官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
翻译 | 付典
Review | 徐榜江、朱翥
Apache Flink 社区很荣幸地宣布 Flink 1.12.0 版本正式发布!近 300 位贡献者参与了 Flink 1.12.0 的开发,提交了超过 1000 多个修复或优化。这些修改极大地提高了 Flink 的可用性,并且简化(且统一)了 Flink 的整个 API 栈。其中一些比较重要的修改包括:
-
在 DataStream API 上添加了高效的批执行模式的支持。这是批处理和流处理实现真正统一的运行时的一个重要里程碑。
-
实现了基于Kubernetes的高可用性(HA)方案,作为生产环境中,ZooKeeper方案之外的另外一种选择。
-
扩展了 Kafka SQL connector,使其可以在 upsert 模式下工作,并且支持在 SQL DDL 中处理 connector 的 metadata。现在,时态表 Join 可以完全用 SQL 来表示,不再依赖于 Table API 了。
-
PyFlink 中添加了对于 DataStream API 的支持,将 PyFlink 扩展到了更复杂的场景,比如需要对状态或者定时器 timer 进行细粒度控制的场景。除此之外,现在原生支持将 PyFlink 作业部署到 Kubernetes上。
本文描述了所有主要的新功能、优化、以及需要特别关注的改动。
Flink 1.12.0 的二进制发布包和源代码可以通过 Flink 官网的下载页面获得,详情可以参阅 Flink 1.12.0 的官方文档。我们希望您下载试用这一版本后,可以通过 Flink 邮件列表和 JIRA 网站和我们分享您的反馈意见。
Flink 1.12 官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/
新的功能和优化
DataStream API 支持批执行模式
Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
-
可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
-
维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
■ 有限流上的批处理
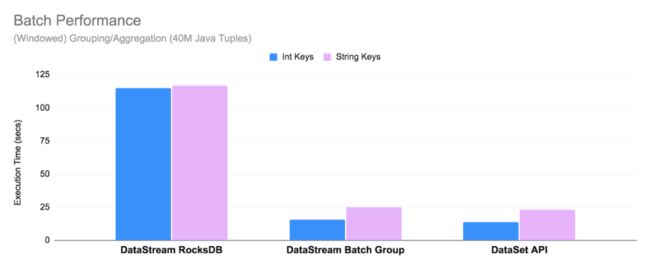
您已经可以使用 DataStream API 来处理有限流(例如文件)了,但需要注意的是,运行时并不“知道”作业的输入是有限的。为了优化在有限流情况下运行时的执行性能,新的 BATCH 执行模式,对于聚合操作,全部在内存中进行,且使用 sort-based shuffle(FLIP-140)和优化过的调度策略(请参见 Pipelined Region Scheduling 了解更多详细信息)。因此,DataStream API 中的 BATCH 执行模式已经非常接近 Flink 1.12 中 DataSet API 的性能。有关性能的更多详细信息,请查看 FLIP-140。
在 Flink 1.12 中,默认执行模式为 STREAMING,要将作业配置为以 BATCH 模式运行,可以在提交作业的时候,设置参数 execution.runtime-mode:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
或者通过编程的方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);
注意:尽管 DataSet API 尚未被弃用,但我们建议用户优先使用具有 BATCH 执行模式的 DataStream API 来开发新的批作业,并考虑迁移现有的 DataSet 作业。
新的 Data Sink API (Beta)
之前发布的 Flink 版本中[1],已经支持了 source connector 工作在流批两种模式下,因此在 Flink 1.12 中,社区着重实现了统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 协议和一个更加模块化的接口。Sink 的实现者只需要定义 what 和 how:SinkWriter,用于写数据,并输出需要 commit 的内容(例如,committables);Committer 和 GlobalCommitter,封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。
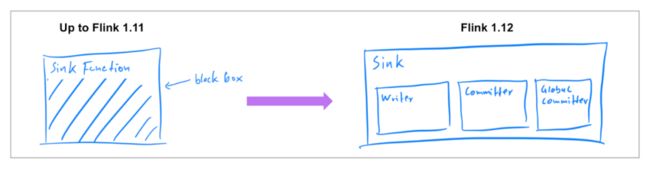
这种模块化的抽象允许为 BATCH 和 STREAMING 两种执行模式,实现不同的运行时策略,以达到仅使用一种 sink 实现,也可以使两种模式都可以高效执行。Flink 1.12 中,提供了统一的 FileSink connector,以替换现有的 StreamingFileSink connector (FLINK-19758)。其它的 connector 也将逐步迁移到新的接口。
基于 Kubernetes 的高可用 (HA) 方案
Flink 可以利用 Kubernetes 提供的内置功能来实现 JobManager 的 failover,而不用依赖 ZooKeeper。为了实现不依赖于 ZooKeeper 的高可用方案,社区在 Flink 1.12(FLIP-144)中实现了基于 Kubernetes 的高可用方案。该方案与 ZooKeeper 方案基于相同的接口[3],并使用 Kubernetes 的 ConfigMap[4] 对象来处理从 JobManager 的故障中恢复所需的所有元数据。关于如何配置高可用的 standalone 或原生 Kubernetes 集群的更多详细信息和示例,请查阅文档[5]。
注意:需要注意的是,这并不意味着 ZooKeeper 将被删除,这只是为 Kubernetes 上的 Flink 用户提供了另外一种选择。
其它功能改进
■ 将现有的 connector 迁移到新的 Data Source API
在之前的版本中,Flink 引入了新的 Data Source API(FLIP-27),以允许实现同时适用于有限数据(批)作业和无限数据(流)作业使用的 connector 。在 Flink 1.12 中,社区从 FileSystem connector(FLINK-19161)出发,开始将现有的 source connector 移植到新的接口。
