ARM汇编【2】:LOAD 和 STORE
ARM使用load-store指令进行内存访问,这意味着只有LDR和STR指令才能访问内存,虽然在X86上,大多数指令都可以对内存中的数据进行操作,但在ARM上,数据在进行操作之前必须从内存移动到寄存器中。这意味着,在ARM上的特定内存地址增加32位值需要三种指令(加载、增量和存储)才能首先将特定的地址的值加载到寄存器中,在寄存器中递增,然后将其从寄存器存储回内存。
汇编程序例子:
.data /* the .data section is dynamically created and its addresses cannot be easily predicted */
var1: .word 3 /* variable 1 in memory */
var2: .word 4 /* variable 2 in memory */
.text /* start of the text (code) section */
.global _start
_start:
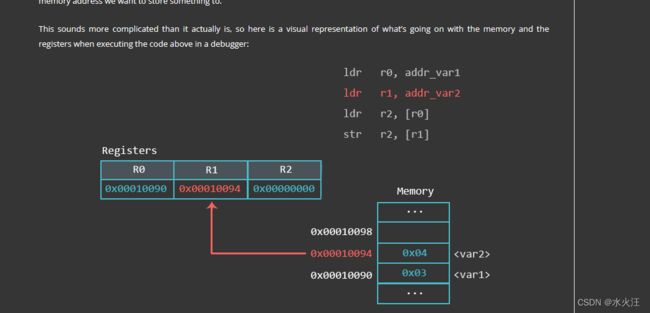
ldr r0, adr_var1 @ load the memory address of var1 via label adr_var1 into R0
ldr r1, adr_var2 @ load the memory address of var2 via label adr_var2 into R1
ldr r2, [r0] @ load the value (0x03) at memory address found in R0 to register R2
str r2, [r1] @ store the value found in R2 (0x03) to the memory address found in R1
bkpt
adr_var1: .word var1 /* address to var1 stored here */
adr_var2: .word var2 /* address to var2 stored here */在底部,我们有我们的Literal Pool(同一代码段中的一个内存区域,用于存储常量、字符串或偏移量,其他人可以以独立于位置的方式引用),在这里,我们使用标签adr_var1和adr_var2存储var1和var2的内存地址(在顶部的数据段中定义)。第一个LDR将var1的地址加载到寄存器R0中。第二个LDR对var2执行相同的操作,并将其加载到R1。然后,我们将存储在R0中找到的存储器地址处的值加载到R2,并将在R2中找到的值存储到在R1中找到的存储地址。
当我们将某个东西加载到寄存器中时,括号([])的意思是:在这些括号之间的寄存器中找到的值是我们想要从中加载某个东西的内存地址。
当我们将东西存储到内存位置时,括号([])的意思是:在这些括号之间的寄存器中找到的值是我们想要存储东西的内存地址。
现在具体分析下上面ldr 和str 四行汇编代码,在内存中和寄存器中的体现:
ldr r0, adr_var1

ldr r1, adr_var2
 标题
标题
ldr r2, [r0]

str r2, [r1]

我们在前两个LDR操作中指定的标签更改为[pc,#12]。这被称为PC相对寻址。因为我们使用了标签,编译器计算了我们在Literal Pool(PC+12)中指定的值的位置。你可以使用这种精确的方法自己计算位置,也可以像我们以前那样使用标签。唯一的区别是,您不需要使用标签,而是需要计算值在Literal Pool中的确切位置。在这种情况下,它距离有效PC位置有3跳(4+4+4=12)。本章稍后将介绍有关PC相对寻址的更多信息。 
偏移形式:立即值作为偏移
STR Ra, [Rb, imm]
LDR Ra, [Rc, imm]这里我们使用立即数(整数)作为偏移量。该值从基址寄存器(以下示例中的R1)中添加或减去,以在编译时以已知的偏移量访问数据。
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ load the memory address of var1 via label adr_var1 into R0
ldr r1, adr_var2 @ load the memory address of var2 via label adr_var2 into R1
ldr r2, [r0] @ load the value (0x03) at memory address found in R0 to register R2
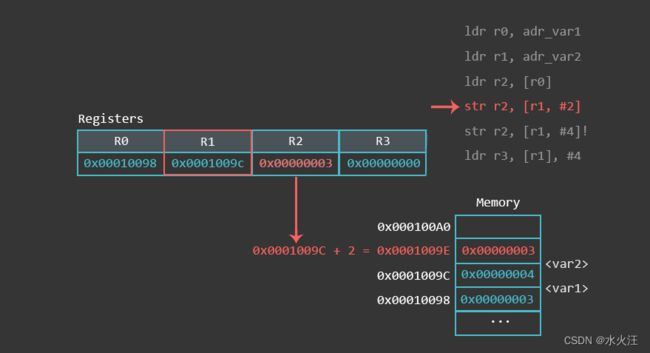
str r2, [r1, #2] @ address mode: offset. Store the value found in R2 (0x03) to the memory address found in R1 plus 2. Base register (R1) unmodified.
