Autoecoder实现的两种方式
autoencoder implement1
import torch
import torch.nn as nn
import torch.nn.functional as F
### simple autoencoder
def init_weights(m):
""" initialize weights of fully connected layer
"""
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
# Encoder
class Encoder(nn.Module):
def __init__(self, input_dim,hidden_size):
super(Encoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_size[0]),
nn.ReLU(),
nn.Linear(hidden_size[0],hidden_size[1]))
self.encoder.apply(init_weights)
def forward(self, x):
x = self.encoder(x)
return x
# Decoder
class Decoder(nn.Module):
def __init__(self, input_dim,hidden_size):
super(Decoder, self).__init__()
self.decoder = nn.Sequential(
nn.Linear(hidden_size[1], hidden_size[0]),
nn.ReLU(),
nn.Linear(hidden_size[0], input_dim),
nn.ReLU())
self.decoder.apply(init_weights)
def forward(self, x):
x = self.decoder(x)
return x
# Autoencoder
class AutoEncoder(nn.Module):
def __init__(self, input_dim,hidden_size=[64,32]):
super(AutoEncoder, self).__init__()
self.encoder = Encoder(input_dim,hidden_size)
self.decoder = Decoder(input_dim,hidden_size)
def forward_single(self, x):
h = self.encoder(x)
x = self.decoder(h)
return h, x
def forward(self,x1,x2,x3,x4):
"""
x1:anchor
x2:postive
x3:negative
x4:limits/adherence
"""
output1,recons1 = self.forward_single(x1)
output2,recons2 = self.forward_single(x2)
output3,recons3 = self.forward_single(x3)
output4,recons4 = self.forward_single(x4)
return output1, output2, output3,output4,recons1,recons2,recons3,recons4
def encodeBatch(self, X, batch_size=256):
#需要注意的是encodeBatch和直接用encode会有一些微小的差异
self.eval()
dataloader = torch.utils.data.DataLoader(
X, batch_size=batch_size, pin_memory=False, shuffle=False)
from tqdm import tqdm
data_iterator = tqdm(dataloader, leave=False, unit="batch")
features = []
for batch in data_iterator:
batch = batch.squeeze(1).view(batch.size(0), -1)
output,_ = self.forward_single(batch)
features.append(output.detach().cpu()) # move to the CPU to prevent out of memory on the GPU
return torch.cat(features,dim=0)
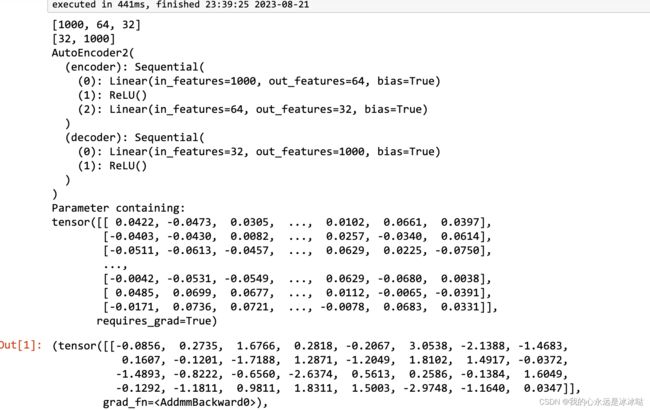
hidden_size=[64,32]
torch.manual_seed(1)
model = AutoEncoder(input_dim=1000,hidden_size=hidden_size)
print(model)
print(model.encoder.encoder[0].weight)
x = torch.randn(1,1000)
model.forward_single(x)
结果如下


autoencoder implement2
import torch
import torch.nn as nn
def buildNetwork(layers, type, activation=["relu"],last_act =False):
print(layers)
net = []
if(last_act):
for i in range(1, len(layers)):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
if(not last_act):
for i in range(1, len(layers)-1):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
net.append(nn.Linear(layers[len(layers)-2],layers[len(layers)-1]))
return nn.Sequential(*net)
### simple autoencoder
def init_weights(m):
""" initialize weights of fully connected layer
"""
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
# Autoencoder
class AutoEncoder2(nn.Module):
def __init__(self, input_dim=1000, z_dim=32, encodeLayer=[64], decodeLayer=[64],activation="relu"):
super(AutoEncoder2, self).__init__()
self.encoder = buildNetwork([input_dim]+encodeLayer+[z_dim], type="encode", activation=activation,last_act=False)