注意: 新的 source 实现,是完全不同的实现,与旧版本的实现不兼容。
■ Pipelined Region 调度 (FLIP-119)
在之前的版本中,Flink 对于批作业和流作业有两套独立的调度策略。Flink 1.12 版本中,引入了统一的调度策略, 该策略通过识别 blocking 数据传输边,将 ExecutionGraph 分解为多个 pipelined region。这样一来,对于一个 pipelined region 来说,仅当有数据时才调度它,并且仅在所有其所需的资源都被满足时才部署它;同时也可以支持独立地重启失败的 region。对于批作业来说,新策略可显著地提高资源利用率,并消除死锁。
■ 支持 Sort-Merge Shuffle (FLIP-148)
为了提高大规模批作业的稳定性、性能和资源利用率,社区引入了 sort-merge shuffle,以替代 Flink 现有的实现。这种方案可以显著减少 shuffle 的时间,并使用较少的文件句柄和文件写缓存(这对于大规模批作业的执行非常重要)。在后续版本中(FLINK-19614),Flink 会进一步优化相关性能。
注意:该功能是实验性的,在 Flink 1.12 中默认情况下不启用。要启用 sort-merge shuffle,需要在 TaskManager 的网络配置[6]中设置合理的最小并行度。
■ Flink WebUI 的改进 (FLIP-75)
作为对上一个版本中,Flink WebUI 一系列改进的延续,Flink 1.12 在 WebUI 上暴露了 JobManager 内存相关的指标和配置参数(FLIP-104)。对于 TaskManager 的指标页面也进行了更新,为 Managed Memory、Network Memory 和 Metaspace 添加了新的指标,以反映自 Flink 1.10(FLIP-102)开始引入的 TaskManager 内存模型的更改[7]。
Table API/SQL: SQL Connectors 中的 Metadata 处理
如果可以将某些 source(和 format)的元数据作为额外字段暴露给用户,对于需要将元数据与记录数据一起处理的用户来说很有意义。一个常见的例子是 Kafka,用户可能需要访问 offset、partition 或 topic 信息、读写 kafka 消息中的 key 或 使用消息 metadata中的时间戳进行时间相关的操作。
在 Flink 1.12 中,Flink SQL 支持了元数据列用来读取和写入每行数据中 connector 或 format 相关的列(FLIP-107)。这些列在 CREATE TABLE 语句中使用 METADATA(保留)关键字来声明。
CREATE TABLE kafka_table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
在 Flink 1.12 中,已经支持 Kafka 和 Kinesis connector 的元数据,并且 FileSystem connector 上的相关工作也已经在计划中(FLINK-19903)。由于 Kafka record 的结构比较复杂,社区还专门为 Kafka connector 实现了新的属性[8],以控制如何处理键/值对。关于 Flink SQL 中元数据支持的完整描述,请查看每个 connector 的文档[9]以及 FLIP-107 中描述的用例。
Table API/SQL: Upsert Kafka Connector
在某些场景中,例如读取 compacted topic 或者输出(更新)聚合结果的时候,需要将 Kafka 消息记录的 key 当成主键处理,用来确定一条数据是应该作为插入、删除还是更新记录来处理。为了实现该功能,社区为 Kafka 专门新增了一个 upsert connector(upsert-kafka),该 connector 扩展自现有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既可以作为 source 使用,也可以作为 sink 使用,并且提供了与现有的 kafka connector 相同的基本功能和持久性保证,因为两者之间复用了大部分代码。
要使用 upsert-kafka connector,必须在创建表时定义主键,并为键(key.format)和值(value.format)指定序列化反序列化格式。完整的示例,请查看最新的文档[10]。
Table API/SQL: SQL 中 支持 Temporal Table Join
在之前的版本中,用户需要通过创建时态表函数(temporal table function) 来支持时态表 join(temporal table join) ,而在 Flink 1.12 中,用户可以使用标准的 SQL 语句 FOR SYSTEM_TIME AS OF(SQL:2011)来支持 join。此外,现在任意包含时间列和主键的表,都可以作为时态表,而不仅仅是 append-only 表。这带来了一些新的应用场景,比如将 Kafka compacted topic 或数据库变更日志(来自 Debezium 等)作为时态表。
CREATE TABLE orders (
order_id STRING,
currency STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '30' SECOND
) WITH (
…
);
-- Table backed by a Kafka compacted topic
CREATE TABLE latest_rates (
currency STRING,
rate DECIMAL(38, 10),
currency_time TIMESTAMP(3),
WATERMARK FOR currency_time AS currency_time - INTERVAL ‘5’ SECOND,
PRIMARY KEY (currency) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
…
);
-- Event-time temporal table join
SELECT
o.order_id,
o.order_time,
o.amount * r.rate AS amount,
r.currency
FROM orders AS o, latest_rates FOR SYSTEM_TIME AS OF o.order_time r
ON o.currency = r.currency;
