整理mongodb文档:聚合管道
个人博客
整理mongodb文档:聚合管道
个人博客,求关注,电脑版看体验更加,如果不够清晰,请指出来,谢谢
文章概叙
文章主要通过几个常用的聚合表达式来介绍聚合管道的使用,以及从索引的角度来介绍聚合管道的限制,让大家对聚合管道有一个理解。
聚合管道
聚合操作处理数据记录和 return 计算结果。聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回单个结果。
如果说,索引能帮我们解决查得慢的问题,那么聚合就能帮我们解决查得复杂的问题。使用聚合管道,就是为了解决复杂的sql的问题,尤其是涉及到多个表的、复杂的查询。
聚合表达式
聚合表达式是我们整个聚合管道学习的核心,其中使用的aggregate方法,就是我们用来做聚合操作的工具。
aggregate的使用方式如下:
db.test.aggregate()
接下来举一个博客网站留评论的例子,给大家讲解下几个常用的表达式,看完例子,对于aggragate也能熟悉。
假设有如下两张表,article表示文章,comment表示评论。
在article表中,存储着代表一篇博客的信息,内容如下:

在代表文章的article表中,我们用"article_id"作为文章的唯一标识,不使用默认的"_id"。其中的"can_comment"字段表示该博客是否允许评论。
现在的业务逻辑如下:当我们后台接收到前端的新增评论的请求时,我们需要在comment表中新增一条评论。
正常的情况下,我们会去用find方法去article表中查询是否有满足可以评论的数据,再用insertOne去comment表中新增一条记录,整体看下来至少需要两个sql。但使用聚合管道则只需要一个sql就可以做到同样的事情。所以遇到相似的业务的时候,基本都会选择使用aggregate来完成我们的业务。
接下来,使用aggregate来实现我们上述两步的逻辑。
使用"$match"从article表中查看是否有符合条件的记录。
过滤文档流以仅允许匹配的文档未经修改地传递到下一个管道阶段。 $match使用标准的 MongoDB
查询。对于每个输入文档,输出一个文档(匹配)或零文档(不匹配)。
db
.article
.aggregate([
{
"$match": {
"can_comment": true,
"article_id":'1'
}
}
])
返回结果如下,筛选出了我们选中的记录
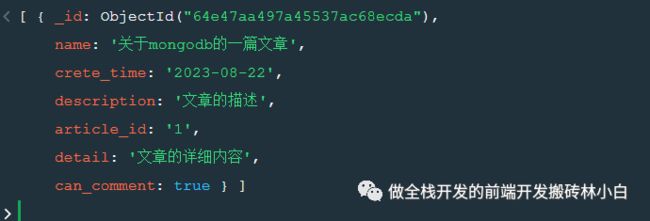
2.在第一步中我们得到了一个数组对象,但是我们只需要一个文章的id,此时可以使用"$project"对字段进行保留跟丢弃,下方的例子,就直接保留article_id以及删除
重新整形流中的每个文档,例如添加新字段或删除现有字段。对于每个输入文档,输出一个文档。 有关删除现有字段,请参见$unset。
db
.article
.aggregate([
{
"$match": {
"can_comment": true,
"article_id": '1'
}
},
{
"$project": {
"article_id": 1,
"_id": 0
}
}
])

3.我们需要将整理出来的数据放到comment表中,但是我们需要用"$addFields"来增加评论内容的字段
向文档添加新字段。类似于 p r o j e c t , project, project,addFields重塑了流中的每个文档;具体而言,通过向输出文档添加新字段,该文档包含输入文档和新添加字段中的现有字段。
s e t 是 set是 set是addFields的别名。
添加了comment之后的sql如下:
db
.article
.aggregate([
{
"$match": {
"can_comment": true,
"article_id": '1'
}
},
{
"$project": {
"article_id": 1,
"_id": 0
}
},
{
"$set": {
"comment": "文章的评论",
"commentator": 'mk',
"comment_time":"2023-08-22 18:00:00"
}
}
])
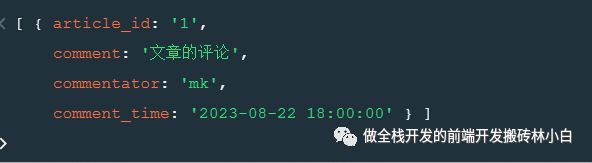
此时,数据整理完毕,我们需要用到"$merge"方法将其写入到comment表中了
将聚合管道的结果文档写入集合。这个阶段可以将结果合并到一个输出集合中(插入新文档、合并文档、替换文档、保留现有文档、操作失败、使用自定义更新管道处理文档)。要使用$merge阶段,它必须是管道中的最后一个阶段。version 4.2 中的新功能
db
.article
.aggregate([
{
"$match": {
"can_comment": true,
"article_id": '1'
}
},
{
"$project": {
"article_id": 1,
"_id": 0
}
},
{
"$set": {
"comment": "文章的评论",
"commentator": 'mk',
"comment_time": "2023-08-22 18:00:00"
}
}, {
"$merge": {
"into": 'comment'
}
}
])
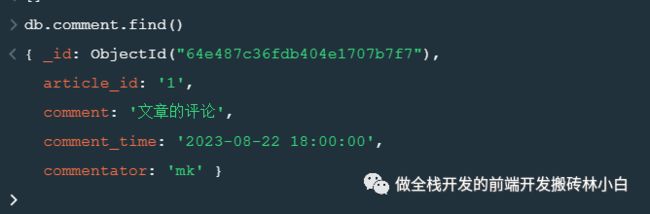
当然,上述的代码是建立在自己article表中有该条数据的情况下,接下来贴一张在article表中查询没有数据时候的运行结果

