论文《DeepInf: Social Influence Prediction with Deep Learning》阅读
论文《DeepInf: Social Influence Prediction with Deep Learning》阅读
- 论文概况
- 摘要
- Introduction
- 问题形式化
- 模型介绍
-
- 获取r-中心网络
- 网络结构
-
- 嵌入层
- 归一化层
- 输入层
- GCN/GAT层
-
- GCN相关处理
- GAT相关处理
- 输出层
- 实验部分
论文概况
这篇文章《DeepInf: Social Influence Prediction with Deep Learning》是清华大学唐杰老师团队的一篇关于社交影响力预测方面的论文,本文提出了DeepInf模型,通过使用深度学习算法对图结构中节点影响力进行预测,发表在SIGKDD 2018上。
论文地址: https://arxiv.org/abs/1807.05560
PDF下载: https://arxiv.org/pdf/1807.05560.pdf
本文亮点主要集中在(1)网络嵌入Network Embedding,(2)图卷积神经网络,(3)注意力机制的引入。
下面对这篇文章进行介绍,介绍内容夹杂了很多个人的理解,主要分为以下几个部分:
- 摘要
- Introduction
- 问题形式化
- 模型介绍
- 实验部分
摘要
社交网络的兴起,加速了我们被社交网络所影响的过程。以往的社交影响力模型,都是通过手动构造特征进行建模,这样不利于模型的迁移。
基于这一现象,本文提出了一个端到端的深度学习模型,具体的,通过结合网络的结构特征和用户层面的特征信息,使用图卷积神经网络进行了学习,并分别在OAG,Twitter,Weibo,Digg这四个数据集上进行了实验。
Introduction
社会影响力在以往的研究中分为个人影响力(user-level)和群体影响力(aggregated or global patterns of social influence),在很多模式下,个体影响力的分析更加有用。个体影响力的分析,也就是从社交网络中将每一个个体的特征进行提取,并对个人的影响力进行分类或者预测等任务。
社交网络一般以图的形式存在,相比较于图像,语句等比较规则的数据(CNN用于处理固定大小的图像,RNN用于NLP中的语句,图像大小一般是固定的,在NLP中用于构建语义的词向量长度也是固定的),图结构更不易处理(对于图中的每个节点,其出度、入度一般都不相同)。因此最近提出的图神经网络对于图结构就是一个比较自然的选择。

如上图所示,本文1主要解决的问题如下:给定节点v,和她的近邻节点,在一个时间窗口内,通过对开始时间各节点状态(包括图结构和节点特征)进行建模,完成对结束时间节点v状态的预测(激活或者未激活)。
在论文中,图结构使用图神经网络GCN(Graph Convolutional Neural Network)抽取,节点特征使用训练好的DeepWalk工具 2 进行抽取。另外,本文在此基础上,使用注意力机制,通过对节点v临近的不同节点赋予不同的权重,使用图注意力网络GAT(Graph Attention Model)进行了进一步拓展。
问题形式化
对社会影响力进行形式化描述之前,首先对一些概念进行定义。
r-近邻(r-neighbor):给定图 G = ( V , E ) G=(V, E) G=(V,E), 其中V表示用户(vertex), E ⊆ V × V E \subseteq V \times V E⊆V×V 表示用户关系(edge),则用户 v v v的r-近邻定义为 Γ v r = { u : d ( u , v ) ≤ r } \Gamma_v^r=\{u:d(u, v)\leq r\} Γvr={u:d(u,v)≤r},其中 d ( u , v ) d(u, v) d(u,v) 用于表示节点 u u u 和节点 v v v 之间的最短距离。
r-中心网络(r-ego network):用户 v v v 的r-中心网络就是由上述的r-近邻及其节点之间的连线组成的网络,用 G v r G_v^r Gvr 表示。
用户行为在本文中只有两个状态,针对时间戳 t t t ,如果用户 u u u 有完成状态,则 s u t = 1 s_u^t=1 sut=1 ;反之,如果在整个观察窗口内都没有完成动作,则 s u t = 0 s_u^t=0 sut=0 。动作包括:转发行为、引用行为等。
