spark整合hive小总结
关于安装spark这里就不多说喽~
!!!看!安装mysql和hive:
安装RPM包和下载mysql:
sudo yum localinstall https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm
sudo yum install mysql-community-server开启MySQL服务并查看状态:
systemctl start mysqld.service
service mysqld status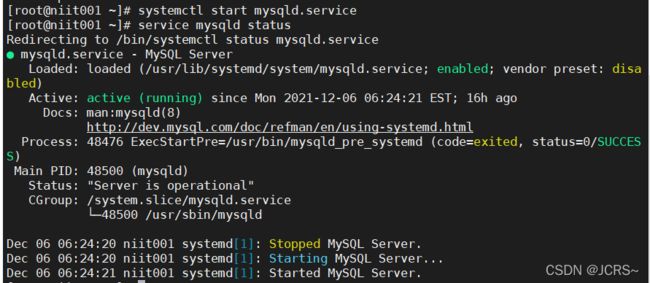
看到整合,估计许多小伙伴的密码应该也没问题了,如有修改记得重启MySQL服务哟!
systemctl restart mysqld
好了好了,安装hive:
解压解压: tar -zvxf /tools/apache-hive-2.3.8-bin.tar.gz -C /training/
配置环境变量 vi ~/.bash_profile,
配置完成后记得保存(ESC,shift+:,wq)刷新:source ~/.bash_profile
#Hive Path
export HIVE_HOME=/training/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin进入配置目录: cd $HIVE_HOME/conf ; 配置文件:vi hive-site.xml ; 内容如下:
hive.default.fileformat
TextFile
hive.metastore.warehouse.dir
hdfs://niit001:9000/user/hive/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://niit001:3306/hive_metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
hiveuser
username to use against metastore database
javax.jdo.option.ConnectionPassword
ud%sH5Ppy:A4
password to use against metastore database
hive.aux.jars.path
file:///training/hbase-1.1.3/lib/zookeeper-3.4.6.jar,,file:///training/hbase-1.1.3/lib/guava-12.0.1.jar,file:///training/hbase-1.1.3/lib/hbase-client-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-common-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-server-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-shell-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-thrift-1.1.3.jar
hive.metastore.uris
thrift://niit001:9083
hive.metastore.schema.verification
false
datanucleus.schema.autoCreateAll
true
记得把驱动 jar 包 mysql-connector-java-8.0.23.jar 复制到 $HIVE_HOME/lib 和 /training/spark-2.2.0-bin-hadoop2.7/jars/ 这里哟!
驱动装好后就是初始化元数据库了!
schematool -dbType mysql -initSchema出错了不用着急!
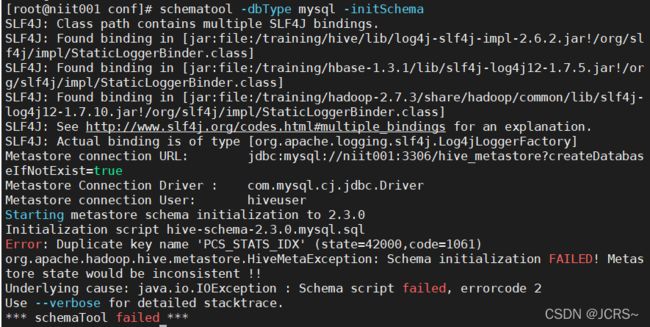
如果这样的话,知识元数据库已经在MySQL中建立了,我们只需要去里边删了就行:
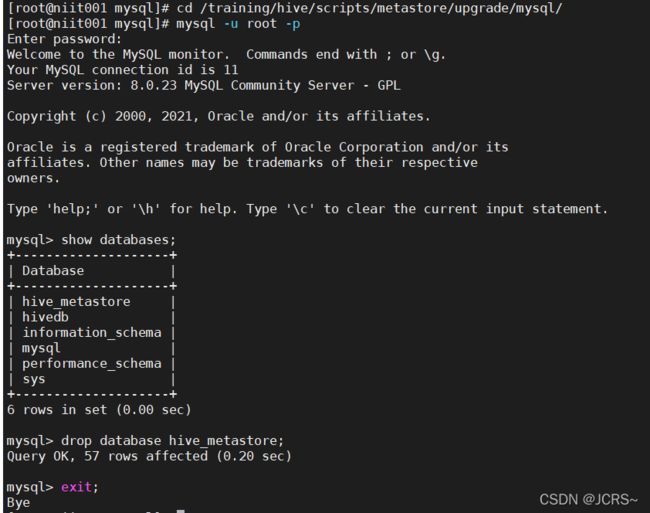

这样子就OK了!
接下来记得把hive和Hadoop的配置文件复制到spark配置文件目录中:
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf
cp $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf然后就可以启动hive metastore了!
!温馨提示:记得在启动hive之前启动Hadoop和spark!
[root@niit001 mysql]# start-dfs.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/training/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/training/hbase-1.3.1/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting namenodes on [niit001]
niit001: starting namenode, logging to /training/hadoop-2.7.3/logs/hadoop-root-namenode-niit001.out
niit001: starting datanode, logging to /training/hadoop-2.7.3/logs/hadoop-root-datanode-niit001.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /training/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-niit001.out
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/training/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/training/hbase-1.3.1/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[root@niit001 mysql]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /training/hadoop-2.7.3/logs/yarn-root-resourcemanager-niit001.out
niit001: starting nodemanager, logging to /training/hadoop-2.7.3/logs/yarn-root-nodemanager-niit001.out
[root@niit001 mysql]# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /training/spark-2.2.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-niit001.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /training/spark-2.2.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-niit001.out
[root@niit001 mysql]# jps
52752 DataNode
53569 Worker
52627 NameNode
52917 SecondaryNameNode
53191 NodeManager
53640 Jps
53082 ResourceManager
53501 Master
[root@niit001 mysql]#
启动hive metastore: hive --service metastore

到这里,或许许多小伙伴会等的很焦急,怎么还不出来,这又是哪里错了
哈哈,其实到这里就是成功了!!!
这只是开启了进程,我们新开一个窗口,就可以在spark中运行MySQL了!看!
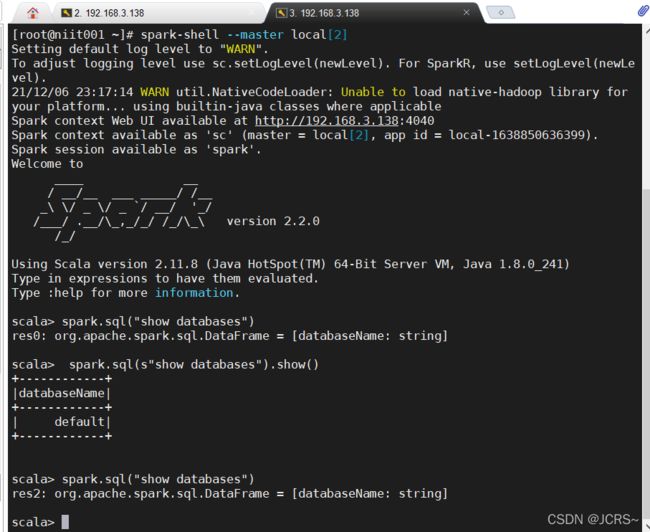
这就是成功了哟!
如果有小伙伴发现在启动spark-shell时,报出了找不到驱动的错误,那就是驱动还没复制到spark的jars目录下哟!可以再仔细看一下前文中所提到的驱动部分;
如果有显示别的错误,小伙伴们可以jps进行检查一下,把多出来的进程 kill -9 进程号 就行;
如果 在启动hive metastore时有出现DBS已经存在的情况,那就重新初始化元数据库就行,如果初始化元数据库错误,那就是元数据库已经被建立,去MySQL中删了就行,就像前文中所提到的那样,还附了图片呢!
大家加油哟!还有什么错误也可以联系我哟!