rust踩雷笔记(4)——刷点Vec相关的题(持续更新)
俗话说,孰能生巧,今天是第六天接触Rust,感觉基础语法和特性没什么问题了(当然如果你整天都学这个可能2天半就够了),但是想达到熟练使用,还需要刷点题。算法我相信能来看rust博客的人都是大牛(只有我最菜),应该只有数据结构的困扰,所以接下来的博客会侧重于数据结构,毕竟咱常见算法都靠C++练得烂熟了,剩下的事情其实是做到把C++题解翻译成rust题解。
hello
-
-
- leetcode 53 最大子数组和
- leetcode 912——快速排序惨案
- leetcode 743——网络延迟——Dijkstra
-
-
- 方法一:用向量实现邻接表
-
- 补充:小根堆
- 方法二:实现邻接矩阵
-
-
leetcode 53 最大子数组和
这个毫无疑问直接用dp就行了,关键注意事项是with_capacity(n)分配的Vec,你以为它可以用数组下标访问,实际上在它真正push进数据前,下标访问会越界,哪怕dp[0]都不行。
impl Solution {
pub fn max_sub_array(nums: Vec<i32>) -> i32 {
let n = nums.len();
println!("{n}");
// 发现一个问题,即便是指定了大小,但是下面dp.len()为0,可能是因为没有元素
let mut dp: Vec<i32> = Vec::with_capacity(n); // dp[i]表示以下标i为结尾的最大连续子数组之和
// println!("{}", dp.len()); // 0
dp.push(nums[0]);
let mut res = dp[0];
for i in 1..n {
// dp[i] = max(nums[i], nums[i] + dp[i - 1])
let t = nums[i].max(nums[i] + dp[i - 1]);
dp.push(t);
res = res.max(dp[i]);
}
res
}
}
看注释就行了,如果dp.push(nums[0])改为dp[0] = nums[0],那么会报数组下标越界。
基本的使用就是这样,我们继续看别的题
leetcode 912——快速排序惨案
为什么叫惨案,因为我直接用自己的C++解法套用过去,因为语言特性的差异而浪费了两小时。
为了你的安全,请不要嫌弃rust的特性麻烦——鲁迅
这是我C++的写法:
#include看看栈溢出的rust写法,当然我还加了好多注释,全是踩到雷的地方。乍一看和C++代码一样,但是要注意usize的问题,详见注释。
impl Solution {
pub fn quick_sort(a: &mut Vec<i32>, l: usize, r: usize) {
// 不写递归边界会报错:thread 'main' has overflowed its stack (solution.rs)
if l >= r {
return ;
}
// 对a的下标l到r之间进行快速排序
// 栈溢出的原因在这里,都是usize类型,如果l为0,那么i的值不会是-1而是很大的数
// 而且只能是usize,因为需要下标访问
let mut i = l - 1;
let mut j = r + 1;
let mid = (l + r) / 2;
while i < j {
// while *a[l] < *a[mid] { // 这样是错的,a是引用但是a[i]不是,*优先级没有[]高
i += 1;
while a[i] < a[mid] {
i += 1;
}
j -= 1;
while a[j] > a[mid] {
j -= 1;
}
if i < j {
let temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
println!("i:{}, j:{}", i, j);
// 递归要加上Solution::或者Self::
// Solution::quick_sort(a, l, j);
// Solution::quick_sort(a, j + 1, r);
Self::quick_sort(a, l, j);
Self::quick_sort(a, j + 1, r);
}
pub fn sort_array(nums: Vec<i32>) -> Vec<i32> {
// 用这行试验了一下,move occurs because `nums` has type `Vec`, which does not implement the `Copy` trait
// 也就是说所有权转移给了nums1
// let mut nums1 = nums;
// 这句是必要的,入参那里的nums不是mutable的,所以后面&mut nums会报错。创建了新的mutable nums并将入参所有权转移过来
let mut nums = nums;
// 早上太困了,简单写个快速排序
// 报错nums.len()这里还borrowed as immutable,不能同时是mutable和immutable的引用
// Solution::quick_sort(&mut nums, 0, nums.len() - 1);
let len = nums.len();
Solution::quick_sort(&mut nums, 0, len - 1);
nums
}
}
改正之后的代码,对usize和i32进行合适的类型转换,
⚠️i32和usize不能直接相互赋值、参与运算
但是需要注意的是,let mid = (l + r) / 2 as usize;,其中l和r都是i32,你觉得这句话会报错么?
