kafka安装说明以及在项目中使用
一、window 安装
1.1、下载安装包
- 下载kafka 地址,其中官方版内置zk, kafka_2.12-3.4.0.tgz
- 其中这个名称的意思是 kafka3.4.0 版本 ,所用语言 scala 版本为 2.12

1.2、安装配置
1、解压刚刚下载的配置文件,解压后如下,其中 data和kafka-logs 这两个文件是没有的
2、修改配置:进入到config目录,
- 修改service.properties里面log.dirs路径未 log.dirs=F:\kafka\installSurround\kafka3.4.0\kafka-logs,该目录是kafka的数据存储目录

- 修改zookeeper.properties里面dataDir路径为 dataDir=F:\kafka\installSurround\kafka3.4.0\data,该目录是 zookeeper存储的kafka的数据目录

3、server.properties说明
| 属性 | 说明 |
|---|---|
| log.dirs | 指定Broker需要使用的若干个文件目录路径,没有默认值,必须指定。在生产环境中一定要为log.dirs配置多个路径,如果条件允许,需要保证目录被挂载到不同的物理磁盘上。优势在于,提升读写性能,多块物理磁盘同时读写数据具有更高的吞吐量;能够实现故障转移(Failover),Kafka 1.1版本引入Failover功能,坏掉磁盘上的数据会自动地转移到其它正常的磁盘上,而且Broker还能正常工作,基于Failover机制,Kafka可以舍弃RAID方案。 |
| zookeeper.connect | CS格式参数,可以指定值为zk1:2181,zk2:2181,zk3:2181,不同Kafka集群可以指定:zk1:2181,zk2:2181,zk3:2181/kafka1,chroot只需要写一次。 |
| listeners | 设置内网访问Kafka服务的监听器。 |
| advertised.listeners | 设置外网访问Kafka服务的监听器。 |
| auto.create.topics.enable | 是否允许自动创建Topic。 |
| unclean.leader.election.enable | 是否允许Unclean Leader 选举。 |
| auto.leader.rebalance.enable | 是否允许定期进行Leader选举,生产环境中建议设置成false。 |
| log.retention.{hours | minutes |
| log.retention.bytes | 指定Broker为消息保存的总磁盘容量大小。message.max.bytes:控制Broker能够接收的最大消息大小。 |
1.3、启动
1、 启动脚本都在bin目录的window目录下,一定要先启动 zookeeper,再启动kafka
如果是linux,不使用window下的命令即可,使用对应的 xxxx.sh 即可

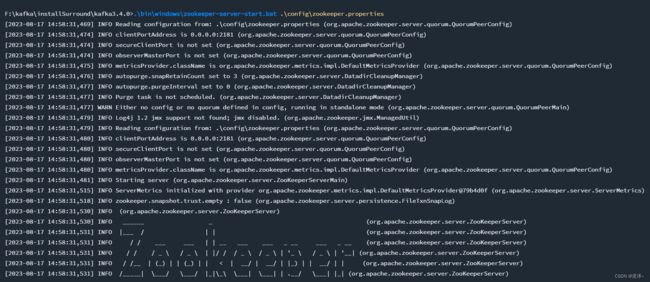
2、首先启动zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
3、在启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties

二、linux 安装
暂略
三、docker 安装
暂略
四、docker 安装
暂略
五、命令行使用
5.1、topic 命令
1、关于topic,这里用window 来示例
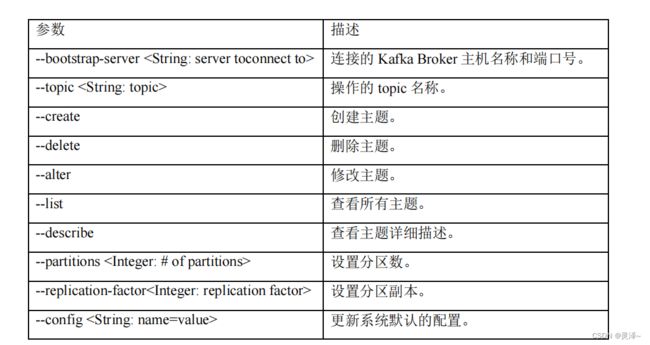
bin\windows\kafka-topics.bat
2、创建 first topic,五个分区,1个副本
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --create --partitions 5 --replication-factor 1 --topic first

