SparkCore-RDD编程
SparkCore-RDD编程操作
0. 大纲
- Spark程序的执行过程
- RDD的操作
- RDD的转换操作
- 共享变量
- 高级排序
1. Spark程序执行过程
1.1. WordCount案例程序的执行过程
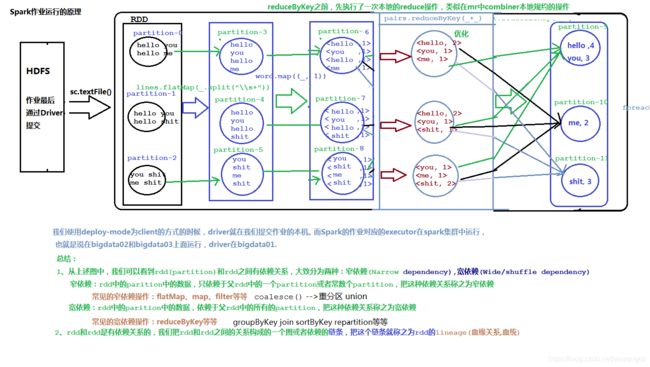
1.2. Spark程序执行流程
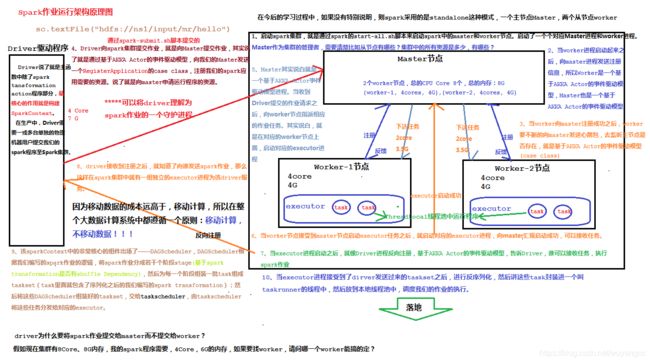
2. RDD的操作
At a high level, every Spark application consists of a driver program that runs the user’s
mainfunction and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures. A second abstraction in Spark is shared variables that can be used in parallel operations. By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task. Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only “added” to, such as counters and sums.
2.1. RDD的初始化
RDD的初始化,原生api提供的2中创建方式,一种就是读取文件textFile,还有一种就是加载一个scala集合parallelize。当然,也可以通过transformation算子来创建的RDD。
2.2. RDD的操作
需要知道RDD操作算子的分类,基本上分为两类:transformation和action,当然更加细致的分,可以分为输入算子,转换算子,缓存算子,行动算子。

输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
运行:在Spark数据输入形成RDD后便可以通过变换算子,如filter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。 如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
2.2.1. transformation转换算子
-
map
-
说明
rdd.map(func):RDD,对rdd集合中的每一个元素,都作用一次该func函数,之后返回值为生成元素构成的一个新的RDD。
-
编码
对rdd中的每一个元素×7
object _01RDDOps { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(s"${_01RDDOps.getClass.getSimpleName}") .setMaster("local[*]") val sc = new SparkContext(conf) //map 原集合*7 val list = 1 to 7 //构建一个rdd val listRDD:RDD[Int] = sc.parallelize(list) // listRDD.map((num:Int) => num * 7) // listRDD.map(num => num * 7) val ret = listRDD.map(_ * 7) ret.foreach(println) sc.stop() } }
-
-
flatMap
-
说明
rdd.flatMap(func):RDD ==>rdd集合中的每一个元素,都要作用func函数,返回0到多个新的元素,这些新的元素共同构成一个新的RDD。所以和上述map算子进行总结:
map操作是一个one-2-one的操作
flatMap操作是一个one-2-many的操作
-
编码
案例:将每行字符串,拆分成一个个的单词
def flatMapOps(sc:SparkContext): Unit = { val list = List( "jia jing kan kan kan", "gao di di di di", "zhan yuan qi qi" ) val listRDD = sc.parallelize(list) listRDD.flatMap(line => line.split("\\s+")) .foreach(println) }
-
-
filter
-
说明
rdd.filter(func):RDD ==> 对rdd中的每一个元素操作func函数,该函数的返回值为Boolean类型,保留返回值为true的元素,共同构成一个新的RDD,过滤掉哪些返回值为false的元素。
-
编程
案例:保留集合中的偶数
def filterMapOps(sc:SparkContext): Unit = { val list = 1 to 10 sc.parallelize(list) .filter(_ % 2 == 0) .foreach(println) }
-
-
sample
-
说明
rdd.sample(withReplacement:Boolean, fraction:Double [, seed:Long]):RDD ===> 抽样,需要注意的是spark的sample抽样不是一个精确的抽样。一个非常重要的作用,就是来看rdd中数据的分布情况,根据数据分布的情况,进行各种调优与优化。—>数据倾斜。
首先得要知道这三个参数是啥意思
withReplacement:抽样的方式,true有放回抽样, false为无返回抽样
fraction: 抽样比例,取值范围就是0~1
seed: 抽样的随机数种子,有默认值,通常也不需要传值
-
编程
案例:从10w个数中抽取千分之一进行样本评估
def sampleMapOps(sc:SparkContext): Unit = { val listRDD = sc.parallelize(1 to 100000) var sampledRDD = listRDD.sample(true, 0.001) println("样本空间的元素个数:" + sampledRDD.count()) sampledRDD = listRDD.sample(false, 0.001) println("样本空间的元素个数:" + sampledRDD.count()) }
-
-
union
-
说明
rdd1.union(rdd2),联合rdd1和rdd2中的数据,形成一个新的rdd,其作用相当于sql中的union all。
-
编程
案例:合并两个rdd中的数据,生成一个新的rdd,做后续统一的处理
def unionMapOps(sc:SparkContext): Unit = { val listRDD1 = sc.parallelize(List(1, 3, 5, 7, 9)) val listRDD2 = sc.parallelize(List(2, 4, 5, 8, 10)) val unionedRDD:RDD[Int] = listRDD1.union(listRDD2) unionedRDD.foreach(println) }
-
-
join
-
说明
join就是sql中的inner join,join的效果工作7种。
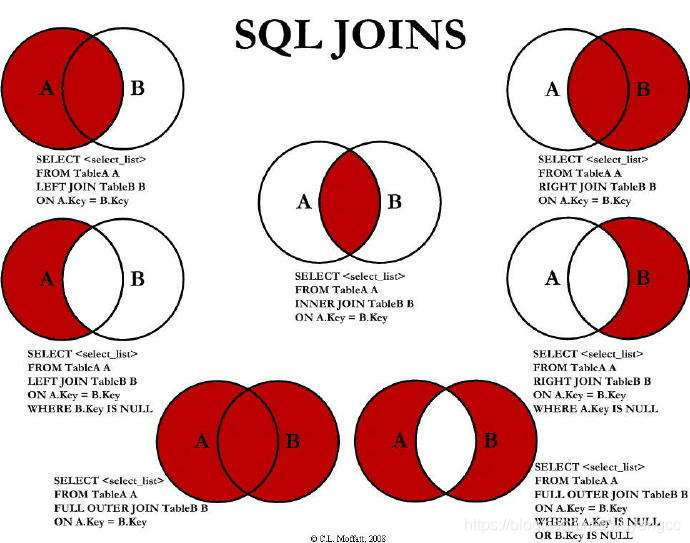
