ClickHouse
ClickHouse
这里目录标题
- ClickHouse
-
- 1、软件介绍
-
- 1.1. 简介
- 1.2. 特点
- 1.3. 优点
- 1.4. 缺点
- 2、系统架构
-
- 2.1. Column与Field
- 2.2. 数据类型DataType
- 2.3. 块Block
- 2.4. 块流BlockStreams
- 2.5. Formats格式
- 2.6. 数据读写I/O
- 2.7. 数据表Table
- 2.8. 解析器Parser
- 2.9. 解释器Interpreter
- 2.10. 函数Functions
-
- 2.10.1. 普通函数Functions
- 2.10.2. 聚合函数Aggregate Functions
- 2.11. Cluster与Replication
- 3、环境搭建
- 4、数据定义
-
- 4.1. 数据类型
-
- 4.1.1. 基本数据类型
- 4.1.2. 字符串
- 4.1.3. 日期时间
- 4.1.4. 复合类型
- 4.1.5. 其他类型
- 4.2. 数据库操作
- 4.3. 数据表
-
- 4.3.1. 创建表
- 4.3.2. 删除表
- 4.3.3. 临时表
- 4.3.4. 分区表
- 4.3.5. 数据表操作
- 4.4. 视图
- 4.5. 数据的CRUD
-
- 4.5.1. 数据的写入
- 4.5.2. 数据的删除和修改
- 5、MergeTree
-
- 5.1. 创建与存储
-
- 5.1.2. 存储格式
- 5.2. 数据分区
-
- 5.2.1. 数据分区规则
- 5.2.2. 分区目录命名
- 5.2.3. 分区目录合并
- 5.3. 一级索引
-
- 5.3.1. 稀疏索引
- 5.3.2. 索引粒度
- 5.3.3. 索引规则
- 5.3.4. 索引查询过程
- 5.4. 二级索引
-
- 5.4.1. 粒度
- 5.4.2. 分类
- 5.5. 数据存储
-
- 5.5.1. 列式存储
- 5.5.2. 数据压缩
- 5.6. 数据标记
-
- 5.6.1. 生成规则
- 5.6.2. 工作方式
- 5.7. 数据标记与数据压缩
-
- 5.7.1. 多对一
- 5.7.2. 一对一
- 5.7.3. 一对多
- 5.8. 数据读写流程
-
- 5.8.1. 写入数据
- 5.8.2. 查询数据
- 5.9. 数据TTL
- 5.10. 多路径存储策略
- 6、 MergeTree Family
-
- 6.1. MergeTree
- 6.2. ReplacingMergeTree
- 6.3. SummingMergeTree
- 6.4. AggregatingMergeTree
- 6.5. CollapsingMergeTree
- 6.6. VersionedCollapsingMergeTree
- 7、常见类型表引擎
-
- 7.1. 外部存储
-
- 7.1.1. HDFS
- 7.1.2. Mysql
- 7.1.3. JDBC
- 7.1.4. Kafka
- 7.1.5. File
- 7.2. 内存类型
-
- 7.2.1. Memory
- 7.2.2. Set
- 7.2.3. Join
- 7.3. 日志类型
-
- 7.3.1. TinyLog
- 7.3.2. StripeLog
- 7.3.3. Log
- 7.4. 接口类型
-
- 7.4.1. Merge
- 8、 数据查询方式
-
- 8.1. With子句
- 8.2. From子句
- 8.3. Sample子句
- 8.4. Array Join子句
- 8.5. Join 子句
- 8.6. WHERE与PREWHERE子句
- 8.7. GROUP BY子句
-
- 8.7.1. WITH ROLLUP
- 8.7.2. WITH CUBE
- 8.7.3. WITH TOTALS
- 8.8. Having子句
- 8.9. ORDER BY子句
- 8.10. LIMIT BY子句
- 8.11. LIMIT子句
- 5、 副本与分片
1、软件介绍
1.1. 简介
ClickHouse 是开源的一个极具 " 战斗力 " 的实时数据分析数据库,开发语言为C++,是一个用于联机分析 (OLAP:Online Analytical Processing) 的列式数据库管理系统(DBMS:Database Management System),简称 CK。
ClickHouse 的性能超过了目前市场上可比的面向列的DBMS。 每秒钟每台服务器每秒处理数 亿至十亿多行和数十千兆字节的数据。
目前国内社区火热,各个大厂纷纷跟进大规模使用:
- 今日头条 内部用ClickHouse来做用户行为分析;
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S
1.2. 特点
- 开源的列存储数据库管理系统,支持线性扩展,简单方便,高可靠性,
- 容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10 亿级别
- https://clickhouse.tech/benchmark/dbms/
- 功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
1.3. 优点
- 真正的面向列的DBMS(ClickHouse是一个DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置和重新启动服务器)
- 数据压缩(一些面向列的DBMS(INFINIDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实是提高了性能)
- 磁盘存储的数据(许多面向列的DBMS(SPA HANA和GooglePowerDrill))只能在内存中工作。但即使在数千台服务器上,内存也太小了。)
- 多核并行处理(多核多节点并行化大型查询)
- 在多个服务器上分布式处理(在clickhouse中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分片上并行处理)
- SQL支持(ClickHouse sql 跟真正的sql有不一样的函数名称。不过语法基本跟SQL语法兼容,支持 JOIN/FROM/IN 和JOIN子句及标量子查询支持子查询)
- 向量化引擎(数据不仅按列式存储,而且由矢量-列的部分进行处理,这使得开发者能够实现高CPU 性能)
- 实时数据更新(ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树 (MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中)
- 支持近似计算(统计全国到底有多少人?143456754 14.3E)
- 数据复制和对数据完整性的支持(ClickHouse使用异步多主复制。写入任何可用的复本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复)
1.4. 缺点
- 没有完整的事务支持,不支持Transaction想快就别Transaction
- 缺少完整Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅用于批量 删除或修改数据。
- 聚合结果必须小于一台机器的内存大小
- 支持有限操作系统,正在慢慢完善
- 不适合Key-value存储,不支持Blob等文档型数据库
2、系统架构
- ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。


2.1. Column与Field
Column和Field是ClickHouse数据最基础的映射单元。- 内存中的一列数据由一个Column对象表示。
- Field对象代表一个单值;操作单个具体的数值 ( 也就是单列中的一行数据 )。
- Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法。
- 几乎所有的操作都是不可变的:这些操作不会更改原始列,但是会创建一个新的修改后的 列。
- Field对象使用了聚合的设计模式。在Field对象内部聚合了 Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
2.2. 数据类型DataType
- DataType 描述了列的数据类型;
- DataType 仅存储元数据。
- 负责序列化和反序列化:读写二进制或文本形式的列或单个值构成的块。
- DataType虽然负责序列化相关工作,但它并不直接负责数据的读取,而是转由从Column或Field对 象获取。
2.3. 块Block
- Block 是表示内存中表的子集(chunk)的容器,由三元组 (cloumn,datatype,列名)构成的集合;
- 表操作的对象是Block;Block对象可以看作数据表的子集。
- Block并没有直接聚合Column和DataType对象,而是通过ColumnWithTypeAndName对象进行间接引用。
2.4. 块流BlockStreams
- 块流用于处理数据,负责块数据的读取和写出。
- Block流操作有两组顶层接口:
- IBlockInputStream负责数据的读取和关系运算,IBlockInputStream 具有read方法,其能够在数据可用时获取下一个块。
- IBlockOutputStream负责将数据输出到下一环节。IBlockOutputStream 具有 write 方法,其能够将块写到某处。
2.5. Formats格式
- 数据格式同块流一起实现。用于向客户端展示数据的方式;
- 如块流 IBlockOutputStream 提供的 Pretty 格式,也有其它输入输出格式,比如 TabSeparated 或 JSONEachRow 。
- 如行流: IRowInputStream 和 IRowOutputStream 。它们允许你按行 pull/push 数据,而不是按 块。
2.6. 数据读写I/O
- 有一个缓冲区负责数据的读写;
- 面向字节的输入输出,有 ReadBuffer 和 WriteBuffer 这两个抽象类。
2.7. 数据表Table
- 多个列的一个集合体。
- 读取数据的时候以表为单位进行操作,操作的时候以BlockStream操作Block;
- 在数据表的底层设计中并没有所谓的Table对象;
- 表由 IStorage 接口表示。该接口的不同实现对应不同的表引擎。
2.8. 解析器Parser
- 查询由一个手写递归下降解析器解析。
- 对Sql语句进行解析为AST语法树。
2.9. 解释器Interpreter
- 解释AST语法树。
- 解释器负责从 AST 创建查询执行流水线。
- 简单的解释器,如 InterpreterExistsQuery 和 InterpreterDropQuery
- 复杂的解释器,如 InterpreterSelectQuery 。
- 查询执行流水线由块输入或输出流组成。
2.10. 函数Functions
- 单行函数(Functions)
- 组函数(Aggregate Functions)
2.10.1. 普通函数Functions
- 普通函数不会改变行数 - 它们的执行看起来就像是独立地处理每一行数据。
- 无状态的普通函数,
- 是作用在以 Block 为单位的数据上,以实现向量查询执行。
2.10.2. 聚合函数Aggregate Functions
- 聚合函数是状态函数。它们将传入的值激活到某个状态,并允许你从该状态获取结果。
- 聚合函数是有状态的
- 聚合状态可以被序列化和反序列化,以在分布式查询执行期间通过网络传递或者在内存不够的时候 将其写到硬盘。
2.11. Cluster与Replication
- ClickHouse的集群由分片 ( Shard ) 组成,而每个分片又通过副本 ( Replica ) 组成。
- 这种分层的概念,在一些流行的分布式系统中十分普遍。
- ClickHouse的1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部 署2个服务节点。
- 分片只是一个逻辑概念,其物理承载还是由副本承担的。
3、环境搭建
- ClickHouse 21.6.8.62 环境搭建
- https://blog.csdn.net/weixin_43660536/article/details/120090681.
