PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西:
- VMware
- ubuntu 14.04(64位)
- Java环境(JDK 1.8)
- Hadoop 2.7.1
- Spark 2.4.0(Local模式)
- Pycharm
(一)Ubuntu
VMware 和 ubuntu 14.04(64位)的安装见:在vmware上安装ubuntu 14.04(64位)_study_note_mark的博客-CSDN博客
安装Ubuntu完成后需要完成一些前期准备工作,包括:创建Hadoop用户、更新apt、安装ssh及配置ssh无密码登录,参考:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- 在Ubuntu里打开终端窗口的快捷键是 ctrl+alt+t
- sudo命令:sudo是ubuntu中一种权限管理机制,管理员可以授权给一些普通用户去执行一些需要root权限执行的操作。当使用sudo命令时,就需要输入您当前用户的密码
- 在Ubuntu终端窗口中,复制粘贴的快捷键需要加上shift,即粘贴是ctrl+shift+v
-
更改软件源:Ubuntu20.04更新软件源路径_ubuntu20.04软件和更新在哪_donnieliu的博客-CSDN博客
- vim编辑器:
- 正常模式:主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式
- 插入编辑模式:用来向文本中添加内容。在正常模式下,输入i键即可进入插入编辑模式
- 退出vim:如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim
- ssh登录:类似于远程登录。可以登录某台Linux主机,并在上面运行命令
- 在Linux系统中,~ 代表的是用户的主文件夹,即 "/home/用户名" 这个目录,如你的用户名为 hadoop,则 ~ 就代表 "/home/hadoop/"
(二)Java(JDK 1.8)
参考Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- 常见Linux命令:Linux系统常用命令_厦大数据库实验室博客
- Linux管道命令:Linux Shell中的管道命令_厦大数据库实验室博客
- vim编辑器用法:Linux系统中vim编辑器的安装和使用方法_厦大数据库实验室博客
(三)Hadoop 2.7.1
Hadoop安装、伪分布式配置、启动Yarn参考Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- Hadoop默认模式为非分布式模式(本地模式),即单Java进程,无需进行其他配置即可运行
- Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时读取的是HDFS中的文件
- 运行Hadoop程序时,为了防止覆盖结果,程序指定的输出目录(如output)不能存在,否则会提示错误,因此运行前需要先删除输出目录(如hdfs dfs -rm -r output)
