机器学习实用工具 Wandb(1)—— 实验追踪
- 在做机器学习项目时,比如这个典型例子,常常遇到以下几个痛点
- 记录训练曲线的代码繁琐,与模型代码耦合度高,观感差又不好修改
- 自己做可视化效果较差,要做好又太浪费时间
- 调参时各种超参数模型难以管理,不易进行性能比较,网格搜索代码也很麻烦
- wandb 是一个实验记录平台,它可以快速实现美观的可视化效果,支持多种机器学习框架,代码侵入小,还能帮助我们进行超参参数搜索及版本控制,可以有效解决以上问题。如果使用团队版本,还可进行团队内实验结果共享,实验环境同步,实验报告制作等功能。它主要有以下四个组件构成:
Dashboard: 实验跟踪Artifacts: 数据集版本控制、模型版本控制Sweeps: 超参数优化Reports: 保存和共享可重现的结果
- 本文主要介绍如何集成 wandb + pytorch 来记录实验过程并可视化,参考文档(注:英文文档比中文文档更细致)
- Quickstart
- Experiment Tracking
- Simple_PyTorch_Integration
文章目录
- 1. 安装和注册
- 2. 跟踪训练过程
-
- 2.1 在代码中集成 wandb
- 2.2 FashionMNIST 分类示例
- 3. 可视化效果
1. 安装和注册
- 直接
pip install wandb安装 - 在 wandb 官网注册账号,注意现在只有注册成个人使用才免费
注册好之后复制给出的私钥,然后在命令行执行wandb login,根据提示输入私钥,即可建立起本地环境和 wandb 平台的联系
2. 跟踪训练过程
- 简单概括下工作流程:将 wandb 集成到需要观测的机器学习代码后,它会在本地建立一个仓库记录所有指定的实验数据,同时数据被上传到 wandb 服务器统一管理,并通过浏览器进行可视化。如果没有网络或者数据涉密,也可以建立本地服务器来完成全部流程
2.1 在代码中集成 wandb
- 将 wandb 集成到典型的 ML pipeline 中的伪代码如下
# import the library import wandb # start a new experiment wandb.init(project="new-sota-model") # capture a dictionary of hyperparameters with config wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128} # set up model and data model, dataloader = get_model(), get_data() # optional: track gradients wandb.watch(model) for batch in dataloader: metrics = model.training_step() # log metrics inside your training loop to visualize model performance wandb.log(metrics) # optional: save model at the end model.to_onnx() wandb.save("model.onnx") - 这里的关键代码只有 5 条,对模型代码入侵很小,下面依次介绍
- wandb.init():在训练或评估过程开始之前调用,它会新建一个 “Run” 记录,并在本地启动一个后台进程,将指定数据记录于其中。默认情况下数据会被同步到 wandb.ai 网站,所以可以看到实时的可视化。这里可以传入很多参数,包括该 Run 的名字、描述、所属的 project/group 及其保存到的本地仓库路径等等,完整参数列表参考官方文档
所谓一个 “Run”,可以理解为一段训练过程或评估过程,体现为一组指定的数据曲线,例如

- wandb.config:这个字典对象用来保存训练的 hyperparameters 和 metadata,是要传入
wandb.init的参数之一。其中 hyperparameters 会影响模型性能,后续需要进行网格搜索调整;metadata 包括数据集名称、模型类型等实验信息,它们对于区分 Run、分析实验和未来重现工作都很有用。在 wandb 网站上可以通过各种 config 参数值对所有 Run 进行分组,方便我们比较不同的设置如何影响模型性能
- wandb.watch():在训练开始前调用,调用后会按固定的 batch 周期记录模型的梯度和参数
如果开启了记录,每次 Run 的梯度和参数都会记录在 wandb 网站上,如


这些数据非常有用,可以帮助我们判断是否发生了梯度爆炸/梯度消失等问题,也能帮助我们判断是否有极端参数值主导模型输出,从而决定需要增加正则化项或 dropout - wandb.log():在循环中周期性调用来记录各项数据指标,每次调用时会向
history对象追加一个新记录,并更新summary对象。history对象是一组像字典一样的对象,记录了各项指标随时间的变化,可以显示为上面那样的折线图;summary对象默认记录的是最后一次wandb.log()记的值,也可手动设定为记录history的某种统计信息,比如最高精度或最低损失等,wandb 网站会自动利用这些信息进行 Run 的排序另外,log 方法也可上传图像、视频、html 等多种格式,可以参考 wandb使用教程(一):基础用法 以及官方文档
- wandb.save():在实验完成后调用这个来生成并保存 onnx 格式的模型,这是一种表示机器学习模型的通用开源格式,常常用来将 pytorch 模型转换为 TF 或 Keras 模型
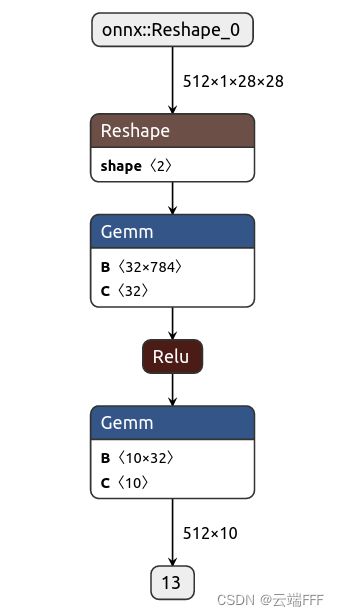
保存的
.onnx模型会被自动同步到 wandb 网站上,网站内嵌了 onnx 可视化工具,可以给出漂亮的网络结构图,例如下面这个两层 MLP
- wandb.init():在训练或评估过程开始之前调用,它会新建一个 “Run” 记录,并在本地启动一个后台进程,将指定数据记录于其中。默认情况下数据会被同步到 wandb.ai 网站,所以可以看到实时的可视化。这里可以传入很多参数,包括该 Run 的名字、描述、所属的 project/group 及其保存到的本地仓库路径等等,完整参数列表参考官方文档
2.2 FashionMNIST 分类示例
- 下面我们将 wandb 嵌入到之前 经典机器学习方法(3)—— 多层感知机 中介绍过的使用两层 MLP 做 FishonMIST 分类任务的代码上,来观察不同隐藏层尺寸对性能的影响
- 首先把上文中最后的 pytorch 代码整理为符合经典 ML pipeline 的结构,如下
import torch import torchvision import torchvision.transforms as transforms from torch import nn from torch.nn import init import random import numpy as np from tqdm import tqdm import argparse from pathlib import Path import os def model_pipeline(hyperparameters): ''' the overall pipeline, which is pretty typical for model-training ''' config=hyperparameters for seed in hyperparameters.seeds: set_random_seed(seed) # make the model, data, and optimization problem model, train_loader, val_loader, test_loader, loss, optimizer = make(config) print(model) # and use them to train the model train(model, train_loader, val_loader, loss, optimizer, config) # and test its final performance test(model, test_loader) def set_random_seed(random_seed): torch.backends.cudnn.deterministic = True random.seed(random_seed) np.random.seed(random_seed) torch.manual_seed(random_seed) torch.cuda.manual_seed_all(random_seed) def make(config): ''' make the data, model, loss and optimizer ''' # Make the data train = torchvision.datasets.FashionMNIST(root='./Datasets/FashionMNIST', train=True, transform=transforms.ToTensor(), download=True) test = torchvision.datasets.FashionMNIST(root='./Datasets/FashionMNIST', train=False, transform=transforms.ToTensor(), download=True) train_dataset = torch.utils.data.Subset(train, indices=range(0, int(0.8*len(train)))) val_dataset = torch.utils.data.Subset(train, indices=range(int(0.8*len(train)), len(train))) test_dataset = torch.utils.data.Subset(test, indices=range(0, len(test), 1)) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4) val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=len(val_dataset), shuffle=True, pin_memory=True, num_workers=4) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4) # Make the model model = MLP(784, 10, config.num_hiddens).to(device) for params in model.parameters(): init.normal_(params, mean=0, std=0.01) # Make the loss and optimizer loss = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate) return model, train_loader, val_loader, test_loader, loss, optimizer class FlattenLayer(nn.Module): ''' 这个自定义 Module 将二维的图像输入拉平成一维向量 ''' def __init__(self): super(FlattenLayer, self).__init__() def forward(self, x): # x shape: (batch, *, *, ...) return x.view(x.shape[0], -1) def MLP(num_inputs, num_outputs, num_hiddens): model = nn.Sequential( FlattenLayer(), nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.Linear(num_hiddens, num_outputs), ) return model def train(model, train_loader, val_loader, loss, optimizer, config): # Run training total_batches = len(train_loader) * config.epochs example_cnt = 0 # number of examples seen batch_cnt = 0 for epoch in range(config.epochs): with tqdm(total=len(train_loader), desc=f'epoch {epoch+1}') as pbar: for _, (images, labels) in enumerate(train_loader): train_loss = train_batch(images, labels, model, optimizer, loss) example_cnt += len(images) batch_cnt += 1 # Report metrics every 20th batch if (batch_cnt + 1) % 20 == 0: val_accuracy, val_loss = validation(model, val_loader, loss) # update tqdm information pbar.set_postfix({ 'val_acc': '%.3f' % val_accuracy, 'val_loss': '%.3f' % val_loss, }) pbar.update(1) def train_batch(images, labels, model, optimizer, loss): images, labels = images.to(device), labels.to(device) # Forward pass outputs = model(images) train_loss = loss(outputs, labels) # Backward pass optimizer.zero_grad() train_loss.backward() # Step with optimizer optimizer.step() return train_loss def test(model, test_loader): model.eval() with torch.no_grad(): correct, total = 0, 0 for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() test_accuracy = correct/total print(f"Accuracy of the model on the {total} test images: {test_accuracy:%}") model.train() return test_accuracy def validation(model, val_loader, loss): model.eval() with torch.no_grad(): correct, total = 0, 0 for images, labels in val_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() val_accuracy = correct/total val_loss = loss(outputs, labels) model.train() return val_accuracy, val_loss if __name__ == '__main__': # random seeds random_seeds = (43,44,45) # Device configuration device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) # as the start of our workflow, store hyperparameters parser = argparse.ArgumentParser() parser.add_argument('--seeds', type=int, default=random_seeds) parser.add_argument('--epochs', type=int, default=5) parser.add_argument('--batch_size', type=int, default=512) parser.add_argument('--learning_rate', type=float, default=0.1) parser.add_argument('--num_hiddens', type=int, default=32) args = parser.parse_args() config = args # Build, train and analyze the model with the pipeline model = model_pipeline(config) - 接下来按 2.1 节说明增加 wandb 方法,完整代码如下,请读者自行对比
import torch import torchvision import torchvision.transforms as transforms from torch import nn from torch.nn import init import random import numpy as np import wandb from tqdm import tqdm import argparse from pathlib import Path import os def model_pipeline(hyperparameters): ''' the overall pipeline, which is pretty typical for model-training ''' # set the location where all the data logged from script will be saved, which will be synced to the W&B cloud # the default location is ./wandb run_dir = Path(f"{os.getcwd()}/wandb_local") / hyperparameters.project_name / hyperparameters.experiment_name if not run_dir.exists(): os.makedirs(str(run_dir)) for seed in hyperparameters.seeds: set_random_seed(seed) # tell wandb to get started with wandb.init(config=vars(hyperparameters), project=hyperparameters.project_name, group=hyperparameters.scenario_name, name=hyperparameters.experiment_name+"_"+str(seed), notes=hyperparameters.note, dir=run_dir): # access all HPs through wandb.config, ensuring the values you chose and logged are always the ones that get used in your model config = wandb.config # make the model, data, and optimization problem model, train_loader, val_loader, test_loader, loss, optimizer = make(config) print(model) # and use them to train the model train(model, train_loader, val_loader, loss, optimizer, config) # and test its final performance test(model, test_loader) # Save the model in the exchangeable ONNX format # Passing that filename to wandb.save ensures that the model parameters are saved to W&B's servers: torch.onnx.export(model, torch.randn(config.batch_size, 1, 28, 28).to(device), "model.onnx") wandb.save("model.onnx") wandb.finish() def set_random_seed(random_seed): torch.backends.cudnn.deterministic = True random.seed(random_seed) np.random.seed(random_seed) torch.manual_seed(random_seed) torch.cuda.manual_seed_all(random_seed) def make(config): ''' make the data, model, loss and optimizer ''' # Make the data train = torchvision.datasets.FashionMNIST(root='./Datasets', train=True, transform=transforms.ToTensor(), download=True) test = torchvision.datasets.FashionMNIST(root='./Datasets', train=False, transform=transforms.ToTensor(), download=True) train_dataset = torch.utils.data.Subset(train, indices=range(0, int(0.8*len(train)))) val_dataset = torch.utils.data.Subset(train, indices=range(int(0.8*len(train)), len(train))) test_dataset = torch.utils.data.Subset(test, indices=range(0, len(test), 1)) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4) val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=len(val_dataset), shuffle=True, pin_memory=True, num_workers=4) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4) # Make the model model = MLP(784, 10, config.num_hiddens).to(device) for params in model.parameters(): init.normal_(params, mean=0, std=0.01) # Make the loss and optimizer loss = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate) return model, train_loader, val_loader, test_loader, loss, optimizer class FlattenLayer(nn.Module): ''' 这个自定义 Module 将二维的图像输入拉平成一维向量 ''' def __init__(self): super(FlattenLayer, self).__init__() def forward(self, x): # x shape: (batch, *, *, ...) return x.view(x.shape[0], -1) def MLP(num_inputs, num_outputs, num_hiddens): model = nn.Sequential( FlattenLayer(), nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.Linear(num_hiddens, num_outputs), ) return model def train(model, train_loader, val_loader, loss, optimizer, config): # wandb.watch will log the gradients and the parameters of your model, every log_freq steps of training. # it need to be called before start training wandb.watch(model, loss, log="all", log_freq=10) # Run training and track with wandb total_batches = len(train_loader) * config.epochs