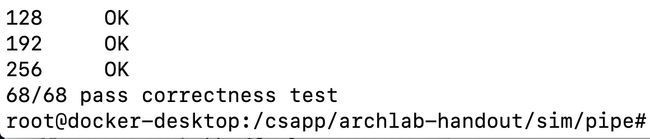
csapp archlab PartC满分解答
任务
修改ncopy.ys和pipe-full.hcl以尽可能的提高ncopy.ys的运行速度
思路
pipe-full.hcl:
- 实现iaddq指令(家庭作业4.54)
- 实现加载转发(家庭作业4.57)
ncopy.ys:
- 使用循环展开(第5.8节),由于代码长度限制,最终使用十路循环展开
- 使用区间判断处理循环展开之后的余数,并利用技巧减少跳转指令
- 利用总是选择分支策略的特性控制分支优先级,决定优先级的有两个因素:一是区间越大(发生的概率越大)的分支优先级越大;二是余数越小优先级越大,因为每个长度的成绩是CPE(cycles per element),而综合成绩又是每个长度成绩的平均值
- 寄存器默认为零,因此删除xorq %rax, %rax指令不会造成错误
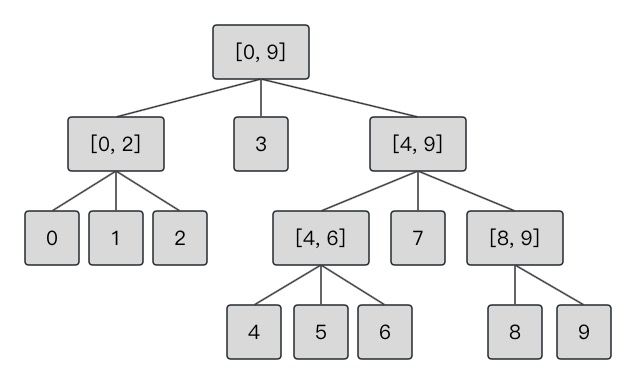
由于采用了十路循环展开,因此余数为[0, 9],由于跳转指令可以为jl,je,jg,因此区间判断的搜索树为一个三叉搜索树,选择3和7进行判断是综合考虑统计因素和余数优先级的结果
代码
##################################################################
# You can modify this portion
# Loop header
# ten-way loop unrolling
iaddq $-10, %rdx # len - 10 < 0?
jl L0R9
Loop1:
mrmovq (%rdi), %r8 # val = *src
rmmovq %r8, (%rsi) # *dst = val
andq %r8, %r8 # val <= 0?
jle Loop2 # if so, goto Loop2
iaddq $1, %rax # count++
Loop2:
mrmovq 0x8(%rdi), %r8
rmmovq %r8, 0x8(%rsi)
andq %r8, %r8
jle Loop3
iaddq $1, %rax
Loop3:
mrmovq 0x10(%rdi), %r8
rmmovq %r8, 0x10(%rsi)
andq %r8, %r8
jle Loop4
iaddq $1, %rax
Loop4:
mrmovq 0x18(%rdi), %r8
rmmovq %r8, 0x18(%rsi)
andq %r8, %r8
jle Loop5
iaddq $1, %rax
Loop5:
mrmovq 0x20(%rdi), %r8
rmmovq %r8, 0x20(%rsi)
andq %r8, %r8
jle Loop6
iaddq $1, %rax
Loop6:
mrmovq 0x28(%rdi), %r8
rmmovq %r8, 0x28(%rsi)
andq %r8, %r8
jle Loop7
iaddq $1, %rax
Loop7:
mrmovq 0x30(%rdi), %r8
rmmovq %r8, 0x30(%rsi)
andq %r8, %r8
jle Loop8
iaddq $1, %rax
Loop8:
mrmovq 0x38(%rdi), %r8
rmmovq %r8, 0x38(%rsi)
andq %r8, %r8
jle Loop9
iaddq $1, %rax
Loop9:
mrmovq 0x40(%rdi), %r8
rmmovq %r8, 0x40(%rsi)
andq %r8, %r8
jle Loop10
iaddq $1, %rax
Loop10:
mrmovq 0x48(%rdi), %r8
rmmovq %r8, 0x48(%rsi)
andq %r8, %r8
jle Step
iaddq $1, %rax
Step:
iaddq $0x50, %rdi
iaddq $0x50, %rsi
iaddq $-10, %rdx
jge Loop1
# applying range checks to remainders
L0R9:
iaddq $7,%rdx # Compare with 3 (len + 10 - 3)
jl L0R2 # len < 3
jg L4R9 # len > 3
je Rem3 # len == 3
L0R2:
iaddq $2,%rdx # Compare with 1 (len + 3 - 1)
je Rem1 # len == 1
jg Rem2 # len == 2
ret # len == 0
L4R6:
iaddq $2,%rdx # Compare with 5 (len + 7 - 5)
jl Rem4 # len == 4
je Rem5 # len == 5
jg Rem6 # len == 6
L4R9:
iaddq $-4,%rdx # Compare with 7 (len + 3 - 7)
jl L4R6 # len < 7
je Rem7 # len == 7
L8R9:
iaddq $-1,%rdx # Compare with 8 (len + 7 - 8)
je Rem8 # len == 8
# dealing with remainders
Rem9:
mrmovq 0x40(%rdi), %r8
rmmovq %r8, 0x40(%rsi)
andq %r8, %r8
jle Rem8
iaddq $1, %rax
Rem8:
mrmovq 0x38(%rdi), %r8
rmmovq %r8, 0x38(%rsi)
andq %r8, %r8
jle Rem7
iaddq $1, %rax
Rem7:
mrmovq 0x30(%rdi), %r8
rmmovq %r8, 0x30(%rsi)
andq %r8, %r8
jle Rem6
iaddq $1, %rax
Rem6:
mrmovq 0x28(%rdi), %r8
rmmovq %r8, 0x28(%rsi)
andq %r8, %r8
jle Rem5
iaddq $1, %rax
Rem5:
mrmovq 0x20(%rdi), %r8
rmmovq %r8, 0x20(%rsi)
andq %r8, %r8
jle Rem4
iaddq $1, %rax
Rem4:
mrmovq 0x18(%rdi), %r8
rmmovq %r8, 0x18(%rsi)
andq %r8, %r8
jle Rem3
iaddq $1, %rax
Rem3:
mrmovq 0x10(%rdi), %r8
rmmovq %r8, 0x10(%rsi)
andq %r8, %r8
jle Rem2
iaddq $1, %rax
Rem2:
mrmovq 0x8(%rdi), %r8
rmmovq %r8, 0x8(%rsi)
andq %r8, %r8
jle Rem1
iaddq $1, %rax
Rem1:
mrmovq (%rdi), %r8
rmmovq %r8, (%rsi)
andq %r8, %r8
jle Done
iaddq $1, %rax
##################################################################
# Do not modify the following section of code
# Function epilogue.
Done:
ret
##################################################################
# Keep the following label at the end of your function
End:
#/* $end ncopy-ys */
实验成绩