- 三种shell命令方式:
- hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
- hadoop dfs:只能适用于HDFS文件系统
- hdfs dfs:只能适用于HDFS文件系统
- 若要关闭Hadoop,运行stop-dfs.sh;下次启动Hadoop,无需进行NameNode初始化,只需运行start-dfs.sh(仅仅启动了MapReduce环境,没有启动YARN)
- 通过hdfs命令可以访问HDFS的内容
http://localhost:50070/dfshealth.html#tab-overview
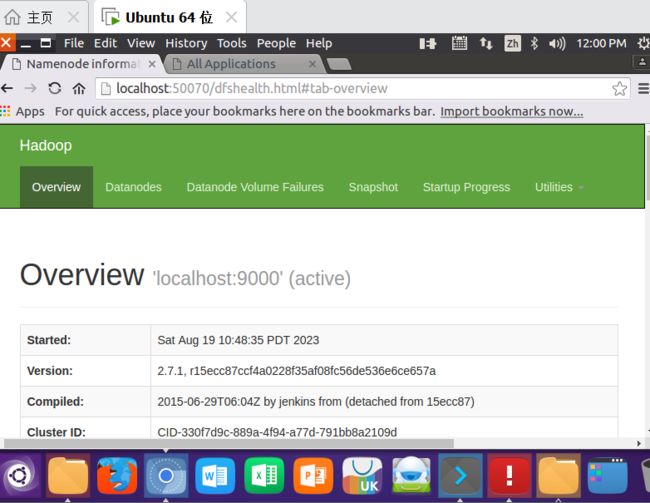
YARN(Yet Another Resource Negotiator)是从MapReduce中分离出来的,负责资源管理与任务调度。YARN运行于MapReduce之上,提供了高可用性、高扩展性
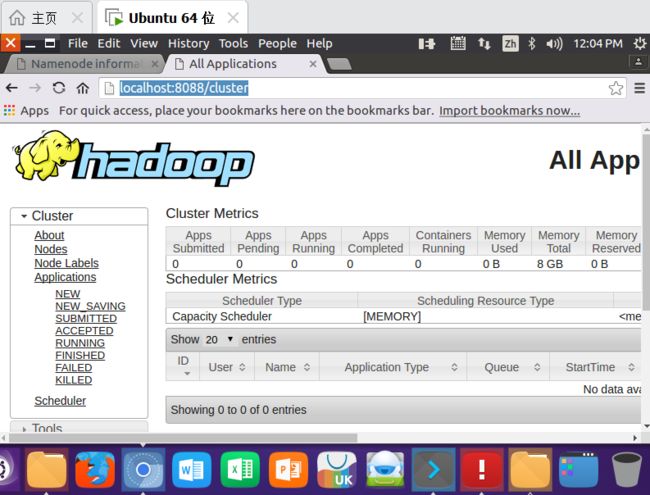
启动YARN之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用YARN时,是 "mapred.LocalJobRunner" 在跑任务;启用YARN之后,是 "mapred.YARNRunner" 在跑任务。启动YARN有个好处是可以通过Web界面查看任务的运行情况:http://localhost:8088/cluster
启动/关闭YARN的脚本:
start-yarn.sh # 启动YARN
mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver如果需要安装Hadoop集群,参考Hadoop 2.7分布式集群环境搭建_厦大数据库实验室博客
(四)Spark 2.4.0(Local模式)
Apache Spark是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。Spark最大的特点就是快,可比Hadoop MapReduce的处理速度快100倍
Spark采用Local模式进行安装,也就是在单机上运行Spark。因此,在安装Hadoop时,需要按照伪分布式模式进行安装。在单台机器上按照“Hadoop(伪分布式)+Spark(Local模式)”这种方式进行Hadoop和Spark组合环境的搭建,可以较好满足入门级Spark学习的需求
Index of /dist/spark/spark-2.4.0
参考以下链接中 “安装Spark(Local模式)” 部分即可(这篇帖子是Spark 3.4.0,但原理相同):Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客
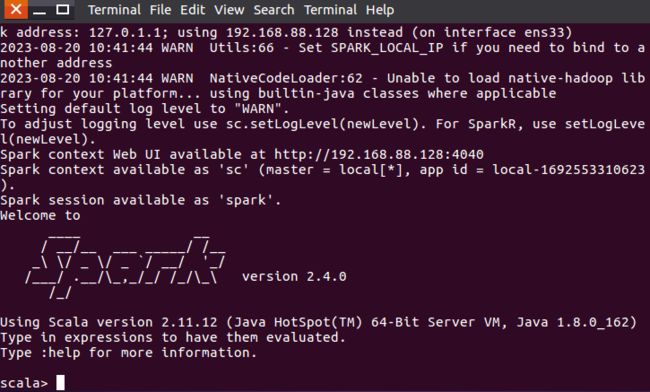
cd /usr/local/spark
