项目实训(七)---多个人物关系建立
2021SC@SDUSC
这里在和老师商讨后,在完成对一个视频目标任务检测计数后,老师建议我们可以加上对多个人关系的建立,主要表现在要统计一个视频中,多个人物出现的时间点的记录。根据每个人物出现的时间点可以判断在哪个时间点前后这些人物同时出现了。
功能效果:
提供两种剪辑方式 :
- 自动:比如要A人物就把A人物出现次数最多的10个gif找出来,然后按时间排序组成视频
- 手动:以提供的如下带有人物出现位置的时间轴作为参考,用户可以自由截取需要的视频

这部分完成后,关于人脸识别这里关键的算法已经完成,关于输入输出,视频文件遍历和组织的存储结构等,在和后端整合到一起时,再来规范。
目录
一.关键代码
二.效果
2.1人脸库建立
2.2人物关系生成
一.关键代码
声明资源:
import dlib,os,glob,time
import cv2
import numpy as np
import pandas as pd
# 声明各个资源路径
resources_path = os.path.abspath("") + "\Resources\\"
predictor_path = resources_path + "shape_predictor_68_face_landmarks.dat"
model_path = resources_path + "dlib_face_recognition_resnet_model_v1.dat"
video_path =resources_path + "shipin.mp4"
resources_vResult=resources_path+"video\\"
faceDB_path= "Resources/featureMean/"
# 加载视频,加载失败则退出
video = cv2.VideoCapture(video_path)
# 获得视频的fps
fps = video.get(cv2.CAP_PROP_FPS)
if not video.isOpened():
print("video is not opened successfully!")
exit(0)
# # 加载模型
#人脸特征提取器
detector = dlib.get_frontal_face_detector()
#人脸关键点标记
predictor= dlib.shape_predictor(predictor_path)
#生成面部识别器
facerec = dlib.face_recognition_model_v1(model_path)
#定义视频创建器,用于输出视频
video_writer = cv2.VideoWriter(resources_vResult+"result1.avi",
cv2.VideoWriter_fourcc(*'XVID'), int(fps),
(int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))))读取本地人脸库:
#读取本地人脸库
head = []
for i in range(128):
fe = "feature_" + str(i + 1)
head.append(fe)
face_path=faceDB_path+"feature_all.csv"
face_feature=pd.read_csv(face_path,names=head)
#人脸库中人物的特征
face_feature_array=np.array(face_feature)
#待识别人物 这个序号和feature_all.csv的特征序号应该保持一致
num=len(face_feature_array)
face_list= []
for i in range(num):
face_list=face_list+[i]
#人脸库中的人脸数量
Flen=len(face_list)
# 创建窗口(测试使用,后期删除)
cv2.namedWindow("Face Recognition", cv2.WINDOW_KEEPRATIO)
cv2.resizeWindow("Face Recognition", 720,576)
#计算128D描述符的欧式距离
def compute_dst(feature_1,feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.linalg.norm(feature_1 - feature_2)
return dist
人物关系初始化:
dict={}#人物关系
for i in range(Flen): #初始化
dict[i]=[]视频时长获取:
#视频时长
duration=0
if video.isOpened():
rate = video.get(5)
frame_num =video.get(7)
duration = frame_num/rate
视频逐帧检测:
while ret:
frame_count+=1
if i % 6== 0: # 每6帧截取一帧
# 转为灰度图像处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1) # 检测帧图像中的人脸
# 处理这一帧检测到的每一张人脸
print("当前检测到的人脸数量%d"%(len(dets)))
#检测到了人脸
if len(dets)>0:
for index,value in enumerate(dets):
#获取面部关键点
shape = predictor(gray,value)
#标记人脸
cv2.rectangle(frame, (value.left(), value.top()), (value.right(), value.bottom()), (0, 255, 0), 2)
#进行人脸识别并打上姓名标签
# 提取特征-图像中的68个关键点转换为128D面部描述符,其中同一人的图片被映射到彼此附近,并且不同人的图片被远离地映射。
face_descriptor = facerec.compute_face_descriptor(frame, shape)
#视频中这个人的特征向量
v = np.array(face_descriptor)
#l = len(descriptors)
flag=0
for j in range(Flen):
# 人脸匹配,距离小于阈值,表示识别成功,打上标签
if(compute_dst(v,face_feature_array[j])<0.56):
flag=1
cv2.putText(frame,'Attention',(value.left(), value.top()),cv2.FONT_HERSHEY_COMPLEX,0.8, (0, 255, 255), 1, cv2.LINE_AA)
count=count+1
dict[j]+=[frame_count]
print('目标人物第%d次出现'%count)
break
if(flag==0):
cv2.putText(frame,"Unknonw", (value.left(), value.top()), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 1,
cv2.LINE_AA)
#标记关键点
for pti,pt in enumerate(shape.parts()):
pos=(pt.x,pt.y)
cv2.circle(frame, pos, 1, color=(0, 255, 0))
#faces.append(frame)
cv2.imshow("Face Recognition", frame) # 在窗口中显示
exitKey= cv2.waitKey(1)
if exitKey == 27:
video.release()
video_writer.release()
cv2.destroyWindow("Face Recognition")
break
video_writer.write(frame)
ret,frame = video.read()
i += 1分类输出统计信息:
if Flen>1:
print('总时长')
print(duration)
print('总帧数')
print(frame_count)
print('人物所在帧')
print(dict)
print('对应出现时间')
for i in dict:
for j in range(len(dict[i])):
dict[i][j] = dict[i][j] / frame_count * duration
print(dict)
else:
print("目标人物出现次数%d" % count)
二.效果
2.1人脸库建立
这次使用和上次同一个视频,将两个主人公都当作检测对象,对应人脸库:

两个人物的特征向量:

2.2人物关系生成
这次两个人都作为目标人物
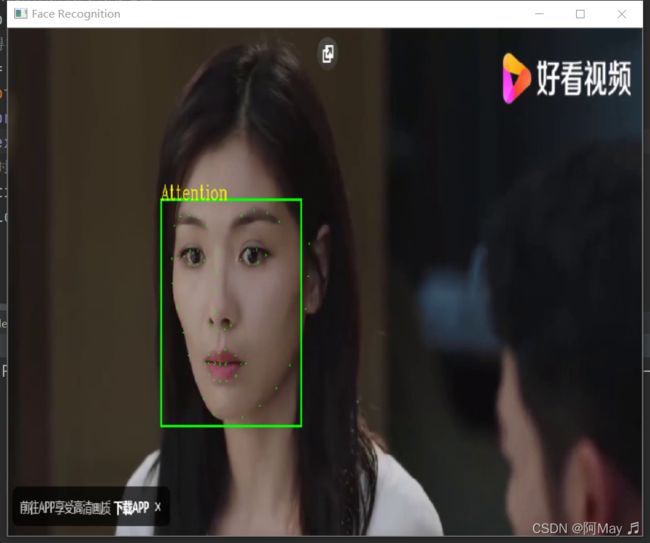

检测过程记录:
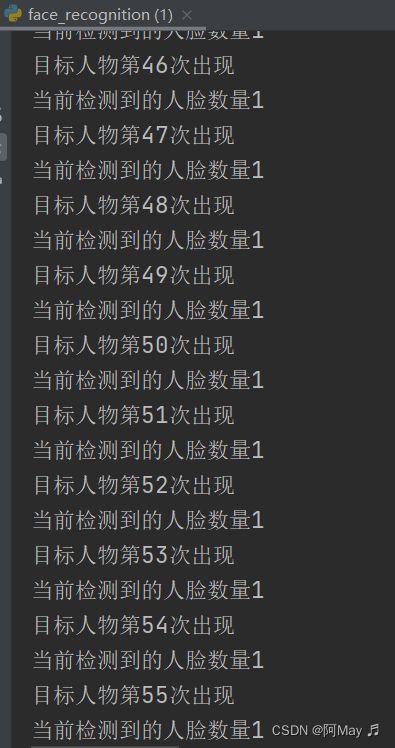
结果输出:
以字典方式呈现,记录每个人物出现的时间点:
