【多目标跟踪】Transtrack 单句翻译 耗时3天!!!
Transtrack:Multiple Object Tracking with Transformer[2021]
Abstract
n this work, we proposeTransTrack, a simple but ef-ficient scheme to solve the multiple object tracking prob-lems. TransTrack leverages the transformer architecture,which is an attention-based query-key mechanism. It ap-plies object features from the previous frame as a queryof the current frame and introduces a set of learned ob-ject queries to enable detecting new-coming objects. Itbuilds up a novel joint-detection-and-tracking paradigm byaccomplishing object detection and object association ina single shot, simplifying complicated multi-step settingsin tracking-by-detection methods. On MOT17 and MOT20benchmark, TransTrack achieves 74.5% and 64.5% MOTA,respectively, competitive to the state-of-the-art methods. Weexpect TransTrack to provide a novel perspective for mul-tiple object tracking
在这项工作中,我们提出了TransTrack,这是一个简单但有效的解决多目标跟踪问题的方案。TransTrack利用了transformer架构,这是一种基于注意力的查询密钥机制。它使用前一帧中的对象特征作为当前帧的查询,并引入一组学习的对象查询,以检测新的对象。它通过在单次拍摄中完成目标检测和目标关联,简化了检测方法跟踪中复杂的多步骤设置,建立了一种新的联合检测和跟踪范式。在MOT17和MOT20基准上,TransTrack分别实现了74.5%和64.5%的MOTA,与最先进的方法相比具有竞争力。Weexpect TransTrack为多目标跟踪提供了一个新颖的视角。
1. Introduction
Visual object tracking is a vital problem in many prac-tical applications, such as visual surveillance, public secu-rity, video analysis, and human-computer interaction. Ac-cording to the number of objects to track, the task of ob-ject tracking is divided intoSingle Object Tracking (SOT)andMultiple Object Tracking (MOT). In recent years, theemerging of deep siamese networks [3, 37, 20, 19] havemade great progress in solving SOT tasks. However, theexisting MOT methods are still suffering from the modelcomplexity and computational cost due to the multi-stagepipeline [50, 36, 43] as shown in Figure
视觉对象跟踪是许多实际应用中的一个重要问题,如视觉监控、公共安全、视频分析和人机交互。根据要跟踪的对象数量,对象跟踪任务分为单对象跟踪(SOT)和多对象跟踪(MOT)。近年来,深度连体网络的融合[3,37,20,19]在解决SOT任务方面取得了巨大进展。然而,如图所示,由于存在多阶段表线[50,36,43],现有的MOT方法仍然受到模型复杂性和计算成本的影响
A critical dilemma in many existing MOT solutions iswhen object detection and re-identification are performedseparately, they can not benefit each other. To tackle theproblem in MOT, a joint-detection-and-tracking frameworkis needed to share knowledge between detection and ob-ject association. By reviewing SOT solutions, we empha-size thatQuery-Keymechanism is promising in this direction. In existing works, the object target is the query and theimage regions are the keys as shown in Figure 1b. For thesame object, its feature in different frames is highly similar,which enables the query-key mechanism to output orderedobject sets. This inspiration should also be beneficial to theMOT task
在许多现有的MOT解决方案中,一个关键的困境是,当物体检测和重新识别分别进行时,它们不能相互受益。为了解决MOT中的问题,需要一个联合检测和跟踪框架来在检测和对象关联之间共享知识。通过回顾SOT解决方案,我们强调了Query Keymechanism在这方面的前景。在现有的工作中,对象目标是查询,图像区域是键,如图1b所示。对于同一个对象,它在不同帧中的特性高度相似,这使得查询键机制能够输出有序的对象集。这种启发也应该有利于MOT任务


However, merely transferring the vanilla query-keymechanism from SOT into the MOT task leads to poor per-formance, significantly causing much more false negatives.It is because when an new object comes into birth, there isno corresponding features for it. This defect causes severeobject missing, as shown in Figure 1c. So what is a suitablequery-key mechanism for MOT remains a critical question.A desirable solution should be able to well capture new-coming objects and propagate previously detected objectsto the following frames at the same time