str r2, [r1, #4]! @ address mode: pre-indexed. Store the value found in R2 (0x03) to the memory address found in R1 plus 4. Base register (R1) modified: R1 = R1+4
ldr r3, [r1], #4 @ address mode: post-indexed. Load the value at memory address found in R1 to register R3. Base register (R1) modified: R1 = R1+4
bkpt
adr_var1: .word var1
adr_var2: .word var2让我们调用这个程序ldr.s,编译它并在GDB中运行它,看看会发生什么。
$ as ldr.s -o ldr.o
$ ld ldr.o -o ldr
$ gdb ldr在GDB(使用gef)中,我们在_start处设置一个断点并运行程序。
gef> break _start
gef> run
...
gef> nexti 3 /* to run the next 3 instructions */我的系统上的寄存器现在填充了以下值(请记住,这些地址在您的系统上可能不同):
$r0 : 0x00010098 -> 0x00000003
$r1 : 0x0001009c -> 0x00000004
$r2 : 0x00000003
$r3 : 0x00000000
$r4 : 0x00000000
$r5 : 0x00000000
$r6 : 0x00000000
$r7 : 0x00000000
$r8 : 0x00000000
$r9 : 0x00000000
$r10 : 0x00000000
$r11 : 0x00000000
$r12 : 0x00000000
$sp : 0xbefff7e0 -> 0x00000001
$lr : 0x00000000
$pc : 0x00010080 -> <_start+12> str r2, [r1]
$cpsr : 0x00000010将执行的下一条指令是具有偏移地址模式的STR操作。它将存储从R2(0x00000003)到R1中指定的存储器地址的值(0x0001009c)+偏移量(#2)=0x1009e。
gef> nexti
gef> x/w 0x1009e
0x1009e : 0x3 下一个STR操作使用预索引地址模式。你可以通过感叹号(!)来识别这种模式。唯一的区别是基址寄存器将被更新为存储R2值的最终存储器地址。这意味着,我们将在R2(0x3)中找到的值存储到R1(0x1009c)中指定的内存地址+偏移量(#4)=0x100A0,并用这个确切的地址更新R1。
gef> nexti
gef> x/w 0x100A0
0x100a0: 0x3
gef> info register r1
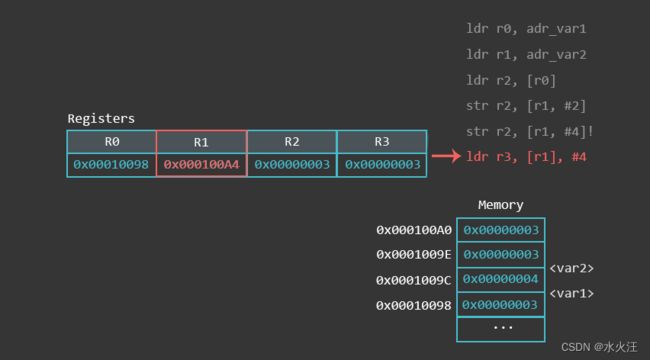
r1 0x100a0 65696最后一个LDR操作使用后索引地址模式。这意味着基址寄存器(R1)被用作最终地址,然后用R1+4计算的偏移量进行更新。换句话说,它取在R1(而不是R1+4)中找到的值,即0x100A0,并将其加载到R3,然后将R1更新为R1(0x100A0)+偏移量(#4)=0x100a4。
gef> info register r1
r1 0x100a4 65700
gef> info register r3
r3 0x3 3以下是汇编语句的执行效果:
str r2, [r1, #2]
str r2, [r1, #4]!