bin/spark-shellSpark Shell界面如下,不过是以Scala为交互语言(Ctrl+c退出):
进入Pyspark:
cd /usr/local/spark
./bin/pyspark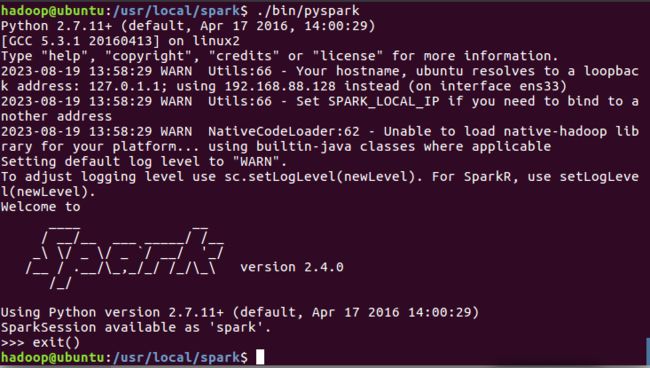
总结:
- bash和shell的区别:
- shell:负责人机交互的一种抽象,接收用户输入交给内核,内核执行完后返回给用户。有多种实现,sh/bash/csh/ksh/ash,当前用户登录后操作系统会用哪种shell,是由配置文件中对应用户的配置来决定的,可由echo $SHELL查看
- bash:shell的一种实现(/bin/bash)。用户远程连接后,操作系统会默认生成一个bash进程

(五)PyCharm
Download PyCharm: Python IDE for Professional Developers by JetBrains
安装参考:使用Pycharm开发Spark应用程序(以WordCount为例)_厦大数据库实验室博客 以及
第一章 python分布式爬虫打造搜索引擎环境搭建 第一节 CentOS7环境下pycharm的安装和使用_Demon丶冷漠的博客-CSDN博客
安装过程中我遇到一个报错如下:

解决方法是新开一个terminal再执行命令,参考linux安装pycharm报错:Unable to detect graphics environment_pycharm unable to detect graphics environment_我有明珠一颗的博客-CSDN博客
编辑hosts文件时遇到以下两个问题,原因是权限不足:
vim 修改文件出现错误 “ E45: ‘readonly’ option is set (add to override)“_大红烧肉的博客-CSDN博客
Linux使用vi编辑文件报错:E212: Can‘t open file for writing Press ENTER or type command to continue_/ect/hosts" e212: can't open file for writing_凝眸伏笔的博客-CSDN博客
(六)案例(以WordCount为例)
参考:使用Pycharm开发Spark应用程序(以WordCount为例)_厦大数据库实验室博客
启动pycharm:

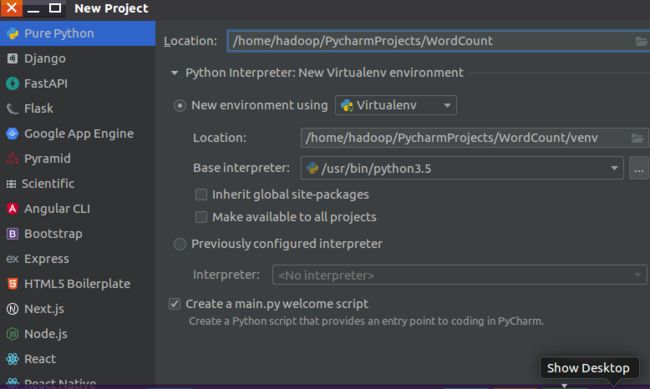
创建文件夹(注意Base interpreter选择的是 /usr/bin/python3.5):
上传word.txt文件(本地地址为/home/hadoop/Downloads/word.txt)至HDFS(创建一个文件夹aaa,上传至aaa文件夹下)
hadoop fs -ls # 查看hdfs下的文件
hdfs dfs -mkdir /aaa # 创建一个目录aaa
hdfs dfs -put /home/hadoop/Downloads/word.txt /aaa # 上传word.txt文件至aaa文件夹下
hadoop fs -ls /aaa # 检查是否上传成功