然而,仅仅将普通的查询键机制从SOT转移到MOT任务中会导致性能不佳,从而导致更多的假阴性。这是因为当一个新对象诞生时,它没有相应的特征。这种缺陷会导致严重的对象丢失,如图1c所示。因此,什么是适合MOT的查询关键机制仍然是一个关键问题
In this paper, we make efforts in this direction by build-ing an MOT framework based on transformer [38], whichis an attention-based query-key mechanism. We term it asTransTrack. It leverages set prediction for detection [5]and the knowledge passed from the previous frame to gainreliable object association at the same time. There are twosets of keys (following previous works [5], they are confus-ingly termed as “object query” in transformer). One set con-tains the object queries learned as in existing transformer-based detector [5] and the other contains those generatedfrom the features of objects on the previous frame, whichare also termed as “track query” for clarification. The firstset of queries provides a sense of new-coming objects andthe track queries provide consistent object information tomaintain tracklets. Two sets of bounding boxes are pre-dicted respectively and TransTrack uses simple IoU match-ing to generate the final ordered object set from them
在本文中,我们在transformer[38]的基础上构建了一个MOT框架,这是一种基于注意力的查询密钥机制。我们称之为TransTrack。它利用检测的集合预测[5]和从前一帧传递的知识,同时获得可靠的对象关联。有两组密钥(在之前的工作[5]之后,它们在transformer中被混淆地称为“对象查询”)。一组包含在现有的基于变换器的检测器[5]中学习到的对象查询,另一组包含从前一帧上的对象特征生成的对象查询。为了澄清,也称为“跟踪查询”。第一组查询提供了对即将到来的新对象的感觉,而track查询提供了一致的对象信息来维护tracklet。分别预测两组边界框,TransTrack使用简单的IoU匹配从t生成最终的有序对象集只有不同查询作为输入的统一解码器架构。我们的模型甚至在检测中去除了传统的NMS阶段。因此,我们的方法简单而直接,可以同时训练模型的所有组件。我们在两个真实世界的基准MOT17和MOT20[26,7]上评估TransTrack。**在MOT17和MOT20的测试集上分别获得74.5和64.5的MOTA。据我们所知,我们是第一个在MOT任务中介绍变压器的人。**Asit已经实现了与最先进的模型相当的性能,我们希望它能为多目标跟踪任务提供一个新的视角和有效的基线
2. Related Work
最近,在视觉任务中使用transformer架构[38]有一种流行性,在那里它已经被证明是强大和鼓舞人心的。作为一种特殊的查询关键机制,transformer在很大程度上依赖注意力机制来处理提取的深层特征。它首先在自然语言处理中表现出很高的效率[38],后来迁移到视觉感知任务[5],取得了显著的成功。Transformer以其优雅的结构和良好的性能吸引着视觉界。它在检测[5,60]、分割[57]、3D数据处理[55]甚至骨干建设[11]方面显示出巨大的潜力。最近,在处理顺序视觉数据时使用变换器的努力也使视频分割中的镜头可以重新标记[42]。通过特征沿时间维度的自然强度转换器显示出对视觉数据的不同时间空间处理任务做出贡献的能力,甚至取代了传统RNN模型的作用[16]。然而,据我们所知,仍然没有发布的基于转换器的对象跟踪解决方案,而它可以直观地利用其在视觉感知和时间处理方面表现出的良好能力。因此,在本文中,我们遵循这一见解,提出了一个基于变压器的MOT模型。它在流行的MOT基准上表现出令人信服的高性能
启动状态多对象跟踪器主要由逐检测跟踪Paradigm控制。它首先使用对象检测器[23,30,22]来定位所有感兴趣的对象,然后根据它们的Re-ID特征和/或其他信息(例如,彼此之间的并集交集(IoU))来关联这些未检测的对象。SORT[4]使用卡尔曼滤波器[44]跟踪边界框,并通过匈牙利算法[18]将其关联到当前帧。DeepSORT[45]将SORT中的关联成本替换为深度卷积网络的外观特征。POI[50]基于高性能检测和基于深度学习的外观特征实现了最先进的跟踪性能。Lifted Multicut[36]结合了姿势估计模型获得的深度表示和身体姿势特征。STRN[48]提出了轨迹和对象之间的相似性学习框架,对其进行编码
The joint-detection-and-tracking pipeline aims to achieve detection and trackingsimultaneously in a single stage. D&T [13] proposes amulti-task architecture for frame-based object detection andacross-frame track regression. Integrated-Detection [54]boosts the detection performance by combining the detec-tion bounding boxes in the current frame and tracks in pre-vious frames. More recently, Tracktor [1] directly usesthe previous frame tracking boxes as region proposals andthen applies the bounding box regression to provide track-ing boxes on the current step, thus eliminating the box as-sociation procedure. JDE [43] and FairMOT [51] learnthe object detection task and appearance embedding taskfrom a shared backbone. CenterTrack [58] localizes ob-jects by tracking-conditioned detection and predicts theiroffsets to the previous frame. ChainedTracker [29] chainspaired bounding boxes estimated from overlapping nodes,in which each node covers two adjacent frames. Our pro-posed TransTrack falls into the joint-detection-and-trackingcategory. Previous works adopt anchor-based [30] or point-based [59] detection framework.Instead, we build thepipeline based on a query-key mechanism and the tracked
联合检测和跟踪管道旨在在单个阶段实现同时检测和跟踪。D&T[13]提出了一种用于基于帧的对象检测和跨帧跟踪回归的多任务架构。集成检测[54]通过组合当前帧中的检测边界框和前一帧中的轨迹来提高检测性能。最近,Trackor[1]直接使用以前的帧跟踪框作为区域建议,然后应用边界框回归来提供当前步骤的跟踪框,从而消除了框作为关联过程。JDE[43]和FairMOT[51]从共享主干学习对象检测任务和外观嵌入任务。CenterTrack[58]通过跟踪条件检测来定位对象,并预测它们到前一帧的偏移。ChainedTracker[29]根据重叠节点估计的链式边界框
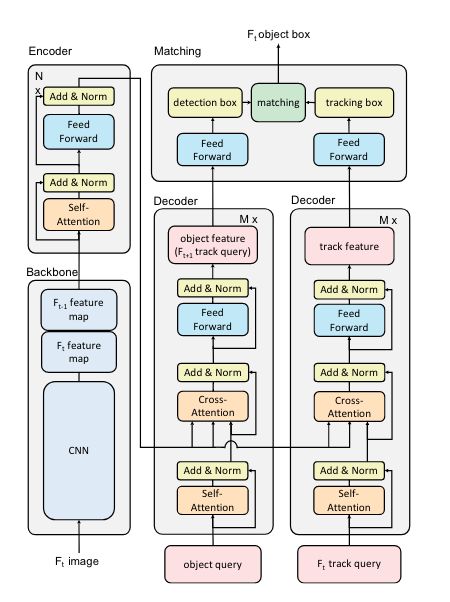
3. TransTrack
In MOT task, the desirable output is acompleteandcor-rectly orderedset of objects on each frame in a video. Tothese two ends, TransTrack uses queries from two sourcesto gain adaptive cues. On the one hand, similar to usualtransformer-based detectors [5, 60], TransTrack takes anobject query as input to provide common object detec-tion results.On the other hand, TransTrack leveragesfeatures from previously detected objects to form another“track query” to discover associated objects on the follow-ing frames. Under this scheme, TransTrack generates inparallel two sets of bounding boxes, termed as “detectionboxes” and “tracking boxes”. Last, TransTrack uses theHungarian algorithm, where the cost is IoU area amongboxes, to achieve the final ordered box set from the twobounding box sets. The pipeline is illustrated in Figure
在MOT任务中,所需的输出是视频中每帧上完整且有序的对象集。为此,TransTrack使用来自两个源的查询来获得自适应提示。一方面,类似于通常的基于转换器的检测器[5,60],TransTrack以另一个对象查询为输入,以提供常见的对象检测结果。另一方面,TransTrack利用先前检测到的对象的变形,形成另一个“跟踪查询”,以发现后续帧上的相关对象。在这种方案下,TransTrack生成平行的两组边界框,称为“检测”框”和“跟踪框”。最后,TransTrack使用Hungarian算法,其中成本是每个盒子的IoU面积,从两个边界盒子集中获得最终的有序盒子集。管道如图所示
3.1. Pipeline
In this section, we introduce the encoder-decoder archi-tecture of TransTrack for object detection and object prop-agation. Given the detection boxes and tracking boxes fromtwo decoders, box IoU matching is used to obtain the finaltracking result. We also introduce the training and inferenceprocess of TransTrack
在本节中,我们介绍了TransTrack的编码器-解码器结构,用于对象检测和对象传播。给定来自两个解码器的检测框和跟踪框,使用框IoU匹配来获得最终的跟踪结果。我们还介绍了TransTrack的训练和推理过程
结构
Given detected objects in the previ-ous frame, TransTrack propagates these objects by passingtheir features to the next frame as the track query. The stageis performed by the right-hand decoder block in Figure 3.The decoder has the same architecture as the left-hand onebut takes queries from different sources. This inherited ob-ject feature conveys the appearance and location informa-tion of previously seen objects, so this decoder could welllocate the position of the corresponding object on the