从具体的写法上面有如下几种 - 交叉连接 A a accross join B b;这种操作方式会产生笛卡尔积,在工作中一定要避免。 - 内连接 A a [inner] join B b [where|on a.id = b.id]; 有时候也写成:A a, B b(自连接) 是一种等值连接。所谓等值连接,就是获取A和B的交集。 - 外连接 - 左外连接 以左表为主体,查找右表中能够关联上的数据,如果管理不上,显示null。 A a left outer join B b on a.id = b.id。 - 右外连接 是以右表为主体,查找左表中能够关联上的数据,如果关联不上,显示null。 A a right outer join B b on a.id = b.id。 - 全连接 就是左外连接+右外连接 A a full outer join B b on a.id = b.id。 - 半连接 一般在工作很少用 sparkcore中支持的连接有:笛卡尔积、内连接join,外连接(左、右、全) - spark连接 要想两个RDD进行连接,那么这两个rdd的数据格式,必须是k-v键值对的,其中的k就是关联的条件,也就是sql中的on连接条件。 假设,RDD1的类型[K, V], RDD2的类型[K, W] - 内连接 val joinedRDD:RDD[(K, (V, W))] = rdd1.join(rdd2) - 左外连接 val leftJoinedRDD:RDD[(K, (V, Option[W]))] = rdd1.leftOuterJoin(rdd2) - 右外连接 val rightJoinedRDD:RDD[(K, (Option[V], W))] = rdd1.rightOuterJoin(rdd2) - 全连接 val fullJoinedRDD:RDD[(K, (Option[V], Option[W]))] = rdd1.fullOuterJoin(rdd2)-
编程
案例:关联学生信息
def joinedMapOps(sc:SparkContext): Unit = { //stu表:id,name,gender,age //score表:stuid,course, score val stuList = List( "1 严文青 女 18", "2 王大伟 男 55", "3 贾静凯 男 33", "4 old李 ladyBoy 31" ) val scoreList = List( "1 语文 59", "3 数学 0", "2 英语 60", "5 体育 99" ) val stuListRDD = sc.parallelize(stuList) val sid2StuInfoRDD:RDD[(Int, String)] = stuListRDD.map(line => { val sid = line.substring(0, line.indexOf(" ")).toInt val info = line.substring(line.indexOf(" ") + 1) (sid, info) }) val scoreListRDD = sc.parallelize(scoreList) val sid2ScoreInfoRDD:RDD[(Int, String)] = scoreListRDD.map(line => { val sid = line.substring(0, line.indexOf(" ")).toInt val scoreInfo = line.substring(line.indexOf(" ") + 1) (sid, scoreInfo) }) //查询有成绩的学生信息 --> join, k-v println("---------------------joined----------------------------") val stuScoreInfoRDD:RDD[(Int, (String, String))] = sid2StuInfoRDD.join(sid2ScoreInfoRDD) // stuScoreInfoRDD.foreach(kv => { // println(s"sid:${kv._1}, stu's info: ${kv._2._1}, stu's score: ${kv._2._2}") // }) stuScoreInfoRDD.foreach{case (sid, (stuInfo, scoreInfo)) => { println(s"sid:${sid}, stu's info: ${stuInfo}, stu's score: ${scoreInfo}") }} println("---------------------left----------------------------") //查询所有学生的信息 val stuInfo:RDD[(Int, (String, Option[String]))] = sid2StuInfoRDD.leftOuterJoin(sid2ScoreInfoRDD) stuInfo.foreach{case (sid, (stuInfo, scoreOption)) => { println(s"sid:${sid}, stu's info: ${stuInfo}, stu's score: ${scoreOption.getOrElse(null)}") }} println("---------------------full----------------------------") //查询学生,及其有成绩的学生信息 val stuScoreInfo:RDD[(Int, (Option[String], Option[String]))] = sid2StuInfoRDD.fullOuterJoin(sid2ScoreInfoRDD) stuScoreInfo.foreach{case (sid, (stuOption, scoreOption)) => { println(s"sid:${sid}, stu's info: ${stuOption.getOrElse(null)}, stu's score: ${scoreOption.getOrElse(null)}") }} }
-
-
groupByKey
-
说明
原始rdd的类型时[(K, V)]
rdd.groupByKey(),按照key进行分组,那必然其结果就肯定[(K, Iterable[V])],是一个shuffle dependency宽依赖shuffle操作,但是这个groupByKey不建议在工作过程中使用,除非非要用,因为groupByKey没有本地预聚合,性能较差,一般我们能用下面的reduceByKey或者combineByKey或者aggregateByKey代替就尽量代替。
-
编程
案例:对不同班级的学生进行分组。
def groupByKeyOps(sc:SparkContext): Unit ={ //stu表:id, name, gender, age, class val stuList = List( "1,白普州,1,22,1904-bd-bj", "2,伍齐城,1,19,1904-bd-wh", "3,曹佳,0,27,1904-bd-sz", "4,姚远,1,27,1904-bd-bj", "5,匿名大哥,2,17,1904-bd-wh", "6,欧阳龙生,0,28,1904-bd-sz" ) val stuRDD = sc.parallelize(stuList) val class2InfoRDD:RDD[(String, String)] = stuRDD.map(line => { val dotIndex = line.lastIndexOf(",") val className = line.substring(dotIndex + 1) val info = line.substring(0, dotIndex) (className, info) }) val gbkRDD:RDD[(String, Iterable[String])] = class2InfoRDD.groupByKey() gbkRDD.foreach(println) }