example_cnt = 0 # number of examples seen batch_cnt = 0 for epoch in range(config.epochs): with tqdm(total=len(train_loader), desc=f'epoch {epoch+1}') as pbar: # tqdm的进度条功能 for _, (images, labels) in enumerate(train_loader): train_loss = train_batch(images, labels, model, optimizer, loss) example_cnt += len(images) batch_cnt += 1 # Report metrics every 200th batch if (batch_cnt + 1) % 20 == 0: val_accuracy, val_loss = validation(model, val_loader, loss) # update tqdm information pbar.set_postfix({ 'val_acc': '%.3f' % val_accuracy, 'val_loss': '%.3f' % val_loss, }) # log the metrics to wandb wandb.log({"epoch": epoch + 1, "train_loss": train_loss, 'val_accuracy': val_accuracy, 'val_loss': val_loss}, step=example_cnt) pbar.update(1) def train_batch(images, labels, model, optimizer, loss): images, labels = images.to(device), labels.to(device) # Forward pass outputs = model(images) train_loss = loss(outputs, labels) # Backward pass ⬅ optimizer.zero_grad() train_loss.backward() # Step with optimizer optimizer.step() return train_loss def test(model, test_loader): model.eval() with torch.no_grad(): correct, total = 0, 0 for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() test_accuracy = correct/total wandb.log({'test_accuracy': test_accuracy}) print(f"Accuracy of the model on the {total} test images: {test_accuracy:%}") model.train() return test_accuracy def validation(model, val_loader, loss): model.eval() with torch.no_grad(): correct, total = 0, 0 for images, labels in val_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() val_accuracy = correct/total val_loss = loss(outputs, labels) model.train() return val_accuracy, val_loss if __name__ == '__main__': # random seeds random_seeds = (43,44,45) # Device configuration device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) # as the start of our workflow, store hyperparameters and metadata in a config dictionary parser = argparse.ArgumentParser() parser.add_argument('--seeds', type=int, default=random_seeds) parser.add_argument('--epochs', type=int, default=5) parser.add_argument('--batch_size', type=int, default=512) parser.add_argument('--learning_rate', type=float, default=0.1) parser.add_argument('--num_hiddens', type=int, default=32) parser.add_argument('--dataset', type=str, default='FashionMNIST') parser.add_argument('--architecture', type=str, default='MLP') parser.add_argument('--note', type=str, default='add some note for the run here') parser.add_argument('--project_name', type=str, default='Wandb_ExpTracking') parser.add_argument('--scenario_name', type=str, default='MLP_Hiddens') parser.add_argument('--experiment_name', type=str, default='seed') args = parser.parse_args() config = args # Build, train and analyze the model with the pipeline model = model_pipeline(config)
3. 可视化效果
- 首次执行 2.2 节代码后,在你的 wandb 主页上就会出现名为 Wandb_ExpTracking 的 project。多次修改
num_hiddens取值重复执行,然后在主页 project 栏找到 Wandb_ExpTracking 点进去,就会如下显示所有 Run 的平均性能

- 每一张 Chart 记录的指标都是我们在代码中调用
wandb.log()时传入的指标之一 - 每一张 Chart 右上角都可以点进去调整图像显示,比如调整曲线粗细和平滑度、设置 x 轴等
- 左边的项目结构是由我们设定的 metadata 决定,最后一级都是独立的 run,倒数第二级是这些 Run 的平均性能,会显示为一条曲线。这里我设置为最后一级是不同的随机种子,倒数第二级是隐藏层尺寸
- 下面一点 System 栏记录了训练过程中的硬件使用情况,这个也非常有用,可以帮助我们确定 batch_size 大小、确定速度瓶颈等

- 每一张 Chart 记录的指标都是我们在代码中调用
- 最左边的竖栏从上到下是
- Overview:显示项目的基础信息,在团队版本比较有用
- Workspace(当前位置)
- Table:显示所有 run 的统计数据

上面那个紫色的按钮可以点进去,根据不同指标的取值灵活设置项目结构,无论结构如何,最后一级都是独立的 Run,倒数第二级会自动变成这些 Run 的平均,显示在上面的曲线图中 - Reports:可以直接调用前面的各种插图写报告,不做介绍
- Sweeps:用来做超参数搜索的,以后介绍
- Artifacts:用来做模型版本控制的,以后介绍
- 随便在 Workspace 找一个 Run 点进去,左边竖栏又会有五个
- Overview:显示这次 Run 的 metadata、指标,以及执行这个 run 的人员和软硬件环境等信息
- Charts:该 Run 的指标 Chart,和上面一致
- System:记录此 Run 执行过程的硬件资源占用情况
- Logs:记录此 Run 的
wandb.init周期内所有的终端显示 - Files:记录此 Run 的虚拟环境、网络结构等信息

其中model.onxx可以点进去查看网络结构图,requirements.txt记录了使用的所有依赖库,可以直接在本地重建虚拟环境