4、数据定义
4.1. 数据类型
4.1.1. 基本数据类型
- 整数Int8->1字节、Int16->2字节、Int32->4字节 和 Int64->8字节
- 浮点数 Float32 和 Float64
- 定点数 Decimal32、Decimal64 和Decimal128
- 布尔 UInt8 限制值为0或1
4.1.2. 字符串
- String、FixedString 和 UUID
- String 不限制长度,相当于Varchar、Text、Clob 和 Blob 等字符类型
- FixedString(N)相当于Char,长度固定,数据长度不够时,添加空字节(null);长度过长返回错误消息
- UUID:32位,格式8-4-4-4-12,如果未被赋值,则用0填充
4.1.3. 日期时间
- Date、DateTime、DateTime64
- Date: 2020-02-02 精确到天
- DateTime: 2020-02-02 20:20:20 精确到秒
- DateTime64: 2020-02-02 20:20:20.335 精确到亚秒,可以设置精度
4.1.4. 复合类型
- 数组
- 创建数据:array(T)或[],类型必须相同
- 元组
- 由多个元素组成,允许不同类型
- 创建数据:(T1, T2, …),Tuple(T1, T2, …)
- 枚举类型
- ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二 致。
- 枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对 应(String:Int8)和(String:Int16)
- 用(String:Int) Key/Value键值对的形式定义数据,键值对不能同时为空,不允许重复,key允许 为空字符串,需要看到对应的值进行转换
- 嵌套类型
- Nested(Name1 Type1,Name2 Type2,…)
- 相当于表中嵌套一张表,插入时相当于一个多维数组的格式,一个字段对应一个数组。
4.1.5. 其他类型
- Nullable(TypeName)
- 只能与基础数据类型搭配使用,表示某个类型的值可以为NULL;Nullable(Int8)表示可以存储 Int8类型的值,没有值时存NULL
- 注意:
- 不能与复合类型数据一起使用
- 不能作为索引字段
- 尽量避免使用,字段被Nullable修饰后会额外生成[Column].null.bin 文件保存Null值, 增加开销
- Domain
- Pv4 使用 UInt32 存储。如 116.253.40.133
- IPv6 使用 FixedString(16) 存储。如 2a02:aa08:e000:3100::2
4.2. 数据库操作
- 数据库起到了命名空间的作用,可以有效规避命名冲突的问题,也为后续的数据隔离提供了支撑。 任何一张数据表,都必须归属在某个数据库之下。
CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]
SHOW DATABASES
DROP DATABASE [IF EXISTS] db_name
- 数据库引擎
- Ordinary:默认引擎
- 在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使 用任意类型的表引擎。
- Dictionary:字典引擎
- 此类数据库会自动为所有数据字典创建它们的数据表,关于数据字典的详细介绍会在第5 章展开。
- Memory:内存引擎
- 用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操 作,当服务重启后数据会被清除。
- Lazy:日志引擎
- 此类数据库下只能使用Log系列的表引擎,关于Log表引擎的详细介绍会在第8章展开。
- MySQL:MySQL引擎
- 此类数据库下会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表,
- Ordinary:默认引擎
4.3. 数据表
4.3.1. 创建表
- ClickHouse目前提供了三种最基本的建表方法
- 第一种是常规定义方法
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略…
) ENGINE = engine
CREATE TABLE hits_v1 (
Title String,
URL String ,
EventTime DateTime
) ENGINE = Memory;
- 使用[db_name.]参数可以为数据表指定数据库,如果不指定此参数,则默认会使用default数 据库。
第二种定义方法是复制其他表的结构
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.]