-
-
reduceByKey
rdd的类型为[(K, V)]
-
说明
rdd.reduceByKey(func:(V, V) => V):RDD[(K, V)] ====>在scala集合中学习过一个reduce(func:(W, W) => W)操作,是一个聚合操作,这里的reduceByKey按照就理解为在groupByKey(按照key进行分组[(K, Iterable[V])])的基础上,对每一个key对应的Iterable[V]执行reduce操作。
同时reduceByKey操作会有一个本地预聚合的操作,所以是一个shuffle dependency宽依赖shuffle操作。
-
编程
经典案例:wordcount
略
-
-
sortByKey
按照key进行排序
略
-
combineByKey
通过查看reduceByKey和groupByKey的实现,发现其二者底层都是基于一个combineByKeyWithClassTag的底层算子来实现的,包括下面的aggregateByKey也是使用该算子实现。该算子又和combineByKey有啥关系呢?
Simplified version of combineByKeyWithClassTag that hash-partitions the resulting RDD using the* existing partitioner/parallelism level. This method is here for backward compatibility. It* does not provide combiner classtag information to the shuffle.通过api学习,我们了解到combineByKey是combineByKeyWithClassTag的简写的版本。
-
说明
这是spark最底层的聚合算子之一,按照key进行各种各样的聚合操作,spark提供的很多高阶算子,都是基于该算子实现的。
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)] = { 。。。。。。 }上述源码便是combineByKey的定义,是将一个类型为[(K, V)]的RDD聚合转化为[(K, C)]的类型,也就是按照K来进行聚合。这里的V是聚合前的类型,C聚合之后的类型。
如何理解聚合函数?切入点就是如何理解分布式计算?总—>分—>总
createCombiner: V => C, 相同的Key在分区中会调用一次该函数,用于创建聚合之后的类型,为了和后续Key相同的数据进行聚合。使用分区中的一条记录进行初始化。
mergeValue: (C, V) => C, 在相同分区中基于上述createCombiner基础之上的局部聚合
mergeCombiners: (C, C) => C) 将每个分区中相同key聚合的结果在分区间进行全局聚合
-

所以combineByKey就是分布式计算。
2. 编程
- 模拟groupByKey
```scala
def cbk2GbkOps(sc:SparkContext): Unit ={
val stuList = List(
"白普州,1904-bd-bj",
"伍齐城,1904-bd-bj",
"曹佳,1904-bd-sz",
"刘文浪,1904-bd-wh",
"姚远,1904-bd-bj",
"匿名大哥,1904-bd-sz",
"欧阳龙生,1904-bd-sz"
)
val stuRDD = sc.parallelize(stuList)
val class2InfoRDD:RDD[(String, String)] = stuRDD.map(line => {
val dotIndex = line.lastIndexOf(",")
val className = line.substring(dotIndex + 1)
(className, line)
})
println("=================groupBykey=================")
val gbkRDD:RDD[(String, Iterable[String])] = class2InfoRDD.groupByKey()
gbkRDD.foreach(println)
println("=================cbk2Gbk================")
val cbk2gbkRDD:RDD[(String, ArrayBuffer[String])] = class2InfoRDD.combineByKey(createCombiner, mergeValue, mergeCombiners)
cbk2gbkRDD.foreach(println)
}
/*
初始化操作
相同key在同一个分区中只会调用一次该函数,用于初始化,并且将第一个元素用于初始化
*/
def createCombiner(stu:String):ArrayBuffer[String] = {
println("============createCombiner<" + stu + ">====================>>>>")
val ab = ArrayBuffer[String]()
ab.append(stu)
ab
}
/**
* 分区内的局部聚合
*/
def mergeValue(ab:ArrayBuffer[String], stu:String):ArrayBuffer[String] = {
println("》》》>>========mergeValue:局部聚合结果<" + ab + ">,被聚合的值:" + stu + "===========>>>>")
ab.append(stu)
ab
}
/*
全局聚合,各个分区内聚合的结果进行二次全局聚合
第一个参数ab就是全局聚合的临时结果
第二个参数ab2就是某一个分区聚合的结果
*/
def mergeCombiners(ab:ArrayBuffer[String], ab2:ArrayBuffer[String]):ArrayBuffer[String] = {
println("|-|-|<>|-|>>========mergeCombiners:全局聚合临时结果<" + ab + ">,局部聚合的值:" + ab2 + "===========>>>>")
ab.++:(ab2)
}
```
- 模拟reduceByKey
```scala
def cbk2rbkOps(sc:SparkContext): Unit = {
val lines = sc.textFile("file:/E:/data/hello.txt")
val pairs = lines.flatMap(_.split("\\s+")).map((_, 1))
println("==========reduceByKey============")
//reduceByKey
pairs.reduceByKey(_+_).foreach(println)
println("==========combineByKey============")
val cbk2rbk = pairs.combineByKey[Int]((num:Int) => num, (sum:Int, num:Int) => sum + num, (sum1:Int, sum2:Int) => sum1 + sum2)