TransTrack is based on transformer, anencoder-decoder framework. It replies on stacked multi-head attention layers and feed-forward networks. Multi-head attention is called self-attention if the input query andthe input key are the same, otherwise, cross-attention. Intransformer architecture, The encoder generates keys andthe decoder takes as input task-specific queries. The archi-tecture overview is shown in
TransTrack是基于transformer,一个编码器-解码器框架。它在堆叠的多头注意力层和前馈网络上进行回复。如果输入查询和输入键相同,则称多头注意力为自注意力,否则称为交叉注意力。在转换器架构中,编码器生成密钥,解码器将特定于任务的查询作为输入。架构概述如所示
The encoder of TransTrack takes the composed featuremaps of two consecutive frames as input. To avoid du-plicated computation, the extracted features of the currentframe are temporarily saved and then re-used for the nextframe. Two parallel decoders are employed in TransTrack.Feature maps generated from the encoder are used as com-mon keys by the two decoders. The two decoders are de-signed to perform object detection and object propagation,respectively. Specifically, a decoder takes learned objectquery as input and predictsdetection boxes. The other de-coder takes the object feature from previous frames, namely“track query”, as input and predicts the locations of the cor-responding objects on the current frame, whose boundingboxes are termed astracking boxes
TransTrack的编码器将两个连续帧的合成特征图作为输入。为了避免重复计算,提取的当前帧的特征被临时保存,然后重新用于下一帧。TransTrack中使用了两个并行解码器。由编码器生成的特征图被两个解码器用作共同密钥。这两个解码器被解设计以分别执行对象检测和对象传播。具体来说,解码器将学习的对象查询作为输入并预测检测框。另一个解编码器将前一帧的对象特征,即“轨迹查询”作为输入,并预测当前帧上相应对象的位置,其边界框称为astracking box
Following DETR [5], TransTrack lever-ages learned object query for object detection. The objectquery is a set of learnable parameters, trained together withall other parameters in the network. During detection, thekey is the global feature maps generated from the input im-age and the object query looks up objects of interest in theimage and outputs the final detection predictions, termed as“detection boxes”. This stage is performed by the left-handdecoder blockrent frame and output “tracking boxes”
继DETR[5]之后,TransTrack杠杆老化学习对象查询以进行对象检测。对象查询是一组可学习的参数,与网络中的所有其他参数一起训练。在检测过程中,关键是根据输入图像生成的全局特征图,对象查询在图像中查找感兴趣的对象,并输出最终的检测预测,称为“检测框”。此阶段由左手解码器块执行
Object Propagation
Given detected objects in the previ-ous frame, TransTrack propagates these objects by passingtheir features to the next frame as the track query. The stageis performed by the right-hand decoder block in Figure 3.The decoder has the same architecture as the left-hand onebut takes queries from different sources. This inherited ob-ject feature conveys the appearance and location informa-tion of previously seen objects, so this decoder could welllocate the position of the corresponding object on the cur-rent frame and output “tracking boxe
给定上一帧中检测到的对象,TransTrack通过将这些对象的特征传递到下一帧作为轨迹查询来传播这些对象。阶段由图3中右侧的解码器块执行。解码器与左侧的解码器具有相同的架构,但接受来自不同来源的查询。这种继承的对象特征传达了先前看到的对象的外观和位置信息,因此该解码器可以很好地定位当前帧上相应对象的位置,并输出“跟踪框”
Provided the detection boxes and track-ing boxes, TransTrack uses the box IoU matching methodto get the final tracking result, as shown in Figure 3. Apply-ing the Kuhn-Munkres (KM) algorithm [18] to IoU similar-ity of detection boxes and tracking boxes, detection boxesare matched to tracking boxes. Those unmatched detectionboxes are kept to create new tracklets.
