AI量化模型预测挑战赛 第二次学习笔记
有关竞赛信息以及基础baseline代码解读请看我的上一篇文章
AI量化模型预测——baseline学习笔记_寂ღ᭄秋࿐的博客-CSDN博客
在经过baseline进行详细的分析之后,接下来的方向肯定是奔着提分去的,下面我就从五个方面进行一一列出提分思路
- 提取更多的特征
- 特征筛选方案
- 内存压缩
- 验证方式
- 模型集成
一、提取更多的特征
1. 完善baseline特征
(1)增加构建买二卖二、买三卖三、买四卖四相关特征
# 计算加权平均价格(wap)以及相关特征
train_df['wap2'] = (train_df['n_bid2'] * train_df['n_bsize2'] + train_df['n_ask2'] * train_df['n_asize2']) / (train_df['n_bsize2'] + train_df['n_asize2'])
train_df['wap3'] = (train_df['n_bid3'] * train_df['n_bsize3'] + train_df['n_ask3'] * train_df['n_asize3']) / (train_df['n_bsize3'] + train_df['n_asize3'])
train_df['wap4'] = (train_df['n_bid4'] * train_df['n_bsize4'] + train_df['n_ask4'] * train_df['n_asize4']) / (train_df['n_bsize4'] + train_df['n_asize4'])
# 计算价格差异百分比(price spread)以及相关特征
train_df['price_spread_2'] = (train_df['n_ask2'] - train_df['n_bid2']) / ((train_df['n_ask2'] + train_df['n_bid2']) / 2)
train_df['price_spread_3'] = (train_df['n_ask3'] - train_df['n_bid3']) / ((train_df['n_ask3'] + train_df['n_bid3']) / 2)
train_df['price_spread_4'] = (train_df['n_ask4'] - train_df['n_bid4']) / ((train_df['n_ask4'] + train_df['n_bid4']) / 2)
# 当前时间特征
# 围绕买卖价格和买卖量进行构建
train_df['wap_balance_23'] = abs(train_df['wap2'] - train_df['wap3']) # 加权平均价格差异
train_df['bid_spread_23'] = train_df['n_bid2'] - train_df['n_bid3'] # 买入价差
train_df['ask_spread_23'] = train_df['n_ask2'] - train_df['n_ask3'] # 卖出价差
train_df['total_volume_23'] = (train_df['n_asize2'] + train_df['n_asize3']) + (train_df['n_bsize2'] + train_df['n_bsize3']) # 总交易量
train_df['volume_imbalance_23'] = abs((train_df['n_asize2'] + train_df['n_asize3']) - (train_df['n_bsize2'] + train_df['n_bsize3'])) # 交易量差异
# 围绕买卖价格和买卖量进行构建
# 对于 train_df
train_df['wap_balance_34'] = abs(train_df['wap3'] - train_df['wap4']) # 加权平均价格差异
train_df['bid_spread_34'] = train_df['n_bid3'] - train_df['n_bid4'] # 买入价差
train_df['ask_spread_34'] = train_df['n_ask3'] - train_df['n_ask4'] # 卖出价差
train_df['total_volume_34'] = (train_df['n_asize3'] + train_df['n_asize4']) + (train_df['n_bsize3'] + train_df['n_bsize4']) # 总交易量
train_df['volume_imbalance_34'] = abs((train_df['n_asize3'] + train_df['n_asize4']) - (train_df['n_bsize3'] + train_df['n_bsize4'])) # 交易量差异
可以看到这里我只构建了二、三、四价的特征信息,而并没有构建五价的信息,我尝试了一下在构建相关特征信息之后线下训练直接过拟合了(达到了0.9+),可能和预测的label5有关,故在此处就不建议放入五价的更多信息。
(2)增加二、三、四价的平移、差分、窗口统计特征
# 历史平移
# 获取历史信息
for val in ['wap2','wap3','wap_balance_23','price_spread_2','bid_spread_23','ask_spread_23','total_volume_23','volume_imbalance_23']:
for loc in [1,5,10,20,40,60]:
train_df[f'file_{val}_shift{loc}'] = train_df.groupby(['file'])[val].shift(loc)
test_df[f'file_{val}_shift{loc}'] = test_df.groupby(['file'])[val].shift(loc)
# 差分特征
# 获取与历史数据的增长关系
for val in ['wap2','wap3','wap_balance_23','price_spread_2','bid_spread_23','ask_spread_23','total_volume_23','volume_imbalance_23']:
for loc in [1,5,10,20,40,60]:
train_df[f'file_{val}_diff{loc}'] = train_df.groupby(['file'])[val].diff(loc)
test_df[f'file_{val}_diff{loc}'] = test_df.groupby(['file'])[val].diff(loc)
# 窗口统计
# 获取历史信息分布变化信息
# 可以尝试更多窗口大小已经统计方式,如min、max、median等
for val in ['wap2','wap3','wap_balance_23','price_spread_2','bid_spread_23','ask_spread_23','total_volume_23','volume_imbalance_23']:
train_df[f'file_{val}_win7_mean'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).mean())