cbk2rbk.foreach(println)
}
```
-
aggregateByKey
-
说明
aggregateByKey和combineByKey都是一个相对底层的聚合算子,可以完成系统没有提供的其它操作,相当于自定义算子。
aggregateByKey底层还是使用combineByKeyWithClassTag来实现,所以本质上二者没啥区别,区别就在于使用时的选择而已。
-
编程
def abk2rbkOps(sc:SparkContext): Unit = { val lines = sc.textFile("file:/E:/data/hello.txt") val pairs = lines.flatMap(_.split("\\s+")).map((_, 1)) println("==========reduceByKey============") //reduceByKey pairs.reduceByKey(_+_).foreach(println) println("==========combineByKey============") val abk:RDD[(String, Int)] = pairs.aggregateByKey(0)(_+_, _+_) abk.foreach(println) } def abk2GbkOps(sc:SparkContext): Unit ={ val stuList = List( "白普州,bj", "伍齐城,bj", "曹佳,sz", "刘文浪,wh", "姚远,bj", "匿名大哥,sz", "欧阳龙生,sz" ) val stuRDD = sc.parallelize(stuList) val class2InfoRDD:RDD[(String, String)] = stuRDD.map(line => { val dotIndex = line.lastIndexOf(",") val className = line.substring(dotIndex + 1) (className, line) }) // class2InfoRDD.saveAsTextFile("file:/E:/data/out/heihei") println("=================groupBykey=================") val gbkRDD:RDD[(String, Iterable[String])] = class2InfoRDD.groupByKey() gbkRDD.foreach(println) println("=================abk2Gbk================") val abkRDD:RDD[(String, ArrayBuffer[String])] = class2InfoRDD.aggregateByKey(ArrayBuffer[String]())( seqOp, combOp ) abkRDD.foreach(println) } def seqOp(ab:ArrayBuffer[String], info:String):ArrayBuffer[String] = { ab.append(info) ab } def combOp(ab:ArrayBuffer[String], ab2:ArrayBuffer[String]):ArrayBuffer[String] = { ab.++:(ab2) } -
总结:
通过上例我们可以看出,如果是对相同类型的数据进行聚合统计,倾向于使用aggregateByKey更为简单,但是如果聚合前后数据类型不一致,建议使用combineByKey;同时如果初始化操作较为复杂,也建议使用combineByKey。
-
2.2.2. action行动算子
所有的这些算子都是在rdd,rdd上的分区partition上面执行的,不是在driver本地执行。
-
foreach
略
-
count
统计该rdd中元素的个数
val count = abk.count() println("abk rdd的count个数为:" + count)返回值为Long类型
-
take(n)
返回该rdd中的前N个元素
val arr:Array[(String, Int)] = abk.take(2) arr.foreach(println)如果该rdd的数据是有序的,那么take(n)就是TopN。
-
first
take(n)中比较特殊的一个take(1)(0)
val ret:(String, Int) = abk.first() println(ret) -
collect
字面意思就是收集,拉取的意思,该算子的含义就是将分布在集群中的各个partition中的数据拉回到driver中,进行统一的处理;但是这个算子有很大的风险存在,第一,driver内存压力很大,第二数据在网络中大规模的传输,效率很低;所以一般不建议使用,如果非要用,请先执行filter。
val arr = abk.filter(_._2 > 2).collect() arr.foreach(println) -
reduce
一定记清楚,reduce是一个action操作,reduceByKey是一个transformation。reduce对一个rdd执行聚合操作,并返回结果,结果是一个值。
//统计有多少个单词 val newRet = abk.reduce{case ((k1, v1), (k2, v2)) => (k1 + "_" + k2, v1 + v2)} println(newRet)需要注意一点的是,聚合前后的数据类型保持一致。
-
countByKey
统计key出现的次数
val countByKey = pairs.countByKey() for ((k, v) <- countByKey) { println(k + "-->" + v) } //使用groupByKey求解wordcount val rr = pairs.groupByKey().map{case (key, iters) => (key, iters.size)} rr.foreach(println) -
saveAsTextFile
rr.saveAsTextFile("file:/E:/data/out/1904-bd/out1")本质上是saveAsHadoopFile[TextOutputFormat[NullWritable, Text]]
-
saveAsObjectFile和saveAsSequenceFile
saveAsObjectFile本质上是saveAsSequenceFile
def saveAsObjectFile(path: String): Unit = withScope { this.mapPartitions(iter => iter.grouped(10).map(_.toArray)) .map(x => (NullWritable.get(), new BytesWritable(Utils.serialize(x)))) .saveAsSequenceFile(path) } -
saveAsHadoopFile和saveAsNewAPIHadoopFile
这二者的主要区别就是OutputFormat的区别,
接口org.apache.hadoop.mapred.OutputFormat
抽象类org.apache.hadoop.mapreduce.OutputFormat
所以saveAshadoopFile使用的是接口OutputFormat,saveAsNewAPIHadoopFile使用的抽象类OutputFormat,建议大家使用后者。