ldr r3, [r1], #4

偏移形式:缩放寄存器作为偏移
LDR Ra, [Rb, Rc, ]
STR Ra, [Rb, Rc, ] 第三种偏移形式具有一个缩放寄存器作为偏移。在这种情况下,Rb是基址寄存器,Rc是左/右移位(<shifter>)以缩放立即数的立即数偏移(或包含立即数值的寄存器)。这意味着桶形移位器用于缩放偏移。这种偏移量形式的一个示例用法是循环在数组上迭代。下面是一个可以在GDB中运行的简单示例:
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ load the memory address of var1 via label adr_var1 to R0
ldr r1, adr_var2 @ load the memory address of var2 via label adr_var2 to R1
ldr r2, [r0] @ load the value (0x03) at memory address found in R0 to R2
str r2, [r1, r2, LSL#2] @ address mode: offset. Store the value found in R2 (0x03) to the memory address found in R1 with the offset R2 left-shifted by 2. Base register (R1) unmodified.
str r2, [r1, r2, LSL#2]! @ address mode: pre-indexed. Store the value found in R2 (0x03) to the memory address found in R1 with the offset R2 left-shifted by 2. Base register modified: R1 = R1 + R2<<2
ldr r3, [r1], r2, LSL#2 @ address mode: post-indexed. Load value at memory address found in R1 to the register R3. Then modifiy base register: R1 = R1 + R2<<2
bkpt
adr_var1: .word var1
adr_var2: .word var2第一个STR操作使用偏移地址模式,并将R2中找到的值存储在根据[r1,R2,LSL#2]计算的内存位置,这意味着它以r1中的值为基数(在这种情况下,r1包含var2的内存地址),然后取R2中的值(0x3),并将其左移2。下面的图片试图可视化如何使用[r1,r2,LSL#2]计算内存位置。

第二个STR操作使用预索引地址模式。这意味着,它执行与先前操作相同的操作,不同之处在于,它随后用计算出的存储器地址更新基址寄存器R1。换句话说,它将首先存储在存储器地址R1(0x1009c)+左移#2的偏移量(0x03 LSL#2=0xC)=0x100a8处找到的值,并用0x100a8。
gef> info register r1
r1 0x100a8 65704最后一个LDR操作使用后索引地址模式。这意味着,它将在R1中找到的存储器地址处的值(0x100a8)加载到寄存器R3中,然后用r2、LSL#2计算的值更新基址寄存器R1。换句话说,R1被更新为值R1(0x100a8)+偏移R2(0x3)左移#2(0xC)=0x100b4。
gef> info register r1
r1 0x100b4 65716用于PC相关寻址的LDR
.section .text
.global _start
_start:
ldr r0, =jump /* load the address of the function label jump into R0 */
ldr r1, =0x68DB00AD /* load the value 0x68DB00AD into R1 */
jump:
ldr r2, =511 /* load the value 511 into R2 */
bkpt在ARM上使用立即数
在ARM上的寄存器中加载立即数并不像在x86上那样简单。您可以使用哪些直接值是有限制的。这些限制是什么以及如何处理它们并不是ARM组装中最令人兴奋的部分,但请记住,这只是为了让你理解,你可以使用一些技巧来绕过这些限制(提示:LDR)。
我们知道每个ARM指令都是32位长的,并且所有指令都是有条件的。我们可以使用16个条件码,其中一个条件码占用指令的4位。然后我们需要2位作为目标寄存器。2位用于第一个操作数寄存器,1位用于设置状态标志,加上用于其他事项(如实际操作码)的各种位数。这里的重点是,在将位分配给指令类型、寄存器和其他字段之后,立即值只剩下12位,这将只允许4096个不同的值。
这意味着ARM指令只能直接与MOV一起使用有限范围的立即值。如果一个数字不能直接使用,则必须将其拆分为多个部分,并将多个较小的数字拼凑在一起。
