shell脚本——函数与数组
shell脚本——函数与数组
- 1、函数
-
- 1.1函数概念
-
- 1.1.1概念和优点
- 1.1.2函数的使用法则
- 1.2函数的运用方法
-
- 1.2.1定义函数
- 1.2.2查看函数
- 1.2.3调用函数
- 1.2.4函数的返回值
- 1.2.5函数传参
- 1.2.6 删除函数
- 1.3函数的作用范围
- 1.4 函数文件
- 1.5 递归函数(重要)
- 2、数组
-
- 2.1数组是什么?
- 2.2数组的格式
- 2.3.数组的数据类型
- 2.4 获取数组的长度
- 2.5获取数组的数据列表
- 2.6获取数组下标对应的值
- 2.7数组的常用操作
-
- 2.7.1数组的遍历
- 2.7.2 数组切片
- 2.7.3 数组替换#临时替换
- 2.7.4 数组删除和指定下标的值删除
- 2.7.5 数组追加元素
- 2.7.6 declare -a: 查看所有数组
- 3、冒泡排序
1、函数
1.1函数概念
1.1.1概念和优点
概念:函数是定义一个函数名,可以调用函数方法,完成便捷处理。
1.1.2函数的使用法则
- 直接写 函数中调用函数 直接写函数名
- 同名函数 后一个生效
- 调用函数一定要先定义
- 只要先定义了调用的 其他函数定义顺序无关
1.2函数的运用方法
1.2.1定义函数
方法一
func_name (){
...函数体...
}
方法二
function function_name {
# 函数体
}
方法三
function function_name() {
# 函数体
}
1.2.2查看函数
declare -F #查看所有已定义的函数的函数名
declare -F func_name #查看指定函数的函数名
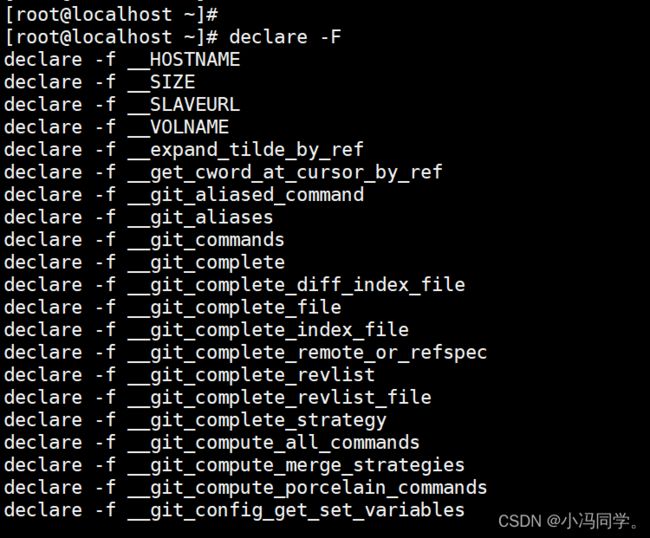
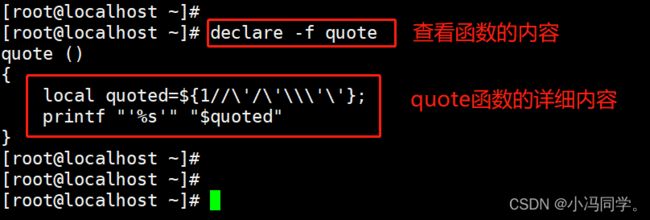
declare -f
#查看所有已定义的函数的内容
declare -f func_name
#查看指定函数的内容
1.2.3调用函数
只有定义了函数,才能调用函数
#先定义函数
function_name() {
# 函数体
}
#调用函数
function_name

例子
#定义函数
#!/bin/bash
os (){
if grep -i -q "CentOS Linux 7 " /etc/os-release
then
echo "此操作系统是centos 7"
elif grep -i -q "CentOS Linux 6 " /etc/os-release
then
echo "此操作系统是centos 6"
elif grep -i -q "CentOS Linux 8 " /etc/os-release
then
echo "此操作系统是centos 8"
fi
}
#调用函数
os

1.2.4函数的返回值
return表示退出函数并返回一个退出值,脚本中可以用$?变量显示该值
使用原则:
- 函数一结束就取返回值,因为$?变量只返回执行的最后一条命令的退出状态码。
#!/bin/bash
test1 () {
read -p "请输入一个数字:" num
return $[$num*2]
}
test1
echo $?

- 退出状态码必须是0~255,超出时值将为除以256取余。
#!/bin/bash
test1 () {
read -p "请输入一个数字:" num
echo $[$num*2]
}
result=`test1`
echo $result

返回值的作用:
- 对函数执行的结果进行判断和处理:函数可以返回不同的值来表示不同的执行状态或错误情况。
- 传递函数执行的结果给其他部分:函数的返回值可以被赋值给变量,能将函数的计算结果传递给其他命令或者再次使用。
- 作为脚本的退出状态码:根据不同的返回值来设置不同的退出状态码。
1.2.5函数传参
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n
的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…即使用位置参数来实现参数传递。
示例脚本
- 内部传参

- 外部传参

- 例子
#!/bin/bash
add ( ) {
num=$[$1+$2]
}
num=0
read -p "请输入第一个数:"a
read -p "请输入第一个数:"b
#调用函数
add $a $b
echo "$num"


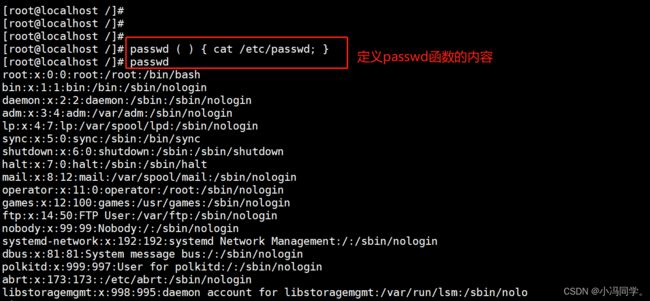
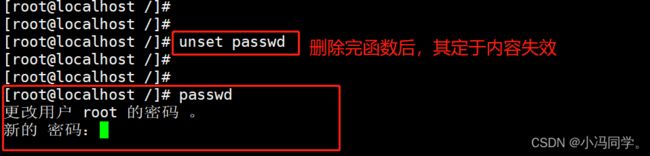
1.2.6 删除函数
unset function_name
#从当前的 Shell 环境中删除指定的函数
1.3函数的作用范围
- 函数在Shell脚本中仅在当前Shell环境中有效
- Shell脚本中变量默认全局有效
- 将变最限定在函数内部使用local命令


1.4 函数文件
将函数代码写入一个脚本文件,在需要的时候调用该脚本文件,相当于直接调用函数。
在Shell脚本中使用函数文件时,需要写上函数文件的绝对路径。
1.5 递归函数(重要)
递归归函数是指在函数体内调用自身的函数,用于需要重复执行相同或类似任务的场景。
编写递归函数时要确保设定递归的结束条件,以避免死循环。
阶乘
fact() {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[$1 - 1]
local result=$(fact $temp)
echo $[$1 * $result]
# 5 * $result(4*$result(3*$result(2*$result(1))))
fi
}
read -p "请输入:" n
result=$(fact $n)
echo $result

2、数组
2.1数组是什么?
- 数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小(与 PHP 类似)。
- 与大部分编程语言类似,数组元素的下标由 0 开始。
- Shell 数组用括号来表示,元素用"空格"符号分割开
- 在shell语句中,使用、遍历数组的时候,数组格式要写成 ${arr[@]} 或 ${arr[*]}
2.2数组的格式
格式一:
数组名=(value1 value2 ... valuen)
arr_number=(1 2 3 4 5 6 7 8 9)
格式二:
数组名=([0]=value0 [1]=value0 [2]=value0 ...)
arr_number=([0]=1 [1]=2 [2]=3 [3]=4)
格式三:
列表名:“value1 value2 valueN ..."
数组名=($列表名)
list_number="1 2 3 4 5 6"
arr_number=($list_number)
格式四:
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
arr_number[0]=1
arr_number[1]=2
arr_number[2]=3
2.3.数组的数据类型
- 数值类型
- 字符类型
- 使用 “ ”(双引号) 或者 ‘ ’ (单引号)定义
数组可以时数值型也可以是混合型