val path = "file:/E:/data/out/1904-bd/out3" rr.saveAsNewAPIHadoopFile(path, classOf[Text], classOf[IntWritable], classOf[TextOutputFormat[Text, IntWritable]] )
2.2.3. 持久化操作
2.2.3.1. 什么是持久化,为什么要持久化
One of the most important capabilities in Spark is persisting (or caching) a dataset in memory across operations. When you persist an RDD, each node stores any partitions of it that it computes in memory and reuses them in other actions on that dataset (or datasets derived from it). This allows future actions to be much faster (often by more than 10x). Caching is a key tool for iterative algorithms and fast interactive use.
2.2.3.2. 如何进行持久化
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
持久化的方法就是rdd.persist()或者rdd.cache()
2.2.3.3. 持久化策略
In addition, each persisted RDD can be stored using a different storage level, allowing you, for example, to persist the dataset on disk, persist it in memory but as serialized Java objects (to save space), replicate it across nodes. These levels are set by passing a StorageLevel object (Scala, Java, Python) to persist(). The cache() method is a shorthand for using the default storage level, which is StorageLevel.MEMORY_ONLY (store deserialized objects in memory).
可以通过persist(StoreageLevle的对象)来指定持久化策略,eg:StorageLevel.MEMORY_ONLY。
| 持久化策略 | 含义 |
|---|---|
| MEMORY_ONLY(默认) | rdd中的数据,以未经序列化的java对象格式,存储在内存中。如果内存不足,剩余的部分不持久化,使用的时候,没有持久化的那一部分数据重新加载。这种效率是最高,但是是对内存要求最高的。 |
| MEMORY_ONLY_SER | 就比MEMORY_ONLY多了一个SER序列化,保存在内存中的数据是经过序列化之后的字节数组,同时每一个partition此时就是一个比较大的字节数组。 |
| MEMORY_AND_DISK | 和MEMORY_ONLY相比就多了一个,内存存不下的数据存储在磁盘中。 |
| MEMEORY_AND_DISK_SER | 比MEMORY_AND_DISK多了个序列化。 |
| DISK_ONLY | 就是MEMORY_ONLY对应,都保存在磁盘,效率太差,一般不用。 |
| xxx_2 | 就是上述多个策略后面加了一个_2,比如MEMORY_ONLY_2,MEMORY_AND_DISK_SER_2等等,就多了一个replicate而已,备份,所以性能会下降,但是容错或者高可用加强了。所以需要在二者直接做权衡。如果说要求数据具备高可用,同时容错的时间花费比从新计算花费时间少,此时便可以使用,否则一般不用。 |
| HEAP_OFF(experimental) | 使用非Spark的内存,也即堆外内存,比如Tachyon,HBase、Redis等等内存来补充spark数据的缓存。 |
2.2.3.4. 如何选择一款合适的持久化策略
第一就选择默认MEMORY_ONLY,因为性能最高嘛,但是对空间要求最高;如果空间满足不了,退而求其次,选择MEMORY_ONLY_SER,此时性能还是蛮高的,相比较于MEMORY_ONLY的主要性能开销就是序列化和反序列化;如果内存满足不了,直接跨越MEMORY_AND_DISK,选择MEMEORY_AND_DISK_SER,因为到这一步,说明数据蛮大的,要想提高性能,关键就是基于内存的计算,所以应该尽可能的在内存中存储对象;DISK_ONLY不用,xx_2的使用如果说要求数据具备高可用,同时容错的时间花费比从新计算花费时间少,此时便可以使用,否则一般不用。
2.2.3.5. 持久化和非持久化性能比较
object _05SparkPersistOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf() .setAppName(s"${_05SparkPersistOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
//读取外部数据
var start = System.currentTimeMillis()
val lines = sc.textFile("file:///E:/data/spark/core/sequences.txt")
var count = lines.count()
println("没有持久化:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.persist(StorageLevel.MEMORY_AND_DISK) //lines.cache()
start = System.currentTimeMillis()
count = lines.count()
println("持久化之后:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.unpersist()//卸载持久化数据
sc.stop()
}
}
没有持久化:#######lines’ count: 1000000, cost time: 5257ms
持久化之后:#######lines’ count: 1000000, cost time: 1408ms
2.3. 共享变量
2.3.0. 概述
Normally, when a function passed to a Spark operation (such as
maporreduce) is executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Supporting general, read-write shared variables across tasks would be inefficient(低效). However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
2.3.1. broadcast广播变量
- 说明
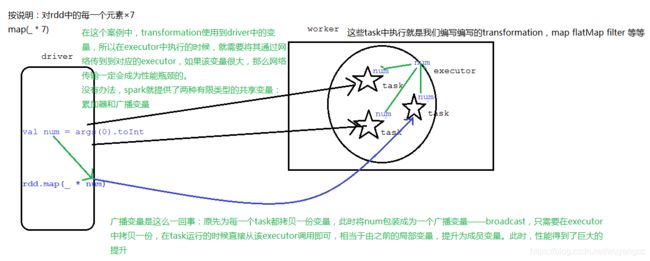
如何使用广播变量呢?