table_name2 [ENGINE = engine]
--创建新的数据库
CREATE DATABASE IF NOT EXISTS new_db
--将default.hits_v1的结构复制到new_db.hits_v1
CREATE TABLE IF NOT EXISTS new_db.hits_v1 AS default.hits_v1 ENGINE =
TinyLog
- 支持在不同的数据库之间复制表结构
第三种定义方法是通过SELECT子句的形式创建
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS
SELECT …
CREATE TABLE IF NOT EXISTS hits_v1_1 ENGINE = Memory AS SELECT * FROM
hits_v1
- 根据SELECT子句建立相应的表结构,同时还会将SELECT子句查询的数据顺带写入
4.3.2. 删除表
- ClickHouse和大多数数据库一样,使用DESC查询可以返回数据表的定义结构。
- 如果想删除一张数据表,则可以使用下面的DROP语句:
DROP TABLE [IF EXISTS] [db_name.]table_name
4.3.3. 临时表
- ClickHouse也有临时表的概念,创建临时表的方法是在普通表的基础之上添加
TEMPORARY关键字。
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name ( name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr], name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],)
- 特点
- 生命周期是会话绑定的,所以它只支持Memory表引擎,如果会话结束,数据表就会被销毁;
- 临时表不属于任何数据库,所以在它的建表语句中,既没有数据库参数也没有表引擎参数。
- 临时表的优先级是大于普通表的。当两张数据表名称相同的时候,会优先读取临时表的数据
4.3.4. 分区表
- 数据分区(partition)和数据分片(shard)是完全不同的两个概念。
- 数据分区是数据的一种纵向切分。而数据分片是数据的一种横向切分;
4.3.5. 数据表操作
-
追加新字段
-
ALTER TABLE tb_name ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [AFTER name_after] ALTER TABLE testcol_v1 ADD COLUMN OS String DEFAULT 'mac'ALTER TABLE testcol_v1 ADD COLUMN IP String AFTER ID
-
-
修改字段类型
-
ALTER TABLE tb_name MODIFY COLUMN [IF EXISTS] name [type] [default_expr] ALTER TABLE testcol_v1 MODIFY COLUMN IP IPv4
-
-
修改备注
-
ALTER TABLE tb_name COMMENT COLUMN [IF EXISTS] name 'some comment' ALTER TABLE testcol_v1 COMMENT COLUMN ID '主键ID' DESC testcol_v1
-
-
删除已有字段
-
ALTER TABLE tb_name DROP COLUMN [IF EXISTS] name ALTER TABLE testcol_v1 DROP COLUMN URL
-
-
清空数据表
-
TRUNCATE TABLE [IF EXISTS] [db_name.]tb_name TRUNCATE TABLE db_test.testcol_v2
-
4.4. 视图
-
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理。
-
普通视图
-
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT ... -
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义 的作用,对查询性能不会有任何增强。
-
-
物化视图
-
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT . -
物化视图支持表引擎,数据保存形式由它的表引擎决定 ;
-
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。
- POPULATE修饰符决定了物化视图的初始化策略:
- 如果使用了POPULATE修饰符,那么在创建视图的过程中,会连带将源表中已存在的数据一并导入,如同执行了SELECT INTO一般;
- 反之,如果不使用POPULATE修饰符,那么物化视图在创建之后是没有数据的,它只会 同步在此之后被写入源表的数据。
- 物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保 留。
-
4.5. 数据的CRUD
4.5.1. 数据的写入
-
INSERT语句支持三种语法范式,三种范式各有不同,可以根据写入的需求灵活运用。
-
第一种是使用VALUES格式的常规语法:
-
INSERT INTO [db.]table [(c1, c2, c3…)] VALUES (v11, v12, v13…), (v21,v22, v23…), ... INSERT INTO partition_v2 VALUES ('A0011','www.nauu.com', '2019-10-01'), ('A0012','www.nauu.com', '2019-11-20') INSERT INTO partition_v2 VALUES ('A0014',toString(1+2), now())
-
-
第二种是使用指定格式的语法:
-
INSERT INTO [db.]table [(c1, c2, c3…)] FORMAT format_name data_set INSERT INTO partition_v2 FORMAT CSV \'A0017','www.nauu.com', '2019-10-01' \'A0018','www.nauu.com', '2019-10-01'
-
-
第三种是使用SELECT子句形式的语法
-
INSERT INTO [db.]table [(c1, c2, c3…)] SELECT ... INSERT INTO partition_v2 SELECT * FROM partition_v1 INSERT INTO partition_v2 SELECT 'A0020', 'www.jack.com', now()
-
4.5.2. 数据的删除和修改
-
ClickHouse提供了DELETE和UPDATE的能力,这类操作被称为Mutation查询,它可以看作ALTER 语句的变种。
-
虽然Mutation能最终实现修改和删除,但不能完全以通常意义上的UPDATE和DELETE来理解,我 们必须清醒地认识到它的不同:
- 首先,Mutation语句是一种“很重”的操作,更适用于批量数据的修改和删除;
- 其次,它不支持事务,一旦语句被提交执行,就会立刻对现有数据产生影响,无法回滚;
- 最后,Mutation语句的执行是一个异步的后台过程,语句被提交之后就会立即返回。
-
DELETE语句的完整语法
-
ALTER TABLE [db_name.]table_name DELETE WHERE filter_expr ALTER TABLE partition_v2 DELETE WHERE ID = 'A003'
-
-
UPDATE语句的完整语法
-
ALTER TABLE [db_name.]table_name UPDATE column1 = expr1 [, ...] WHERE filter_expr ALTER TABLE partition_v2 UPDATE URL = 'www.wayne.com',OS = 'mac' WHERE ID IN(10,20,30)
-
5、MergeTree
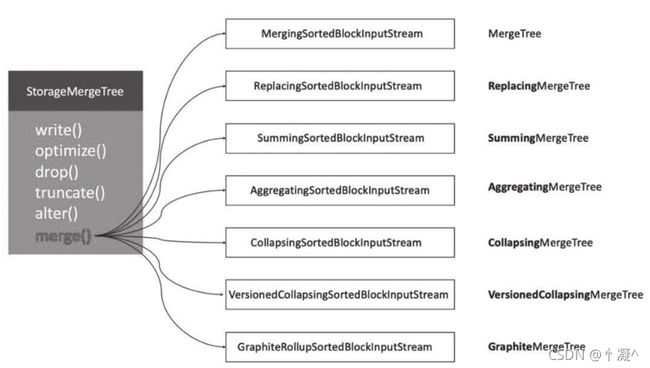
- 表引擎是ClickHouse设计实现中的一大特色
- ClickHouse拥有非常庞大的表引擎体系,其共拥有
合并树、外部存储、内存、文件、接口和其他6大类20多种表引擎。 - 合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家族中最基础的表引擎;
- 提供了
主键索引、数据分区、数据副本和数据采样等基本能力;
5.1. 创建与存储
- MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。
- 为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。
- 这种数据片段往复合并的特点,也正是合并树名称的由来。
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略...
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, 省略...]
-- 实例
CREATE TABLE IF NOT EXISTS yjxxt.mt (
mid String, mname String,
createtime DateTime)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(createtime)
ORDER BY (mid,mname)
PRIMARY KEY mid;
insert into yjxxt.mt values ('1','zs','2021-05-02'),('2','ls','2021-06-02'),('3','ww','2021-06-04');
-- 可以通过system.tables 查看表的元数据信息
- 配置选项
- PARTITION BY [选填]:分区键,用于指定表数据以何种标准进行分区。
- ORDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。
- 默认情况下主键(PRIMARY KEY)与排序键相同。
- PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主键字段生成一级索引,用于加速表 查询。
- SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标准进行采样。
- SETTINGS:
- index_granularity [选填]:索引粒度 默认8192
- index_granularity_bytes [选填]:自适应间隔大小(粒度),默认10M;
- enable_mixed_granularity_parts [选填] 是否开启自适应间隔,默认开启;
- merge_with_ttl_timeout [选填] TTL的功能;
- storage_policy [选填]:提供了多路径的存储策略;
5.1.2. 存储格式
-
MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上。
-

-
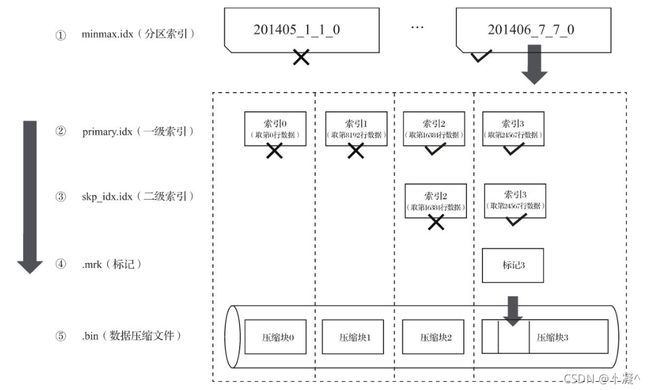
一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件;
-
partition:分区目录,余下各类数据文件(primary.idx、[Column].mrk、[Column].bin等)
- 以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录。
- checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary.idx、 count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
- columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息
- count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数,
- primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表 只能声明一次一级索引(通过ORDERBY或者PRIMARY KEY)。
- [Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。
- [Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据 的偏移量信息。
- [Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。它的工作 原理和作用与.mrk标记文件相同。
- partition.dat与minmax_[Column].idx:如果使用了分区键,例如PARTITION BY EventTime,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。
- skp_idx[Column].idx与skp_idx[Column].mrk:如果在建表语句中声明了二级索引,则会额外 生成相应的二级索引与标记文件,它们同样也使用二进制存储。二级索引在ClickHouse中又 称跳数索引,
5.2. 数据分区
5.2.1. 数据分区规则
- MergeTree数据分区的规则由分区ID决定,而具体到每个数据分区所对应的ID,则是由分区键的取值决定的。
- 针对取值数据类型的不同,分区ID的生成逻辑目前拥有四种规则:

5.2.2. 分区目录命名
-
一个完整分区目录的命名公式
-

- 201905表示分区目录的ID;
- 1_1分别表示最小的数据块编号与最大的数据块编号;
- 而最后的_0则表示目前合并的层级。
-
PartitionID_MinBlockNum_MaxBlockNum_Level
5.2.3. 分区目录合并
- MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。
- 也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。
- MergeTree伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。
- 即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。
- 写入后的10~15分钟,也可以手动执行optimize查询语句)
- ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。
- 已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认 8分钟)。
- 新目录名称的合并方式遵循规则:
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。
- Level:取同一分区内最大Level值并加1。
5.3. 一级索引
- MergeTree的主键使用PRIMARY KEY定义,
- 待主键定义之后,MergeTree会依据 index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARYKEY排序。
5.3.1. 稀疏索引
- primary.idx文件内的一级索引采用稀疏索引实现。
- 稠密索引中每一行索引标记都会对应到一行具体的数据记录。
- 稀疏索引中每一行索引标记对应的是一段数据,而不是一行。
- 由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快。
5.3.2. 索引粒度
- 索引粒度就如同标尺一般,会丈量整个数据的长度,并依照刻度对数据进行标注,最终将数据标记成多个间隔的小段。
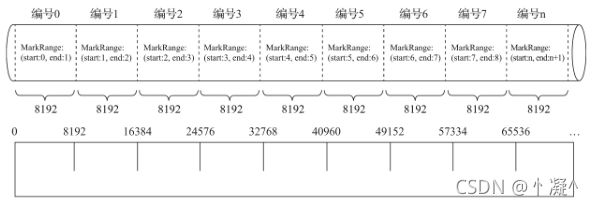
5.3.3. 索引规则
- 由于是稀疏索引,所以MergeTree需要间隔index_granularity行数据才会生成一条索引记录,其索 引值会依据声明的主键字段获取。
- 单主键
-

-
第0(81920)行CounterID取值57,第8192(81921)行CounterID取值1635,而第 16384(8192*2)行CounterID取值3266
-
最终索引数据将会是5716353266。
-
- 多主键
- 联合主键或多个字段列充当主键,多个ID放在一起。
5.3.4. 索引查询过程
-
MarkRange
- MarkRange在ClickHouse中是用于定义标记区间的对象。
- 按照index_granularity的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段即是一个MarkRange。
- MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。
- 通过与start及end对应的索引编号的取值,即能够得到它所对应的数值区间。而数值区间表示 了此MarkRange包含的数据范围。
-
索引查询其实就是两个数值区间的交集判断。
- 一个区间是由基于主键的查询条件转换而来的条件区间;
- 一个区间是刚才所讲述的与MarkRange对应的数值区间。
-
查询步骤
-

-
生成查询条件区间:首先,将查询条件转换为条件区间。
WHERE ID = 'A003' ['A003', 'A003'] -
递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最 大的区间[A000,+inf)开始:
- 如果不存在交集,则直接通过剪枝算法优化此整段MarkRange。
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区 间,并重复此规则,继续做递归交集判断。
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
-
合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
-
5.4. 二级索引
- 二级索引又称跳数索引,由数据的聚合信息构建而成。
- 根据索引类型的不同,其聚合信息的内容也不同。跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
- 跳数索引在默认情况下是关闭的,需要设置allow_experimental_data_skipping_indices
- SET allow_experimental_data_skipping_indices = 1
- 跳数索引需要在CREATE语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法
- INDEX index_name expr TYPE index_type(…) GRANULARITY granularity
5.4.1. 粒度
- 定义了一行跳数索引能够跳过多少个index_granularity区间的数据(默认8192行)。
- 按照index_granularity粒度间隔将数据划分成n段,总共有[0,n-1]个区(n=total_rows/index_granularity,向上取整)
- 当移动index_granularity次区间时,则汇总并生成一行跳数索引数据。

5.4.2. 分类
-
MergeTree共支持4种跳数索引,分别是minmax、set、ngrambf_v1和tokenbf_v1。一张数据表支持同时声明多个跳数索引。
-
CREATE TABLE skip_test ( ID String, URL String, Code String, EventTime Date, INDEX a ID TYPE minmax GRANULARITY 5, INDEX b(length(ID) * 8) TYPE set(2) GRANULARITY 5, INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5, INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5 ) ENGINE = MergeTree() -
minmax
- minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索 引,能够快速跳过无用的数据区间.
-
set
- set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为 set(max_rows),其中max_rows是一个阈 值,表示在一个index_granularity内,索引最多记录的数据行数。
-
ngrambf_v1:
- ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。
- ngrambf_v1只能够提升in、notIn、like、equals和notEquals查询的性能.
-
tokenbf_v1:
- tokenbf_v1索引是ngrambf_v1的变种,同样也是一种布隆过滤器索引。
- tokenbf_v1除了短语token的处理方法外,其他与ngrambf_v1是完全一样的。
- tokenbf_v1会自动按照非字符的、数字的字符串分割token。
5.5. 数据存储
5.5.1. 列式存储
- 在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有 一个与之对应的.bin数据文件。也正是这些.bin文件,最终承载着数据的物理存储。
- 数据文件以分区目录的形式被组织存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据
- 优势:
- 一是可以更好地进行数据压缩
- 二是能够最小化数据扫描的范围
- 存储方式
- 首先,数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用LZ4算 法;
