Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation (译文)
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation (译文)
项目链接
https://yuanxunlu.github.io/projects/LiveSpeechPortraits/
1. 简介
会说话的头部动画,即合成目标人物的音频同步视频帧,对于交互式应用(如数字化身、视频会议、视觉效果、虚拟现实、视频配音和计算机游戏)非常有价值。随着深度学习的最新进展,人们在这个长期存在的问题上取得了巨大的进步。然而,实现逼真且富有表现力的会说话的头部动画仍然是一个开放的挑战。人类对任何面部伪影都极为敏感,因此对所需技术的要求很高。有几个因素促成了这一挑战。首先,尝试生成嘴唇同步和个性化的面部动力学面临双重困难,部分原因是从一维音频信号映射到高维人脸运动的挑战,但也由于野生音频和目标语音空间之间的域差异。这使得该系统无法预先服务于个人的谈话习惯。其次,头部和身体的运动是逼真动画的另一个关键组成部分,与音频没有密切关系。例如,当一个人说同样的话时,他可以摇头,也可以一动不动,这取决于许多因素——他的情绪、地点或历史姿势。第三,合成目标的可控照片级真实感渲染非常简单。如今,传统的渲染引擎仍远未达到预期效果,其结果一目了然就被认为是假的。神经渲染器在照片级真实感渲染方面表现出强大的能力,但如果预测的运动远远超出训练语料库的范围,则会导致性能下降[Kim等人,2018]。最后但并非最不重要的一点是,许多交互场景(如视频会议和数字化身)要求整个系统实时运行,这对系统效率提出了很高的要求,同时又不会损害性能。
在本文中,我们提出了一种称为实时语音肖像(LSP)的深度学习体系结构,以应对这些挑战并进一步走向实际应用。我们的系统生成个性化的说话人头部动画流,包括面部表情和由音频驱动的运动动力学(头部姿势和上身运动),并允许实时真实感渲染。
首先,我们采用了自监督表征学习的思想,它在学习语义或结构表征方面显示出强大的能力,并有利于各种下游任务,以提取与说话人无关的音频特征。为了在野生音频流上实现逼真和个性化的动画,我们进一步将野生特征投影到目标特征空间,并使用目标特征重建它们。这个过程可以看作是从源到目标的域自适应。随后,我们可以学习从重建的音频特征到面部动力学的映射。
另一个重要的组成部分,有助于现实的谈话-头部动画是头部和身体的运动。为了从音频中生成个性化和时间一致的头部姿势,我们假设当前头部姿势部分与音频信息相关,部分与历史姿势相关。我们提出了一种新的自回归概率模型来学习基于这两种条件的目标人的头部姿势分布。根据估计的分布对头部姿势进行采样,并根据采样的头部姿势进一步推断上半身运动。
为了合成照片级真实感渲染,我们采用了一个基于特征映射和可编辑图像的图像到图像的转换网络。我们将采样的刚性头部姿势应用于面部动力学,并将变换后的面部关键点和上身位置投影到图像平面,生成地标图像作为中间表示。虽然我们的系统由几个模块组成,但它仍然足够紧凑,可以以30 fps以上的速度实时运行。总之,我们提出以下贡献:
- 据我们所知,我们提出实时语音Por-traits(LSP)作为第一个具有实时真实感渲染的音频驱动的说话头动画系统。综合评估表明,我们的方法在定性和定量上都优于先前的方法。
- 一种新颖的音频特征提取模块,将我们的系统推广到野生音频信号。该模型的关键组成部分是流形投影,它利用目标语音特征重建深层语音表示。
- 精心设计的概率自回归结构,可根据音频信号和历史运动预测个性化的头部姿势分布。我们的系统还允许用户控制头部姿势生成。
2. 相关工作
从数学上讲,音频驱动的面部动画旨在从输入音频流生成一系列会说话的头部帧。在下文中,我们将回顾音频驱动的面部动画的前期工作,以及语音表征学习、头部姿势估计和面部重现的相关技术。
音频驱动的说话头动画。音频驱动的说话人头部动画是计算机图形学界一个历史悠久的跨模态研究课题。以前的方法根据它们是否旨在生成照片级真实感视频而采用两种不同的方法。在非真实照片的情况下,这些方法侧重于学习从输入波形到面部运动的映射,例如,3D顶点坐标,参考面部模型参数[Taylor等人2017]或索具参数[Zhou等人2018]。这些方法通常需要高质量的4D人脸捕捉数据,或通过艺术家干预操纵参数。在这里,我们将重点放在我们的方法所渴望的真实照片上。二十多年前,人们在这个领域进行了开创性的探索。Bregler等人[1997]建议重写视频,使用现有的视频片段创建一个新的人物对话视频。Brand[1999]提出用声音木偶从音轨生成完整的虚拟动画。这些技术大致可以分为基于视频的编辑方法和基于图像的生成方法。基于视频的编辑方法可以对目标视频进行编辑-通常合成与嘴相关的区域贴片并将其混合到目标帧中,同时保持其他区域不变[Ezzat et al.2002;Garrido et al.2015;Thies et al.2020]。最近,Thies等人[2020]提出将神经语音木偶作为语音木偶的升级。他们首先从音频序列中学习一个通用的3D人脸模型,然后通过学习特定于人的混合形状,在tar-get剪辑上对模型进行微调,在这种情况下,目标肖像的说话风格可以保留下来。最后通过神经渲染网络合成下表面。然而,这些方法有几个固有的局限性。首先,将信息长度限制为目标视频长度。为了生成更长的视频,需要进行启发式后处理以选择合适的候选帧。其次,头部姿势和上半身运动是无法控制的,因为这些动作是直接从目标视频复制的,这可能与音频轨迹冲突,并给实时应用带来障碍。值得注意的是,Suwajanakorn等人[2017]采用了重新计时计划来选择具有自然和同步头部运动的目标帧。最后但并非最不重要的一点是,这些方法依赖于成功的人脸跟踪,当人脸部分不可见或未被检测到时(例如,较低的人脸被手遮挡或在非常黑暗的环境中),这些方法往往会失败。跳过这些不好的帧会导致短暂不一致的结果。相比之下,我们的方法直接合成肖像。在不影响性能的情况下,可在训练前放下阻塞的车架。