对普通遍历进行包装即可,
val num:Any = xxx
val numBC:Broadcast[Any] = sc.broadcast(num)
调用
val n = numBC.value
需要注意一点的是,显然该num需要进行序列化。
-
编程
object _06BroadcastOps { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(s"${_06BroadcastOps.getClass.getSimpleName}") .setMaster("local[*]") val sc = new SparkContext(conf) val genderMap = Map( "0" -> "妹砸儿", "1" -> "大兄弟" ) val stuRDD = sc.parallelize(List( Student("01", "宋敏健", "0", 18), Student("02", "严文青", "1", 19), Student("03", "王大伟", "1", 18), Student("04", "闫来宾", "1", 22) )) stuRDD.map(stu => { val gender = stu.gender Student(stu.id, stu.name, genderMap.getOrElse(gender, "ladyBoy"), stu.age) }).foreach(println) println("=============使用广播变量的做法==============") val genderBC:Broadcast[Map[String, String]] = sc.broadcast(genderMap) stuRDD.map(stu => { val gender = genderBC.value.getOrElse(stu.gender, "ladyBody") Student(stu.id, stu.name, gender, stu.age) }).foreach(println) sc.stop() } } case class Student(id:String, name:String, gender:String, age:Int)
2.3.2. accumulator累加器
-
说明
accumulator累加器的概念和mr中出现的counter计数器的概念有异曲同工之妙,对某些具备某些特征的数据进行累加。累加器的一个好处是,不需要修改程序的业务逻辑来完成数据累加,同时也不需要额外的触发一个action job来完成累加,反之必须要添加新的业务逻辑,必须要触发一个新的action job来完成,显然这个accumulator的操作性能更佳!
累加的使用:
构建一个累加器
val accu = sc.longAccumuator()
累加的操作
accu.add(参数)
获取累加器的结果,累加器的获取,必须需要action的触发
val ret = accu.value
-
编程
-
使用非累加器完成某些特征数据的累加求解
val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/work/1904-bd/workspace/spark-parent-1904/data/accu.txt") val words = lines.flatMap(_.split("\\s+")) //统计每个单词出现的次数 val rbk = words.map((_, 1)).reduceByKey(_+_) rbk.foreach(println) println("=============额外的统计=================") //统计其中的is出现的次数 rbk.filter{case (word, count) => word == "is"}.foreach(println) Thread.sleep(10000000) sc.stop()
-
使用累加器完成上述案例
val conf = new SparkConf() .setAppName(s"${_07AccumulatorOps.getClass.getSimpleName}") .setMaster("local[*]") val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/work/1904-bd/workspace/spark-parent-1904/data/accu.txt") val words = lines.flatMap(_.split("\\s+")) //统计每个单词出现的次数 val accumulator = sc.longAccumulator val rbk = words.map(word => { if(word == "is") accumulator.add(1) (word, 1) }).reduceByKey(_+_) rbk.foreach(println) println("================使用累加器===================") println("is: " + accumulator.value) Thread.sleep(10000000) sc.stop()
-
![]()
- 总结
使用累加器也能够完成上述的操作,而且只使用了一个action操作。
3. 注意
- 累加器的调用,也就是accumulator.value必须要在action之后被调用,也就是说累加器必须在action触发之后。
- 多次使用同一个累加器,应该尽量做到用完即重置
accumulator.reset
- 尽量给累加器指定name,方便我们在web-ui上面进行查看

4. 自定义累加器
在上述3的案例基础之上,还用统计of,甚至统计a这些额外的单词,怎么做?此时就应该使用自定义累加器。
MyAccumulator
```scala
/*
自定义累加器
IN 指的是accmulator.add(sth.)中sth的数据类型
OUT 指的是accmulator.value返回值的数据类型
*/
class MyAccumulator extends AccumulatorV2[String, Map[String, Long]] {
private var map = mutable.Map[String, Long]()
/**
* 当前累加器是否有初始化值
* 如果为一个long的值,0就是初始化值,如果为list,Nil就是初始化值,是map,Map()就是初始化值
*/
override def isZero: Boolean = true
override def copy(): AccumulatorV2[String, Map[String, Long]] = {
val accu = new MyAccumulator
accu.map = this.map
accu
}
override def reset(): Unit = map.clear()
//分区内的数据累加 is: 5, of:4
override def add(word: String): Unit = {
if(map.contains(word)) {
val newCount = map(word) + 1
map.put(word, newCount)
} else {
map.put(word, 1)
}
// map.put(word, map.getOrElse(word, 0) + 1)
}
//多个分区间的数据累加
override def merge(other: AccumulatorV2[String, Map[String, Long]]): Unit = {
other.value.foreach{case (word, count) => {
if(map.contains(word)) {
val newCount = map(word) + count
map.put(word, newCount)
} else {
map.put(word, count)
}
// map.put(word, map.getOrElse(word, 0) + count)
}}
}
override def value: Map[String, Long] = map.toMap
}
```
注册使用
```scala
object _08AccumulatorOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_08AccumulatorOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/work/1904-bd/workspace/spark-parent-1904/data/accu.txt")