- 其次,数据会事先依照ORDER BY的声明排序;
- 最后,数据是以压缩数据块的形式被组织并写入.bin文件中的。
5.5.2. 数据压缩
- 一个压缩数据块由头信息和压缩数据两部分组成。
- 头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成 。
- 分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小 。
- bin压缩文件是由多个压缩数据块组成的,而每个压缩数据块的头信息则是基于CompressionMethod_CompressedSize_UncompressedSize公式生成的。
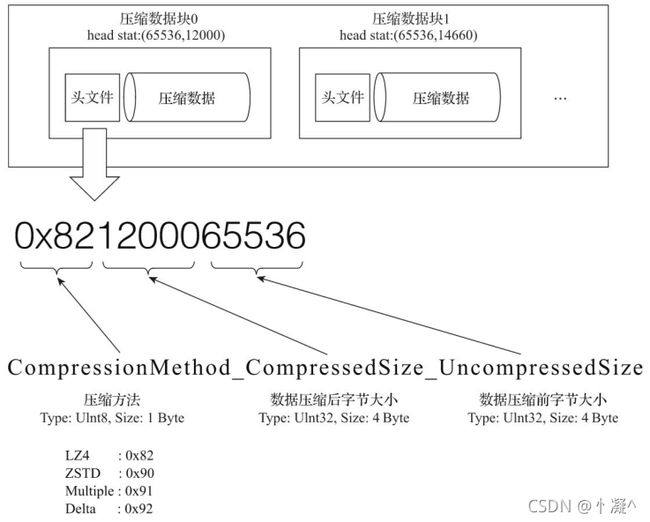
-
每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB~1MB。
- 其上下限分别由min_compress_block_size(默认65536)与max_compress_block_size(默 认1048576)参数指定。
- 一个压缩数据块最终的大小,则和一个间隔(index_granularity)内数据的实际大小相关。
-
数据写入过程
- MergeTree在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取8192行),按批次获取数据并进行处理
- 单个批次数据size<64KB :如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块。
- 单个批次数据64KB<=size<=1MB :如果单个批次数据大小恰好在64KB与1MB之间,则直接生成下一个压缩数据块。
- 单个批次数据size>1MB :如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成 下一个压缩数据块。剩余数据继续依照上述规则执行。

- 优势:
- 其一,虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率,但数据的压缩和解压动作,其本身也会带来额外的性能损耗。所以需要控制被压缩数据的大小,以求 在性能损耗和压缩率之间寻求一种平衡。
- 其二,在具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围。
5.6. 数据标记
5.6.1. 生成规则
- 数据标记作为衔接一级索引和数据的桥梁,其像极了做过标记小抄的书签,而且书本中每个一级章节都拥有各自的书签。
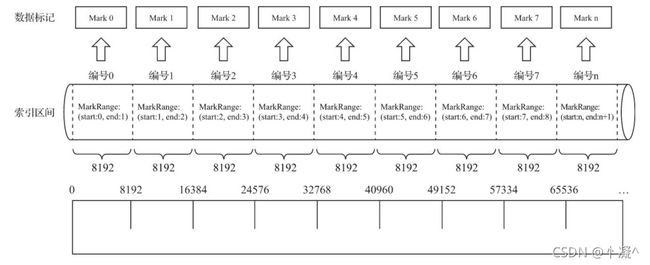
-
数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔。
-
为了能够与数据衔接,数据标记文件也与.bin文件一一对应。
- 每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录 数据在.bin文件中的偏移量信息。
-
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。
- 它们分别表示在此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;
- 以及将该数据压缩块解压后,其未压缩数据的起始偏移量。
-
每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息。标记 数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取用速度。
-
标记查看命令
-
od -An -l name.mrk
-
5.6.2. 工作方式
- MergeTree在读取数据时,必须通过标记数据的位置信息才能够找到所需要的数据。整个查找过程大致可以分为读取压缩数据块和读取数据两个步骤

- 数据理解
- 1B*8192=8192B,64KB=65536B,65536/8192=8
- 头信息固定由9个字节组成,压缩后大小为8个字节
- 12016=8+12000+8
- 读取压缩数据块:
- 在查询某一列数据时,MergeTree无须一次性加载整个.bin文件,而是可以根据需要,只加载特定的压缩数据块。而这项特性需要借助标记文件中所保存的压缩文件中的偏移量。
- 读取数据:
- 在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要, 以index_granularity的粒度加载特定的一小段。为了实现这项特性,需要借助标记文件中保存的解压数据块中的偏移量。
5.7. 数据标记与数据压缩
- 由于压缩数据块的划分,与一个间隔(index_granularity)内的数据大小相关,每个未压缩数据块的体积都被严格控制在64KB~1MB。
- 而一个间隔(index_granularity)的数据,又只会产生一行数据标记。
- 那么根据一个间隔内数据的实际字节大小,数据标记和压缩数据块之间会产生三种不同的对应关系。
5.7.1. 多对一
- 多个数据标记对应一个压缩数据块 当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时
5.7.2. 一对一
- 一个数据标记对应一个压缩数据块 当一个间隔(index_granularity)内的数据未压缩大小size大于等于64KB且小于等于1MB时
5.7.3. 一对多
- 一个数据标记对应多个压缩数据块 当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时
5.8. 数据读写流程
5.8.1. 写入数据
- 数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后 续的某一时刻,属于相同分区的目录会依照规则合并到一起;接着,按照index_granularity索引粒 度,会分别生成primary.idx一级索引、每一个列字段的.mrk数据标记和.bin压缩数据文件。
-
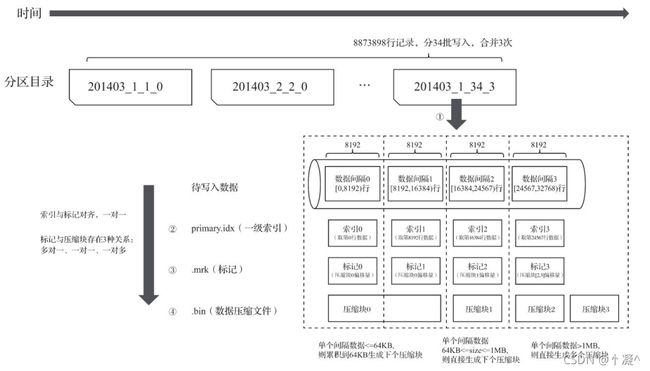
-
从分区目录201403_1_34_3能够得知,该分区数据共分34批写入,期间发生过3次合并。在数 据写入的过程中,依据index_granularity的粒度,依次为每个区间的数据生成索引、标记和 压缩数据块。其中,索引和标记区间是对齐的,而标记与压缩块则根据区间数据大小的不同, 会生成多对一、一对一和一对多三种关系。
-
5.8.2. 查询数据
- 数据查询的本质,可以看作一个不断减小数据范围的过程。在最理想的情况下,MergeTree首先可 以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将 需要解压与计算的数据范围缩至最小。
5.9. 数据TTL
-
TTL即Time To Live,顾名思义,它表示数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。
- 当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;
- 如果是表级别的TTL,则会删除整张表的数据;
- 如果同时设置了列级别和表级别的TTL,则会以先到期的那个为主。
-
设置TTL
-
INTERVAL完整的操作包括SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER 和YEAR。
-
ClickHouse没有提供取消TTL的方法。
-
列级别设置TTL
-- create_time是日期类型,列字段code与type均被设置了TTL,它们的存活时间是在 -- create_time的取值基础之上向后延续10秒 CREATE TABLE ttl_table_v1( id String, create_time DateTime, code String TTL create_time + INTERVAL 10 SECOND, type UInt8 TTL create_time + INTERVAL 10 SECOND ) ENGINE = MergeTree PARTITION BY toYYYYMM(create_time) ORDER BY id; INSERT INTO TABLE ttl_table_v1 VALUES('A000',now(),'C0',1), ('A001',now() + INTERVAL 10 MINUTE,'C1',1); SELECT * FROM ttl_table_v1 -- 执行optimize命令强制触发TTL清理 -- 第一行数据满足TTL过期条件(当前系统时间>=create_time+10秒),它们的code和 -- type列会被还原为数据类型的默认值: optimize TABLE ttl_table_v1 FINAL -- 修改列字段的TTL,或是为已有字段添加TTL,则可以使用ALTER语句 ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY -
表级别设置TTL
--整张表被设置了TTL,当触发TTL清理时,那些满足过期时间的数据行将会被整行删除CREATE TABLE ttl_table_v2( id String, create_time DateTime, code String TTL create_time + INTERVAL 1 MINUTE, type UInt8)ENGINE = MergeTreePARTITION BY toYYYYMM(create_time)ORDER BY create_timeTTL create_time + INTERVAL 1 DAY-- 修改表级别的TTLALTER TABLE ttl_table_v2 MODIFY TTL create_time + INTERVAL 3 DAY -
TTL的运行机制
- 如果一张MergeTree表被设置了TTL表达式,那么在写入数据时,会以数据分区为单位,在每 个分区目录内生成一个名为ttl.txt的文件。
- ttl.txt文件中通过一串JSON配置保存了TTL的相关信息
- {“columns”:[{“name”:“code”,“min”:1557478860,“max”:1557651660}],“table”: {“min”:1557565200,“max”:1557738000}}
- columns用于保存列级别TTL信息;
- table用于保存表级别TTL信息;
- min和max则保存了当前数据分区内,TTL指定日期字段的最小值、最大值分别与 INTERVAL表达式计算后的时间戳。
-
5.10. 多路径存储策略
- 19.15版本之前,MergeTree只支持单路径存储,所有的数据都会被写入config.xml配置中path指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。
- 19.15版本开始,MergeTree实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
- 存储策略
- 默认策略
- MergeTree原本的存储策略,无须任何配置,所有分区会自动保存到config.xml配置中 path指定的路径下.