3、查看当前服务器中的所有 topic
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092

4、查看 first 主题的详情
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --describe --topic first

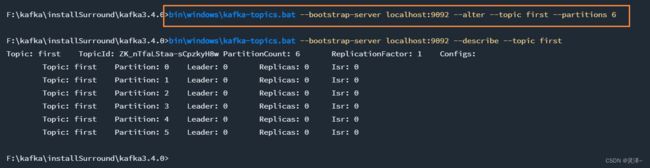
5、修改分区数**(注意:分区数只能增加,不能减少)**
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --alter --topic first --partitions 6
6、删除 topic,该操作在winodw,会出现文件授权问题,日志可以在kafka的启动命令窗口中查看,只需要修改文件权限即可,如果出现这个问题,我们需要清空之前配置的 data和kafka-logs 这两个文件中的内容,再次重新启动即可。
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --delete --topic first

5.2、生产者命令行操作
1、关于查看操作生产者命令参数,这里用window 来示例
.\bin\windows\kafka-console-producer.bat

2、发送消息,这里发送了2次的数据,第一次是hello,第二次是world
.\bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic first

5.3、消费者命令行操作
1、关于查看操作生产者命令参数,这里用window 来示例
.\bin\windows\kafka-console-consumer.bat


2、接受消息,因为前面我们在发送消息的时候,消费者没有启动,所以第一次发的数据这里是收不到的,并没有存储到topic中
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic first


3、把主题中所有的数据都读取出来(包括历史数据),可以看到我们获取到了从消费者没有上线之前到上线之后的所有数据,一共6条。
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --from-beginning --topic first

