clickhouse(十四、分布式DDL阻塞及同步阻塞问题)
文章目录
- 一、分布式ddl 阻塞、超时
-
- 现象
- 验证方法
- 解决方案
- 二、副本同步阻塞
-
- 现象
- 验证
- 解决方案
一、分布式ddl 阻塞、超时
现象
在clickhouse 集群的操作中,如果同时执行一些重量级变更语句,往往会引起阻塞。 一般是由于节点堆积过多耗时的ddl。然后抛出如下异常
ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 159, host: 127.0.0.1, port: 8123; Code: 159, e.displayText() =
DB::Exception: Watching task /clickhouse/task_queue/ddl/query-0000000318 is executing longer than distributed_ddl_task_timeout (=180) seconds.

验证方法
1.查询zookeeper的队列数,节点完成情况。
2.查询mutations表,改更较重操作一般会在这个表记录。
select FQDN() as node,
database,
table,
mutation_id,
create_time,
command,
is_done,
parts_to_do
FROM clusterAllReplicas('default_cluster', system.mutations)
WHERE is_done = 0;
解决方案
先看能不能是kill MUTATION ,确定一下是不是所有节点里都KILL了,如果所有节点都确定KILL了这个队列还堵在那就只能删ZK。
KILL MUTATION on cluster default_cluster WHERE database = 'default' AND table = 'table';
二、副本同步阻塞
现象
写入副本表后,查询数据量不一致或是很长时间才能一致。例如原表8968w, 写入sql都已经执行完成,查询只有6629w。集群没有阻塞时会直接查询到全量数据。
CREATE TABLE tmp.dwm_we_search_query_ad_data_v5_copy_20230815_local (
`f000_date` Nullable(Date),
`row_key` Int64,
`day_` Nullable(String),
`hour_` Nullable(String),
`position_id` String,
`query` String,
`aid` Int64,
`advertiser_id` String,
`query_classify_res` Nullable(Int64),
`imp_fail_cnt` Nullable(Int64),
`imp_pv` Nullable(Int64)
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/default_cluster/tables/{shard}/tmp/dwm_we_search_query_ad_data_v5_copy_20230815_local', '{replica}')
PARTITION BY ds_
ORDER BY (ds_, position_id,query,aid,advertiser_id,row_key)
SETTINGS index_granularity = 8192
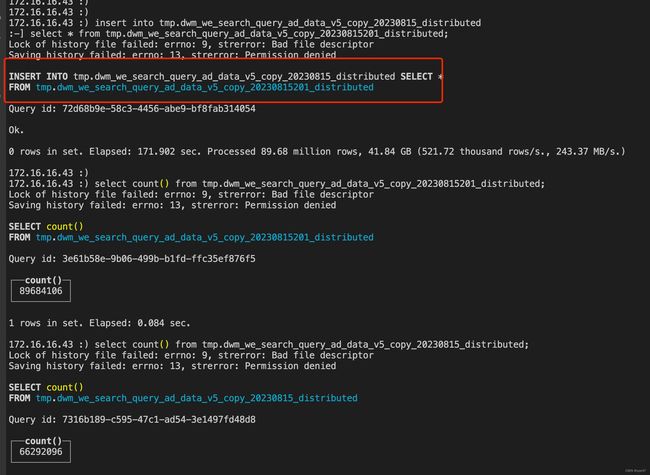
验证
查询 system.replication_queue 表的数量,如果记录很多,说明正在同步的任务多,数据达到一致的延迟大。
-- 查询同步队列数
SELECT count() FROM system.replication_queue;
-- 查询同步表详情
SELECT * FROM system.replication_queue LIMIT 1 FORMAT Vertical;
解决方案
首先确认同步队列中的表是否正常业务需要的,集群的io是否正常。 如果确实有大量的写入业务,就需要调整副本并行的线程大小replicated_max_parallel_fetches_for_host, 如果发现大量没用/测试 的表在同步,可删除,这也是快速解决问题的方案。