# 三种shell命令方式:
# hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
# hadoop dfs:只能适用于HDFS文件系统
# hdfs dfs:只能适用于HDFS文件系统打开HDFS:
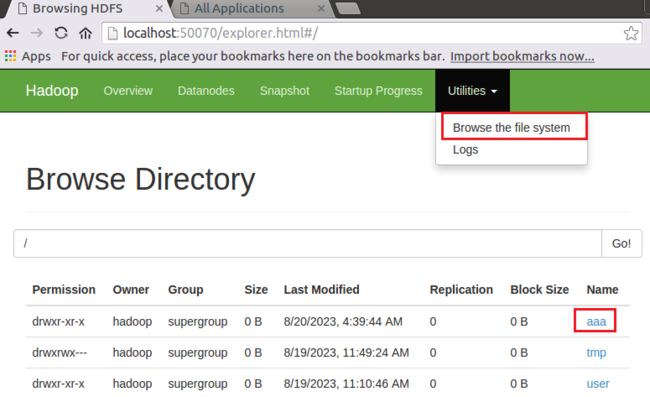
关于HDFS的一些操作可以参考:如何上传文件到hdfs?_数据上传至hdfs://crash目录下_你看这人,真菜的博客-CSDN博客
WordCount.py代码如下:
# -*- coding:utf8-*-
# 安装pyspark:在终端输入pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
import os
os.environ['PYSPARK_PYTHON'] = '/usr/bin/python3.5' # python解释器路径
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "hdfs://localhost:9000/aaa/word.txt" # 文件放在hdfs伪分布式文件系统上(必须开启hdfs文件系统)
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
wordCount.foreach(print)- flatMap:将文件按空格进行拍扁
- map:将拍扁后的一个个单词分别映射成 (word, 1) 的形式
- reduceByKey:将map输出中key相同的值加起来
- foreach:循环遍历打印输出结果

(1)右键运行。运行结果如下:
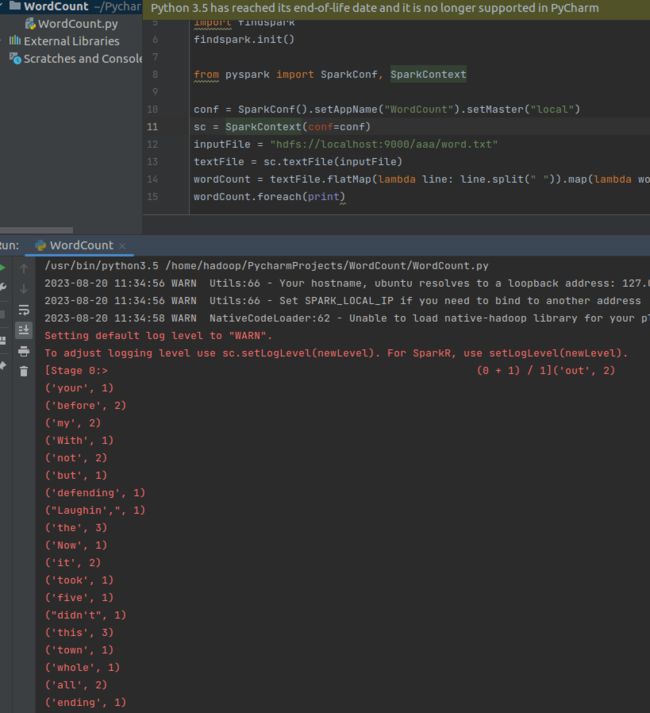
(2)也可以把代码提交到Spark运行。在终端运行:
cd /usr/local/spark/
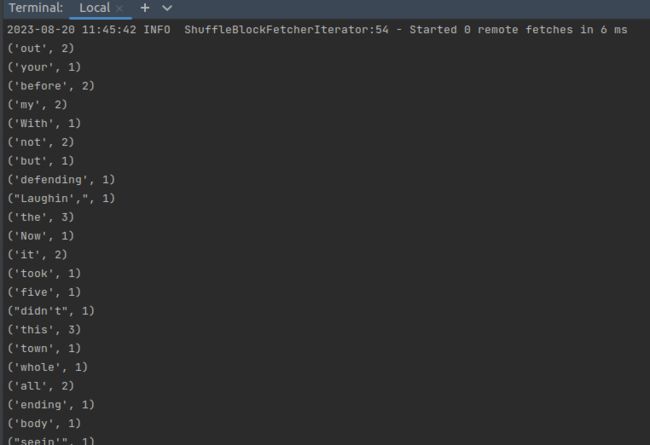
./bin/spark-submit /home/hadoop/PycharmProjects/WordCount/WordCount.py翻一下我们的输出信息可以找到结果:
注:Spark & PySpark 的执行可以特别详细,很多INFO日志消息都会打印到屏幕。开发过程中,这非常恼人,因为可能丢失Python栈跟踪或者print的输出。为了减少Spark输出,可以设置$SPARK_HOME/conf 下的log4j
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties
将 log4j.rootCategory=INFO, console 中的 INFO 改为 WARN 或者 ERROR,保存退出,如下图:

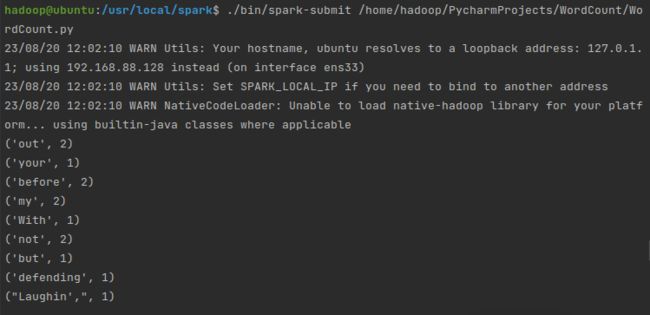
再运行,输出结果就一目了然了:
更多案例参考:
基于Python语言的Spark数据处理分析案例集锦(PySpark)_厦大数据库实验室博客
更多大数据相关博客:大数据_厦大数据库实验室博客