Java笔记(三十):MySQL(上)-- 数据库、MySQL常用数据类型、DDL、DML、多表设计
一、数据库
0、MySQL安装,IDEA配置MySQL
- 用MySQL installer for windows(msi)
- MySQL默认安装位置:
C:\Program Files\MySQL\MySQL Server 8.0 - 配置环境变量
- 使用前先确保启动了mysql服务
- my.ini位置:
C:\ProgramData\MySQL\MySQL Server 8.0 - 存放数据库的位置:
C:\ProgramData\MySQL\MySQL Server 8.0\Data
IDEA有个Database模块,点一下,连接上MySQL就行
(1)调出查询界面
1、数据库简单原理图

2、使用命令行窗口连接MYSQL数据库
(1)mysql -h 主机名 -P 端口 -u 用户名 -p密码; //-P 端口大写 -p密码没有空格
mysql -u -root -p //快捷登录
(2)登录前,保证服务启动。

3、MySQL三层结构
(1)所谓安装MySQL数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库。一个数据库中可以创建多个表,以保存数据(信息)
(2)数据库管理系统(DBMS)、数据库和表的关系如图:
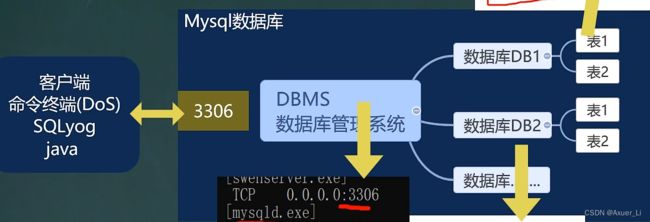
(3)MySQL数据库-表的本质仍然是文件
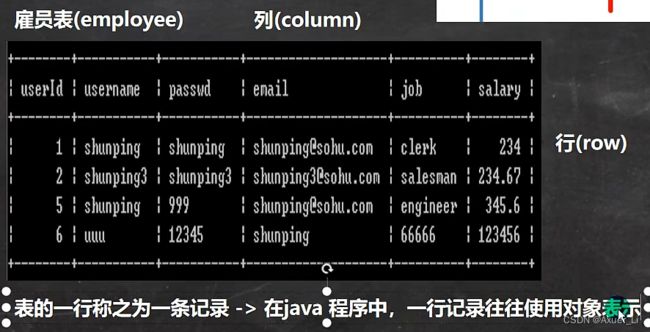
4、数据在数据库中的存储方式
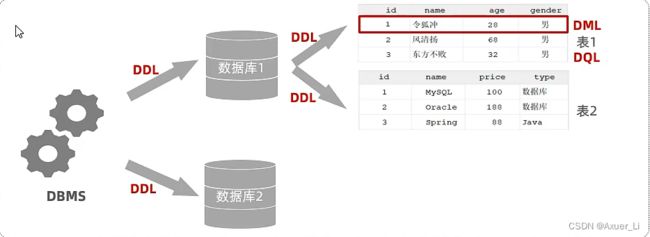
5、SQL语句分类

6、数据库操作
1)创建数据库


如果新建一个表,没有指定字符集和校对规则,那么就会默认设为该表所在的数据库字符集和校对规则

#使用指令创建数据库
CREATE DATABASE hsp_db01;
#删除数据库指令
DROP DATABASE hsp_db01;
#创建一个使用 utf8 字符集的 hsp_db02 数据库
CREATE DATABASE hsp_db02 CHARACTER SET utf8;
#创建一个使用 utf8 字符集,并带校对规则的 hsp_db03 数据库
CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin;
#校对规则 utf8_bin 区分大小 默认 utf8_general_ci 不区分大小
#WHERE 从哪个字段 NAME = 'tom' 查询名字是 tom
SELECT *
FROM t1
WHERE NAME = 'tom'
【注意点】
-
sql语句末尾是否加分号:
如果同时执行多条sql语句,那就得加分号
如果只执行单条语句,那就不用加 -
在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
CREATE DATABASE `hsp_db01`
2)查看、删除数据库


#演示删除和查询数据库
#查看当前数据库服务器中的所有数据库
SHOW DATABASES
#查看前面创建的 hsp_db01 数据库的定义信息
SHOW CREATE DATABASE `hsp_db01` #在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
#删除前面创建的 hsp_db01 数据库
DROP DATABASE hsp_db01
3)使用数据库