- JBOD策略
- 这种策略适合服务器挂载了多块磁盘,但没有做RAID的场景。
- JBOD的全称是Just a Bunch of Disks,它是一种轮询策略,每执行一次INSERT或者 MERGE,所产生的新分区会轮询写入各个磁盘。
- HOT/COLD策略
- 这种策略适合服务器挂载了不同类型磁盘的场景。
- 将存储磁盘分为HOT与COLD两类区域。
- HOT区域使用SSD这类高性能存储媒介,注重存取性能;
- COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。
- 数据在写入MergeTree之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自行移动到COLD区域。
- 默认策略
- 配置方式
- 存储配置需要预先定义在config.xml配置文件中,由storage_configuration标签表示。
- 在storage_configuration之下又分为disks和policies两组标签,分别表示磁盘与存储策略。
<storage_configuration>
<disks>
<disk_name_a>
<path>/chbase/datapath><!—磁盘路径 -->
<keep_free_space_bytes>1073741824keep_free_space_bytes>
disk_name_a>
<disk_name_b>
<path>… path>
<keep_free_space_bytes>...keep_free_space_bytes>
disk_name_b>
disks>
<policies>
<default_jbod>
<volumes>
<jbod> <!—自定义名称 磁盘组 -->
<disk>disk_name_adisk>
<disk>disk_name_bdisk>
jbod>
volumes>
default_jbod>
policies>
storage_configuration>
6、 MergeTree Family
6.1. MergeTree
- MergeTree表引擎向下派生出6个变种表引擎。

6.2. ReplacingMergeTree
- MergeTree拥有主键,但是它的主键却没有唯一键的约束。这意味着即便多行数据的主键相同,它 们还是能够被正常写入。
- 能够在合并分区时删除重复的数据。
- ReplacingMergeTree是以分区为单位删除重复数据的。
- ENGINE = ReplacingMergeTree(ver)
- ver是选填参数,会指定一个UInt*、Date或者DateTime类型的字段作为版本号。
6.3. SummingMergeTree
- 只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的 。
- SummingMergeTree就是为了应对这类聚合查询场景而生的。
- 只能进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
- 照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行。
- 这样既减少了数据行,又降低了后续汇总查询的开销。
- ENGINE = SummingMergeTree() PRIMARY KEY id
6.4. AggregatingMergeTree
-
将需要聚合的数据,预先计算出来,并将结果保存起来。
-
在后续进行聚合查询的时候,直接使用结果数据。
-
-- GROUP BY id,city -- UNIQ(code), SUM(value) CREATE TABLE agg_table( id String, city String, code AggregateFunction(uniq,String), value AggregateFunction(sum,UInt32), create_time DateTime )ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY (id,city) PRIMARY KEY id -
AggregatingMergeTree更为常见的应用方式是结合物化视图使用,将它作为物化视图的表引擎。
6.5. CollapsingMergeTree
-
是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。
-
如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。
-
分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
-
这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般。
-
ENGINE = CollapsingMergeTree(sign)
-
只有相同分区内的数据才有可能被折叠。
-
折叠规则
- 如果1比-1的数据多一行,则保留最后一行sign=1的数据。
- 如果**-1比sign=1的数据多一行,则保留第一行sign=-1的数据**。
- 如果1和-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
- 如果1和-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。
- 其余情况,ClickHouse会打印警告日志,但不会报错,在这种情形下,查询结果不可预知。
-
特点
-
折叠数据并不是实时触发的,和所有其他的MergeTree变种表引擎一样,这项特性也只有在分区合并的时候才会体现。
-
所以在分区合并之前,用户还是会看到旧的数据。解决这个问题的方式有两种。
-
用optimize TABLE table_name FINAL命令强制分区合并。
-
GROUP BY idHAVING SUM(sign) > 0
-
-
-
CollapsingMergeTree对于写入数据的顺序有着严格要求。
- 先写入sign=1,再写入sign=-1,则能够正常折叠
- 先写入sign=-1,再写入sign=1,则不能够折叠
6.6. VersionedCollapsingMergeTree
- 作用与CollapsingMergeTree完全相同.
- VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分 区内,任意顺序的数据都能够完成折叠操作。
- ENGINE = VersionedCollapsingMergeTree(sign,ver)
7、常见类型表引擎
7.1. 外部存储
- 外部存储表引擎直接从其他的存储系统读取数据 .
- 例如直接读取HDFS的文件或者MySQL数据库的表。
- 这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。
7.1.1. HDFS
-- 在HDFS上创建用于存放文件的目录
hadoop fs -mkdir /clickhouse
-- 在HDFS上给ClickHouse用户授权
hadoop fs -chown -R clickhouse:clickhouse /clickhouse
-- hdfs_uri表示HDFS的文件存储路径,format表示文件格式
ENGINE = HDFS(hdfs_uri,format)CREATE TABLE hdfs_table1(
id UInt32,
code String,
name String
)ENGINE = HDFS('hdfs://node01:8020/clickhouse/hdfs_table1','CSV');
INSERT INTO hdfs_table1 SELECT number,concat('code',toString(number)),concat('n',toString(number)) FROM numbers(5)
-- 其他方式,只能读取
ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_{1..3}.csv','CSV')
ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_?.csv','CSV')
7.1.2. Mysql
-
MySQL表引擎可以与MySQL数据库中的数据表建立映射,并通过SQL向其发起远程查询,包括 SELECT和INSERT
-
ENGINE = MySQL( 'host:port', 'database', 'table', 'user', 'password'[replace_query, 'on_duplicate_clause'] )- host:port表示MySQL的地址和端口。
- database表示数据库的名称。
- table表示需要映射的表名称。
- user表示MySQL的用户名。
- password表示MySQL的密码。
- replace_query默认为0,对应MySQL的REPLACE INTO语法。如果将它设置为1,则会用 REPLACEINTO代替INSERT INTO。
- on_duplicate_clause默认为0,对应MySQL的ON DUPLICATE KEY语法。如果需要使用该设 置,则必须将replace_query设置成0。
CREATE TABLE mysql_dept(
deptno UInt32,
dname String,
loc String
)ENGINE = MySQL('192.168.88.101:3306', 'scott', 'dept', 'root','123456');