train_df[f'file_{val}_win7_std'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).std())
test_df[f'file_{val}_win7_mean'] = test_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).mean())
test_df[f'file_{val}_win7_std'] = test_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=7, min_periods=3).std())因代码过多故只展示加入的二价信息,后面三价、四价信息一样。
2. 增加时间信息统计
观察数据可以看到一共用户(uuid)含有多条会话,因此可以根据uuid进行分组进行统计数值型的特征信息。
通过计算描述性统计指标来为数据集中的数值列生成新的特征。
首先,通过定义一个包含数值列名称的列表,确定了需要进行统计的特征。
然后,对于每个唯一的'uuid'标识,代码迭代地组合每个数值列和'uuid',然后针对这些组合,在原始数据集中进行分组。
接下来,通过计算这些分组内数值列的描述性统计指标,例如均值、标准差、最小值、中位数等,来得出有关这些数值列分布和特征的信息。
最后,将计算得到的统计特征合并回原始数据集,以丰富数据的特征表示,为后续的建模分析提供更多有价值的信息。
# 定义需要进行描述性统计的数值列
num_cols = [['wap1', 'wap2', 'wap3', 'wap4',
'price_spread', 'price_spread_2', 'price_spread_3', 'price_spread_4',
'wap_balance', 'bid_spread', 'ask_spread', 'total_volume', 'volume_imbalance']]
# 针对每个 'uuid' 进行统计特征的计算
b = ['uuid']
for i in b:
global_dense_group_feature = []
# 构建特征组合列表,包含 'uuid' 和 num_cols 中的每个数值列
for j in num_cols:
global_dense_group_feature.append([i, j])
# 对于每个 [key, value] 组合,进行统计特征的计算
for [key, value] in tqdm(global_dense_group_feature):
# 对数据按 'uuid' 分组,计算描述性统计指标,并重新命名列
tmp = train_df.groupby([key])[value].describe().reset_index()
tmp.columns = [key] + [key + '_' + value + '_' + x for x in ['count', 'mean', 'std', 'min', '25%', '50%', '75%', 'max']]
# 将计算得到的统计特征合并回原始数据集中
train_df = train_df.merge(tmp[[key] + [key + '_' + value + '_' + x for x in ['mean', 'std', 'min', '25%', '50%', '75%', 'max']]], on=key, how='left')
3. 增加更多的窗口滑窗以及统计信息
计算在不同时间窗口内的一些统计量,包括均值、标准差、中位数、最小值、最大值、百分位数(例如25%和75%分位数),以及移动平均线(例如指数加权移动平均)。
这些统计量是在每个文件组内进行计算,通过滚动窗口或指数加权移动平均的方式,考虑了最近的数据点,并将计算结果添加到原始DataFrame中,以补充原始特征数据。
这些可以帮助分析数据的趋势、波动性和分布情况,为进一步的数据分析和建模提供更多信息。
for val in fea_cols:
for time in [3, 10, 20]:
# 均值
train_df[f'file_{val}_win{time}_mean'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).mean())
# 标准差
train_df[f'file_{val}_win{time}_std'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).std())
# 中位数
train_df[f'file_{val}_win{time}_median'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).median())
# 最小值
train_df[f'file_{val}_win{time}_min'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).min())
# 最大值
train_df[f'file_{val}_win{time}_max'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).max())
# 25% 分位数
train_df[f'file_{val}_win{time}_pct25'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).quantile(0.25))
# 75% 分位数
train_df[f'file_{val}_win{time}_pct75'] = train_df.groupby(['file'])[val].transform(lambda x: x.rolling(window=time, min_periods=3).quantile(0.75))
# 指数加权移动平均
train_df[f'file_{val}_win{time}_ema'] = train_df.groupby(['file'])[val].transform(lambda x: x.ewm(span=time, min_periods=3).mean())
二、特征筛选方案
1. 相关性筛选特征
检测列中是否包含具有相同值或缺失值过多的特征。对于具有唯一值数量为1的列,这些特征被认为在建模中没有意义
检测相关系数矩阵中存在高于指定阈值的相关性的特征。通过计算数据的相关系数矩阵,代码遍历矩阵的每个元素,比较其绝对值与给定阈值。如果某个元素的绝对值大于阈值,就意味着相应的两个特征之间存在高相关性
print('过滤异常特征... ')
drop_cols = [] # 用于存储需要删除的异常特征列的列表
# 遍历DataFrame `df` 的每一列
for col in df.columns:
# 如果列中的唯一值数量为1,说明该列中所有的值都相同,对于建模来说没有意义,将其添加到 `drop_cols` 列表中
if df[col].nunique() == 1:
drop_cols.append(col)
# 计算每列缺失值的比例,如果缺失值比例超过总行数的 95%,也将该列添加到 `drop_cols` 列表中
if df[col].isnull().sum() / df.shape[0] > 0.95:
drop_cols.append(col)
print('过滤高相关特征...')