3)备份恢复数据库
(1)备份恢复数据库

#(1)备份数据库
#执行 mysqldump 指令,因为该指令其实在 mysql 安装目录\bin,所以要在 Dos 下执行
#这个备份的文件,就是对应的 sql 语句
mysqldump -u root -p -B hsp_db02 hsp_db03 > d:\\bak.sql
#模拟文件损坏
DROP DATABASE hsp_db02;
DROP DATABASE hsp_db03;
#(2)恢复数据库
#(注意:进入 Mysql 命令行再执行---> mysql -u root -p)
source d:\\bak.sql
#第二个恢复方法, 直接将 bak.sql 的内容放到查询编辑器中,执行
(2)备份恢复数据库的表(不带-B)
备份
mysqldump -u 用户名 -p 数据库 表1 表2 > d:\\文件名.sql

恢复
【⭐】恢复前需要先use 想要恢复的数据库名,不然会报错No databaseSelected
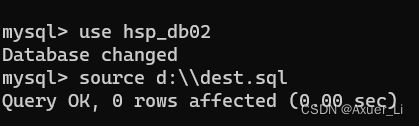
导入一个sql文件和恢复是一样的思想
先use 表
再source sql文件
二、MySQL常用数据类型⭐⭐⭐
1、数值–整型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-263,263-1) | (0,2^64-1) | 极大整数值 |
常用:tinyint、int、bigint
如何指定无符号和有符号
#1. 如果没有指定 unsinged , 则TINYINT就是有符号
#2. 如果指定 unsinged , 则TINYINT就是无符号 0-255
CREATE TABLE t3 (
id TINYINT);
CREATE TABLE t4 (
id TINYINT UNSIGNED);
2、数值–浮点类型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
常用:double
float、double、decimal的用法区别


#演示decimal类型、float、double使用
#创建表
CREATE TABLE t06 (
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#添加数据
INSERT INTO t06 VALUES(88.12345678912345, 88.12345678912345,88.12345678912345);
SELECT * FROM t06;
#decimal可以存放很大的数
CREATE TABLE t07 (
num DECIMAL(65));
INSERT INTO t07 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t07;
CREATE TABLE t08(
num BIGINT UNSIGNED)
INSERT INTO t08 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t08;
3、数值–bit型

#演示bit类型使用
#说明
#1. bit(m) m 在 1-64
#2. 添加数据 范围 按照你给的位数来确定,比如m = 8 表示一个字节 0~255
#3. 显示按照bit
#4. 查询时,仍然可以按照数来查询
CREATE TABLE t05 (
num BIT(8)
);
INSERT INTO t05 VALUES(255);
SELECT * FROM t05;
SELECT * FROM t05 WHERE num = 1;
4、字符串、二进制类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
常用:char、varchar(存放文本时用TEXT)
char和varchar的区别
- char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。
- varchar是变长字符串,指定的长度为最大占用长度 。

示例:
用户名 username ---长度不定, 最长不会超过50
username varchar(50)
手机号 phone ---固定长度为11
phone char(11)
字符串使用细节

5、日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
常用:date、datetime
示例:
生日字段 birthday ---生日只需要年月日
birthday date
创建时间 createtime --- 需要精确到时分秒
createtime datetime
(1)数值型(整数)的基本使用
(2)数值型(bit位)的使用
(3)数值型(小数)的基本使用
(4)字符串的基本使用
(5)字符串使用细节
(6)日期类型的基本使用
(7)创建表练习
三、表结构相关DDL
1、创建表⭐⭐⭐
1)基本语法

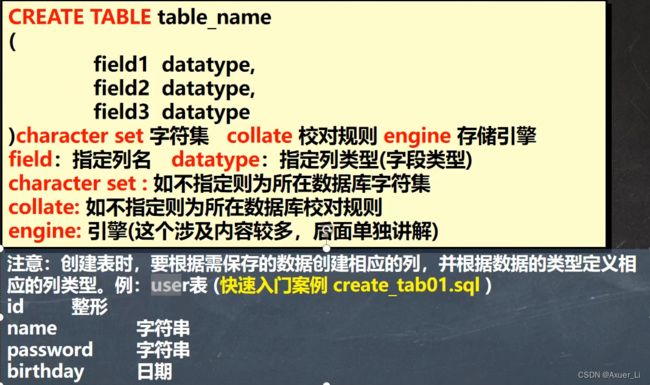
【】注意最后一个字段不要加逗号
#指令创建表
#hsp_db02创建表时,要根据需保存的数据创建相应的列,并根据数据的类型定义相应的列类型。例:user表 (快速入门案例 create_tab01.sql )
#id 整形 [图形化,指令]
#name 字符串
#password 字符串
#birthday 日期
CREATE TABLE `user` (
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE
)CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
2)约束⭐
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。
作用:就是来保证数据库当中数据的正确性、有效性和完整性。(后面的学习会验证这些)