在提供了检测框和跟踪框的情况下,TransTrack使用框-IoU匹配方法来获得最终的跟踪结果,如图3所示。将Kuhn-Munkres(KM)算法[18]应用于检测盒和跟踪盒的IoU相似性,检测盒与跟踪盒匹配。这些不匹配的检测框将被保留以创建新的tracklet。
3.2. Training
Training Data.We build training dataset from two sources.As usual, the training data of could be two consecutiveframes or two randomly selected frames from a real videoclip. Furthermore, training data could also be the staticimage [58], where the adjacent frame is simulated by ran-domly scaling and translating the static image.
**训练数据 **我们从两个来源构建训练数据集。通常,训练数据可以是两个连续的帧,也可以是从真实视频剪辑中随机选择的两个帧。此外,训练数据也可以是静态[58],其中通过对静态图像进行随机缩放和平移来模拟相邻帧。
Training Loss.In TransTrack, tracking boxes and detec-tion boxes are the predictions of object boxes in the sameimage. It allows us to simultaneously train two decoders bythe same training loss
训练损失 在TransTrack中,跟踪框和检测框是同一图像中对象框的预测。它允许我们以相同的训练损失同时训练两个解码器TransTrack应用集合预测损失来监督分类和箱坐标的检测箱和跟踪箱。基于集合的损失产生了预测和地面实况对象之间的最优二分匹配。根据[5,60,35,34,39],匹配成本定义为
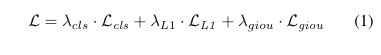
其中,预测分类和地面实况类别标签的Lclsis焦点损失[23],预测框和地面实况框的归一化中心坐标与高度和宽度之间的LL1和Lgiouare L1损失和广义IoU损失[31]。每个分量的λcls、λL1和λgiouare系数。训练损失与匹配成本相同,只是只在匹配的对上执行。最终损失是由训练批中对象数量归一化的所有对的总和

3.3. Inference
We use track rebirth in the inference procedure ofTransTrack to enhance robustness to occlusions and short-term disappearing [1, 58, 29]. Specifically, if a tracking boxis unmatched, it keeps as an “inactive” tracking box untilit remains unmatched forKconsecutive frames. Inactivetracking boxes can be matched to detection boxes and re-gain their ID. Following [58], we chooseK= 32
我们在TransTrack的推理过程中使用轨迹再生来增强对闭塞和短期消失的鲁棒性[1,58,29]。具体来说,如果跟踪框不匹配,它将保持为“非活动”跟踪框,直到连续K帧保持不匹配。非活动跟踪框可以与检测框匹配并重新获得其ID。在[58]之后,我们选择K=32

4. Experiments
To measure the performance of our proposed method,we conduct experiments on the pedestrian-tracking datasetMOT17 [26] and MOT20 [7]. In the ablation study, we fol-low previous practice [58] to split the MOT17 training setinto two parts, one for training and the other for validation.We adopt the widely-used MOT metrics set [2] for quan-titative evaluation where multiple object tracking accuracy(MOTA) is the primary metric to measure the overall per-formance.