# 定义一个函数用于检测高相关特征
def correlation(data, threshold):
col_corr = [] # 用于存储高相关特征列的列表
corr_matrix = data.corr() # 计算数据的相关系数矩阵
# 遍历相关系数矩阵中的每个元素
for i in range(len(corr_matrix)):
for j in range(i):
# 如果某个元素的绝对值大于阈值 `threshold`,说明这两个特征之间存在高相关性
# 将其中一个特征的名称添加到 `col_corr` 列表中
if abs(corr_matrix.iloc[i, j]) > threshold:
colname = corr_matrix.columns[i]
col_corr.append(colname)
return list(set(col_corr)) # 返回包含所有高相关特征的列名的列表2. 特征重要性筛选特征
在特征选择的背景下,通过训练CatBoost分类器模型并分析特征重要性,确定哪些特征对于解决给定的分类问题最为重要。它将模型训练和特征选择结合在一起,以便找到对模型性能有显著贡献的特征,从而优化建模过程并提高预测的准确性。
def model_train(x_train, y_train, x_test, y_test):
params = {'learning_rate': 0.2, 'depth': 12, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 23, 'allow_writing_files': False,
'loss_function': 'MultiClass'}
model = CatBoostClassifier(iterations=5000, **params)
model.fit(x_train, y_train, eval_set=(x_test, y_test),
metric_period=100,
use_best_model=True,
cat_features=[],
verbose=1)
return model
def select_feature(train_df, feature_name, pred):
# 数据划分
x_train, x_test, y_train, y_test = train_test_split(train_df[feature_name], train_df[pred], test_size=0.25, random_state=23)
# 将数据编号进行重编号
x_train, y_train = x_train.reset_index(drop=True), y_train.reset_index(drop=True)
x_test, y_test = x_test.reset_index(drop=True), y_test.reset_index(drop=True)
cat_model = model_train(x_train, y_train, x_test, y_test)
df = pd.DataFrame({'feature': x_train.columns, 'importance': cat_model.feature_importances_}).sort_values(
by='importance', ascending=False) # 降序
use = df.loc[df['importance'] != 0, 'feature'].tolist()
print('有用的特征个数:', len(use))
# print('有用的特征:', use)
return use3.使用对抗训练筛选特征
对抗训练在特征选择中是一种基于模型的方法,它通过在特征子集上构建对抗性模型,使得这些模型难以区分正常数据和噪声数据,从而筛选出对模型更具挑战性的特征。这样的方法可以鼓励模型学习更具鲁棒性的特征,同时抑制噪声对特征选择的影响。
# 划分数据为特征和目标
X = train_df.drop(columns=['target'])
y = train_df['target']
# 划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用 CatBoost 模型构建分类器
model = CatBoostClassifier(iterations=500, learning_rate=0.1, depth=8, random_seed=42)
model.fit(X_train, y_train, eval_set=(X_test, y_test), verbose=100)
# 提取特征重要性
feature_importances = model.get_feature_importance()
