人脸检测Retinaface算法原理详解
论文:RetinaFace: Single-stage Dense Face Localisation in the Wild
代码:official Implemented by mxnet detection/retinaface
代码:unofficial implemented by toch
RetinaFaces是一个单阶段人脸检测SOTA模型,被CVPR 2020 所接收。在前一篇文章 SSD目标检测算法详解 中,我们介绍了SSD算法的基本原理,本文虽然是人脸检测,但是其中的原理很大一部分与SSD算法都是相同的。本文通过对RetinaFace的原理和代码进行详细介绍,一方面来了解人脸检测的算法,另一方面进一步加深对SSD算法的理解。
1. RetinaFace算法原理
RetinaFace的主要贡献如下:
-
在single-stage设计的基础上,提出了一种新的基于像素级的人脸定位方法RetinaFace,该方法采用多任务学习策略,同时预测人脸评分、人脸框、五个人脸关键点以及每个人脸像素的三维位置和对应关系。
-
在WILDER FACE HARD子集上,RetinaFace的性能比目前 SOTA 的 two-stage 方法(ISRN)的AP高出1.1% (AP等于91.4%)。
-
在IJB-C数据集上,RetinaFace有助于提高ArcFace的验证精度(FAR=1e-6时TAR等于89:59%),这表明更好的人脸定位可以显著提高人脸识别。
-
通过使用轻量级backbone网络(mobieNet),RetinaFace可以在VGA分辨率的图片上实时运行
1.1 数据集介绍
Retina Face主要使用了WIDER FACE数据集,该数据集包含32203个图像和393703个人脸框,图像的尺度, 姿态,表情,遮挡和光照变化都很大。WIDER FACE数据集被分为训练40% 验证10% 和测试50%三个子集,通过在61个场景分类中随机采样。基于EdgeBox的检测率,然后通过递增合并难样本,整个数据集分为分为3级:容易,中性和困难。
此外RetinaFace团队还进行了额外标注:依据人脸关键点标注困难程度定义的5个人脸质量级别,并且标注5个关键点(眼睛中心2,鼻尖1,嘴角2)。总共标注了84.6k个训练集人脸和18.5k个验证集人脸。标注的样式如下图所示

1.2 网络结构
RetinaFace整体结构如下图所示。主要分为三个部分:特征金字塔、上下文模块、损失模块
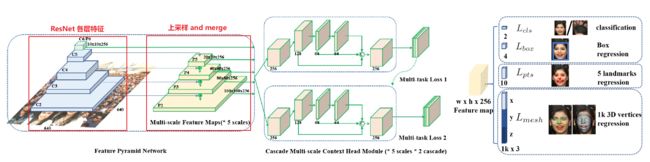
特征金字塔
- 在特征金字塔左半边自底向上的部分就是普通的特征提取网络,特征分辨率不断缩小,特征提取网络可以换成任意Backbone,以ResNet为例,选取conv2、conv3、conv4、conv5层的最后一个残差block层特征作为FPN的特征,注意最上层C6是C5通过一个3x3,s=2的卷积得到。
- 特征金字塔右半边自顶向下的部分是一个上采样过程。从C6层开始上采样,将C6上采样到和C5尺寸相同后并与C5相加得到P5,然后将P5上采样到和C4同尺寸并和C4相加得到P4,依次这样下去
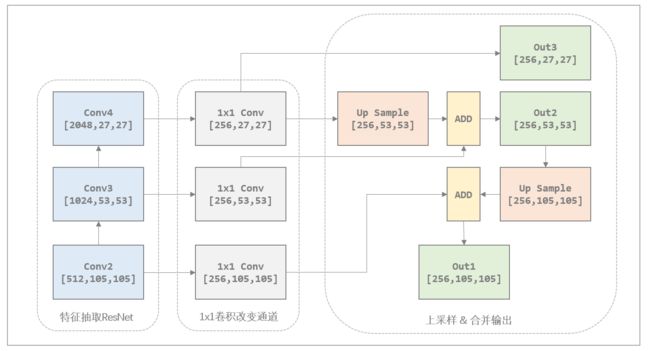
如下图所示,展示了从特征抽取到特征金字塔的整个过程,该图以抽取2,3,4层特征为例。在实际实现过程中会首先将抽取的特征层通过1x1卷积来改变通道数,然后上采样相加。
上下文模块SSH
作者通过引入卷积核尺寸较大的卷积层例如 5 × 5 5 \times 5 5×5 和 7 × 7 7 \times 7 7×7 的卷积核来增大感受野,从而引入更多的上下文信息。SSH模块如下图所示
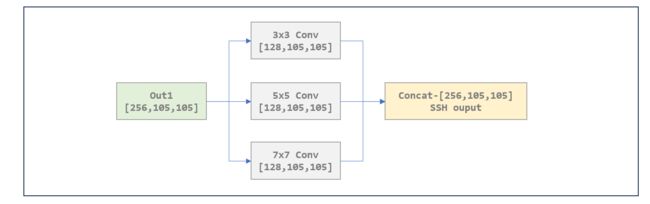
但为了减少计算量,作者借鉴了GoogleNet中用多个 3 × 3 3 \times 3 3×3 卷积代替 5 × 5 5 \times 5 5×5 卷积或者 7 × 7 7 \times 7 7×7卷积的做法,于是最终上下文模块的结构就如下图所示,Conv1 Conv2两个3x3卷积等价一个5x5卷积,Conv1 Conv2 Conv3 Conv4四个卷积串联输出等价一个7x7卷积。将特征金字塔模块输出的out1 out2 out3分别输入到SSH模块,得到三个特征输出。

然后使用SSH输出的三个特征层分别来预测BBOX,这三个特征就相当于我们在 SSD目标检测原理详解 中介绍的ResNet输出的特征层。后面的内容就和SSD目标检测原理详解 中类似,先在特征层上构建先验框,并将这些先验框坐标映射到原图中,然后通过先验框和ground truth框的IOU选择正负本,进行训练。
1.3 损失函数
RetinaFace损失函数如下所示,前两项和 SSD目标检测原理详解的损失函数类似,即:分类损失(确定框中是否为人脸),BBOX回归损失;此外还增加了关键点回归损失和Dense Regression分支带来的损失,这个分支就是将2D的人脸映射到3D模型上,再将3D模型解码为2D图片,然后计算经过了编解码的图片和原始图片的差别。
