WTF Langchain极简入门: 03. 数据连接
加载文档
langchain提供多种文档加载器,支持多种格式、来源的文件。可以从本地存储系统加载文件,也可以从网上加载远端文件。想了解LangChain所支持的所有文档加载器,请参考Document Loaders。
在本系列课程中,我们将使用最基本的TextLoader来加载本地文件系统中的文档。
代码如下:
# 从langchain.document_loader文件中导入文件加载类TextLoder
from langchain.document_loaders import TextLoader
# TextLoader加载"./README.md",实例化loader对象
loader = TextLoader("./README.md")
# loader调用load方法生成一个Document类型的文件doc
doc = loader.load()
docs使用TextLoader加载"./README.md"文件,调用TextLoader的load函数生成一个Document对象数组。Document是langchain中的文档类,存放原始内容和元数据,还可以通过Document类的content属性访问原内容。
拆分文档
拆分文档是最常见的文档转换操作。拆分文档将文档拆分为更小的文档块,为了更好地利用模型。
在基于长篇文本的问答(QA)系统中, 必须将文本拆分为多个文本块,这样才能在数据搜索中,基于文本相似性匹配到与问题最相近的文本块。这也是常见的AI问答机器人的基本工作原理。
langchain提供多种文档拆分器,将文档拆分为更小的文档块。
按字符拆分
langchain中最基础的文档拆分器——CharacterTextSplitter,它将文档拆分为固定长度文本块。
# 从langchain.text_splitter中导入CharacterTextSplitter类
from langchain.text_splitter import CharacterTextSplitter
# CharacterTextSplitter实例化对象text_splitter
# 参数separator是分割符,chunk_size是切块大小,chunk_overlap是块与块重叠部分
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)
# text_splitter调用split_documents处理docs文件
split_docs = text_splitter.split_documents(docs)
print(len(docs[0].page_content))
for split_doc in split_docs:
print(len(split_doc.page_content))应该看到下面的输出
3316
996
963
864
913
296
拆分代码
RecursiveCharacterTextSplitter的from_language函数,能够根据编程语言的特性,将代码分为恰当的文本块。
# 写python代码hello_chain
PYTHON_CODE = """
def hello_langchain():
print("Hello, LangChain!")
# Call the function
hello_langchain()
"""
# 导入RecursiveCharacterTextSplitter文本分块类
from langchain.text_splitter import RecursiveCharacterTextSplitter,Language
# 实例化python_splitter。
# RecursiveCharacterTextSplitter的from_language方法识别Python代码
python_splitter = RecursiveCharacterTextSplitter.from_language(
language = Language.PYTHON, chunk_size = 50, chunk_overlap = 0,
)
# create_documents对PYTHON_CODE切块
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs应该看到下面这个输出
[Document(page_content='def hello_langchain():', metadata={}), Document(page_content='print("Hello, LangChain!")', metadata={}),
Document(page_content='# Call the function\nhello_langchain()', metadata={})]
Markdown文件拆分
MarkdownHeaderTextSplitter能够将Markdown文件按照段落结构,基于Markdowm语法进行文本拆分。代码如下
# 从langchain.text_splitter导入MarkdownHeaderTextSplitter类
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 设置mark_document文件
markdown_document = "# Chapter 1\n\n ## Section 1\n\nHi this is the 1st section\n\nWelcome\n\n ### Module 1 \n\n Hi this is the first module \n\n ## Section 2\n\n Hi this is the 2nd section"
# 设置切分参数
headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3")]
# MarkdownHeaderTextSplitter类实例化splitter对象
splitter = MarkdownHeaderTextSplitter(headers_to_split_on = headers_to_split_on)
# splitter调用split_text方法切分Markdown文件,生成splits
splits = splitter.split_text(markdown_document)