self.encoder.apply(init_weights)
self.decoder = buildNetwork([z_dim]+decodeLayer+[input_dim], type="decode", activation=activation,last_act=True)
self.decoder.apply(init_weights)
def forward_single(self, x):
h = self.encoder(x)
x = self.decoder(h)
return h, x
def forward(self,x1,x2,x3,x4):
"""
x1:anchor
x2:postive
x3:negative
x4:limits/adherence
"""
output1,recons1 = self.forward_single(x1)
output2,recons2 = self.forward_single(x2)
output3,recons3 = self.forward_single(x3)
output4,recons4 = self.forward_single(x4)
return output1, output2, output3,output4,recons1,recons2,recons3,recons4
def encodeBatch(self, X, batch_size=256):
#需要注意的是encodeBatch和直接用encode会有一些微小的差异
self.eval()
dataloader = torch.utils.data.DataLoader(
X, batch_size=batch_size, pin_memory=False, shuffle=False)
from tqdm import tqdm
data_iterator = tqdm(dataloader, leave=False, unit="batch")
features = []
for batch in data_iterator:
batch = batch.squeeze(1).view(batch.size(0), -1)
output,_ = self.forward_single(batch)
features.append(output.detach().cpu()) # move to the CPU to prevent out of memory on the GPU
return torch.cat(features,dim=0)
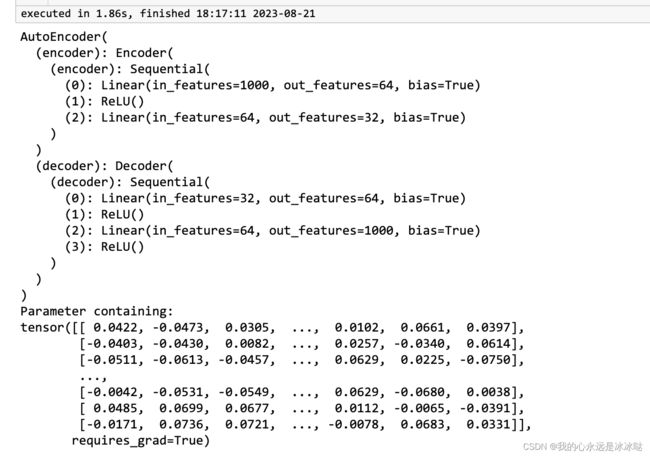
torch.manual_seed(1)
model = AutoEncoder2(input_dim=1000, z_dim=32,
encodeLayer=[64], decodeLayer=[64]) ## not use noise
print(model)
print(model.encoder[0].weight)
x = torch.randn(1,1000)
model.forward_single(x)
结果如下


第二种实现还有一个好处
buildNetwork是可以构造空网络的
空squential 网络
import torch
import torch.nn as nn
def buildNetwork(layers, type, activation=["relu"],last_act =False):
print(layers)
net = []
if(last_act):
for i in range(1, len(layers)):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
if(not last_act):
for i in range(1, len(layers)-1):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
net.append(nn.Linear(layers[len(layers)-2],layers[len(layers)-1]))
return nn.Sequential(*net)
### simple autoencoder
def init_weights(m):
""" initialize weights of fully connected layer
"""
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
# Autoencoder
class AutoEncoder2(nn.Module):
def __init__(self, input_dim=1000, z_dim=32, encodeLayer=[64], decodeLayer=[64],activation="relu"):
super(AutoEncoder2, self).__init__()
self.encoder = buildNetwork([input_dim]+encodeLayer+[z_dim], type="encode", activation=activation,last_act=False)
self.encoder.apply(init_weights)
self.AAA = buildNetwork([z_dim], type="decode", activation=activation,last_act=True)
self.decoder = buildNetwork([z_dim]+decodeLayer+[input_dim], type="decode", activation=activation,last_act=True)
self.decoder.apply(init_weights)
def forward_single(self, x):
h = self.encoder(x)
h = self.AAA(h)
x = self.decoder(h)
return h, x
def forward(self,x1,x2,x3,x4):
"""
x1:anchor
x2:postive
x3:negative
x4:limits/adherence
"""
output1,recons1 = self.forward_single(x1)
output2,recons2 = self.forward_single(x2)
output3,recons3 = self.forward_single(x3)
output4,recons4 = self.forward_single(x4)
return output1, output2, output3,output4,recons1,recons2,recons3,recons4
def encodeBatch(self, X, batch_size=256):
#需要注意的是encodeBatch和直接用encode会有一些微小的差异
self.eval()