基于上述定义,作者给出文章想要解决的问题——局部社会影响力(social influence locality):给定用户 v v v 的r中心网络 G v r G_v^r Gvr 以及r-近邻(不含 v v v)的用户行为状态集合 S v t = { s u t : u ∈ Γ v r ∖ { v } } S_v^t=\{s_u^t:u\in\Gamma_v^r \setminus \{v\}\} Svt={sut:u∈Γvr∖{v}} ,局部社会影响力拟解决在一段时间 Δ t \Delta t Δt 之后,对用户 v v v的用户行为的预测问题,即 P ( s v t + Δ t ∣ G v r , S v t ) P(s_v^{t+\Delta t} \vert G_v^r, S_v^t ) P(svt+Δt∣Gvr,Svt)
为解决这一问题,具体的,可以形式化如下:对于 N N N个样本,每个样本是一个三元组 ( v , a , t ) (v, a, t) (v,a,t),v表示用户,a表示行为,t表示时间。对于每个三元组,给定 G v r G_v^r Gvr 和 S v t S_v^t Svt,以及 Δ t \Delta t Δt 时间之后用户 v v v 的状态 s v t + Δ t s_v^{t+\Delta t} svt+Δt,则社会影响力预测问题可以转化为一个二元图分类问题,进一步通过最大似然估计法解决问题,即 L ( Θ ) = − ∑ i = 1 N l o g ( P Θ ( s v i t i + Δ t ∣ G v i r , S v i t i ) ) \mathcal{L}(\Theta)=-\sum\nolimits_{i=1}^{N}{log(P_{\Theta}(s_{v_i}^{t_i+\Delta t} \vert G_{v_i}^{r}, S_{v_i}^{t_i}))} L(Θ)=−∑i=1Nlog(PΘ(sviti+Δt∣Gvir,Sviti))
模型介绍
获取r-中心网络
针对用户 v v v,想要获取她的r-中心网络 G v r G_v^r Gvr ,最直接的方法是进行从 v v v 开始的广度优先遍历。但由于(1)不同节点 v v v 的r-中心网络规模可能相差很大;(2)六度分隔理论表明一个节点 v v v 的r-中心网络可能会很大(在本文中,r设置为3)。因此本文进一步使在原始的r-中心网络中进行下采样,以固定样本规模。
下采样的方式使用重启随机游走算法(Random Walk with Restart,RWR),即从用户 v v v 或她的激活临近用户出发,每次以一定概率游走到下一个节点,或者回到出发节点再次游走。通过这样的方式,就可以形成一个固定规模 n n n 的r-近邻 Γ ˉ v r \bar{\Gamma}_v^r Γˉvr 。( ∣ Γ ˉ v r ∣ = n \vert \bar{\Gamma}_v^r \vert = n ∣Γˉvr∣=n ),由此产生固定规模的r-中心网络 G ˉ v r \bar{G}_v^r Gˉvr,以及新的状态集合 S ˉ v t = { s u t : u ∈ Γ ˉ v r ∖ { v } } \bar{S}_v^t=\{s_u^t:u\in \bar{\Gamma}_v^r \setminus \{v\}\} Sˉvt={sut:u∈Γˉvr∖{v}}。因此,重新定义目标函数如下:
L ( Θ ) = − ∑ i = 1 N l o g ( P Θ ( s v i t i + Δ t ∣ G ˉ v i r , S ˉ v i t i ) ) \mathcal{L}(\Theta)=-\sum_{i=1}^{N}{log(P_{\Theta}(s_{v_i}^{t_i+\Delta t} \vert \bar{G}_{v_i}^{r}, \bar{S}_{v_i}^{t_i}))} L(Θ)=−i=1∑Nlog(PΘ(sviti+Δt∣Gˉvir,Sˉviti))
网络结构
网络的整体结构如下图所示,下面分别进行介绍:

嵌入层
在原始输入的网络中使用DeepWalk2模型,得到嵌入矩阵 X ∈ R D × ∣ V ∣ \mathbf{X} \in \mathbb{R}^{D \times \vert V \vert} X∈RD×∣V∣,其中每一行 x u ∈ R D \mathbf{x}_u \in \mathbb{R}^D xu∈RD 表示对于其中任意节点的嵌入向量。
归一化层
为使不同用户(节点)之间特征向量量纲统一,使用归一化层。具体的,针对不同用户的特征向量,将相同坐标的特征向量进行统一。 μ d \mu_d μd 表示均值, σ d 2 \sigma_d^2 σd2 表示方差, ϵ \epsilon ϵ 表示一个极小值。具体如下:
y u d = x u d − μ d σ d 2 + ϵ d = 1 , 2 , . . , D y_ud=\frac{x_{ud} - \mu_d}{\sqrt{\sigma_d^2 + \epsilon}} \qquad d=1,2,..,D yud=σd2+ϵxud−μdd=1,2,..,D