val words = lines.flatMap(_.split("\\s+"))
//注册
val myAccu = new MyAccumulator()
sc.register(myAccu, "myAccu")
//统计每个单词出现的次数
val pairs = words.map(word => {
if(word == "is" || word == "of" || word == "a")
myAccu.add(word)
(word, 1)
})
val rbk = pairs.reduceByKey(_+_)
rbk.foreach(println)
println("=============累加器==========")
myAccu.value.foreach(println)
Thread.sleep(10000000)
sc.stop()
}
}
```
3. 高级排序
3.1. 普通的排序
3.1.1. sortByKey
object _01SortByKeyOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_01SortByKeyOps.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
//sortByKey 数据类型为k-v,且是按照key进行排序
val stuRDD:RDD[Student] = sc.parallelize(List(
Student(1, "吴轩宇", 19, 168),
Student(2, "彭国宏", 18, 175),
Student(3, "随国强", 18, 176),
Student(4, "闫 磊", 20, 180),
Student(5, "王静轶", 18, 168.5)
))
//按照学生身高进行降序排序
val height2Stu = stuRDD.map(stu => (stu.height, stu))
//注意:sortByKey是局部排序,不是全局排序,如果要进行全局排序,
// 必须将所有的数据都拉取到一台机器上面才可以
val sorted = height2Stu.sortByKey(ascending = false, numPartitions = 1)
sorted.foreach{case (height, stu) => println(stu)}
sc.stop()
}
}
case class Student(id:Int, name:String, age:Int, height:Double)
3.1.2. sortBy
-
说明
这个sortByKey其实使用sortByKey来实现,但是比sortByKey更加灵活,因为sortByKey只能应用在k-v数据格式上,而这个sortByKey可以应在非k-v键值对的数据格式上面。
-
编程
val sortedBy = stuRDD.sortBy(stu => stu.height, ascending = true, numPartitions = 1 )(new Ordering[Double](){ override def compare(x: Double, y: Double) = y.compareTo(x) }, ClassTag.Double.asInstanceOf[ClassTag[Double]]) sortedBy.foreach(println) -
总结
sortedBy的操作,除了正常的升序,分区个数以外,还需需要传递一个将原始数据类型,提取其中用于排序的字段;并且提供用于比较的方式,以及在运行时的数据类型ClassTag标记型trait。
3.1.3. takeOrdered
-
说明
takeOrdered也是对rdd进行排序,但是和上述的sortByKey和sortBy相比较,takeOrdered是一个action操作,返回值为一个集合,而前两者为transformation,返回值为rdd。如果我们想在driver中获取排序之后的结果,那么建议使用takeOrdered,因为该操作边排序边返回。
其实是take和sortBy的一个结合体。
takeOrdered(n),获取排序之后的n条记录
-
编程
//先按照身高降序排序,身高相对按照年龄升序排 ---> 二次排序 stuRDD.takeOrdered(3)(new Ordering[Student](){ override def compare(x: Student, y: Student) = { var ret = y.height.compareTo(x.height) if(ret == 0) { ret = x.age.compareTo(y.age) } ret } }).foreach(println)
3.2. TopN
到这里,topN就是3.1之后执行action操作take(N),或者3.2直接takeOrderd(N),建议使用后者,效率高于前者。
3.3. 二次排序
所谓二次排序,指的是排序字段不唯一,有多个,共同排序,仍然使用上面的数据,对学生的身高和年龄一次排序。
object _02SecondSortOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_02SecondSortOps.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
//sortByKey 数据类型为k-v,且是按照key进行排序
val personRDD:RDD[Person] = sc.parallelize(List(
Person(1, "吴轩宇", 19, 168),
Person(2, "彭国宏", 18, 175),
Person(3, "随国强", 18, 176),
Person(4, "闫 磊", 20, 180),
Person(5, "王静轶", 18, 168)
))
personRDD.map(stu => (stu, null)).sortByKey(true, 1).foreach(p => println(p._1))
sc.stop()
}
}
case class Person(id:Int, name:String, age:Int, height:Double) extends Ordered[Person] {
//对学生的身高和年龄依次排序
override def compare(that: Person) = {
var ret = this.height.compareTo(that.height)
if(ret == 0) {
ret = this.age.compareTo(that.age)
}
ret
}
}
3.4. 分组TopN
在分组的情况之下,获取每个组内的TopN数据。
-
需求
基础数据:
chinese ls 91
english ww 56
chinese zs 90
chinese zl 76
english zq 88字段分别为科目,姓名,成绩。要求:求出每个科目成绩排名前3的学生信息。
-
编码
object _03GroupSortTopN { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(s"${_03GroupSortTopN.getClass.getSimpleName}") .setMaster("local[2]") val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/data/spark/topn.txt") //按照科目进行排序 val course2Info:RDD[(String, String)] = lines.map(line => { val spaceIndex = line.indexOf(" ") val course = line.substring(0, spaceIndex) val info = line.substring(spaceIndex + 1) (course, info) }) //按照科目排序,指的是科目内排序,不是科目间的排序,所以需要把每个科目的信息汇总 val course2Infos:RDD[(String, Iterable[String])] = course2Info.groupByKey()//按照key进行分组 //分组内的排序 val sorted:RDD[(String, mutable.TreeSet[String])] = course2Infos.map{case (course, infos) => { val topN = mutable.TreeSet[String]()(new Ordering[String](){ override def compare(x: String, y: String) = { val xScore = x.split("\\s+")(1) val yScore = y.split("\\s+")(1) yScore.compareTo(xScore) } }) for(info <- infos) { topN.add(info) } (course, topN.take(3)) }} sorted.foreach(println) sc.stop() } }