基于图像的生成方法基于一个或多个裁剪的参考图像生成对话头部视频。这种方法避免了前面提到的缺点,但对于操作整个图像(包括面部细节、运动动力学和背景)的要求,使任务更具挑战性。随着深度学习的兴起,端到端培训【Chung等人,2017年;Wiles等人,2018年】正在成为制作视频的强大趋势。Chuang等人[2017]首次利用CNN模型,从静止图像和音频序列生成了有声人脸视频。后来,GANs经常被用来通过对抗性学习生成高保真的面部图像[Vougioukas等人,2018年、2019年;Zhou等人,2019年]。Chen等人[2019]和Zhou等人[2020]没有直接合成会说话的人脸图像,而是利用稀疏的人脸标志作为中间表示。landmark Dynamics首先通过音频到landmark模块从音频输入推导出来,然后作为图像到图像转换网络的一个条件来生成动画视频。这些方法共有的一个共同问题是,他们倾向于在训练语料库中学习平均面部动力学,而没有特定于人的谈话风格。请注意,Zhou等人[2020]从说话人嵌入向量中学习了说话人感知动力学,但仍然无法学习目标感知动力学,这可能会产生不可思议的结果。我们的方法专注于只使用一段短的目标视频(大约3分钟)捕捉特定于人的谈话动态。我们利用面部标志作为中间表示,并生成可控的头部姿势和上身运动,这使得动画视频更令人印象深刻和逼真。
语音表征学习。语音信号包含丰富的高级信息,包括内容、音色和韵律。以前的许多工作都要求在毫秒时间内准确地标注音素标签,并将其作为输入。这些标签通常被组合成一系列的标签用于编码邻域信息的双音或三音 [Fan et al. 2015]。然而,将波形转换为音素会导致信息压缩,同时容易出错的自动音素标记工具可能会降低性能。人们还发现了不同的方案,以使用手工制作的功能消除对音素的依赖[Suwajanakorn等人,2017]。最近,通过深度神经网络对这些语义和结构表示进行建模已显示出巨大的成功,并优于传统的手工特征[Devlin等人,2018;Peters等人,2018]。Thies等人[2020]利用DeepSpeech[Han-nun等人2014]网络提取语音特征。Zhou等人[2020]求助于语音转换社区[Qian等人2019]来分离语音内容和身份信息。类似地,我们的系统使用自监督学习方法[Chung and Glass 2020]来提取高级语音信息。此外,采用流形投影来提高泛化能力。
根据音频估计头部姿势。头部姿势作为真实感动画的重要组成部分,在有声头部视频中提供了丰富的信息。Greenwood等人[2018]采用双向LSTM模型从音频预测角色头部动画。Zhou等人[2020]预测说话人感知的头部运动动力学为3D面部标志性位移。他们在对抗机制中培训了转换器架构[Vaswani et al.2017],以限制长时间依赖并产生自然的头部动态。最近,Chen等人[2020a]提出了一种3D感知生成网络,用于从3秒钟的视频剪辑中学习目标感知的头部运动。与以往大多数使用确定性模型的工作不同,我们使用基于历史头部姿势和语音表示的自回归概率模型来预测当前时间戳的分布参数。头部姿势从预测的概率模型中采样。此外,我们进一步从预测的头部姿势推断出上半身的运动,这表明动画质量有了很大的提高。
基于视频的面部重现。基于视频的面部重现是另一种与音频驱动动画相关的技术。Thies等人[2015]提出了第一个使用两个RGBD摄像机的基于模型的实时再现系统。Face2Face[Thies et al.2016]仅使用RGB摄像机扩展边界。此外,Liu等人[2015]将音频和视频信息结合起来作为输入,解决了人脸被遮挡或头部姿势极端时跟踪结果容易失败的问题。Fried等人[2019]提出了一种基于文本的说话人头部编辑方法,而viseme搜索速度较慢(三个单词5分钟)。Yao等人[2021]将一个视频的视频生成时间缩短到40秒。最近,GANs在可控高保真人脸合成方面取得了巨大成功[Karras et al.2019;Wang et al.2018a,b]。通过在无监督方案中预先定义或学习的地标探索很少的镜头或甚至一次镜头面部动画方法[Siarohin等人2019;Sun等人2020;Zakharov等人2019]。大多数方法依赖于以语义图像作为输入的图像到图像机制。Kim等人[2018]通过输入参考视频生成了包括头部、嘴巴和凝视的肖像视频。Kim等人[2019]训练了一名复现的GAN来合成保留风格的视觉配音。最近,Elgharib在al.[2020]使用位置条件转换将以自我为中心的视图视频转换为面向前方的视频。与以前的方法不同,我们的方法仅从语音生成照片级真实感说话人头部动画,并实时运行。
3. 方法
概述。在给定任意语音流的情况下,我们的实时语音特征方法会实时生成目标人物的真实照片级说话头部动画(图2)。我们的方法包括三个阶段:深度语音表示提取、音频到人脸预测和真实感人脸渲染。第一阶段提取输入音频的语音表示(第3.1节)。表示提取器学习高级语音表示,并在未标记的语音语料库上以自我监督的方式进行训练。然后,我们将表示投影到目标人的语音空间,以提高泛化能力。第二阶段预测全运动动力学。两个精心设计的神经网络分别从语音表征预测与嘴相关的运动(第3.2节)和头部姿势(第3.3节)。与嘴相关的运动表示为稀疏的3D地标,头部姿势表示为刚性旋转和平移。考虑到头部姿势与声音信息的相关性小于与嘴相关的动作,我们采用概率自回归模型来学习以声音信息和历史姿势为条件的姿势。从训练集中采集与音频几乎没有关联的其他面部成分(例如眼睛、眉毛、鼻子等)。然后,我们根据预测的头部姿势计算上半身的运动。最后阶段使用条件图像到图像转换网络,从先前的预测和候选图像集(第3.4节)合成照片级真实感视频帧。下面,我们将详细介绍每个模块。