# 排序特征重要性
sorted_indices = np.argsort(feature_importances)[::-1]
# 选择前N个重要的特征
num_selected_features = 10
selected_feature_indices = sorted_indices[:num_selected_features]
selected_features = X.columns[selected_feature_indices]
print("Selected features:", selected_features)
4. feature-selection-with-null-importances
通过对数据的随机置换来构建一组基准分布,以评估每个特征在模型中的实际重要性
- 首先,从 提供的数据集中读取数据,并进行预处理和准备。
- 使用 CatBoost 模型构建一个基准模型,将原始数据拟合到模型中。
- 通过对每个特征进行随机置换,对特征进行重要性评估。随机置换会破坏特征与目标之间的关系,从而产生一个“空”或“虚假”的特征重要性分布。
- 计算原始特征与随机置换特征重要性之间的差异,以识别出真正对目标有贡献的特征。这些差异指示了模型在原始特征上的学习能力。
- 结合原始特征重要性和虚假特征重要性分布,生成一个重要性置信度分数。较高的置信度分数表示特征对目标的贡献更加显著。
- 基于特征的重要性置信度分数,筛选出最有价值的特征,用于进一步的建模和分析。
通过这种基于空重要性的方法,该方案可以在特征选择过程中综合考虑特征与目标之间的关系以及模型的学习能力,从而识别出对于解决问题最为关键的特征,提高了模型的预测能力和可解释性。
实现方案链接
Feature Selection with Null Importances | Kaggle
三、内存压缩
比赛按照上面的baseline会读取很大的数据内存,因此在此处放入一个降低内存的方法:
通过减少数字列的数据类型并将对象列转换为分类类型来优化 DataFrame 'train_df' 的内存使用量,从而减少内存使用量。
# 定义一个列表,其中包含需要进行内存优化的特征列(排除 'uuid'、'time' 和 'file' 列)
predictor_columns = [col for col in test_df.columns if col not in ['uuid','time','file']]
# 定义内存优化函数,用于减少数据帧的内存使用量
def reduce_mem_usage(df):
# 计算初始内存使用量
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
# 遍历预测特征列
for col in tqdm.tqdm(predictor_columns):
col_type = df[col].dtype
# 根据特征列的数据类型进行优化
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
# 根据数据范围选择适当的数据类型
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
# 计算优化后的内存使用量
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
# 调用内存优化函数,对训练数据帧进行内存优化
train_df = reduce_mem_usage(train_df)
四、验证方式
1. 交叉验证
交叉验证是一种评估机器学习模型性能的技术,用于估计模型在未见过的数据上的表现。其基本思想是将原始数据集分成若干个子集(折),然后重复多次,每次将其中一折作为验证集,其余折作为训练集。这样可以对模型进行多次训练和验证,从而更全面地评估模型的性能。
在交叉验证过程中,每次迭代的步骤如下:
- 将数据集分成k个子集,通常称为“折”(folds)。
- 在每次迭代中,选择其中一个折作为验证集,其余折作为训练集。
- 使用训练集训练模型,然后在验证集上进行预测,得到模型的性能指标。
- 重复以上步骤k次,每次选择不同的验证集。
- 计算k次迭代中性能指标的平均值,作为最终的模型性能评估。
常见的交叉验证方法包括 k 折交叉验证(k-Fold Cross Validation)、留一交叉验证(Leave-One-Out Cross Validation,LOOCV)以及随机分割交叉验证等。交叉验证可以帮助评估模型在不同数据子集上的泛化能力,降低过拟合的风险,提供对模型性能的更准确估计,以便更好地调整模型参数或选择最佳模型。

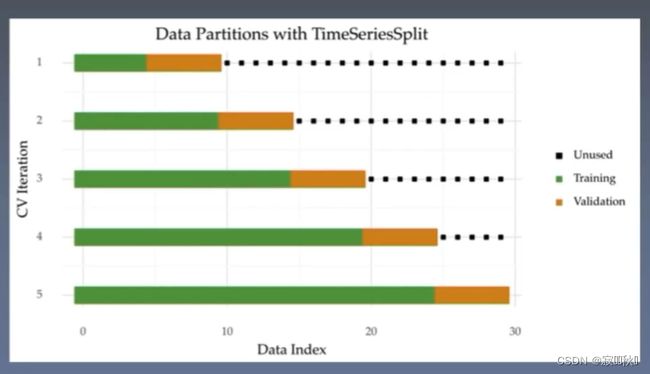
2. 时序验证