dataloader = torch.utils.data.DataLoader(
X, batch_size=batch_size, pin_memory=False, shuffle=False)
from tqdm import tqdm
data_iterator = tqdm(dataloader, leave=False, unit="batch")
features = []
for batch in data_iterator:
batch = batch.squeeze(1).view(batch.size(0), -1)
output,_ = self.forward_single(batch)
features.append(output.detach().cpu()) # move to the CPU to prevent out of memory on the GPU
return torch.cat(features,dim=0)
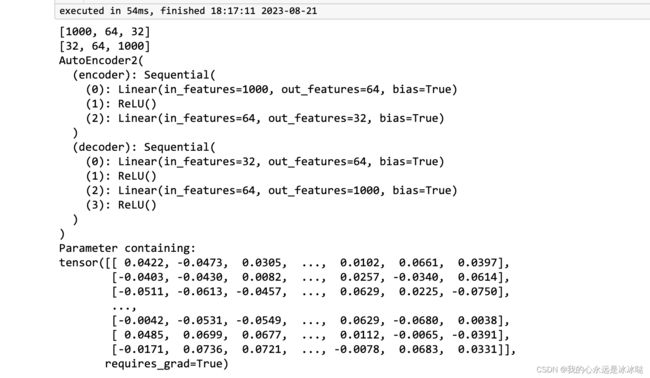
torch.manual_seed(1)
model = AutoEncoder2(input_dim=1000, z_dim=32,
encodeLayer=[64], decodeLayer=[]) ## not use noise
print(model)
print(model.encoder[0].weight)
x = torch.randn(1,1000)
model.forward_single(x)
结果如下

对比版本
import torch
import torch.nn as nn
def buildNetwork(layers, type, activation=["relu"],last_act =False):
print(layers)
net = []
if(last_act):
for i in range(1, len(layers)):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
if(not last_act):
for i in range(1, len(layers)-1):
net.append(nn.Linear(layers[i-1], layers[i]))
if activation=="relu":
net.append(nn.ReLU())
elif activation=="sigmoid":
net.append(nn.Sigmoid())
else:
pass
net.append(nn.Linear(layers[len(layers)-2],layers[len(layers)-1]))
return nn.Sequential(*net)
### simple autoencoder
def init_weights(m):
""" initialize weights of fully connected layer
"""
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
# Autoencoder
class AutoEncoder2(nn.Module):
def __init__(self, input_dim=1000, z_dim=32, encodeLayer=[64], decodeLayer=[64],activation="relu"):
super(AutoEncoder2, self).__init__()
self.encoder = buildNetwork([input_dim]+encodeLayer+[z_dim], type="encode", activation=activation,last_act=False)
self.encoder.apply(init_weights)
#self.AAA = buildNetwork([z_dim], type="decode", activation=activation,last_act=True)
self.decoder = buildNetwork([z_dim]+decodeLayer+[input_dim], type="decode", activation=activation,last_act=True)
self.decoder.apply(init_weights)
def forward_single(self, x):
h = self.encoder(x)
#h = self.AAA(h)
x = self.decoder(h)
return h, x
def forward(self,x1,x2,x3,x4):
"""
x1:anchor
x2:postive
x3:negative
x4:limits/adherence
"""
output1,recons1 = self.forward_single(x1)
output2,recons2 = self.forward_single(x2)
output3,recons3 = self.forward_single(x3)
output4,recons4 = self.forward_single(x4)
return output1, output2, output3,output4,recons1,recons2,recons3,recons4
def encodeBatch(self, X, batch_size=256):
#需要注意的是encodeBatch和直接用encode会有一些微小的差异
self.eval()
dataloader = torch.utils.data.DataLoader(
X, batch_size=batch_size, pin_memory=False, shuffle=False)
from tqdm import tqdm
data_iterator = tqdm(dataloader, leave=False, unit="batch")
features = []
for batch in data_iterator:
batch = batch.squeeze(1).view(batch.size(0), -1)
output,_ = self.forward_single(batch)
features.append(output.detach().cpu()) # move to the CPU to prevent out of memory on the GPU
return torch.cat(features,dim=0)
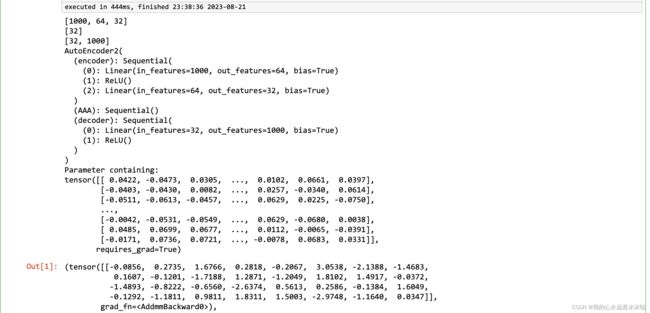
torch.manual_seed(1)
model = AutoEncoder2(input_dim=1000, z_dim=32,
encodeLayer=[64], decodeLayer=[]) ## not use noise
print(model)
print(model.encoder[0].weight)
x = torch.randn(1,1000)
model.forward_single(x)
结果如下