图2。我们的现场演讲肖像方法概述。在给定任意音频流的情况下,我们的方法实时生成目标人物的个性化和照片级真实感对话动画。首先,使用流形投影提取和重构输入音频的深层语音表示。然后,根据重建的语音表示预测与嘴相关的运动、头部姿势和上身运动。然后,我们通过投影预测的运动和其他采样的面部组件来生成条件特征映射。最后,我们将条件特征映射和候选图像集发送到图像到图像转换网络,以合成照片级真实感对话肖像。视频奥巴马®巴拉克奥巴马基金会(公共领域)。
3.1深度语音特征提取
在我们的例子中,输入信息是语音信号,它起着至关重要的作用,因为它为整个系统提供动力。如第2部分所言,人们利用深度学习方法,通常在自我监督机制下进行训练,从表面特征学习高级非特定人语音表示。这些方法极大地提高了下游任务的最先进性能,例如自动语音识别、电话分类和说话人验证[Chorowski等人,2019年;Liu等人,2020年;Oord等人,2018年]。这些方法成功的原因之一是,与人类标记数据集的有限大小相比,可以自由利用大量未标记数据。
具体而言,我们使用自回归预测编码(APC)模型[Chung and Glass 2020]来提取结构性语音表达。APC模型根据历史信息预测未来的表面特征。在我们的例子中,我们选择80维对数Mel谱图作为语音表面特征。该模型是一个标准的3层单向选通循环单元(GRU):
h l = G R U ( l ) ( h l − 1 ) , ∀ l ∈ [ 1 , L ] \mathbf{h}_{l}=G R U^{(l)}\left(\mathbf{h}_{l-1}\right), \forall l \in[1, L] hl=GRU(l)(hl−1),∀l∈[1,L]
这里 h l ∈ R 512 \mathbf{h}_{l} \in \mathbb{R}^{512} hl∈R512是GRU中每个层的隐藏状态。最后一个GRU层中的隐藏状态是我们想要的深层语音表示。我们在训练过程中添加一个线性层来映射输出,以预测未来的对数Mel谱图,并且在测试过程中删除线性层。
3.1.1 流形投影
不同的人拥有不同的说话风格,这被认为是个性化的风格。例如,May发音表现出较大的嘴唇运动,始终是“O”型,Ford 发音表现出较小的嘴唇运动,如耳语,Nadella 发音表现出上下嘴唇的粘连,如口齿不清。当输入语音表示远离目标语音特征空间时(例如,用男人的声音、外国语言甚至歌曲为女人制作动画),直接应用深度语音表示可能会导致较差的结果。为了提高泛化能力,我们在提取语音表示后进行流形投影。
流形投影操作的灵感来源于最近从草图中合成人脸的成功【Chen等人,2020c】,可以推广到远离人脸的草图。我们在语音表示流形上应用局部线性嵌入(LLE)假设:每个数据点及其邻域在高维流形上都是局部线性的[Roweis和Saul 2000]。

图 3. 流形投影。左:对于每个原始深度特征,我们将其投影到目标特征空间。右图:放大原始特征(黄色), =5 最近邻(棕色)和重建特征(红色)。
给定一个提取的语音表示 h ∈ R 512 \mathbf{h} \in \mathbb{R}^{512} h∈R512,我们计算LLE重构表示 h ^ ∈ R 512 \hat{\mathbf{h}} \in \mathbb{R}^{512} h^∈R512,如图3所示,我们在目标语音表示数据库 D ∈ R N s × 512 \mathcal{D} \in \mathbb{R}^{N_{s} \times 512} D∈RNs×512 中找到距离 h \mathbf{h} h最近的 K K K个点(通过计算欧几里德距离)。 _ Ns是训练的帧数。然后,我们寻求 K个最近邻居的线性组合来最好地重建 h \mathbf{h} h,这相当于通过解决以下最小化问题,基于其邻居计算 h \mathbf{h} h 的重心坐标:
min ∥ h − ∑ k = 1 K w k ⋅ f k ∥ 2 2 , s.t. ∑ k = 1 K w k = 1 \min \left\|\mathbf{h}-\sum_{k=1}^{K} w_{k} \cdot \mathbf{f}_{k}\right\|_{2}^{2}, \quad \text { s.t. } \sum_{k=1}^{K} w_{k}=1 min∥∥∥∥∥h−k=1∑Kwk⋅fk∥∥∥∥∥22, s.t. k=1∑Kwk=1
其中 w k w_{k} wk是-最近邻 f k \mathbf{f}_{k} fk 的重心权重,可以通过求解最小二乘问题来计算。 在我们的实验中根据经验选择为 10。最后,我们得到投影语音表示 h ^ \hat{\mathbf{h}} h^。
h ^ = ∑ k = 1 K w k ⋅ f k \hat{\mathbf{h}}=\sum_{k=1}^{K} w_{k} \cdot \mathbf{f}_{k} h^=k=1∑Kwk⋅fk
随后,将 h ^ \hat{\mathbf{h}} h^ 作为输入深度语音表示发送到第 3.2 节和第 3.3 节中的运动预测器。我们的实验结果表明流形投影有助于提高我们的系统泛化能力。由于复杂性,尚未考虑非线性投影。
3.2 音频到口腔相关运动