时序验证是一种特殊的交叉验证方法,专门针对时间序列数据的模型评估。在时间序列数据中,数据点的顺序对于模型的训练和验证至关重要,因为未来的数据点可能受过去数据点的影响。时序验证方法能够在保留时间顺序的前提下,对时间序列数据进行模型评估,更好地模拟模型在实际应用中的性能。
时序验证的基本思想是将时间序列数据划分为训练集和测试集,其中测试集的时间窗口在训练集之后。这样可以模拟模型在未来数据上的预测能力。常见的时序验证方法包括滚动窗口验证(Rolling Window Validation)和时间分割验证(Time-based Split Validation)等。
在滚动窗口验证中,训练集的时间窗口逐步向前滑动,每次增加一个时间步长,以便在不同时间段对模型进行训练和验证。在时间分割验证中,将时间序列数据按照时间顺序划分为多个时间段,每个时间段作为一个验证集,其之前的数据作为训练集。


五、模型集成
1. 多模型加权融合
模型加权融合是一种集成学习方法,旨在通过将多个不同算法或同一算法的不同实例的预测结果进行加权组合,从而提高模型的预测性能和稳定性。在加权融合中,每个模型的权重根据其在训练集上的表现或其他评估指标而定,较优的模型获得更高的权重。这种方法能够平衡各个模型的优势,弥补单一模型的不足,从而在多个模型的共同作用下,产生更准确、鲁棒的预测结果。加权融合适用于提升预测效果、减小过拟合风险以及对多种算法进行有效组合的情境。
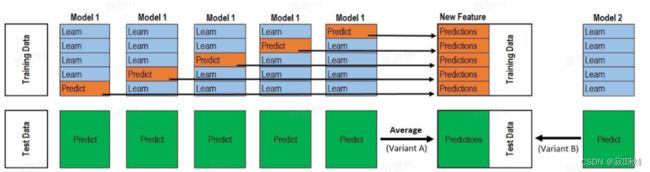
2. stacking模型融合
Stacking(又称为堆叠)是一种集成学习方法,用于将多个基本模型(也称为初级模型或基分类器)的预测结果作为输入,通过训练一个次级模型(也称为元模型或次级分类器)来生成最终的预测结果。Stacking 通过将不同模型的预测结果结合起来,可以有效地提高模型的预测性能和泛化能力。
from sklearn.model_selection import RepeatedKFold
def stack_model(oof_1, oof_2, oof_3, predictions_1, predictions_2, predictions_3, y):
# 合并训练集的预测结果
train_stack = pd.concat([oof_1, oof_2, oof_3], axis=1)
# 合并测试集的预测结果
test_stack = pd.concat([predictions_1, predictions_2, predictions_3], axis=1)
# 初始化一个全零数组来存储最终的交叉验证预测结果
oof = np.zeros((train_stack.shape[0],))
# 初始化一个全零数组来存储最终的测试集预测结果
predictions = np.zeros((test_stack.shape[0],))
# 存储每个交叉验证折数的模型分数
scores = []
# 定义交叉验证折数和重复次数,用于后续交叉验证的划分
folds = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2021)
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_stack, y)):
print("第{}折交叉验证".format(fold_+1))
# 获取当前折数的训练数据和标签
trn_data, trn_y = train_stack.loc[trn_idx], y[trn_idx]
# 获取当前折数的验证数据和标签
val_data, val_y = train_stack.loc[val_idx], y[val_idx]
# 初始化回归模型
clf = Ridge(random_state=2021)
# 在当前折数的训练数据上拟合模型
clf.fit(trn_data, trn_y)
# 对当前折数的验证数据进行预测
oof[val_idx] = clf.predict(val_data)
# 对测试集进行预测,并累加预测结果(最后会取平均值)
predictions += clf.predict(test_stack) / (5 * 2)
# 计算当前折数的验证集的ROC AUC得分
score_single = roc_auc_score(val_y, oof[val_idx])
# 将当前折数得分添加到scores列表中
scores.append(score_single)
print(f'{fold_+1}/5', score_single)
# 输出交叉验证得分的平均值
print('mena:', np.mean(scores))
# 返回交叉验证预测结果和测试集预测结果
return oof, predictions科大讯飞AI量化模型预测挑战赛_Baseline - 飞桨AI Studio (baidu.com)