为了测量我们提出的方法的性能,我们在行人跟踪数据集MOT17[26]和MOT20[7]上进行了实验。在消融研究中,我们遵循以往的实践[58],将MOT17训练集分为两部分,一部分用于训练,另一部分用于验证。我们采用广泛使用的MOT度量集[2]进行定量评估,其中多目标跟踪精度(MOTA)是衡量整体性能的主要度量。
4.1. Implementation details
We use ResNet-50 [15] as the network backbone. Theoptimizer is AdamW [24] and the batch size is set to be16. The initial learning rate is 2e-4 for the transformer and2e-5 for the backbone. The weight decay is 1e-4 All trans-former weights are initialized with Xavier-init [14], and thebackbone model is pretrained on ImageNet [8] with frozenbatch-norm layers [17]. We use data augmentation includ-ing random horizontal, random crop, scale augmentation,resizing the input images whose shorter side is by 480 -800 pixels while the longer side is by at most 1333 pixels.We train the model for 150 epochs and the learning ratedrops by a factor of 10 at the 100th epoch. In the ablation study, the model is first pre-trained on CrowdHuman [33]and then fine-tuned on MOT. When evaluating on the testset, we train our network on combination of CrowdHumanand MOT. More details are discussed in Appendix
我们使用ResNet-50[15]作为网络骨干。优化器为AdamW[24],批量大小设置为16。变压器的初始学习率为2e-4,主干的初始学习速率为2e-5。权重衰减为1e-4所有变换器权重都用Xavier init[14]初始化,并且在ImageNet[8]上用frozenbatch范数层[17]预训练Backbone模型。我们使用数据扩充,包括随机水平、随机裁剪、比例扩充、调整输入图像的大小,输入图像的短边为480-800像素,而长边最多为1333像素。我们对模型进行了150个历元的训练,在第100个历元时学习率下降了10倍。在消融过程中该模型首先在CrowdHuman[33]上进行预训练,然后在MOT上进行微调。在测试集上进行评估时,我们将CrowdHuman和MOT相结合来训练我们的网络。更多细节见附录
4.2. MOT17 benchmark
We evaluate models on MOT17 under the private detec-tor setting. The results We evaluate models on MOT17 un-der the private detector setting. The results are shown in Ta-ble 1. TransTrack achieves comparable results with the cur-rent state-of-the-art methods, especially in terms of MOTPand FN. The excellent MOTP demonstrates TransTrackcan precisely locate objects in the image. The good FNscore represents that most objects are successfully detected.Those prove the success of introducing learned object queryinto the pipeline. As for ID-switch, TransTrack is compara-ble with the popular trackers,e.g., FairMOT [51] and Cen-terTrack [58], which proves the effectiveness of object fea-ture query to associate adjacent frames. Although the ID-switch score of TransTrack is inferior to SOTA methods, itis a promising direction to further improve the overall per-formance of TransTrack
我们在专用检测器设置下评估MOT17上的模型。结果我们在专用检测器设置下对MOT17上的模型进行了评估。结果如表1所示。TransTrack与目前最先进的方法取得了可比的结果,尤其是在MOTPand FN方面。出色的MOTP演示了TransTrack可以精确定位图像中的对象。良好的FNscore表示大多数对象都被成功检测到。这些证明了将学习对象查询引入管道的成功。在ID切换方面,TransTrack与FairMOT[51]和Cen-terTrack[58]等流行的跟踪器进行了比较,证明了对象特征查询关联相邻帧的有效性。尽管TransTrack的ID切换得分不如SOTA方法,但这是进一步提高TransTrack整体性能的一个有希望的方向
4.3. MOT20 benchmark