在过去几年中,人们广泛研究了从音频中预测与嘴巴相关的运动。人们使用深度学习架构来学习从音频特征到中间表示的映射,例如与嘴唇相关的地标 [Greenwood et al. 2018 年;周等人。 2020],参数模型的参数 [Chen et al. 2019; Suwajanakorn 等。 2017;泰勒等人。 2017],3D 顶点 [Cudeiro 等人。 2019;卡拉斯等人。 2017],或面部混合形状 [Thies 等人。 2020 年;周等人。 2018]。在我们的例子中,我们使用 3D 位移 Δ v m ∈ R 25 × 3 \Delta \mathbf{v}_{m} \in \mathbb{R}^{25 \times 3} Δvm∈R25×3相对于目标人在对象坐标中的平均位置作为我们的中间表示。
为了对序列依赖性进行建模,我们使用长短期记忆 (LSTM) 模型来学习从语音表示到与嘴巴相关的运动的映射。类似于 [Suwajanakorn 等人。 2017],我们添加了 帧延迟,使模型可以在短期内访问,从而显着提高质量。我们稍后将 LSTM 网络的输出提供给多层感知 (MLP),并最终预测 3D 位移 Δ v m \Delta \mathbf{v}_{m} Δvm。综上所述,我们的口腔相关预测模块的工作原理如下:
m 0 , m 1 , … , m t = LSTM ( h ^ 0 , h ^ 1 , … , h ^ t + d ) Δ v m , t = M L P ( m t ) \begin{aligned} \mathbf{m}_{0}, \mathbf{m}_{1}, \ldots, \mathbf{m}_{t} &=\operatorname{LSTM}\left(\hat{\mathbf{h}}_{0}, \hat{\mathbf{h}}_{1}, \ldots, \hat{\mathbf{h}}_{t+d}\right) \\ \Delta \mathbf{v}_{m, t} &=M L P\left(\mathbf{m}_{t}\right) \end{aligned} m0,m1,…,mtΔvm,t=LSTM(h^0,h^1,…,h^t+d)=MLP(mt)
其中时间延迟 设置为 18 帧,相当于我们实验中的 300 毫秒延迟(60 FPS)。 LSTM 堆叠成三层,每层有一个大小为 256 的隐藏状态。 MLP 解码器网络有三层,隐藏状态大小分别为 256、512 和 75。
3.3 概率头部和上身运动合成
头部姿势和上半身运动是另两个有助于生动对话的头部动画的组成部分。例如,人们在谈话时自然地摆动头部和移动身体,旨在向观众表达情感和表达态度。我们首先描述估计头部姿势和上半身运动的方法。
基于音频的头部姿势估计是非常重要的,因为它们之间几乎没有关系。考虑到固有的困难,即从音频到头部姿势的一对多映射(一个人可以在任意姿势中说同一个句子),我们将两个假设作为先验知识。
假设1。头部姿势部分与声音信息有关,如表情和语调。例如,人们在表达同意时倾向于点头,在用上升音调说话时倾向于抬头,反之亦然。
假设2。当前头部姿势部分取决于历史头部姿势。例如,如果人们以前转了一个大角度,他们很可能会回头。
这两个假设简化了问题并激发了我们的架构设计。为了满足这些要求,建议的网络系统应具备将历史头部姿势和当前音频信息视为条件的能力。此外,我们不应将其视为回归问题并使用欧几里德距离损失对其进行训练[Zhou等人,2020],而应将该映射建模为概率分布。最近,概率模型成功地应用于运动合成[Henter et al.2020],其性能优于确定性模型。头部运动的联合概率可描述如下:
p ( x ∣ h ^ ) = ∏ t = 1 T p ( x t ∣ x 1 , x 2 , … , x t − 1 , h ^ t ) p(\mathbf{x} \mid \hat{\mathbf{h}})=\prod_{t=1}^{T} p\left(x_{t} \mid x_{1}, x_{2}, \ldots, x_{t-1}, \hat{\mathbf{h}}_{t}\right) p(x∣h^)=t=1∏Tp(xt∣x1,x2,…,xt−1,h^t)
这里 x 是头部运动, h ^ \hat{\mathbf{h}} h^ 是言语表征。
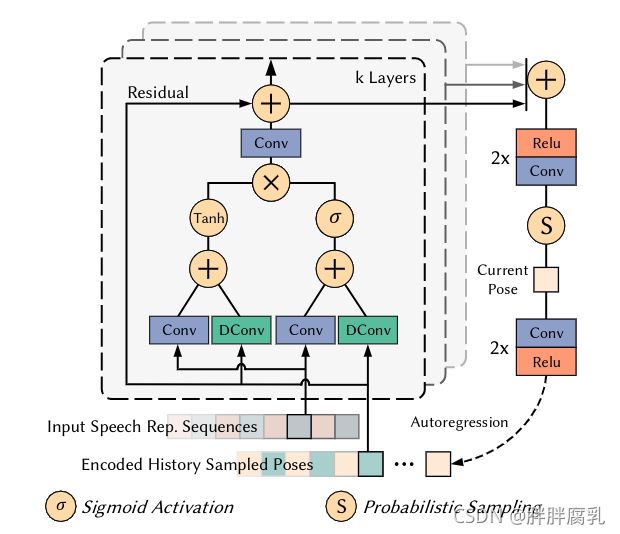
图 4. 我们的概率头部姿势估计网络的图示。该图展示了一个示例架构,它由一个具有三层的残差块组成。
我们使用的概率模型是多维高斯分布。该网络体系结构的灵感来源于最近在条件概率生成建模方面取得的成功[Oord et al. 2016a,b]。概率模型的详细设计如图 4 所示。该模型是两个残差块的堆栈,每个块有七层。考虑到产生自然头部运动所需的长时间依赖(从左到右摆动头部可能持续几秒钟),这些残差块使用扩张卷积层来捕获依赖关系,而不是参数少得多的普通卷积。在我们的架构中,每一层的膨胀都加倍了七次,然后重复了两次:1、2、4、8、16、32、64、1、2、4、8、16、32、64。结果,我们模型的历史感受野大小 是 255 帧,在我们的实验中等于 4.25 秒。每一层的输出被一个后处理网络(一个由 2 个 reluconv 层组成的堆栈)相加和处理,以生成当前的分布。特别是,该模型输出估计高斯分布的平均值 和标准差 。然后我们在分布中采样以获得最终的刚性头部姿势 P ∈ R 6 P \in \mathbb{R}^{6} P∈R6,,由3D旋转 R ∈ R 3 R \in \mathbb{R}^{3} R∈R3和平移 T ∈ T 3 T \in \mathbb{T}^{3} T∈T3组成。我们还尝试了高斯混合模型,但没有发现明显的改进。采样后,我们将当前姿势编码为下一个时间步的输入姿势信息,形成自回归机制。总之,头部姿态估计可以说明如下:
P para, t = Φ ( P t − F , … , P t − 1 , h ^ t ) P t = Sample ( P para , t ) \begin{aligned} \mathbf{P}_{\text {para, } t} &=\Phi\left(\mathbf{P}_{t-F}, \ldots, \mathbf{P}_{t-1}, \hat{\mathbf{h}}_{t}\right) \\ \mathbf{P}_{t} &=\text { Sample }\left(\mathbf{P}_{\text {para }, t}\right) \end{aligned} Ppara, tPt=Φ(Pt−F,…,Pt−1,h^t)= Sample (Ppara ,t)
上身运动。对于上身运动估计,一种理想的方法是建立身体模型并估计参数[Mehta et al. 2020]。为了避免使算法过于复杂(上半身总是仅位于图像的底部),我们将上半身指定为广告牌 [Cao et al. 2016] 由手动定义的几个肩部地标形成。广告牌的初始深度被设置为完整训练序列中地标的平均深度,并且所有的都相同。在大多数情况下,我们用预测的头部运动 P 中的 50% 平移部分 T T T 来翻译广告牌模型作为结果。
3.4 逼真图像合成
我们方法的最后一个阶段是根据先前的预测生成逼真的面部渲染,如图 2 所示。我们的渲染网络受到合成逼真和可控面部视频的最新进展的启发 [Elgharib 等人。 2020 年;伊索拉等人。 2017;金等人。 2018 年;蒂斯等人。 2019]。我们使用条件图像到图像的翻译网络作为我们的主干以及对抗性训练。该网络将条件特征图和 = 4 个目标人物的候选图像按通道串联起来,以生成逼真的渲染效果。

图 5. 我们的条件特征图的一个例子。不同的颜色用于说明不同的语义子集。例如,绿色表示眼睛和眉毛,蓝色表示上身线条。在实际实验中,条件特征图是单色的,如图2。
条件特征图。为了提供面部和上半身的线索,我们从上述预测中为每一帧绘制条件特征图。条件图的示例如图 5 所示。特征图由面部部分和上半身部分组成。用颜色绘制语义区域,甚至更远的一个区域,一个通道会带来更丰富的信息和更多的绘制时间。我们没有发现这两个替代方案有明显的改进。请注意,我们预测的稀疏面部标志和上身广告牌都位于对象坐标中。因此,我们需要通过预先计算的相机内在参数 将这些 3D 位置投影到 2D 图像平面。我们使用的相机模型是针孔相机模型, K = [ f 0 c x ; 0 f c y ; 0 0 1 ] K=\left[\begin{array}{llll}f & 0 & c_{x} ; 0 & f & c_{y} ; 0 & 0 & 1\end{array}\right] K=[f0cx;0fcy;001],其中 f是焦距, ( c x , c y ) \left(c_{x}, c_{y}\right) (cx,cy)是主点。连续的 2D 投影组件以预先定义的语义序列进行线连接,从而产生大小为 1 × 512 × 512 1 \times 512 \times 512 1×512×512 的条件特征图。

图 6. 我们的音频驱动的说话头动画结果的图库。给定任意音频流,我们的方法首先生成个性化的面部动态、头部姿势和上半身运动,然后根据这些预测合成逼真的渲染。有关完整序列,请参阅补充视频。视频(左上角)奥巴马 ©Barack Obama Foundation(公共领域)。 Video May ©英国政府(开放政府许可证)。视频 Nadella ©IEEE 计算机协会(公共领域)。视频特朗普©白宫(公共领域)。视频(右下角)奥巴马 ©White House(公共领域)。
候选图像集。除了条件特征图外,我们还输入了目标人物的候选图像集,以提供详细的场景和纹理线索。我们发现,考虑到训练集中不断变化的相机运动,添加这样一个候选集有助于网络生成一致的背景,并减轻网络合成细微细节(如牙齿和毛孔)的压力。这些图像是自动选择的。对于前两个,我们选择第 100 个最小/最大嘴巴区域。对于其余部分,我们按均匀间隔对 x 轴和 y 轴旋转进行采样,并从间隔中选择最近的样本。因此,最终连接后的输入图像的大小变为 13 ( 1 + 3 × 4 ) × 512 × 512 13(1+3 \times 4) \times 512 \times 512 13(1+3×4)×512×512。该网络是一个类似 UNet 的 8 层 [Esser 等人。 2018 年;韩等人。 2019; Ronneberger 等人。 2015] 在每个分辨率层中具有跳跃连接的卷积神经网络。每层的分辨率为 ( 25 6 2 , 12 8 2 , 6 4 2 , 3 2 2 , 1 6 2 , 8 2 , 4 2 , 2 2 ) \left(256^{2}, 128^{2}, 64^{2}, 32^{2}, 16^{2}, 8^{2}, 4^{2}, 2^{2}\right) (2562,1282,642,322,162,82,42,22),对应的特征通道数为(64, 128, 256, 512, 512, 512, 512, 512) .每个编码器层由一个卷积(步幅 2)和一个残差块组成。对称解码器层几乎相同,除了第一个卷积被最近的上采样操作替换,比例因子为 2。我们的真实感渲染示例如图 6 所示。
4 实施细节
在本节中,我们将描述与我们的方法实现相关的方面:数据集获取和预处理(第 4.1 节)、损失函数(第 4.2 节)、训练设置(第 4.3 节)和实时动画设置(第 4.4 节)
4.1 数据集获取与预处理
我们将我们的方法应用于 7 个不同主题的 8 个不同目标序列进行训练和测试。这些序列跨越 3-5 分钟的范围。所有视频均以每秒 60 帧(FPS)的速度提取,并且同步的音频波以 16 Hz 频率采样。我们首先裁剪视频以保持人脸居中,然后调整为 512×512。所有输入图像和输出图像共享相同的分辨率。我们将视频分成 80% / 20% 用于训练和验证。有关详细信息,请参阅附录 A。