L = L c l s ( p i , p i ⋆ ) + λ 1 p i ⋆ L b o x ( t i , t i ⋆ ) + λ 2 p i ⋆ L p t s ( l i , l i ⋆ ) + λ 3 p i ⋆ L m e s h ( v i , v i ⋆ ) . \begin{array}{l}{{{\cal L}={\cal L}_{c l s}(p_{i},p_{i}^{\star})+\lambda_{1}p_{i}^{\star}{\cal L}_{b o x}(t_{i},t_{i}^{\star})}}{{+\,\lambda_{2}p_{i}^{\star}{\cal L}_{p t s}(l_{i},l_{i}^{\star})+\lambda_{3}p_{i}^{\star}{\cal L}_{m e s h}(v_{i},v_{i}^{\star}).}}\end{array} L=Lcls(pi,pi⋆)+λ1pi⋆Lbox(ti,ti⋆)+λ2pi⋆Lpts(li,li⋆)+λ3pi⋆Lmesh(vi,vi⋆).
其中 λ 1 , λ 2 , λ 3 \lambda_1,\lambda_2,\lambda_3 λ1,λ2,λ3取值分别为0.25,0.1,0.01,也即是说来自检测分支和关键点分支的损失权重更高,而Dense Regression分支的损失权重占比小。
2. RetinaFace源码解读
整个模型代码如下,即先从resnet中拿各层的特征,然后经过特征金字塔FPN,上下文模块SSH后进行分类、bbox回归、人脸关键点回归。
def forward(self,inputs):
# resnet中抽取特征
out = self.body(inputs)
# FPN
fpn = self.fpn(out)
# SSH
feature1 = self.ssh1(fpn[0])
feature2 = self.ssh2(fpn[1])
feature3 = self.ssh3(fpn[2])
features = [feature1, feature2, feature3]
bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1)
ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
if self.phase == 'train':
output = (bbox_regressions, classifications, ldm_regressions)
else:
output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
return output
下面我们来细说每个模块
- 特征金字塔
特征金字塔实现如下,先通过1x1卷积调整通道,然后进行上采样以及相加,最后输出三个特征
def forward(self, input):
# names = list(input.keys())
input = list(input.values())
# 1x1卷积调整通道
output1 = self.output1(input[0]) # input[0].shape=[2, 512, 105, 105] out1.shape=[2, 256, 105, 105]
output2 = self.output2(input[1]) # input[1].shape=[2, 1024, 53, 53] out2.shape=[2, 256, 53, 53]
output3 = self.output3(input[2]) # input[2].shape=[2, 2048, 27, 27] out2.shape=[2, 256, 27, 27]
# 上采样 and 相加
up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
output2 = output2 + up3
output2 = self.merge2(output2) # [2, 256, 53, 53]
up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
output1 = output1 + up2
output1 = self.merge1(output1) # [2, 256, 105, 105]
out = [output1, output2, output3]
return out
- SSH模块
SSH 模块如下所示,其中conv3x3 conv5x5_1 conv5x5_2 conv7x7_2 conv7x7_3 内部实现都是3x3卷积
def forward(self, input):
conv3X3 = self.conv3X3(input) # in.shape [2, 256, 105, 105] out.shape [2, 128, 105, 105]
conv5X5_1 = self.conv5X5_1(input) # [2, 64, 105, 105]
conv5X5 = self.conv5X5_2(conv5X5_1) # [2, 64, 105, 105]
conv7X7_2 = self.conv7X7_2(conv5X5_1) # [2, 64, 105, 105]
conv7X7 = self.conv7x7_3(conv7X7_2) # [2, 64, 105, 105]
out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1) # [2, 256, 105, 105]
out = F.relu(out)
return out
- 分类and回归