① 主键约束

-- 主键使用
-- id name email
CREATE TABLE t17
(id INT PRIMARY KEY, -- 表示id列是主键
`name` VARCHAR(32),
email VARCHAR(32));
-- 主键列的值是不可以重复
INSERT INTO t17
VALUES(1, 'jack', '[email protected]');
INSERT INTO t17
VALUES(2, 'tom', '[email protected]');
INSERT INTO t17
VALUES(1, 'hsp', '[email protected]');
SELECT * FROM t17;
-- 主键使用的细节讨论
-- primary key不能重复而且不能为 null。
INSERT INTO t17
VALUES(NULL, 'hsp', '[email protected]');
-- 一张表最多只能有一个主键, 但可以是复合主键(比如 id+name)
CREATE TABLE t18
(id INT PRIMARY KEY, -- 表示id列是主键
`name` VARCHAR(32), PRIMARY KEY -- 错误的
email VARCHAR(32));
-- 演示复合主键 (id 和 name 做成复合主键)
CREATE TABLE t18
(id INT ,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY (id, `name`) -- 这里就是复合主键
);
INSERT INTO t18
VALUES(1, 'tom', '[email protected]');
INSERT INTO t18
VALUES(1, 'jack', '[email protected]');
INSERT INTO t18
VALUES(1, 'tom', '[email protected]'); -- 这里就违反了复合主键
SELECT * FROM t18;
-- 主键的指定方式 有两种
-- 1. 直接在字段名后指定:字段名 primakry key
-- 2. 在表定义最后写 primary key(列名);
CREATE TABLE t19
(id INT ,
`name` VARCHAR(32) PRIMARY KEY,
email VARCHAR(32)
);
CREATE TABLE t20
(id INT ,
`name` VARCHAR(32) ,
email VARCHAR(32),
PRIMARY KEY(`name`) -- 在表定义最后写 primary key(列名)
);
-- 使用desc 表名,可以看到primary key的情况
DESC t20 -- 查看 t20表的结果,显示约束的情况
DESC t18
② 非空(not null)和 唯一(unique)

-- unique的使用
CREATE TABLE t21
(id INT UNIQUE , -- 表示 id 列是不可以重复的.
`name` VARCHAR(32) ,
email VARCHAR(32)
);
INSERT INTO t21
VALUES(1, 'jack', '[email protected]');
INSERT INTO t21
VALUES(1, 'tom', '[email protected]');
-- unqiue使用细节
-- 1. 如果没有指定 not null , 则 unique 字段可以有多个null
-- 如果一个列(字段), 是 unique not null 使用效果类似 primary key
INSERT INTO t21
VALUES(NULL, 'tom', '[email protected]');
SELECT * FROM t21;
-- 2. 一张表可以有多个unique字段
CREATE TABLE t22
(id INT UNIQUE , -- 表示 id 列是不可以重复的.
`name` VARCHAR(32) UNIQUE , -- 表示name不可以重复
email VARCHAR(32)
);
DESC t22
③ 外键