# 显示splits
splits应该能看到下面这个输出
[Document(page_content='Hi this is the 1st section \nWelcome', metadata={'Header 1': 'Chapter 1', 'Header 2': 'Section 1'}), Document(page_content='Hi this is the first module', metadata={'Header 1': 'Chapter 1', 'Header 2': 'Section 1', 'Header 3': 'Module 1'}), Document(page_content='Hi this is the 2nd section', metadata={'Header 1': 'Chapter 1', 'Header 2': 'Section 2'})]
按字符递归拆分
这是常见的一种拆分方式,使用拆分符号不断拆分文本,尽量使文本尺寸减小。默认的参数是["\n\n","\n",","],它尽可能保证语义的完整性,保持段落、句子、单词的完整。
# 导入RecursiveCharacterTextSplitter类
from langchain.text_splitter import RecursiveCharacterTextSplitter
# RecursiveCharacterTextSplitter实例化text_splitter对象
# 设置初始化参数
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
# text_splitter切分器调用split_documents方法切分docs文件
doc = text_splitter.split_documents(docs)
doc按token拆分
一些语言模型,在API的使用过程中,交互时都有token数的限制。可见,拆分文本时,按照token数目拆分也是不错的方法。目前有许多token化工具,在统计文本token数时,请使用对应的token化工具。
注:OpenAI所使用的是tiktoken。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size = 100, chunk_overlap = 20)
doc = text_splitter.split_documents(docs)
doc向量化文档
langchain框架中的embeddings类,是与文本嵌入模型的进行交互地标准接口。当前有许多文本嵌入模型,如如OpenAI、Cohere、Hugging Face等,本文选用的是OpenAI的嵌入模型,也可以使用其他的模型。
嵌入模型对文本进行向量化,这种转化能够在向量空间中处理文本,通过向量空间的相似性,进行文本语义的搜索。
注:文本的相似性常由其向量表示的欧几里得距离来衡量,也称第二范式。对于n维的两个向量a,b,欧几里得距离可通过以下公式计算:
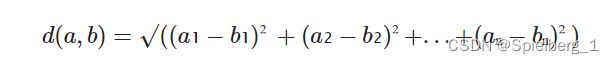
我们使用如下代码来创建文本片段的向量表示:
# 导入OpenAIEmbeddings类
from langchain.embeddings import OpenAIEmbeddings
# 实例化embeddings_model对象
embeddings_model = OpenAIEmbeddings(openai_api_key = "您的openai_api_key")
# embeddings_model调用embed_documents方法对文本向量化
embeddings = embeddings_model.embed_documents(
["你好",
"Langchain",
"你真棒"
])
embeddings您应该看到类似的输出
[[0.001767348474591444,
-0.016549955833298362,
0.009669921232251705,
-0.024465152668289573,
-0.04928377577655549,
...],
[...
-0.026084684286027195,
-0.0023797790465254626,
0.006104789779720747,
...]]
向量数据存储
langchain支持多种向量存储,如Chroma, FAISS, Pinecone等。本文以Chroma为例
langchain框架提供Chroma包装类,封装了chromadb的操作。
需要先安装Chroma
pip install -q chromadb接下来进行数据存储
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 下载README.md
!wget https://raw.githubusercontent.com/WTFAcademy/WTF-Langchain/main/01_Hello_Langchain/README.md
# TextLoader实例化对象loader,加载README.md生成docs文件
loader = TextLoader("./README.md")
docs = loader.load()
# 切分docs文件为documents
text_splitter = CharacterTextSplitter(
chunk_size = 1000, chunk_overlap = 0)
documents = text_splitter.split_documents(docs)
# 实例化嵌入模型
embedding_model = OpenAIEmbeddings(openai_api_key = "您的openai_api_key")
# 存储向量化文本
db = Chroma.from_documents(documents, embedding_model)
db检索
向量数据库最常用来查询给定文本的相似文本,通过similarity_search方法来获取。
query = " 什么是 WTF langchain"
docs = db.similarity_search(query)
docs
docs = db.similarity_search_with_score(query)
docs总结:
本文我们学习了Langchain的数据连接部分
1.数据的加载
2.数据的切分
3.数据的嵌入向量化
4.数据的向量化存储以及查询