通过SSH层后我们得到三个特征层,对每个特征层,我们都要对其进行预测
(1)人脸分类
实现如下,每个像素点都有两个框,预测每个框是否包含人脸
def forward(self,x):
out = self.conv1x1(x) # x.shape=[2, 256, 105, 105] out.shape [2, 4, 105, 105]
out = out.permute(0,2,3,1).contiguous() # [2, 105, 105, 4]
return out.view(out.shape[0], -1, 2)
(2)bbox回归
bbox回归如下,每个像素点预测2个框,每个框包含4个坐标点
def forward(self,x):
out = self.conv1x1(x) # x.sahpe [2, 256, 105, 105] out.shape [2, 8, 105, 105]
out = out.permute(0,2,3,1).contiguous() # [2, 105, 105, 8]
return out.view(out.shape[0], -1, 4) # [2, 22050, 4] 共有22050个框每个框4个点
(3)landmark回归
landmark回归和bbox回归类似,每个像素点包含两个框,每个框预测5个人脸关键点
class LandmarkHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=3):
super(LandmarkHead,self).__init__()
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 10)
- 损失函数
最后就是计算损失函数了,损失函数计算的原理可参考 SSD目标检测原理详解 ,概括来说,首先要把大量的先验框和groundtruth计算IOU来确定正样本和负样本,然后使用正样本来算bbox和landmark回归损失;使用正样本和负样本计算分类损失。
def forward(self, predictions, priors, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
ground_truth (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, landm_data = predictions
priors = priors
num = loc_data.size(0)
num_priors = (priors.size(0))
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
landm_t = torch.Tensor(num, num_priors, 10)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :4].data
labels = targets[idx][:, -1].data
landms = targets[idx][:, 4:14].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels, landms, loc_t, conf_t, landm_t, idx)
if GPU:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
landm_t = landm_t.cuda()
zeros = torch.tensor(0).cuda()
# landm Loss (Smooth L1)
# Shape: [batch,num_priors,10]
pos1 = conf_t > zeros
num_pos_landm = pos1.long().sum(1, keepdim=True)
N1 = max(num_pos_landm.data.sum().float(), 1)
pos_idx1 = pos1.unsqueeze(pos1.dim()).expand_as(landm_data) # [2, 29126, 10]
landm_p = landm_data[pos_idx1].view(-1, 10) # [100, 10]
landm_t = landm_t[pos_idx1].view(-1, 10)
loss_landm = F.smooth_l1_loss(landm_p, landm_t, reduction='sum')
pos = conf_t != zeros
conf_t[pos] = 1
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c[pos.view(-1, 1)] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = max(num_pos.data.sum().float(), 1)
loss_l /= N
loss_c /= N
loss_landm /= N1
return loss_l, loss_c, loss_landm
关注微信公众号 funNLPer, 了解更多AI算法
3. 参考
- InsightFace力作:RetinaFace单阶段人脸检测器
- 为什么一个5x5的卷积核可以用两个3x3的卷积核代替,一个7x7的卷积核可以用三个的3x3卷积核代替