字段允许为null —> 没有添加not null 字段
④ check

-- 演示check的使用
-- mysql5.7目前还不支持check ,只做语法校验,但不会生效
-- 了解
-- 学习 oracle, sql server, 这两个数据库是真的生效.
-- 测试
CREATE TABLE t23 (
id INT PRIMARY KEY,
`name` VARCHAR(32) ,
sex VARCHAR(6) CHECK (sex IN('man','woman')),
sal DOUBLE CHECK ( sal > 1000 AND sal < 2000)
);
-- 添加数据
INSERT INTO t23
VALUES(1, 'jack', 'mid', 1);
SELECT * FROM t23;
⑤ 约束练习
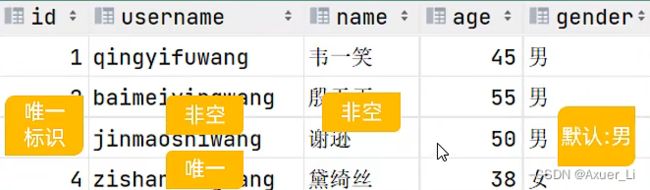
主键自增:auto_increment
每次插入新的行记录时,数据库自动生成id字段(主键)下的值
-- 添加约束的建表语句
create table tb_user (
id int primary key auto_increment comment 'ID,唯一标识', #主键自动增长
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';
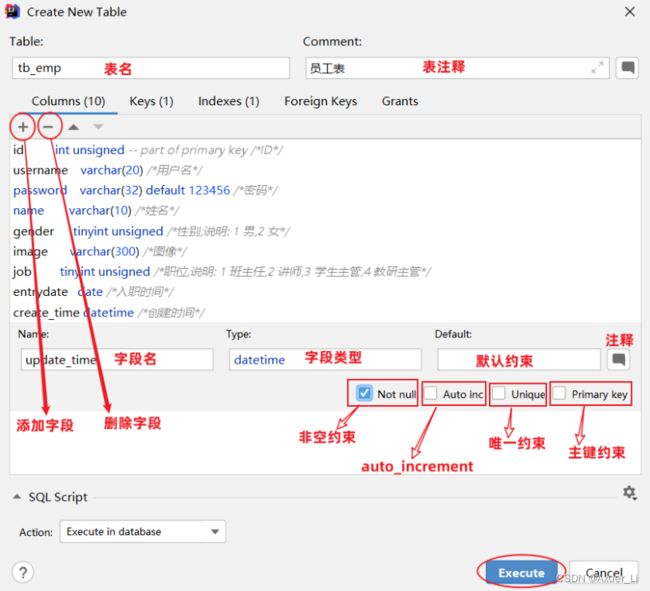
3)创建表练习
//图片存储的是路径(链接)—> varchar
create table emp (
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
用idea
2、查询表结构
关于表结构的查询操作,工作中一般都是直接基于图形化界面操作。
查询当前数据库所有表
show tables;
查看指定表结构
#可以查看指定表的字段、字段的类型、是否可以为NULL、是否存在默认值等信息
desc 表名 ;
查询指定表的建表语句
show create table 表名 ;

3、修改表(包含增加删除字段操作)

-- 为表 tb_emp 添加字段 qq varchar(11)
-- 修改 tb_emp 字段类型为 qq varchar(13)
-- 修改tb_emp 字段名qq 为 qq_num varchar(13)
-- 删除 tb_emp 的 qq_num 字段
-- 将 tb_emp 修改为 emp
alter table tb_emp add qq varchar(11);
alter table tb_emp modify qq varchar(13);
alter table tb_emp change qq qq_num varchar(13);
alter table tb_emp drop column qq_num;
rename table tb_emp to emp;
图形化操作
4、删除表
drop table [ if exists ] 表名;
注意,在删除表时,表中的全部数据也会被删除
四、表数据操作相关DML

1、添加数据INSERT

案例1:向tb_emp表的username、name、gender字段插入数据
-- 因为设计表时create_time, update_time两个字段不能为NULL,所以也做为要插入的字段
-- MySQL中获取当前时间的方法: now()
insert into tb_emp(username, name, gender, create_time, update_time)
values ('wuji', '张无忌', 1, now(), now());
案例2:向tb_emp表的所有字段插入数据
insert into tb_emp(id, username, password, name, gender, image, job, entrydate, create_time, update_time)
values (null, 'zhirou', '123', '周芷若', 2, '1.jpg', 1, '2010-01-01', now(), now());
案例3:批量向tb_emp表的username、name、gender字段插入数据
insert into tb_emp(username, name, gender, create_time, update_time)
values ('weifuwang', '韦一笑', 1, now(), now()),
('fengzi', '张三疯', 1, now(), now());
Insert操作的注意事项:
-
插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
-
字符串和日期型数据应该包含在引号中。
-
插入的数据大小,应该在字段的规定范围内。
2、更新UPDATE
update语法:
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;
案例1:将tb_emp表中id为1的员工,姓名name字段更新为’张三’(where)
update tb_emp set name='张三',update_time=now() where id=1;
案例2:将tb_emp表的所有员工入职日期更新为’2010-01-01’
update tb_emp set entrydate='2010-01-01',update_time=now();
UPDATE注意事项:

- 在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
3、删除DELETE
delete语法:
delete from 表名 [where 条件] ;
案例1:删除tb_emp表中id为1的员工
delete from tb_emp where id = 1;
案例2:删除tb_emp表中所有员工(慎用)
delete from tb_emp;
DELETE注意事项:

-
DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
-
DELETE 语句不能删除某一个字段(某一列)的值(可以使用UPDATE,将该字段值置为NULL或者""即可)。
-
使用delete语句仅删除记录,不删除表本身。如果要删除表,使用drop table语句。
drop table 表名 -
当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
4、DELETE和UPDATE在删除上的用法
DELETE是删除横向数据,也就是一行一行的
UPDATE是“删除”纵向数据,也就是可以把一列上的所有数据给置为null
核心:UPDATE 是 set 字段,而DELETE 没有
五、多表设计
1、表结构之间的关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
-
一对多(多对一)
-
多对多
-
一对一
需求:根据页面原型及需求文档 ,完成部门及员工的表结构设计
- 部门管理页面原型:
经过上述分析,现已明确的部门表结构:
- 业务字段 : 部门名称
- 基础字段 : id(主键)、创建时间、修改时间
部门表 - SQL语句:
# 建议:创建新的数据库(多表设计存放在新数据库下)
create database db03;
use db03;
-- 部门表
CREATE TABLE tb_dept(
id INT UNSIGNED AUTO_INCREMENT COMMENT '部门号',
name VARCHAR(10) NOT NULL UNIQUE COMMENT '部门名称',
create_time DATETIME NOT NULL COMMENT '创建时间',
update_time DATETIME NOT NULL COMMENT '更新时间'
) COMMENT '部门表';
部门表创建好之后,我们还需要再修改下员工表。为什么要修改员工表呢?是因为我们之前设计员工表(单表)的时候,并没有考虑员工的归属部门。
CREATE TABLE tb_emp
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT 'ID',
username VARCHAR(20) UNIQUE NOT NULL COMMENT '用户名',
password VARCHAR(32) DEFAULT '123456' NOT NULL COMMENT '密码',
name VARCHAR(10) NOT NULL COMMENT '姓名',
gender TINYINT UNSIGNED NOT NULL COMMENT '性别, 说明: 1 男, 2 女',
image VARCHAR(300) NULL COMMENT '图像',
job TINYINT UNSIGNED NULL COMMENT '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate DATE NULL COMMENT '入职时间',
dept_id INT UNSIGNED COMMENT '归属的部门',
create_time DATETIME NOT NULL COMMENT '创建时间',
update_time DATETIME NOT NULL COMMENT '修改时间'
) COMMENT '员工表';
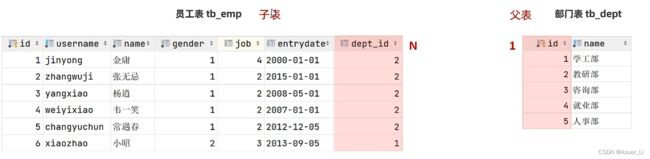
一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
2、外键引入

3、外键
① 一对多/多对一

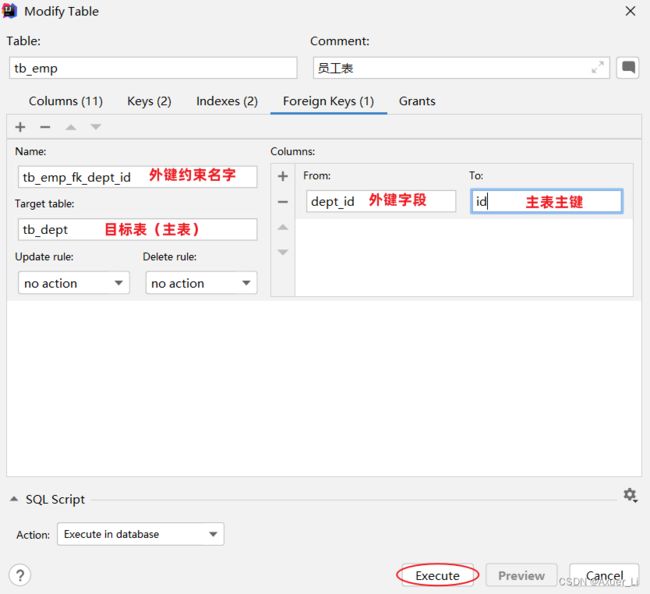
-- 修改表: 添加外键约束
alter table tb_emp
add constraint fk_dept_id foreign key (dept_id) references tb_dept(id);
【物理外键和逻辑外键的区别】