可以看到,由于在article表中查不到数据,所以后续的操作都被取消了。
聚合管道限制
聚合管道能满足我们许多复杂的需求,能让我们在db层就将我们的数据整理好,而不是通过一个又一个find方法去查询索引能帮我们快速的查询。而聚合能帮我们做复杂的数据。因此我们需要处理好索引跟聚合管道的关系,防止顾此失彼。
举一个例子,在一个集合中,使用"$facet"起一个别名作为数据
在同一组输入文档的单个阶段内处理多个聚合管道。允许创建能够在单个阶段中跨多个维度或方面描述数据的多面聚合。
db
.article
.aggregate([
{
"$facet": {
"article_list": [{
"$match": {
"can_comment": true
}
}]
}
}
])
该例子直接去article表中查询能够评论的文章,然后将其赋名为article_list。结果如下:

此时,我们使用explain查看查询的状态,看看是否使用到了索引。
db
.article
.aggregate([
{
"$facet": {
"article_list": [{
"$match": {
"can_comment": true
}
}]
}
}
]).explain("executionStats")
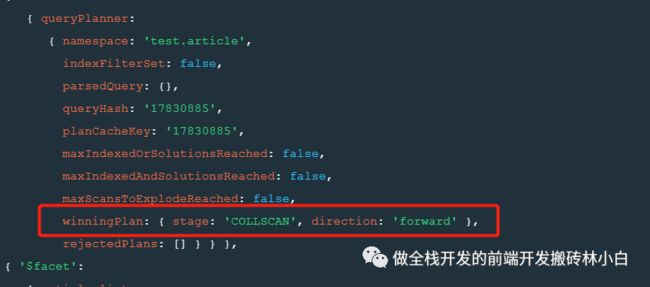
但是如果直接使用"$match"呢?
db
.article
.aggregate([{
"$match": {
"can_comment": true
}
}
]).explain()
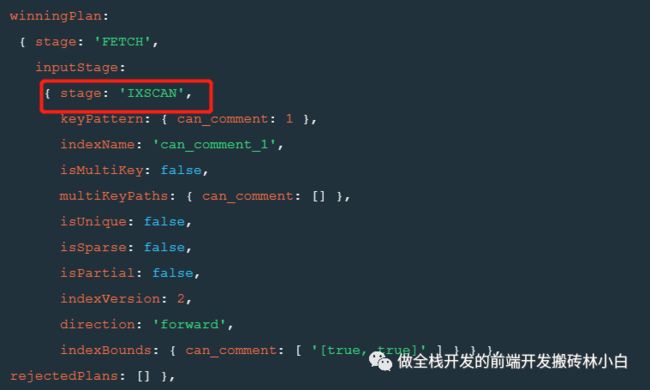
可以看到,当我们使用"$facet"在最外围的时候,是不使用index查询的,就会导致很慢,而我们直接使用"$match"的时候,使用索引就会让查询时间大大的优化。
其他例子还有很多,这儿只是举个例子,如果出现了查询缓慢的情况,我建议使用explain看下运行结果。
allowDiskUse
必须要提一嘴的是关于16mb的内存,前面提及到了aggregate会将数据整理完返回给我们的后台,但是很多时候会报错,显示内存超过16MB,这是可以设置allowDiskUse为true。当前的代码是在shell中使用,建议大家自己去官网下查看。
单用途聚合操作
单用途聚合操作顾名思义,指的是用途单一的聚合管道,主要包括下面三种计数的方法,但是了解了之后会发现基本都是用来统计数量的,现在列举如下
1.estimatedDocumentCount
统计文档总数,返回集合或视图中所有文档的计数。该方法包装count命令。
db.test.estimatedDocumentCount()
2.count
也是一种计数的方式,但是可以添加条件,使用方法如下
db.test.count()
db.test.count({string:'a'})
3.distinct
查询不同值,并返回一个数组,包含所有的结果
db.test.distinct('string')

最后的话
本文章不会详细介绍每一个表达式的优缺点,只会告诉大家要注意的点,最常用的表达式会后面再写。毕竟框架搭建好了,添砖加瓦的事情可以慢慢来,aggregate的难度不大,就跟积木一样,不断的组装,完成我们的需求