安装pyspark步骤过程
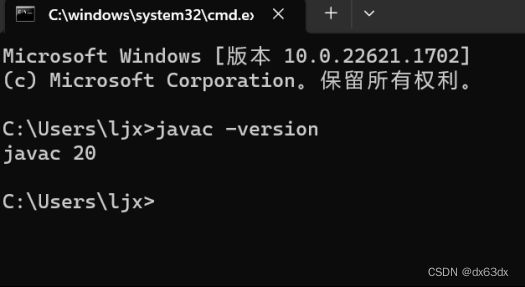
一,首先检查java环境的安装
二,打开pycharm,点击左上角File选中Settings,找到图片显示的位置,根据划线的绝对路径,打开自己电脑上的对应位置,然后cmd进入终端,进行下载。

三,PySpark库的安装
输入如下中的其中一个(我一般用第二个下载,比较快)
pip install pyspark==3.3.1
或者
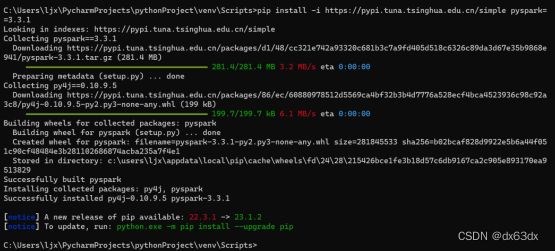
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.3.1
下载完提示要update的话,直接复制提示给的命令,直接下载
四,配置本机Spark环境
1,将hadoop-3.3.1放到一个指定的目录,比如D:\spark\hadoop-3.3.1
2. 将hadoop.dll放到C:\Windows\System32目录下
3. 配置hadoop环境变量:将hadoop的安装路径,如:D:\spark\hadoop-3.3.1,放到path变量中
4. 将winutils.exe放到hadoop的bin目录下
五,Spark环境准备
使用Spark前必须完成两个操作:
设置Spark的配置信息
创建Spark工具对象
代码示例
# 导包
from pyspark import SparkConf, SparkContext
import os
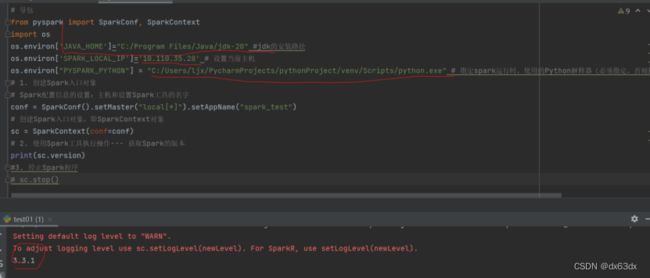
os.environ['JAVA_HOME']="C:/java/jdk18" #jdk的安装路径
os.environ['SPARK_LOCAL_IP']='127.0.0.1' # 设置当前主机
os.environ["PYSPARK_PYTHON"] = "D:/python/python.exe" # 指定spark运行时,使用的Python解释器(必
须指定,否则执行数据分析时,会报错)
# 1. 创建Spark入口对象
# Spark配置信息的设置:主机和设置Spark工具的名字
conf = SparkConf().setMaster("local[*]").setAppName("spark_test")
# 创建Spark入口对象,即SparkContext对象
sc = SparkContext(conf=conf)
# 2. 使用Spark工具执行操作--- 获取Spark的版本
print(sc.version)
#3. 停止Spark程序
sc.stop()
注意!!!导包那三个路径需要修改(下图划线处)
成功如下