SELECT * FROM mysql_dept INSERT INTO TABLE mysql_dept VALUES (50,'干饭部','207')
-- 目前MySQL表引擎不支持任何UPDATE和DELETE操作
7.1.3. JDBC
- JDBC表引擎不仅可以对接MySQL数据库,还能够与PostgreSQL、SQLite和H2数据库对接。
- JDBC表引擎无法单独完成所有的工作,它需要依赖名为clickhouse-jdbc-bridge的查询代理服务。
- clickhouse-jdbc-bridge是一款基于Java语言实现的SQL代理服务,它的项目地址为https://github. com/ClickHouse/clickhouse-jdbc-bridge 。
- clickhouse-jdbc-bridge可以为ClickHouse代理访问其他的数据库,并自动转换数据类型。
7.1.4. Kafka
- 目前ClickHouse还不支持恰好一次(Exactly once)的语义,因为这需要应用端与Kafka深度配合才能实现。
ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port,... ',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol']
[kafka_schema = '']
[kafka_num_consumers = N]
[kafka_skip_broken_messages = N]
[kafka_commit_every_batch = N]
-
必填参数:
- kafka_broker_list:表示Broker服务的地址列表,多个地址之间使用逗号分隔。
- kafka_topic_list:表示订阅消息主题的名称列表,多个主题之间使用逗号分隔。
- kafka_group_name:表示消费组的名称,表引擎会依据此名称创建Kafka的消费组。
- kafka_format:表示用于解析消息的数据格式,在消息的发送端,必须按照此格式发送 消息。数据格式必须是ClickHouse提供的格式之一
- 例如TSV、JSONEachRow和CSV等。
-
再次执行SELECT查询会发现kafka_test数据表空空如也,这是因为Kafka表引擎在执行查询之后就会删除表内的数据。
7.1.5. File
- File表引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用。
- File表引擎的定义参数中,并没有包含文件路径这一项。所以,File表引擎的数据文件只能保存在 config.xml配置中由path指定的路径下。
- 每张File数据表均由目录和文件组成,其中目录以表的名称命名,而数据文件则固定以data.format 命名。
-- 自动创建
CREATE TABLE file_table ( name String, value UInt32) ENGINE = File("CSV")INSERT INTO file_table VALUES ('one', 1), ('two', 2), ('three', 3)
-- 手动创建
//创建表目录
mkdir /chbase/data/default/file_table1
//创建数据文件#
mv /chbase/data/default/file_table/data.CSV/chbase/data/default/file_table1
ATTACH TABLE file_table1(
name String,
value UInt32
)ENGINE =
File(CSV)INSERT INTO file_table1 VALUES ('four', 4), ('five', 5)
7.2. 内存类型
- 将数据全量放在内存中,对于表引擎来说是一把双刃剑:
- 一方面,这意味着拥有较好的查询性能;
- 另一方面,如果表内装载的数据量过大,可能会带来极大的内存消耗和负担。
7.2.1. Memory
-
Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换,数据在内存中保存的形态与查询时看到的如出一辙。
-
当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。
-
当数据被写入之后,磁盘上不会创建任何数据文件。 操作方式。
-
CREATE TABLE memory_1 (id UInt64)ENGINE = Memory()
7.2.2. Set
- Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中。
- 所以当服务重启时,它的数据不会丢失,当数据表被重新装载时,文件数据会再次被全量加载至内存。
- Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略。
- Set表引擎的存储结构由两部分组成,它们分别是:
- [num].bin数据文件:保存了所有列字段的数据。其中,num是一个自增id,从1开始。伴随 着每一批数据的写入(每一次INSERT),都会生成一个新的.bin文件,num也会随之加1。
- tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕之后,数据文件会被移出此目录。
CREATE TABLE set_1 (
id UInt8
)ENGINE = Set()
INSERT INTO TABLE set_1 SELECT number FROM numbers(10)
SELECT arrayJoin([1, 2, 3]) AS a WHERE a IN set_1
7.2.3. Join
- Join表引擎可以说是为JOIN查询而生的,它等同于将JOIN查询进行了一层简单封装。在Join表引擎的底层实现中,它与Set表引擎共用了大部分的处理逻辑,所以Join和Set表引擎拥有许多相似之处。
ENGINE = Join(join_strictness, join_type, key1[, key2, ...])
- join_strictness:连接精度,它决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、 ANY和ASOF三种类型。
- join_type:连接类型,它决定了JOIN查询组合左右两个数据集合的策略,它们所形成的结果 是交集、并集、笛卡儿积或其他形式,目前支持INNER、OUTER和CROSS三种类型。当 join_type被设置为ANY时,在数据写入时,join_key重复的数据会被自动忽略。
- join_key:连接键,它决定了使用哪个列字段进行关联。
7.3. 日志类型
7.3.1. TinyLog
- TinyLog是日志家族系列中性能最低的表引擎,它的存储结构由数据文件和元数据两部分组成。
- 数据文件是按列独立存储的,也就是说每一个列字段都拥有一个与之对应的.bin文件。
- TinyLog既不支持分区,也没有.mrk标记文件 。
- 由于没有标记文件,它自然无法支持.bin文件的并行读取操作,所以它只适合在非常简单的场景下使用。
CREATE TABLE tinylog_1 (
id UInt64,
code UInt64
)ENGINE = TinyLog()
INSERT INTO TABLE tinylog_1 SELECT number,number+1 FROM numbers(100)
7.3.2. StripeLog
- StripeLog表引擎的存储结构由固定的3个文件组成,它们分别是:
- data.bin:数据文件,所有的列字段使用同一个文件保存,它们的数据都会被写入data.bin。
- index.mrk:数据标记,保存了数据在data.bin文件中的位置信息。利用数据标记能够使用多 个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
- sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息。
CREATE TABLE spripelog_1 (
id UInt64,
price Float32
)ENGINE = StripeLog()
INSERT INTO TABLE spripelog_1 SELECT number,number+100 FROMnumbers(1000)
7.3.3. Log
- Log表引擎结合了TinyLog表引擎和StripeLog表引擎的长处,是日志家族系列中性能最高的表引擎。
- Log表引擎的存储结构由3个部分组成:
- [column].bin:数据文件,数据文件按列独立存储,每一个列字段都拥有一个与之对应的.bin 文件。
- marks.mrk:数据标记,统一保存了数据在各个[column].bin文件中的位置信息。利用数据标 记能够使用多个线程,以并行的方式读取.bin内的压缩数据块,从而提升数据查询的性能。
- sizes.json:元数据文件,记录了[column].bin和__marks.mrk大小的信息。
CREATE TABLE log_1 (
id UInt64,
code UInt64
)ENGINE = Log()
INSERT INTO TABLE log_1 SELECT number,number+1 FROM numbers(200)
7.4. 接口类型
7.4.1. Merge
- 在数据仓库的设计中,数据按年分表存储,例如test_table_2018、test_table_2019和 test_table_2020。假如现在需要跨年度查询这些数据 ?