上面的示例同时也展示了如何在 temporal table join 中使用 Flink 1.12 中新增的 upsert-kafka connector。
■ 使用 Hive 表进行 Temporal Table Join
用户也可以将 Hive 表作为时态表来使用,Flink 既支持自动读取 Hive 表的最新分区作为时态表(FLINK-19644),也支持在作业执行时追踪整个 Hive 表的最新版本作为时态表。请参阅文档,了解更多关于如何在 temporal table join 中使用 Hive 表的示例。
Table API/SQL 中的其它改进
■ Kinesis Flink SQL Connector (FLINK-18858)
从 Flink 1.12 开始,Table API / SQL 原生支持将 Amazon Kinesis Data Streams(KDS)作为 source 和 sink 使用。新的 Kinesis SQL connector 提供了对于增强的Fan-Out(EFO)以及 Sink Partition 的支持。如需了解 Kinesis SQL connector 所有支持的功能、配置选项以及对外暴露的元数据信息,请查看最新的文档。
■ 在 FileSystem/Hive connector 的流式写入中支持小文件合并 (FLINK-19345)
很多 bulk format,例如 Parquet,只有当写入的文件比较大时,才比较高效。当 checkpoint 的间隔比较小时,这会成为一个很大的问题,因为会创建大量的小文件。在 Flink 1.12 中,File Sink 增加了小文件合并功能,从而使得即使作业 checkpoint 间隔比较小时,也不会产生大量的文件。要开启小文件合并,可以按照文档[11]中的说明在 FileSystem connector 中设置 auto-compaction = true 属性。
■ Kafka Connector 支持 Watermark 下推 (FLINK-20041)
为了确保使用 Kafka 的作业的结果的正确性,通常来说,最好基于分区来生成 watermark,因为分区内数据的乱序程度通常来说比分区之间数据的乱序程度要低很多。Flink 现在允许将 watermark 策略下推到 Kafka connector 里面,从而支持在 Kafka connector 内部构造基于分区的 watermark[12]。一个 Kafka source 节点最终所产生的 watermark 由该节点所读取的所有分区中的 watermark 的最小值决定,从而使整个系统可以获得更好的(即更接近真实情况)的 watermark。该功能也允许用户配置基于分区的空闲检测策略,以防止空闲分区阻碍整个作业的 event time 增长。
■ 新增的 Formats
| Format |
描述 |
支持的 Connectors 类型 |
| Avro Schema Registry (FLINK-16048) |
读写由 Confluent Schema Registry KafkaAvroSerializer 序列化的数据 |
|
| Debezium Avro (FLINK-18774) |
读写由 Confluent Schema Registry KafkaAvroSerializer序列化的Debezium记录 |
|
| Maxwell(CDC) |
读写 Maxwell JSON 记录 |
|
| Raw[13] (FLINK-14356) |
读写 raw values (基于byte的) 作为单独的一列 |
|
■ 利用 Multi-input 算子进行 Join 优化 (FLINK-19621)
Shuffling 是一个 Flink 作业中最耗时的操作之一。为了消除不必要的序列化反序列化开销、数据 spilling 开销,提升 Table API / SQL 上批作业和流作业的性能, planner 当前会利用上一个版本中已经引入的N元算子(FLIP-92),将由 forward 边所连接的多个算子合并到一个 Task 里执行。
■ Type Inference for Table API UDAFs (FLIP-65)
Flink 1.12 完成了从 Flink 1.9 开始的,针对 Table API 上的新的类型系统[2]的工作,并在聚合函数(UDAF)上支持了新的类型系统。从 Flink 1.12 开始,与标量函数和表函数类似,聚合函数也支持了所有的数据类型。
PyFlink: Python DataStream API
为了扩展 PyFlink 的可用性,Flink 1.12 提供了对于 Python DataStream API(FLIP-130)的初步支持,该版本支持了无状态类型的操作(例如 Map,FlatMap,Filter,KeyBy 等)。如果需要尝试 Python DataStream API,可以安装PyFlink,然后按照该文档[14]进行操作,文档中描述了如何使用 Python DataStream API 构建一个简单的流应用程序。
from pyflink.common.typeinfo import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
class MyMapFunction(MapFunction):
def map(self, value):
return value + 1
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("datastream job")
PyFlink 中的其它改进
■ PyFlink Jobs on Kubernetes (FLINK-17480)
除了 standalone 部署和 YARN 部署之外,现在也原生支持将 PyFlink 作业部署在 Kubernetes 上。最新的文档中详细描述了如何在 Kubernetes 上启动 session 或 application 集群。
■ 用户自定义聚合函数 (UDAFs)
从 Flink 1.12 开始,您可以在 PyFlink 作业中定义和使用 Python UDAF 了(FLIP-139)。普通的 UDF(标量函数)每次只能处理一行数据,而 UDAF(聚合函数)则可以处理多行数据,用于计算多行数据的聚合值。您也可以使用 Pandas UDAF[15](FLIP-137),来进行向量化计算(通常来说,比普通 Python UDAF 快10倍以上)。
注意: 普通 Python UDAF,当前仅支持在 group aggregations 以及流模式下使用。如果需要在批模式或者窗口聚合中使用,建议使用 Pandas UDAF。