② 一对一


③ 多对多

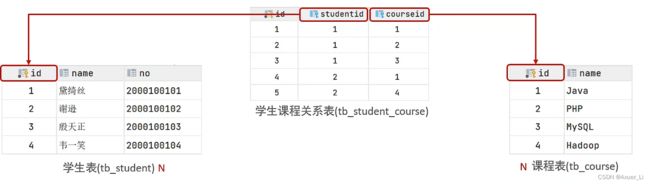
-- 学生表
create table tb_student(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
no varchar(10) comment '学号'
) comment '学生表';
-- 学生表测试数据
insert into tb_student(name, no) values ('黛绮丝', '2000100101'),('谢逊', '2000100102'),('殷天正', '2000100103'),('韦一笑', '2000100104');
-- 课程表
create table tb_course(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '课程名称'
) comment '课程表';
-- 课程表测试数据
insert into tb_course (name) values ('Java'), ('PHP'), ('MySQL') , ('Hadoop');
-- 学生课程表(中间表)
create table tb_student_course(
id int auto_increment comment '主键' primary key,
student_id int not null comment '学生ID',
course_id int not null comment '课程ID',
constraint fk_courseid foreign key (course_id) references tb_course (id),
constraint fk_studentid foreign key (student_id) references tb_student (id)
)comment '学生课程中间表';
-- 学生课程表测试数据
insert into tb_student_course(student_id, course_id) values (1,1),(1,2),(1,3),(2,2),(2,3),(3,4);
4、案例