但还有更多。不是将12位作为单个整数,而是将这12位拆分为能够加载0-255范围内的任何8位值的8位数字(n)和在0和30之间以2为步长进行右旋转的4位旋转字段(r)。这意味着全立即值v由公式给出:v=n或2*r。换句话说,唯一有效的立即数值是旋转的字节(可以减少为按偶数旋转的字节的值)。
以下是一些有效和无效立即值的示例:
Valid values:
#256 // 1 ror 24 --> 256
#384 // 6 ror 26 --> 384
#484 // 121 ror 30 --> 484
#16384 // 1 ror 18 --> 16384
#2030043136 // 121 ror 8 --> 2030043136
#0x06000000 // 6 ror 8 --> 100663296 (0x06000000 in hex)
Invalid values:
#370 // 185 ror 31 --> 31 is not in range (0 – 30)
#511 // 1 1111 1111 --> bit-pattern can’t fit into one byte
#0x06010000 // 1 1000 0001.. --> bit-pattern can’t fit into one byte这样做的结果是不可能一次加载完整的32位地址。我们可以通过使用以下两个选项之一来绕过此限制:
用较小的部分构建更大的价值
代替使用MOV r0,#511
将511拆分为两部分:MOV r0,#256和ADD r0,#255
使用一个加载构造“ldr r1,=value”,汇编程序会很乐意将其转换为MOV,或者如果不可能,则转换为PC相对加载。
LDR r1,=511
如果您试图加载一个无效的立即数,汇编程序将报告并输出一个错误:错误:无效常量。如果你遇到这个错误,你现在知道它意味着什么以及该怎么办了。
假设您想将#511加载到R0中。
.section .text
.global _start
_start:
mov r0, #511
bkpt如果您试图汇编此代码,汇编程序将抛出一个错误:
azeria@labs:~$ as test.s -o test.o
test.s: Assembler messages:
test.s:5: Error: invalid constant (1ff) after fixup您需要将511拆分为多个部分,或者像我之前描述的那样使用LDR。
.section .text
.global _start
_start:
mov r0, #256 /* 1 ror 24 = 256, so it's valid */
add r0, #255 /* 255 ror 0 = 255, valid. r0 = 256 + 255 = 511 */
ldr r1, =511 /* load 511 from the literal pool using LDR */
bkpt如果你需要弄清楚某个数字是否可以用作有效的立即值,你不需要自己计算。您可以使用我的小python脚本rotator.py,它将您的数字作为输入,并告诉您是否可以将其用作有效的立即数。
from __future__ import print_function # PEP 3105
import sys
# Rotate right: 0b1001 --> 0b1100
ror = lambda val, r_bits, max_bits: \
((val & (2**max_bits-1)) >> r_bits%max_bits) | \
(val << (max_bits-(r_bits%max_bits)) & (2**max_bits-1))
max_bits = 32
input = int(raw_input("Enter the value you want to check: "))
print()
for n in xrange(1, 256):
for i in xrange(0, 31, 2):
rotated = ror(n, i, max_bits)
if(rotated == input):
print("The number %i can be used as a valid immediate number." % input)
print("%i ror %x --> %s" % (n, int(str(i), 16), rotated))
print()
sys.exit()
else:
print("Sorry, %i cannot be used as an immediate number and has to be split." % input)azeria@labs:~$ python rotator.py
Enter the value you want to check: 511
Sorry, 511 cannot be used as an immediate number and has to be split.
azeria@labs:~$ python rotator.py
Enter the value you want to check: 256
The number 256 can be used as a valid immediate number.
1 ror 24 --> 256