其它重要改动
-
[FLINK-19319] The default stream time characteristic has been changed to EventTime, so you no longer need to call StreamExecutionEnvironment.setStreamTimeCharacteristic() to enable event time support.
-
[FLINK-19278] Flink now relies on Scala Macros 2.1.1, so Scala versions < 2.11.11 are no longer supported.
-
[FLINK-19152] The Kafka 0.10.x and 0.11.x connectors have been removed with this release. If you’re still using these versions, please refer to the documentation[16] to learn how to upgrade to the universal Kafka connector.
-
[FLINK-18795] The HBase connector has been upgraded to the last stable version (2.2.3).
-
[FLINK-17877] PyFlink now supports Python 3.8.
-
[FLINK-18738] To align with FLIP-53, managed memory is now the default also for Python workers. The configurations python.fn-execution.buffer.memory.size and python.fn-execution.framework.memory.size have been removed and will not take effect anymore.
详细发布说明
如果你想要升级到1.12的话,请详细阅读详细发布说明[17]。与之前所有1.x版本相比,1.12可以保证所有标记为 @Public 的接口的兼容性。
原文链接:
https://flink.apache.org/news/2020/12/10/release-1.12.0.html
参考链接:
[1] https://flink.apache.org/news/2020/07/06/release-1.11.0.html#new-data-source-api-beta
[2] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/types.html#data-types
[3] https://ci.apache.org/projects/flink/flink-docs-release-1.11/api/java/org/apache/flink/runtime/highavailability/HighAvailabilityServices.html
[4] https://kubernetes.io/docs/concepts/configuration/configmap/
[5] https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/ha/kubernetes_ha.html
[6] https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/config.html#taskmanager-network-sort-shuffle-min-parallelism
[7] https://flink.apache.org/news/2020/04/21/memory-management-improvements-flink-1.10.html
[8] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/kafka.html#key-format
[9] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/
[10] https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connectors/kinesis.html
[11] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/filesystem.html#file-compaction
[12] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/kafka.html#source-per-partition-watermarks
[13] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/formats/raw.html
[14] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/python/datastream_tutorial.html
[15] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/python/table-api-users-guide/udfs/vectorized_python_udfs.html#vectorized-aggregate-functions
[16] https://ci.apache.org/projects/flink/flink-docs-master/dev/connectors/kafka.html
[17] https://ci.apache.org/projects/flink/flink-docs-stable/release-notes/flink-1.12.html
 Flink Forward Asia 2020
Flink Forward Asia 2020
大会议程发布
Flink Forward Asia 2020 在线峰会重磅开启!12月13-15日,全球 38+ 一线厂商,70+ 优质议题,与您探讨新型数字化技术下的未来趋势!大会议程已正式上线,点击文末「阅读原文」即可免费预约~
