技术角度分析:中国谁能玩转大数据
【IT168技术】大数据好用,但谁会为它投资?在目前中国的经济环境下,大中型国企臃肿缓慢的业务流程对于大数据不是太过于感冒。可以说谁都不是十分清楚大数据究竟是怎么创造价值的,下面我们就来一起看看大数据技术背后的故事。
毫无疑问,世界上所有关注开发技术的人都意识到“大数据”对企业商务所蕴含的潜在价值,其目的都在于解决在企业发展过程中各种业务数据增长所带来的痛苦。
现实是,许多问题阻碍了大数据技术的发展和实际应用。
因为一种成功的技术,需要一些衡量的标准。现在我们可以通过几个基本要素来衡量一下大数据技术,这就是——流处理、并行性、摘要索引和可视化。
谁会用到大数据?
一年前,大数据技术的一些主要用户是大型Web企业,例如Facebook和雅虎,它们需要分析点击流数据。但是今天,“大数据技术已经超出了Web,是要是有大量数据需要处理的企业都有可能用到它。”例如银行、公用事业机构、情报部门等都在搭乘大数据这辆车。
实际上,一些大数据技术已经被一些拥有很前卫技术的企业在使用了,比如受社交媒体推动而需要创建相应Web服务的企业。它们对于大数据项目的贡献非常重要。
而在其他垂直行业中,有些企业正在意识到,它们基于信息服务的价值定位要比它们先前想象的要大得多,所以大数据技术很快就吸引了这些企业的注意。再加上硬件和软件成本的下降,这些企业发现它们已经处在了一场企业大转型机遇的完美风暴中。
大数据处理的应对三大挑战:大容量数据、多格式数据和速度
大容量数据(TB级、PB级甚至EB级):人们和机器制造的越来越多的业务数据对IT系统带来了更大的挑战,数据的存储和安全以及在未来访问和使用这些数据已成为难点。
多格式数据:海量数据包括了越来越多不同格式的数据,这些不同格式的数据也需要不同的处理方法。从简单的电子邮件、数据日志和信用卡记录,再到仪器收集到的科学研究数据、医疗数据、财务数据以及丰富的媒体数据(包括照片、音乐、视频等)。
速度:速度是指数据从端点移动到处理器和存储的速度。
大数据技术涵盖哪些内容?
①流处理
伴随着业务发展的步调,以及业务流程的复杂化,我们的注意力越来越集中在“数据流”而非“数据集”上面。
决策者感兴趣的是紧扣其组织机构的命脉,并获取实时的结果。他们需要的是能够处理随时发生的数据流的架构,当前的数据库技术并不适合数据流处理。
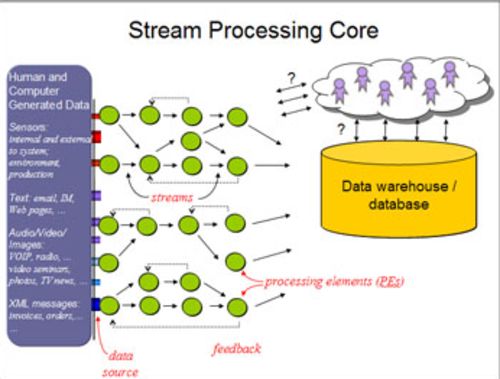
例如,计算一组数据的平均值,可以使用一个传统的脚本实现。但对于移动数据平均值的计算,不论是到达、增长还是一个又一个的单元,有更高效的算法。如果你 想构建数据仓库,并执行任意的数据分析、统计,开源的产品R或者类似于SAS的商业产品就可以实现。但是你想创建的是一个数据流统计集,对此逐步添加或移 除数据块,进行移动平均计算,而且数据库不存在或者尚不成熟。
数据流周边的生态系统有欠发达。换言之,如果你正在与一家供应商洽谈一个大数据项目,那么你必须知道数据流处理对你的项目而言是否重要,并且供应商是否有能力提供。
②并行化
大数据的定义有许多种,以下这种相对有用。“小数据”的情形类似于桌面环境,磁盘存储能力在1GB到10GB之间,“中数据”的数据量在100GB到1TB之间,“大数据”分布式的存储在多台机器上,包含1TB到多个PB的数据。
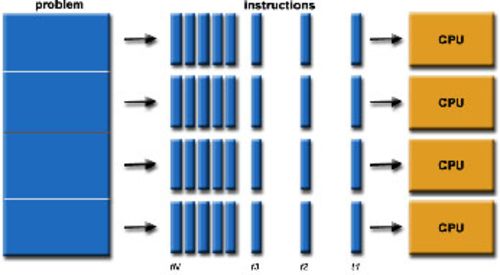
如果你在分布式数据环境中工作,并且想在很短的时间内处理数据,这就需要分布式处理。
并行处理在分布式数据中脱颖而出,Hadoop是一个分布式/并行处理领域广为人知的例子。Hadoop包含一个大型分布式的文件系统,支持分布式/并行查询。
③摘要索引
摘要索引是一个对数据创建预计算摘要,以加速查询运行的过程。摘要索引的问题是,你必须为要执行的查询做好计划,因此它有所限制。
数据增长飞速,对摘要索引的要求远不会停止,不论是长期考虑还是短期,供应商必须对摘要索引的制定有一个确定的策略。
④数据可视化
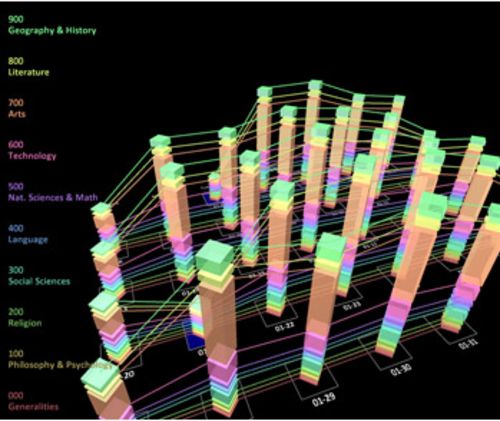
可视化工具有两大类。
探索性可视化描述工具可以帮助决策者和分析师挖掘不同数据之间的联系,这是一种可视化的洞察力。类似的工具有Tableau、TIBCO和QlikView,这是一类。
叙事可视化工具被设计成以独特的方式探索数据。例如,如果你想以可视化的方式在一个时间序列中按照地域查看一个企业的销售业绩,可视化格式会被预先创建。数据会按照地域逐月展示,并根据预定义的公式排序。供应商Perceptive Pixel就属于这一类。
⑤生态系统战略
许多最大最成功的公司都花费大量资金构建围绕它们产品的生态系统。这些生态系统被产品特性和商务模型所支持,并与合作伙伴的产品和技术协同工作。如果一个产品没有一个富有战略的生态系统,是很难适应客户的要求的。