5.4、脚本说明
| 项目 | Value |
|---|---|
| connect-standalone.sh | 用于启动单节点的Standalone模式的Kafka Connect组件。 |
| connect-distributed.sh | 用于启动多节点的Distributed模式的Kafka Connect组件。 |
| kafka-acls.sh | 脚本用于设置Kafka权限,比如设置哪些用户可以访问Kafka的哪些TOPIC的权限。 |
| kafka-delegation-tokens.sh | 用于管理Delegation Token。基于Delegation Token的认证是一种轻量级的认证机制,是对SASL认证机制的补充。 |
| kafka-topics.sh | 用于管理所有TOPIC。 |
| kafka-console-producer.sh | 用于生产消息。 |
| kafka-console-consumer.sh | 用于消费消息。 |
| kafka-producer-perf-test.sh | 用于生产者性能测试。 |
| kafka-consumer-perf-test.sh | 用于消费者性能测试。 |
| kafka-delete-records.sh | 用于删除Kafka的分区消息,由于Kafka有自己的自动消息删除策略,使用率不高。 |
| kafka-dump-log.sh | 用于查看Kafka消息文件的内容,包括消息的各种元数据信息、消息体数据。 |
| kafka-log-dirs.sh | 用于查询各个Broker上的各个日志路径的磁盘占用情况。 |
| kafka-mirror-maker.sh | 用于在Kafka集群间实现数据镜像。 |
| kafka-preferred-replica-election.sh | 用于执行Preferred Leader选举,可以为指定的主题执行更换Leader的操作。 |
| kafka-reassign-partitions.sh | 用于执行分区副本迁移以及副本文件路径迁移。 |
| kafka-run-class.sh | 用于执行任何带main方法的Kafka类。 |
| kafka-server-start.sh | 用于启动Broker进程。 |
| kafka-server-stop.sh | 用于停止Broker进程。 |
| kafka-streams-application-reset.sh | 用于给Kafka Streams应用程序重设位移,以便重新消费数据。 |
| kafka-verifiable-producer.sh | 用于测试验证生产者的功能。 |
| kafka-verifiable-consumer.sh | 用于测试验证消费者功能。 |
| trogdor.sh | 是Kafka的测试框架,用于执行各种基准测试和负载测试。 |
| kafka-broker-api-versions.sh | 脚本主要用于验证不同Kafka版本之间服务器和客户端的适配性 |
5.5、关闭kafka
1、一定要先关闭 kafka,再关闭zookeeper,否则容易出现数据错乱
如果出现数据错错乱,最简单的方法就是清空data和kafka-logs 这两个文件下的内容,重新启动即可
2、关闭
.\bin\windows\kafka-server-stop.bat
.\bin\windows\zookeeper-server-stop.bat
5.6、选择分区数及kafka性能测试
1、主要工具是 kafka-producer-perf-test.bat 和 kafka-consumer-perf-test.bat 两个脚本,可以参考 kafka如何选择分区数及kafka性能测试
六、java 使用
6.1、使用原生客户端
1、依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>3.4.0version>
dependency>
2、发送和消费消息,具体代码如下:
public class KafkaConfig {
public static void main(String[] args) {
// 声明主题
String topic = "first";
// 创建消费者
Properties consumerConfig = new Properties();
consumerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
consumerConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"boot-kafka");
consumerConfig.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
consumerConfig.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer kafkaConsumer = new KafkaConsumer(consumerConfig);
// 订阅主题并循环拉取消息
kafkaConsumer.subscribe(Arrays.asList(topic));
new Thread(new Runnable() {
@Override
public void run() {
while (true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(10000));
for(ConsumerRecord<String, String> record:records){
System.out.println(record.value());
}
}
}
}).start();
// 创建生产者
Properties producerConfig = new Properties();
producerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
producerConfig.put(ProducerConfig.CLIENT_ID_CONFIG,"boot-kafka-client");
producerConfig.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
producerConfig.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<>(producerConfig);
// 给主题发送消息
producer.send(new ProducerRecord<>(topic, "hello,"+System.currentTimeMillis()));
}
}
6.2、使用springBoot
1、依赖
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
2、配置文件
server:
port: 7280
servlet:
context-path: /thermal-emqx2kafka
shutdown: graceful
spring:
application:
name: thermal-api-demonstration-tdengine
lifecycle:
timeout-per-shutdown-phase: 30s
mvc:
pathmatch:
matching-strategy: ant_path_matcher # 不然spring boot 2.6以后的版本 和 swagger 会出现 问题,可以参考 https://blog.csdn.net/qq_41027259/article/details/125747298
kafka:
bootstrap-servers: 127.0.0.1:9092 # 192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094 连接的 Kafka Broker 主机名称和端口号
#properties.key-serializer: # 用于配置客户端的附加属性,对于生产者和消费者都是通用的,。 org.apache.kafka.common.serialization.StringSerializer
producer: # 生产者
retries: 3 # 重试次数
#acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
#batch-size: 16384 # 一次最多发送数据量
#buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # 消费者
group-id: test-consumer-group #默认的消费组ID,在Kafka的/config/consumer.properties中查看和修改
#enable-auto-commit: true # 是否自动提交offset
#auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
#auto-offset-reset: latest #earliest,latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3、发送消息
package cn.jt.thermalemqx2kafka.kafka.controller;
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
/**
* @author GXM
* @version 1.0.0
* @Description TODO
* @createTime 2023年08月17日
*/
@Slf4j
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@GetMapping("/mock")
public String sendKafkaMessage() {
Map<String, Object> data = new HashMap<>(2);
data.put("id", 1);
data.put("name", "gkj");
kafkaTemplate.send("first", JSON.toJSONString(data));
return "ok";
}
}
4、接受消息
package cn.jt.thermalemqx2kafka.kafka.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author GXM
* @version 1.0.0
* @Description TODO
* @createTime 2023年08月17日
*/
@Slf4j
@Component
public class KafkaListener {
@org.springframework.kafka.annotation.KafkaListener(topics = "first")
private void handler(String content) {
log.info("consumer received: {} ", content);
}
}