2.4 获取数组的长度
echo ${#数组名[*]}
echo ${#数组名[@]}

2.5获取数组的数据列表
echo ${数组名[*]}
echo ${数组名[@]}

2.6获取数组下标对应的值
数组名=(元素0 元素1 元素2 ……) //定义数组
echo ${数组名[索引值]} //输出数组索引值对应的元素,索引值为从0开始
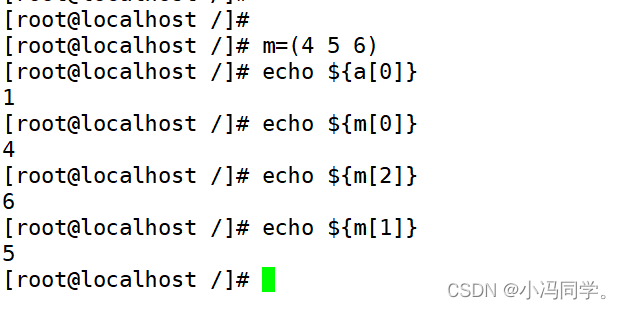
2.7数组的常用操作
2.7.1数组的遍历
#!/bin/bash
a=(1 2 3 4 5 6)
for i in ${a[@]}
do
echo $i
done

2.7.2 数组切片
a=(0 1 2 3 4 5 6 7 8)
echo "输出整个数组: " ${a[@]}
echo "取出数组1到3: " ${a[@]:1:3}
echo "取出数组5到后面所有的元素: " ${a[@]:5:5}

2.7.3 数组替换#临时替换
echo ${a[@]/原替换位置/替换内容}
#重新赋值,可以永久修改
a=(${a[@]/原替换位置/替换内容})

2.7.4 数组删除和指定下标的值删除
#删除整个数组
unset 数组名
#删除指定下标的值
unset 数组名[数组下标]
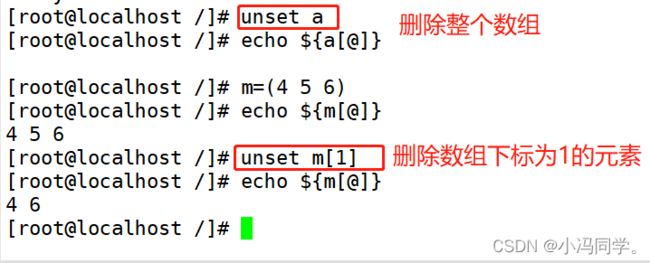
2.7.5 数组追加元素
方法一:直接使用下标进行元素的追加
数组名[下标]=变量

方法二: 将数组的长度作为下标进行追加元素
数组名[${数组名[#@]}]=变量名
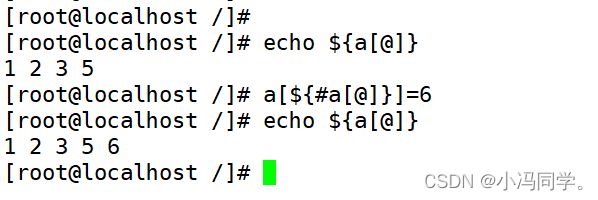
方法三: 使用+=进行追加
数组名+=(变量1 变量2 ...)

2.7.6 declare -a: 查看所有数组

3、冒泡排序
#!/bin/bash
#排序之前的数组顺序
a=(10 40 33 30 77 66 44 )
#确定循环比较的次数
for ((j=1;j<${#a[@]};j++))
do
#对比获取每次的最大元素的索引位置
for ((i=0;i<${#a[@]}-j;i++))
do
#如果对比出最大元素,就把该元素赋值给后面的变量tmp
if [ ${a[$i]} -gt ${a[$i+1]} ]
then
#定义一个变量tmp,将每次比较的最大数值放进tmp,实现变量对换
tmp=${a[$i+1]}
a[$i+1]=${a[$i]}
a[$i]=$tmp
fi
done
done
echo ${a[*]}