我们使用现成的工具检测所有视频的 73 个预定义的面部标志。为了提供 3D 嘴形和头部姿势的真实情况,我们采用了一种基于优化的 3D 面部跟踪算法,类似于 [Shi et al. 2014;蒂斯等人。 2016]。对于相机校准,我们使用二分搜索来计算焦距 f ,如 [Cao 等人。 2013]。主点 ( c x , c y ) \left(c_{x}, c_{y}\right) (cx,cy) 被设置为图像的中心。请注意,我们对原始图像进行相机校准和 3D 面部跟踪,并根据裁剪和调整大小参数计算变换矩阵。对于每个序列的第一帧手动选择一次上身运动特征点,并使用 LK 光流跟踪其余帧 [Bouguet 等人。 2001] 和 OpenCV 实现 [Bradski 2000]。有关单目 3D 人脸跟踪的更多详细信息,我们建议读者参考摘要论文 [Zollhöfer 等人。 2018]。
为了训练 APC 语音表示提取器,我们使用了 Common Voice 数据集的普通话中文部分 [Ardila et al. 2020] 提供未标记的狂野话语。具体来说,该子集包含 889 个不同口音的说话者。总共有大约 26 小时的未标记话语。我们使用 80 维对数梅尔谱图作为表面特征。 log mel 谱图是使用 1/60 秒帧长、1/120 秒帧移和 512 点短时傅立叶变换 (STFT) 计算的。尽管我们的 APC 模型是用普通话训练的,但我们发现我们的系统在其他语言中仍然运行良好,因为该模型学习了高级和语义信息。流形投影也提高了泛化能力。
4.2 损失函数
4.2.1 深度语音表征提取
APC 模型的训练是完全自我监督的,通过预测前面的表面特征 帧。给定一系列对数梅尔谱图 ( x 1 , x 2 , … , x T ) \left(x_{1}, x_{2}, \ldots, x_{T}\right) (x1,x2,…,xT),APC 模型在时间步长 t 处理每个元素 _ xt 并输出预测 _ yt,生成预测序列 ( y 1 , y 2 , … , y T ) \left(y_{1}, y_{2}, \ldots, y_{T}\right) (y1,y2,…,yT)。我们通过最小化输入序列和预测之间的 L1 损失来优化模型,如下所示:
∑ i = 1 T − n ∣ x i + n − y i ∣ \sum_{i=1}^{T-n}\left|x_{i+n}-y_{i}\right| i=1∑T−n∣xi+n−yi∣
其中 = 3 =3 n=3 遵循 [Chung and Glass 2020] 中的设置。
4.2.2 音频到口腔相关运动
为了学习从音频到嘴巴相关运动的映射,我们最小化了真实嘴巴位移和预测位移之间的 2 2 L2 距离。具体来说,损失可以写为:
∑ t = 1 T ∑ i = 1 N ∥ Δ v m , t − Δ v ^ m , t ∥ 2 2 \sum_{t=1}^{T} \sum_{i=1}^{N}\left\|\Delta \mathbf{v}_{m, t}-\Delta \hat{\mathbf{v}}_{m, t}\right\|_{2}^{2} t=1∑Ti=1∑N∥Δvm,t−Δv^m,t∥22
其中 = 240 = 240 T=240 表示每次迭代时发送到模型的连续帧数。 = 25 =25 N=25 是我们实验中预先定义的稀疏嘴相关 3D 点的数量。
4.2.3 概率头部运动合成
除了学习从音频到嘴巴相关运动的映射之外,我们还旨在估计训练期间目标的头部姿势。上半身运动可以从 3.3 节中提到的头部姿势推断出来。具体来说,我们采用自回归概率模型来模拟头部姿势分布。我们通过最小化姿势分布的负对数似然来训练模型。给定一系列历史头部姿势 ( x t − F , … , x t ) \left(x_{t-F}, \ldots, x_{t}\right) (xt−F,…,xt)和语音表示 h t \mathbf{h}_{t} ht ,概率损失为:
− ln ( N ( x t , h t ∣ μ ^ n , σ ^ n ) ) -\ln \left(\mathcal{N}\left(\mathbf{x}_{t}, \mathbf{h}_{t} \mid \hat{\mu}_{n}, \hat{\sigma}_{n}\right)\right) −ln(N(xt,ht∣μ^n,σ^n))
其中 x t , h t \mathbf{x}_{t}, \mathbf{h}_{t} xt,ht 是时间 t 的输入头部姿势和语音表示。这个损失项迫使模型输出高斯分布的平均值 μ ^ n \hat{\mu}_{n} μ^n 和标准差 σ ^ n \hat{\sigma}_{n} σ^n。为了增加数值稳定性,我们直接输出负对数 sigma 而不是 sigma。姿态序列中的每个元素 x t ∈ R 12 \mathbf{x}_{t} \in \mathbb{R}^{12} xt∈R12 由当前姿态 p t ∈ R 6 \mathbf{p}_{t} \in \mathbb{R}^{6} pt∈R6和线速度项 Δ p t ∈ R 6 \Delta \mathbf{p}_{t} \in \mathbb{R}^{6} Δpt∈R6组成。尽管我们在分布中采样后仅使用旋转和平移的前六个维度,但我们发现添加这样的速度项可以隐式地强制模型关注运动速度,从而导致更平滑的结果。
4.2.4 逼真图像合成
