会Python编程( ChatGPT版)》两本
加入粉丝群,不定期发放粉丝福利,各种专业书籍免费赠送!