当然会!2 as usize会被当成一个整体,于是变成i32 / usize,报错。
impl Solution {
pub fn quick_sort(a: &mut Vec<i32>, l: i32, r: i32) {
// 不写递归边界会报错:thread 'main' has overflowed its stack (solution.rs)
if l >= r {
return ;
}
// 对a的下标l到r之间进行快速排序
let mut i = l - 1;
let mut j = r + 1;
let mid = a[((l + r) / 2) as usize];
while i < j {
i += 1;
while a[i as usize] < mid {
i += 1;
}
j -= 1;
while a[j as usize] > mid {
j -= 1;
}
if i < j {
let temp = a[i as usize];
a[i as usize] = a[j as usize];
a[j as usize] = temp;
}
}
// Self或者Solution都可以
// Solution::quick_sort(a, l, j);
// Solution::quick_sort(a, j + 1, r);
Self::quick_sort(a, l, j);
Self::quick_sort(a, j + 1, r);
}
pub fn sort_array(nums: Vec<i32>) -> Vec<i32> {
let mut nums = nums;
let len = nums.len();
Solution::quick_sort(&mut nums, 0, (len - 1) as i32);
nums
}
}
小结,快速排序不难,麻烦的是语言特性相关的东西:
(1)注意[]下标访问只能用usize不能用i32,下标访问比*优先级高,如果a是引用&i32,但a[i]是i32(自动“解引用”了),此时不要自作聪明用*a[i],会报错对i32没法解引用
(2)usize和i32不能相互赋值,所以xxx as usize和xxx as i32用起来,但注意优先级问题:(a + b) / 2 as usize,这是先把2转为usize
(3)Vec依旧是没有实现copy trait的,所以它的赋值会转移所有权。当然这句话和本题无关,和本题有关的是方法签名:
pub fn sort_array(nums: Vec,如果你要改变nums,然后返回它,由于它是immutable的,所以你需要let mut nums = nums,重新创建一个变量绑定老nums的值(当然这么做老nums的值就被move掉了),然后改变新nums并返回
(4)不要抱怨rust的特性怎么这么复杂,我一开始套用自己的解法,因为要把变量定义为i32并在若干地方加as usize,我觉得这样不优雅,就试图改变解法,结果发明了几个错误的快排写法。非常蛋疼,假如我没有嫌弃rust的写法麻烦,而是理解这是为了程序安全,就不会浪费时间了!
leetcode 743——网络延迟——Dijkstra
看下图的数据结构,无非就是邻接表和邻接矩阵,这个都可以用数组或者向量来实现。
方法一:用向量实现邻接表
补充:小根堆
注意用到了小根堆
use std::collections::BinaryHeap;
use std::cmp::Reverse;
详情见下面代码,反正push的时候如果用Reverse包起来,那就是小根堆,不包就是大根堆。
如果是小根堆,那么你heap.pop().unwrap_or(Reverse((0, 0)))查出来的是Reverse(元素),注意不是引用(加unwrap是因为pop()查出来是Some(Reverse(元素))或者None),那么需要自己解构一下。
use std::collections::BinaryHeap;
use std::cmp::Reverse;
const MAX_VALUE: i32 = 100 * 100 + 7;
impl Solution {
pub fn network_delay_time(times: Vec<Vec<i32>>, n: i32, k: i32) -> i32 {
let (n, k) = (n as usize, k as usize);
// 二维数组注意显式指定类型
let mut graph = vec![vec![]; n + 1]; // graph[i]表示节点i的邻接表,注意i是1到n
// 初始化图
// 这道题用这里总结下遍历数组方法大全
for i in 0..times.len() {
// times[i] = [u,v,w],表示一条边
// 二维数组除了用[][]定位元素,还有没有更好的方法
// 坑死了,times是i32类型向量;坑死了+1,不要把w变成usize,后面它要和i32运算啊喂!
let (u, v, w) = (times[i][0] as usize, times[i][1] as usize, times[i][2]);
// 所有用于数组下标索引的都必须是usize
graph[u].push((v, w));
}
let mut dist = vec![MAX_VALUE; n + 1]; // dist[i]表示到节点i的最小距离
let mut state = vec![0; n + 1]; // state[i]=0表示节点i没被确认最短路
let mut cnt = 0; // 表示有多少节点确认了最短路
let mut heap = BinaryHeap::new();
let mut res = 0;
dist[k] = 0;
heap.push(Reverse((0, k)));
while heap.len() != 0 {
// heap.pop直接获取元素本身,而不是元素的引用
let Reverse(t) = heap.pop().unwrap_or(Reverse((0, 0)));
let (d, u) = (t.0, t.1);
// 如果u已经被确认最短路,那就直接跳过
if state[u] == 1 {
continue;
}
state[u] = 1;
cnt += 1;
res = res.max(dist[u]);
// 更新u的所有下一个点
for i in 0..graph[u].len() {
// graph[u] = [(v,w),()...]
let (v, w) = graph[u][i];
if state[v] == 1 {
continue;
}
if dist[u] + w < dist[v] {
dist[v] = dist[u] + w;
heap.push(Reverse((dist[v], v)));
}
}
}
if cnt != n {
-1
} else {
res
}
}
}
mark一下rust圣经上的遍历语句
还有一个enumerate,拿的是下标和引用:
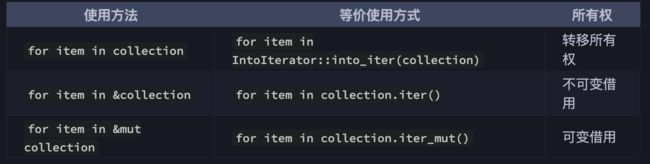
let mut v = vec![1, 3, 2]; // Veci是usize,va是&i32
方法二:实现邻接矩阵
这个我测了一下:

(这图怎么粘上来这么大,怀念以前可以直接调整图片大小的时候)
这个可以成功打印出3x2的矩阵,元素都是1.
To be continued…