最后,我们训练神经渲染器来合成逼真的头部说话图像。训练过程遵循对抗训练机制 [Goodfellow et al. 2014]。我们采用多尺度 PatchGAN 架构 [Isola 等人。 2017;王等人。 2018b] 作为判别器 D 的骨干。图像到图像的翻译网络 G 被训练生成“真实”图像来欺骗判别器 D,而判别器 D 被训练来区分生成的图像和真实图像。具体来说,我们采用 LSGAN 损失 [Mao 等人。 2017] 作为优化判别器 D 的对抗性损失:
L G A N ( D ) = ( r ^ − 1 ) 2 + r 2 \mathcal{L}_{G A N}(\mathbf{D})=(\hat{r}-1)^{2}+r^{2} LGAN(D)=(r^−1)2+r2
其中 r ^ , r \hat{r}, r r^,r分别是输入真实图像 y ^ \hat{y} y^ 和生成的渲染 y 时的判别器分类输出。我们还使用了颜色损失、感知损失 [Johnson et al. 2016] 和特征匹配损失 [Wang et al. 2018b]:
L G = L G A N ( G ) + λ C L C + λ P L P + λ F M L F M \mathcal{L}_{G}=\mathcal{L}_{G A N}(\mathbf{G})+\lambda_{C} \mathcal{L}_{C}+\lambda_{P} \mathcal{L}_{P}+\lambda_{F M} \mathcal{L}_{F M} LG=LGAN(G)+λCLC+λPLP+λFMLFM
其中 L G A N ( G ) = ( r − 1 ) 2 \mathcal{L}_{G A N}(\mathbf{G})=(r-1)^{2} LGAN(G)=(r−1)2 是对抗性损失, L C \mathcal{L}_{C} LC 是颜色损失, L P \mathcal{L}_{P} LP 是感知损失, L F M \mathcal{L}_{FM} LFM 是特征匹配损失。在我们所有的实验中,每个损失的权重 λ C , λ P , λ F M \lambda_{C}, \lambda_{P}, \lambda_{F M} λC,λP,λFM 都根据经验设置为 (100,10,1)。颜色损失是 1 1 L1 每像素损失,以最小化生成图像 y 和真实图像 ^ \hat y^ 的差异: L C = ∥ y − y ^ ∥ 1 \mathcal{L}_{C}=\|y-\hat{y}\|_{1} LC=∥y−y^∥1 。我们在嘴巴上尝试了更高的权重 (x10),是的,嘴巴相关的错误减少了,但全图像错误增加了。考虑到全图像生成任务,我们选择相等的权重。对于感知损失,我们采用 VGG19 网络 [Simonyan and Zisserman 2014] 从 ^ \hat y^ 和 y 中提取感知特征,并最小化它们的 1 1 L1 距离:
L P = ∑ i ∈ S ∥ ϕ ( i ) ( y ) − ϕ ( i ) ( y ^ ) ∥ 1 \mathcal{L}_{P}=\sum_{i \in \mathcal{S}}\left\|\phi^{(i)}(y)-\phi^{(i)}(\hat{y})\right\|_{1} LP=i∈S∑∥∥∥ϕ(i)(y)−ϕ(i)(y^)∥∥∥1
这里 S = { 1 , 6 , 11 , 20 , 29 } \mathcal{S}=\{1,6,11,20,29\} S={1,6,11,20,29} 表示我们使用的层, ϕ ( i ) \phi^{(i)} ϕ(i) 表示第 i i i 层. 最后,为了提高训练速度和稳定性, 我们采用特征匹配损失:
L F M = ∑ i = 1 L ∥ r − r ^ ∥ 1 \mathcal{L}_{F M}=\sum_{i=1}^{L}\|r-\hat{r}\|_{1} LFM=i=1∑L∥r−r^∥1
其中 是判别器 D D D 中的空间层数。基于 1 1 L1 的特征匹配损失旨在匹配判别器从 ^ \hat y^ 和 y 提取的特征的统计数据。
4.3 训练设置和参数
我们所有的模型都是在 PyTorch (Python) 上训练的 [Paszke et al. 2019] 使用 Adam 优化器和超参数 ( β 1 , β 2 ) = ( 0.9 , 0.999 ) \left(\beta_{1}, \beta_{2}\right)=(0.9,0.999) (β1,β2)=(0.9,0.999)。在所有实验中,学习率设置为 1 0 − 4 10^{-4} 10−4 衰减至 1 0 − 5 10^{-5} 10−5。 APC模型包含4.064参数,嘴相关位置预测器包含3.064参数,头部姿态估计器包含4.267参数,渲染器包含76.204参数。我们在 Nvidia 1080Ti GPU 上训练前三个模型,总共需要 ( 11 , 0.5 , 5 ) (11, 0.5, 5) (11,0.5,5) 小时 ( 200 , 200 , 200 ) (200, 200, 200) (200,200,200) epochs,批大小分别为 32。逼真的图像渲染器在 4 个 Nvidia 1080Ti GPU 上进行了平均 22 小时的训练,训练时间为 60 个时期,批次大小为 8。在测试期间,我们选择验证损失最小的所有模型。
4.4 实时动画