① 分析各个表之间的关系

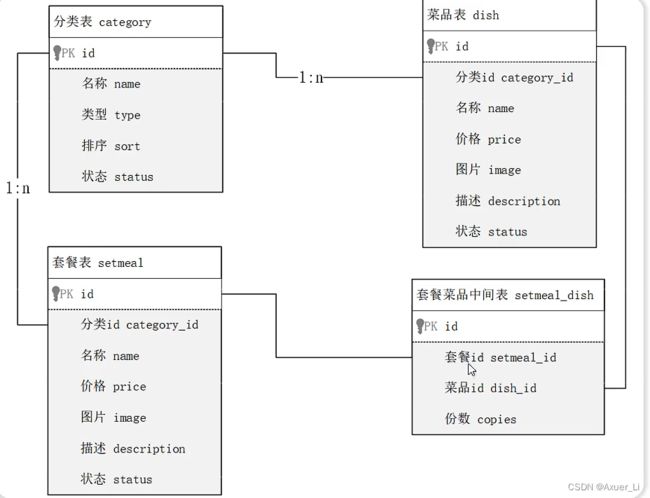
② 分析各个表结构

-- 分类表
create table category
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '分类名称',
type tinyint unsigned not null comment '类型 1 菜品分类 2 套餐分类',
sort tinyint unsigned not null comment '顺序',
status tinyint unsigned not null default 0 comment '状态 0 禁用,1 启用',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间'
) comment '菜品及套餐分类';
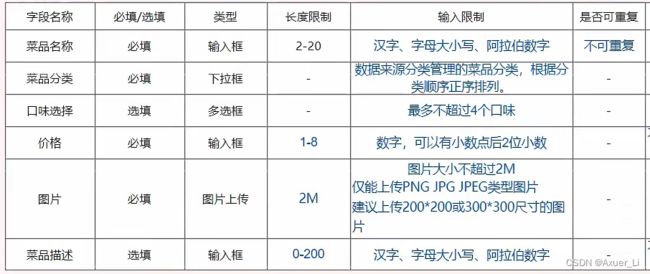
-- 菜品表
create table dish
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '菜品名称',
category_id int unsigned not null comment '菜品分类ID', -- 逻辑外键
price decimal(8, 2) not null comment '菜品价格',
image varchar(300) not null comment '菜品图片',
description varchar(200) comment '描述信息',
status tinyint unsigned not null default 0 comment '状态, 0 停售 1 起售',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间',
constraint dish_category_id_fk
foreign key (category_id) references category (id)
) comment '菜品';
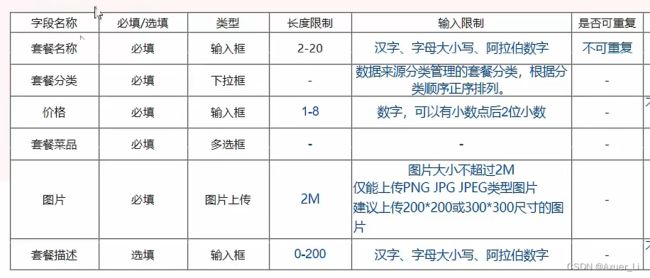
create table setmeal
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '套餐名称',
category_id int unsigned not null comment '分类id', -- 逻辑外键
price decimal(8, 2) not null comment '套餐价格',
image varchar(300) not null comment '图片',
description varchar(200) comment '描述信息',
status tinyint unsigned not null default 0 comment '状态 0:停用 1:启用',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间',
constraint setmeal_category_id_fk
foreign key (category_id) references category (id)
) comment '套餐';

注意套餐菜品关联表中还有一个“份数”字段,因为它也是属于菜品和套餐的关系里的一个属性
-- 套餐菜品关联表
create table setmeal_dish
(
id int unsigned primary key auto_increment comment '主键ID',
setmeal_id int unsigned not null comment '套餐id ', -- 逻辑外键
dish_id int unsigned not null comment '菜品id', -- 逻辑外键
copies tinyint unsigned not null comment '份数',
constraint setmeal_dish_dish_id_fk
foreign key (dish_id) references dish (id),
constraint setmeal_dish_setmeal_id_fk
foreign key (setmeal_id) references setmeal (id)
) comment '套餐菜品关联表';
5、表复制和去重
① 复制
-- 表的复制
-- 为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据
CREATE TABLE my_tab01
( id INT,
`name` VARCHAR(32),
sal DOUBLE,
job VARCHAR(32),
deptno INT);
DESC my_tab01
SELECT * FROM my_tab01;
-- 演示如何自我复制
-- 1. 先把emp 表的记录复制到 my_tab01
INSERT INTO my_tab01
(id, `name`, sal, job,deptno)
SELECT empno, ename, sal, job, deptno FROM emp;
-- 2. 自我复制
INSERT INTO my_tab01
SELECT * FROM my_tab01;
-- 3. 查询这张表有多少行(看是否复制成功)
SELECT COUNT(*) FROM my_tab01;
② 去重
简单来说:
- 准备一张原数据表和两张新数据表(新数据表格式和源数据表一样)
- 然后将源数据拷贝到新表1
- 再对新表1进行去重处理得到新表2
- 再将新表2复制给新表1(在这之前要将新表1清空)
- 最后删除新表2
(按理来说其实可以只创建一张新表,让新表和原表操作,但这样做数据不安全,万一哪里操作错了,源数据已经被改了就没了)
-- 如何删除掉一张表重复记录
-- 1. 先创建一张表 my_tab02,
-- 2. 让 my_tab02 有重复的记录
CREATE TABLE my_tab02 LIKE emp; -- 这个语句 把emp表的结构(列),复制到my_tab02
desc my_tab02;
insert into my_tab02
select * from emp;
select * from my_tab02;
-- 3. 考虑去重 my_tab02的记录
/*
思路
(1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02一样
(2) 把my_tmp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_tmp
(3) 清除掉 my_tab02 记录
(4) 把 my_tmp 表的记录复制到 my_tab02
(5) drop 掉 临时表my_tmp
*/
-- (1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02一样
create table my_tmp like my_tab02
-- (2) 把my_tmp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_tmp
insert into my_tmp
select distinct * from my_tab02;
-- (3) 清除掉 my_tab02 记录
delete from my_tab02;
-- (4) 把 my_tmp 表的记录复制到 my_tab02
insert into my_tab02
select * from my_tmp;
-- (5) drop 掉 临时表my_tmp
drop table my_tmp;
select * from my_tab02;