- Merge表引擎就如同一层使用了门面模式的代理,它本身不存储任何数据,也不支持数据写入。
- 它的作用就如其名,即负责合并多个查询的结果集。
- Merge表引擎可以代理查询任意数量的数据表,这些查询会异步且并行执行,并最终合成一个结果集返回。
- 被代理查询的数据表被要求处于同一个数据库内,且拥有相同的表结构,但是它们可以使用不同的表引擎以及不同的分区定义
ENGINE = Merge(database, table_name)
-- database表示数据库名称;
-- table_name表示数据表的名称,它支持使用正则表达式
8、 数据查询方式
- ClickHouse对于SQL语句的解析是大小写敏感的,这意味着SELECT a和SELECT A表示的语义是不 相同的。
[WITH expr |(subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]] ]
JOIN (subquery)|table ON|USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]
- 方括号包裹的查询子句表示其为可选项,所以只有SELECT子句是必须的,
- ClickHouse对于查询语法的解析也大致是按照上面各个子句排列的顺序进行的。
8.1. With子句
-
支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达。
-
在改用CTE的形式后,可以极大地提高语句的可读性和可维护性。
-
定义变量
-
这些变量能够在后续的查询子句中被直接访问。
-
WITH 10 AS start SELECT number FROM system.numbers WHERE number > start LIMIT 5
-
-
调用函数
-
访问SELECT子句中的列字段,并调用函数做进一步的加工处理。
-
WITH SUM(data_uncompressed_bytes) AS bytes SELECT database , formatReadableSize(bytes) AS format FROM system.columns GROUP BY database ORDER BY bytes DESC
-
-
定义子查询
-
-- 子查询 WITH ( SELECT SUM(data_uncompressed_bytes) FROM system.columns ) AS total_bytes SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage FROM system.columns GROUP BY database ORDER BY database_disk_usage DESC
-
-
子查询中重复(嵌套)使用WITH
-
嵌套使用WITH子句
-
WITH ( round(database_disk_usage) ) AS database_disk_usage_v1 SELECT database,database_disk_usage, database_disk_usage_v1 FROM ( -- 嵌套 WITH ( SELECT SUM(data_uncompressed_bytes) FROM system.columns ) AS total_bytes SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage FROM system.colum GROUP BY database ORDER BY database_disk_usage DESC )
-
8.2. From子句
-
FROM子句表示从何处读取数据,目前支持如下3种形式
- 从数据表中取数
SELECT WatchID FROM hits_v1
- 从子查询中取数
SELECT MAX_WatchID FROM (SELECT MAX(WatchID) AS MAX_WatchID FROM hits_v1)
- 从表函数中取数
SELECT number FROM numbers(5)
- 从数据表中取数
-
在ClickHouse中,并没有数据库中常见的DUAL虚拟表,取而代之的是system.one。
-
SELECT 1 SELECT 1 FROM system.one -
在FROM子句后,可以使用Final修饰符。
- 它可以配合CollapsingMergeTree和Versioned-CollapsingMergeTree等表引擎进行查询操作,以强制在查询过程中合并
- 但由于Final修饰符会降低查询性能,所以应该尽可能避免使用它。
8.3. Sample子句
- 能够实现数据抽样的功能,使查询仅返回采样数据而不是全部数据,从而有效减少查询负载。
- SAMPLE子句只能用于MergeTree系列引擎的数据表,并且要求在CREATE TABLE时声明SAMPLE BY抽样表达式
-- Sample Key声明的表达式必须也包含在主键的声明中
-- Sample Key必须是Int类型,如若不是,ClickHouse在进行CREATE TABLE操作时也不会报
错
CREATE TABLE hits_v1 (
CounterID UInt64,
EventDate DATE,
UserID UInt64
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, intHash32(UserID))
SAMPLE BY intHash32(UserID)
-
SAMPLE子句目前支持如下3种用法
-
SAMPLE factor
-
SAMPLE factor表示按因子系数采样,其中factor表示采样因子,它的取值支持0~1之间 的小数。
-
如果factor设置为0或者1,则效果等同于不进行数据采样。
-
SELECT count() * 10 FROM hits_v1 SAMPLE 0.1 SELECT CounterID, _sample_factor FROM hits_v1 SAMPLE 0.1 LIMIT 2
-
-
SAMPLE rows
-
SAMPLE rows表示按样本数量采样,其中rows表示至少采样多少行数据,它的取值必须 是大于1的整数。
-
如果rows的取值大于表内数据的总行数,则效果等于rows=1
-
SELECT count() FROM hits_v1 SAMPLE 10000 SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 100000 LIMIT 1
-
-
SAMPLE factor OFFSET n
-
SAMPLE factor OFFSET n表示按因子系数和偏移量采样,其中factor表示采样因子,n 表示偏移多少数据后才开始采样,它们两个的取值都是0~1之间的小数。
-
-- 最终的查询会从数据的0.5处开始,按0.4的系数采样数据 SELECT CounterID FROM hits_v1 SAMPLE 0.4 OFFSET 0.5 -- 最终的查询会从数据的二分之一处开始,按0.1的系数采样数据 SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 1/10 OFFSET 1/2 -
如果在计算OFFSET偏移量后,按照SAMPLE比例采样出现了溢出,则数据会被自动截断
-
-
8.4. Array Join子句
- ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行。接下来让我们看看它的基础用法。
- 一条SELECT语句中,只能存在一个ARRAY JOIN(使用子查询除外)。目前支持INNER和LEFT两种
- INNER ARRAY JOIN 默认
- LEFT ARRAY JOIN 左连接
CREATE TABLE query_v1(
title String,
value Array(Int8)
) ENGINE = Log
INSERT INTO query_v1 VALUES ('food', [1,2,3]), ('fruit', [3,4]), ('meat', []);
SELECT title,value FROM query_v1;
8.5. Join 子句
- JOIN子句可以对左右两张表的数据进行连接
- JOIN的语法包含连接精度和连接类型两部分
- JOIN查询还可以根据其执行策略被划分为本地查询和远程查询。

-
目前支持ALL、ANY和ASOF三种类型。如果不主动声明,则默认是ALL。
- all 如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据。
- any 如果左表内的一行数据,则仅返回右表中第一行连接的数据。
- asof ASOF是一种模糊连接,它允许在连接键之后追加定义一个模糊连接的匹配条件asof_column;仅返回了右表中第一行连接匹配的数据。
-
连接类型
- INNER JOIN表示内连接,在查询时会以左表为基础逐行遍历数据,
- OUTER JOIN表示外连接,它可以进一步细分为左外连接(LEFT)、右外连接(RIGHT)和全外连接(FULL)三种形式。
- CROSS JOIN表示交叉连接,它会返回左表与右表两个数据集合的笛卡儿积。
-
查询优化
- 为了能够优化JOIN查询性能,首先应该遵循左大右小的原则 ,无论使用的是哪种连接方式,右表都会被全部加载到内存中与左表进行比较。
- JOIN查询目前没有缓存的支持
- 如果是在大量维度属性补全的查询场景中,则建议使用字典代替JOIN查询
- 连接查询的空值是由默认值填充的,这与其他数据库所采取的策略不同(由Null填充)。
8.6. WHERE与PREWHERE子句
-
WHERE子句基于条件表达式来实现数据过滤。如果过滤条件恰好是主键字段,则能够进一步借助索引加速查询;
-
PREWHERE目前只能用于MergeTree系列的表引擎,它可以看作对WHERE的一种优化,其作用与WHERE相同,均是用来过滤数据。
-
ClickHouse实现了自动优化的功能,会在条件合适的情况下将WHERE替换为PREWHERE。
如果想开启这项特性,需要将optimize_move_to_prewhere设置为1
8.7. GROUP BY子句
-
GROUP BY又称聚合查询
-
聚合查询目前还能配合WITH ROLLUP、WITHCUBE和WITH TOTALS三种修饰符获取额外的汇总信
息。
8.7.1. WITH ROLLUP
- 按照聚合键从右向左上卷数据,基于聚合函数依次生成分组小计和总计。
- 设聚合键的个数为n,则最终会生成小计的个数为n+1。
8.7.2. WITH CUBE
- CUBE会像立方体模型一样,基于聚合键之间所有的组合生成小计信息。如果设聚合键的个数为n,则最终小计组合的个数为2的n次方。
8.7.3. WITH TOTALS
- 使用TOTALS修饰符后,会基于聚合函数对所有数据进行总计
8.8. Having子句
- HAVING子句需要与GROUP BY同时出现,不能单独使用。它能够在聚合计算之后实现二次过滤数据。
8.9. ORDER BY子句
-
ORDER BY子句通过声明排序键来指定查询数据返回时的顺序。
-
ORDER BY在使用时可以定义多个排序键,每个排序键后需紧跟ASC(升序)或DESC(降序)来确定排列顺序。如若不写,则默认为ASC(升序)。
-
空值处理
-
NULLS LAST
数据的排列顺序为其他值(value)→NaN→NULL。
-
NULLS FIRST
数据的排列顺序为NULL→NaN→其他值(value)
ORDER BY v1 DESC NULLS FIRST
-
8.10. LIMIT BY子句
-
LIMIT BY子句和大家常见的LIMIT所有不同,它运行于ORDER BY之后和LIMIT之前,能够按照指定分组,最多返回前n行数据(如果数据少于n行,则按实际数量返回)
-
常用于TOP N的查询场景。LIMIT BY的常规语法如下:
LIMIT n BY express
8.11. LIMIT子句
-
LIMIT子句用于返回指定的前n行数据,常用于分页场景
-
LIMIT n
SELECT number FROM system.numbers LIMIT 10 -
LIMIT n OFFSET m
SELECT number FROM system.numbers LIMIT 10 OFFSET 5 -
LIMIT m,n
SELECT number FROM system.numbers LIMIT 5 ,10
5、 副本与分片