We evaluate models on MOT20 under the private de-tector setting. The results are shown in Table 1. MOT20includes more crowded scenes than MOT17. Its more se-vere object occlusion and smaller object size bring morechallenges for object detection and tracking. Therefore,all methods show lower performance on MOT20 than onMOT17. But still, TransTrack achieves comparable re-sults with the current state-of-the-art methods on MOT20,in terms of detection metrics and association metrics
我们在专用探测器设置下评估MOT20上的模型。结果如表1所示。MOT20包含比MOT17更拥挤的场景。其更精确的物体遮挡和更小的物体尺寸给物体检测和跟踪带来了更多的挑战。因此,所有方法在MOT20上的性能都低于在MOT17上的性能。但是,在检测指标和关联指标方面,TransTrack仍然取得了与MOT20上当前最先进方法相当的结果
4.4. Ablation study
4.4.1 Transformer Architecture
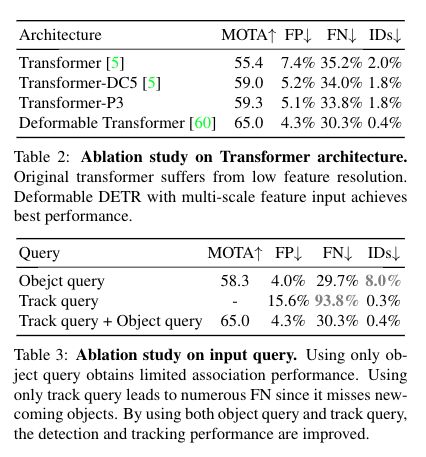
We ablate the effect of Transformer architecture.Fourtransformer structures are put into comparison.Trans-formerfollows the settings of DETR [5] detector, wheretransformer is built on top of the feature maps of res5stage [15].Transformer-DC5increases the feature mapsresolution. To be precise, we apply dilation convolution tores5 stage and remove a stride from the first convolution ofthis stage.Transformer-P3adopts FPN [22] on the inputfeature maps. The encoder of the Transformer is directlyremoved from the whole pipeline for memory limitation.After removing the encoder, the learning rate of the back-bone could be raised to the same as transformers. Finally,we also triedDeformable Transformer[60], which is arecently proposed architecture to solve the issue of limitedresolution in the transformer. Within plausible memory us-age, it fuses multiple-scale features into the whole encoder-decoder pipeline and achieves excellent performance in thegeneral object detection dataset
我们消除了Transformer架构的影响。将四个Transformer结构进行比较。Trans-former遵循DETR[5]检测器的设置,其中Transformer构建在res5stage[15]的特征图之上。Transformer-DC5增加了特征图的分辨率。准确地说,我们将膨胀卷积应用于5阶段,并从该阶段的第一次卷积中删除一个步长。变换器-P3在输入特征图上采用FPN[22]。由于内存限制,Transformer的编码器直接从整个流水线中移除。移除编码器后,背部骨骼的学习率可以提高到与Transformer相同。最后,我们还尝试了可变形变压器[60],这是最近提出的解决变压器中有限解问题的架构。在我们时代看似合理的记忆中,它将多个尺度特征融合到整个编码器-解码器流水线中,并在一般情况下实现了优异的性能


In this work, we set up a joint-detection-and-trackingMOT pipeline, TransTrack, based on the transformer. Ituses the learned object query as input to detects objectsand track query, which is the features the from previousframe, to propagate previously detected objects to the fol-lowing frames. TransTrack is the first work solving MOT insuch a paradigm. It achieves a competitive 74.5 MOTA onthe MOT17 dataset and 64.5 MOTA on a more challengingMOT20 dataset. We expect it to provide a novel perspectiveand insight to the MOT community
在这项工作中,我们建立了一个基于变压器的联合检测和跟踪MOT管道TransTrack。它使用学习的对象查询作为输入来检测对象,并跟踪查询,这是前一帧的特征,以将先前检测到的对象传播到下一帧。TransTrack是第一个解决MOT问题的范例。它在MOT17数据集上获得了具有竞争力的74.5 MOTA,在更具挑战性的MOT20数据集上实现了64.5 MOTA。我们希望它能为MOT社区提供一个新颖的视角和见解