其中, μ d = 1 n ∑ u ∈ Γ v r x u d \mu_d=\frac{1}{n}\sum\limits_{u\in\Gamma_v^r}x_{ud} μd=n1u∈Γvr∑xud
σ d 2 = 1 n ∑ u ∈ Γ v r ( x u d − μ d ) 2 \sigma_d^2=\frac{1}{n}\sum\limits_{u\in\Gamma_v^r}(x_{ud}-\mu_d)^2 σd2=n1u∈Γvr∑(xud−μd)2
输入层
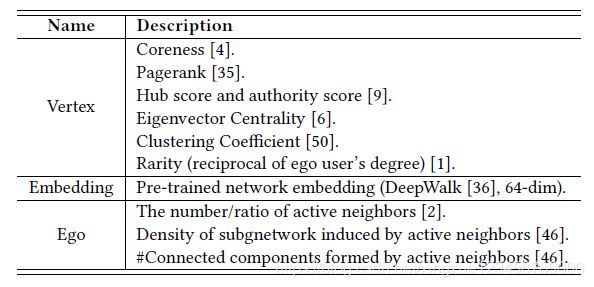
经过上面两层,已经将图中的特征进行了提取,本文又进一步添加了三类手动提取的特征:
- 用户行为状态
- 用户是否是中心用户(ego user)
- 一些定制的节点结构化特征如下:
GCN/GAT层
这一层执行真正的深度学习运算。GCN执行图卷积运算,GAT则是在GCN的基础上加入了attention机制,能够在临近节点的影响中加入权重,从而能够将临近节点的影响进行差异化。
两个模型的原理,都是通过利用图中的特征信息和图的拓扑结构信息这两类信息,完成图中节点特征的映射,将特征进行非线性变换,映射到一个2维的结果向量上(也就是用户的行为状态)。
我们使用 H H H 表示每一层的输入向量, H ′ H' H′表示输出的向量,假定每个batch使用的用户数量为n,则 H ∈ R n × F H\in\mathbb{R}^{n\times F} H∈Rn×F , H H H 中的每一行 h i T h_i^\mathsf{T} hiT 表示一个用户的特征。其中F表示输入的特征向量的长度,对于第一层来说,F就是我们输入层输出的向量长度(DeepWalk长度 + 1(ego标志位) + 2(状态标志位) + 手动特征长度)。
这一层的目的,就是进行非线性变换,输出一个 H ′ H' H′向量, H ′ ∈ R n × F ′ H'\in\mathbb{R}^{n\times F'} H′∈Rn×F′。转换过程如下:
H ′ = G C N ( H ) = g ( A ( G ) H W T + b ) H'=GCN(H)=\mathit{g}(A(G)HW^\mathsf{T}+b) H′=GCN(H)=g(A(G)HWT+b)
在上式中,
H ∈ R n × F H\in \mathbb{R}^{n\times F} H∈Rn×F表示输入的特征向量,
A ( G ) A(G) A(G)是一个函数,输出一个 n × n n \times n n×n大小的矩阵,用于表示图卷积神经网络中的拉普拉斯矩阵。图卷积神经网络通过构造拉普拉斯矩阵完成了归一化。这部分具体可以参考【图结构】之图神经网络GCN详解 这篇博客,对GCN的一些细节进行了讲解,这里不再赘述。
W ∈ R F ′ × F W \in \mathbb {R}^{F' \times F} W∈RF′×F, b ∈ R F ′ b \in \mathbb {R}^{F'} b∈RF′ 用于表示模型中的参数。
GCN相关处理
GCN中的 A ( G ) A(G) A(G) 使用下式进行:
A G C N ( G ) = D − 1 / 2 A D − 1 / 2 A_{GCN}(G)={D^{-1/2}}A{D^{-1/2}} AGCN(G)=D−1/2AD−1/2
在上式中, A A A是图结构的邻接矩阵(但事实上是在邻接矩阵的基础上对角线全部+1,也即, A = A + I A=A+I A=A+I,这样保证了在特征相互影响的过程中能够将元素本身考虑进去); D D D是一个对角矩阵,对角线元素用来表示每个节点的度。
GAT相关处理
GCN通过将图中的结构信息加以考虑,使得节点的特征映射受到了邻接节点的影响。但是这种影响是相同的,没有对每个邻接节点进行单独考虑,这显然与实际情况不相符合。GAT就是利用这一点,通过注意力机制的引入,对不同节点加以不同的权重,得到了一个有所侧重的特征影响过程。
具体地,GAT中的 A ( G ) A(G) A(G) 使用下式进行:
A G A T ( G ) = [ a i j ] n × n A_{GAT}(G)=[a_{ij}]_{n\times n} AGAT(G)=[aij]n×n
a i j a_{ij} aij的计算过程较为复杂,如下:
- 首先,我们通过attention函数计算出attention系数, attn函数完成运算: e i j = a t t n ( W h i , W h j ) e_{ij}=attn(Wh_i , Wh_j) eij=attn(Whi,Whj) 。值得注意的,这里的 e i j e_{ij} eij只对邻接节点及节点自身进行计算。这样,就可以将图中的结构信息进行计算。attn 函数完成节点之间的关联重要性: R F ′ × R F ′ → R \mathbb{R}^{F'} \times \mathbb{R}^{F'} \rightarrow \mathbb{R} RF′×RF′→R
- 之后,再将上述计算的系数进行归一化,使用softmax函数进行。具体地, a i j = s o f t m a x ( e i j ) = e x p ( e i j ) ∑ k ∈ Γ i 1 e x p ( e i k ) a_{ij}=softmax(e_{ij})=\frac{exp(e_{ij})}{\sum\limits_{k \in \Gamma _i ^1}{exp(e_{ik})}} aij=softmax(eij)=k∈Γi1∑exp(eik)exp(eij) 。这里 Γ i 1 \Gamma _i ^1 Γi1 就是节点 i i i 的直接相邻节点。
在本文中,attn函数相当于一个单层的前馈神经网络,即把 2 F ′ 2F' 2F′ 长度的向量通过 c T c^\mathsf{T} cT作为权重映射到一个实数域上。结合所有上述信息,我们可以得到最终的 A ( G ) A(G) A(G)计算如下:
a i j = e x p ( L e a k y R e L U ( c T [ W h i ∣ ∣ W h j ] ) ) ∑ k ∈ Γ i 1 e x p ( L e a k y R e L U ( c T [ W h i ∣ ∣ W h j ] ) ) a_{ij}=\frac{\mathsf{exp}(LeakyReLU(\mathbf{c}^{\mathsf{T}}[\mathbf{Wh_i} \vert \vert \mathbf{Wh_j}]))}{\sum\nolimits_{k \in \Gamma_i^1}{\mathsf{exp}(LeakyReLU(\mathbf{c}^{\mathsf{T}}[\mathbf{Wh_i} \vert \vert \mathbf{Wh_j}]))}} aij=∑k∈Γi1exp(LeakyReLU(cT[Whi∣∣Whj]))exp(LeakyReLU(cT[Whi∣∣Whj]))
更进一步地,多头注意力(Multi-Head Graph Attention)的使用可以聚合多种注意力影响下的特征向量。每一个头就是上述的一个注意力矩阵,通过并行使用多个头并进行聚合,可以提取多种注意力下的影响力。这一过程和CNN中的多个核原理是一样的。如下:
H ′ = g ( A g g r e g a t e ( A 1 ( G ) H W 1 T , … , A k ( G ) H W k T ) + b ) H'=\mathit{g}(Aggregate(A_1(G)HW_1^{\mathsf{T}}, \dots, A_k(G)HW_k^{\mathsf{T}}) + b) H′=g(Aggregate(A1(G)HW1T,…,Ak(G)HWkT)+b)
输出层
输出层共两个,用于表示用户的行为状态(转发/未转发,引用/未引用等),通过与标记结果进行比较,并进行反向梯度传播,完成参数的更新。
实验部分
实验部分在OAG(Open Academic Graph),Digg, Twitter, Weibo四个数据集上进行了实验,这里贴一个结果,略过……

如果你看到了这篇文章的最后,并且觉得有帮助的话,麻烦点个赞,谢谢了!也欢迎和我进行讨论!
Jiezhong Qiu, Jian Tang, Hao Ma, Yuxiao Dong, KuansanWang, and Jie Tang.2018. DeepInf: Social Influence Prediction with Deep Learning . In KDD ’18: The 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, August 19–23, 2018, London, United Kingdom. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3219819.3220077 ↩︎
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. Deepwalk: Online learning of social representations. In KDD ’14. ACM, 701–710. ↩︎ ↩︎