3.6. 优化分组TopN
-
说明
上述在编码过程当中使用groupByKey,我们说着这个算子的性能很差,因为没有本地预聚合,所以应该在开发过程当中尽量避免使用,能用其它代替就代替。
-
编码
-
使用combineByKey模拟
object _04GroupSortByCombineByKeyTopN { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(s"${_04GroupSortByCombineByKeyTopN.getClass.getSimpleName}") .setMaster("local[2]") val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/data/spark/topn.txt") //按照科目进行排序 val course2Info:RDD[(String, String)] = lines.map(line => { val spaceIndex = line.indexOf(" ") val course = line.substring(0, spaceIndex) val info = line.substring(spaceIndex + 1) (course, info) }) //按照科目排序,指的是科目内排序,不是科目间的排序,所以需要把每个科目的信息汇总 val course2Infos= course2Info.combineByKey(createCombiner, mergeValue, mergeCombiners) //分组内的排序 val sorted:RDD[(String, mutable.TreeSet[String])] = course2Infos.map{case (course, infos) => { val topN = mutable.TreeSet[String]()(new Ordering[String](){ override def compare(x: String, y: String) = { val xScore = x.split("\\s+")(1) val yScore = y.split("\\s+")(1) yScore.compareTo(xScore) } }) for(info <- infos) { topN.add(info) } (course, topN.take(3)) }} sorted.foreach(println) sc.stop() } def createCombiner(info:String): ArrayBuffer[String] = { val ab = new ArrayBuffer[String]() ab.append(info) ab } def mergeValue(ab:ArrayBuffer[String], info:String): ArrayBuffer[String] = { ab.append(info) ab } def mergeCombiners(ab:ArrayBuffer[String], ab1: ArrayBuffer[String]): ArrayBuffer[String] = { ab.++:(ab1) } }此时这种写法和上面的groupByKey性能一模一样,没有任何的优化。
-
使用combineByKey的优化
object _05GroupSortByCombineByKeyTopN { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(s"${_05GroupSortByCombineByKeyTopN.getClass.getSimpleName}") .setMaster("local[2]") val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/data/spark/topn.txt") //按照科目进行排序 val course2Info:RDD[(String, String)] = lines.map(line => { val spaceIndex = line.indexOf(" ") val course = line.substring(0, spaceIndex) val info = line.substring(spaceIndex + 1) (course, info) }) //按照科目排序,指的是科目内排序,不是科目间的排序,所以需要把每个科目的信息汇总 val sorted= course2Info.combineByKey(createCombiner, mergeValue, mergeCombiners) sorted.foreach(println) sc.stop() } def createCombiner(info:String): mutable.TreeSet[String] = { val ts = new mutable.TreeSet[String]()(new Ordering[String](){ override def compare(x: String, y: String) = { val xScore = x.split("\\s+")(1) val yScore = y.split("\\s+")(1) yScore.compareTo(xScore) } }) ts.add(info) ts } def mergeValue(ab:mutable.TreeSet[String], info:String): mutable.TreeSet[String] = { ab.add(info) if(ab.size > 3) { ab.take(3) } else { ab } } def mergeCombiners(ab:mutable.TreeSet[String], ab1: mutable.TreeSet[String]): mutable.TreeSet[String] = { for (info <- ab1) { ab.add(info) } if(ab.size > 3) { ab.take(3) } else { ab } } }sorted.foreach(println) sc.stop() } def createCombiner(info:String): mutable.TreeSet[String] = { val ts = new mutable.TreeSet[String]()(new Ordering[String](){ override def compare(x: String, y: String) = { val xScore = x.split("\\s+")(1) val yScore = y.split("\\s+")(1) yScore.compareTo(xScore) } }) ts.add(info) ts } def mergeValue(ab:mutable.TreeSet[String], info:String): mutable.TreeSet[String] = { ab.add(info) if(ab.size > 3) { ab.take(3) } else { ab } } def mergeCombiners(ab:mutable.TreeSet[String], ab1: mutable.TreeSet[String]): mutable.TreeSet[String] = { for (info <- ab1) { ab.add(info) } if(ab.size > 3) { ab.take(3) } else { ab } }}
-