我们在配备 Intel Core i7-9700K CPU(32 GB RAM)和 NVIDIA GeForce RTX 2080(8 GB RAM)的台式机上使用 C++ 实现和测试我们的实时动画系统。深度语音表示提取模块进行推理需要大约 2.9 毫秒(APC 模型前向传递需要 1.4 毫秒,流形投影需要 1.5 毫秒)。通过音频表示学习面部动态 3 层 LSTM 和 MLP 网络大约需要 2.5 毫秒。此外,Audio2Mouth 模块导致获取 18 帧未来音频信息的延迟约为 300 毫秒。然后我们使用 Tensorrt 来加速最后两个模型。具体来说,头部姿势估计模型需要 4.4 毫秒,而真实感渲染器在加速后需要 20.1 毫秒。 CPU 和 GPU 之间的内存复制时间已经包含在这里。因此,整个系统以超过 30 FPS 的速度进行推理大约需要 27.4 毫秒,延迟为 300 毫秒。
讨论。在这里,我们与 Zhou 等人的相关工作讨论了运行时间。 [2020] 和 Thies 等人。 [2020]。我们强调,考虑到这些论文没有展示实际的现场演示,我们的系统是第一个实现逼真的音频驱动说话头动画的端到端实时系统,并进一步走向实际应用。此外,周等人。 [2020] 不是为实时流媒体生成而设计的。自注意力网络 [Vaswani et al. 2017] 在扬声器感知动画中作为先前地标预测的后加权组合,不适用于视频会议等需要低延迟的实时应用程序。蒂斯等人。 【2020】会遇到更多困难。他们的方法受限于目标视频长度,因此需要足够长且无遮挡的目标视频,这很难获取。为了生成更长的帧,需要额外的启发式调度来选择合适的候选帧。此外,由于缺乏对头部运动的控制,会出现姿势音频不一致(第 2 节)。这些因素导致现场实施的障碍。
5. 结果
我们的现场演讲肖像方法实时从音频输入生成个性化和照片逼真的谈话头部动画。我们建议读者观看补充视频。
在下文中,我们展示了我们的方法的结果,定性和定量地评估了我们方法的设计,与最先进的技术进行了比较,并展示了用户研究的结果。我们进一步展示了几种应用的潜力,例如,配音、视频会议和虚拟化身。
5.1 定性评价
略
5.2 定量评价
略
5.3 与最先进技术的比较
略
5.4 用户研究
略
5.5 应用
我们的方法从音频流中实时合成逼真的头部谈话动画,因此具有广泛的应用,例如,配音、视频会议和虚拟化身。我们向读者推荐我们的补充视频。图 16 展示了潜在的应用。在图的顶部,我们展示了目标人物的音频驱动配音结果。与基于视频的配音方法相比 [Kim 等人。 2019],我们的方法避免了生成目标人物令人难以置信的面部动态,因为我们对个人特征进行了建模。
视频会议是另一个应用(见图 16 (b))。在人们无法传递视觉信号的场景中,例如他们在户外或带宽有限,我们的方法可以实时生成仅由音频驱动的高保真视频帧。
我们最终在虚拟主播、助手等虚拟化身中展示了我们的潜力。我们的补充视频展示了虚拟化身的实时演示,例如,特蕾莎·梅的肖像被动画化,以通过演员的声音演唱歌曲。图 16 © 显示了由文本到语音 (TTS) 系统驱动的结果。补充视频还包括与 Zhou 等人的比较。 [2020] 和 Thies 等人。 [2020]。我们的方法生成更逼真的帧和更准确的唇形同步。
6. 结论
我们提出了一种深度学习方法,用于实时生成目标人物的逼真的头部说话动画。我们的方法可以处理训练期间看不到的新音频剪辑,并且仍然可以合成个性化的视频帧。整个系统只需要在几分钟长的视频上进行训练。我们的管道包含三个阶段:深度音频特征提取、面部动态和运动生成以及逼真的图像合成。第一阶段包括对深度音频特征的多方面投影,这有助于泛化到狂野的音频。在第二阶段,生成面部动态、头部姿势和上半身运动。训练一个自回归概率头部姿势估计网络来学习目标演员的姿势分布。该网络导致个性化的头部姿势生成,并避免了后续神经渲染器的潜在性能下降。最后,我们从这些预测中生成中间特征图,并将它们与候选图像集一起发送到图像到图像转换网络以合成视频帧。彻底的实验和用户研究表明,我们的方法在定性和定量上都优于最先进的技术。我们的方法可以应用于很多场景,尤其是需要实时运行的场景,比如配音、视频会议和虚拟化身。我们希望这项工作可以为未来的研究在该领域开辟一条新的途径。
局限性和未来的工作。虽然我们已经在各种场景中展示了我们方法的令人印象深刻的结果,但我们的方法仍然存在一些限制。我们的实时系统并不总是能很好地捕捉爆破音和鼻辅音,例如 /p/b/m/。背后的原因是多种多样的。首先,/p/b/m/ 通常声音很小,可能会被前端作为环境噪音忽略。其次,我们的直播系统以超过 30 FPS 的速度运行,它可能会错过这些短促的声音。它也无法以非常快的速度捕捉演讲,就像吵架一样。我们的离线结果(60FPS)更好,这在一定程度上验证了我们的假设。应用模型剪枝是减少参数和提高运行速度的有前途的解决方案。此外,我们使用的频谱构建往往会遗漏那些短音素,这可以通过使用纯深度特征来解决,例如 wav2vec [Schneider et al. 2019]。我们使用的面部跟踪算法不是最先进的,我们相信更好的重建会导致更好的唇形同步结果。
与大多数基于学习的方法类似,生成的视频的风格仅限于训练语料库。我们的方法通过流形投影保留了训练序列(3-5 分钟)中的谈话风格,流形投影是一种用于查找最相似样本的域转移方法。这种机制在一定程度上缓解了这个问题。我们认为一个完整的解决方案是应用一个完美的音频解缠算法,如 [Qian et al. 2020] 拆分每个组件,即内容、音高、音色和节奏,并找到这些组件的最佳映射。
当模型在中性风格的视频上训练时,情感音频可能会产生不满意的结果。我们的方法不能直接控制生成视频的情绪。最近的工作 [Ji et al. 2021] 在情感数据集上训练时显示出有希望的情感操纵结果。将这样的进展应用于我们的系统会很有趣。
虽然我们成功地处理了人们摇头时的阴影和灯光反射,但我们仍然无法明确控制这些参数。重新照明技术 [Sun et al. 2019] 可以直接应用于我们的渲染结果来控制环境照明。手势是人们表达表情的另一个重要组成部分。我们期待未来在音频驱动的手势生成方面的工作。
7. 道德考虑
略