TCP拥塞控制详解 | 7. 超越TCP
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach[1]
第7章 超越TCP
随着对拥塞控制的探索不断深入,出现了许多新的算法和协议,与我们前几章中所介绍方法的主要不同之处在于,它们大多数都针对特定用例优化,而不是TCP所支持的任意复杂度的异构网络环境。QUIC可能是个例外,其最初目标是提升HTTP的性能,但现在已经发展成为一种通用的TCP替代方案。
本章将介绍其中某些具体用例,但并没有详尽包含所有可能选项。这些用例包括数据中心TCP性能调优;在较长时间段内仅用剩余容量传输背景流量;非TCP兼容的基于HTTP的web流量优化;以TCP友好的方式支持实时流;支持多路径传输协议;以及具有独特无线电诱导行为的移动蜂窝网络。
7.1 数据中心(DCTCP, On-Ramp)
有一些针对云数据中心的TCP优化工作,其中之一是数据中心TCP(Data Center TCP) ,数据中心环境的几个特点使我们可以采用不同于传统TCP的方法,这些特点包括:
- 数据中心内流量的往返时间较小;
- 数据中心交换机中的缓冲区通常也很小;
- 所有的交换机都在统一的管理控制之下,因此可以要求满足一定的标准;
- 大量流量具有较低的时延要求;
- 这些流量与高带宽流竞争;
应该注意的是,DCTCP不仅仅是TCP的一个版本,而是一种改变交换机行为和终端主机对从交换机接收到的拥塞信息的响应的系统设计。
DCTCP的核心观点是,在数据中心环境中使用丢包作为拥塞的主要信号是不够的。当队列已经积累到足以溢出时,低延迟流量已经无法满足其最低需求,因此会对性能产生负面影响。DCTCP使用ECN的一个版本来提供拥塞的早期信号。但是,ECN的原始设计将ECN标记处理得很像一个丢包,并将拥塞窗口缩短一半,而DCTCP采用了一种更精细的方法。DCTCP试图估算遇到拥塞的字节比例,而不是简单判断拥塞是否发生。然后,根据这个估算缩放拥塞窗口。同时标准TCP算法仍然在数据包实际丢失的情况下发挥作用。该方法的设计目的是通过提前对拥塞做出反应来保持队列较短,同时不对空队列做出过度反应,避免牺牲吞吐量。
该方法的关键挑战是估算遇到拥塞的字节比例。对于每个交换机来说计算都很简单,如果一个包到达,并且交换机看到队列长度(K)超过某个阈值,例如,
其中C是每秒数据包的链路速率,然后交换机设置IP报头中的CE位。该算法避免了RED的复杂性。
然后,接收器为每个流维护一个布尔变量,我们将其表示为DCTCP.CE,并将其初始值设置为false。当发送ACK报文时,如果DCTCP.CE为true,接收端会在TCP报头中设置ECE (Echo Congestion Experienced)标志,并且实现了以下状态机来响应每一个收到的数据包:
- 如果设置了CE位,并且
DCTCP.CE=False, 设置DCTCP.CE为True,并立即发送ACK。 - 如果没有设置CE位,并且
DCTCP.CE=True, 设置DCTCP.CE为False,并立即发送ACK。 - 其他清空清空忽略CE位。
"其他"情况的非明显后果是,只要收到CE值固定的数据包流,接收端就会每n个数据包发送一次延迟ACK,延迟ACK已被证明对保持高性能非常重要。
在每个观察窗口(通常选择近似于RTT的周期)结束时,发送端计算在该窗口期间遇到拥塞的字节的比例,即标记为CE的字节与总传输字节的比率。DCTCP以与标准算法完全相同的方式增加拥塞窗口,但减小窗口的方式与上次观察窗口期间遇到拥塞的字节数成正比。
具体来说,引入一个名为DCTCP.Alpha的新变量并初始化为1,在观察窗口的最后更新如下:
M是标记的字节组,g是估算增益,为常数(由实现设置),决定了DCTCP.Alpha随数据包的标记而变化的速度。当出现持续拥塞时,DCTCP.Alpha接近1,如果持续通畅(没有阻塞),DCTCP.Alpha衰减到0。这样对新拥堵反应较小,对持续拥堵反应较大,拥堵窗口的计算如下:
综上所述,CE标记表明早期且频繁发生的拥塞,但对这种标记的反应比标准TCP更慎重,以避免过度反应导致队列空。
阐述了DCTCP的论文,包括推动其设计的数据中心流量特性的研究,获得了SIGCOMM的"test of time"奖。
延伸阅读:
M. Alizadeh, et al. Data Center TCP (DCTCP). ACM SIGCOMM, August 2010.
自DCTCP以来,已经有相当多关于数据中心TCP优化的研究,一般方法是从网络中引入更复杂的信号,发送方可以使用这些信号来管理拥塞。我们通过详细介绍最近的一项成果On-Ramp来结束对这一用例的讨论,它侧重于所有拥塞控制算法面临的根本问题: 平衡长期流量与瞬态突发流量。On-Ramp采用模块化设计,直接解决了这一冲突,而且不需要依赖来自网络的额外反馈。
其主要的观点是,当处于平衡状态的拥塞控制算法遇到严重拥塞并大幅减少窗口(或速率)时,必须决定是否记住之前的均衡状态。这是一个困难的选择,因为这取决于拥堵的持续时间,而拥堵的持续时间很难预测。如果拥塞是暂时的,算法应该记住之前的状态,这样一旦突发流量结束,就可以迅速恢复到原来的均衡状态,避免浪费网络资源。如果由于一个或多个新流的到来造成了持续的拥塞,算法应该忽略之前的状态,以便迅速找到新的均衡。
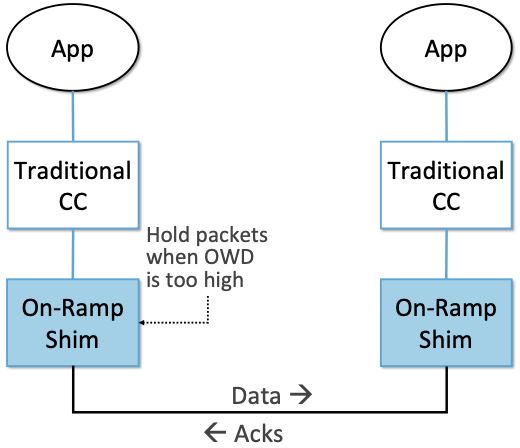 图41. On-Ramp对数据包传输进行配速,以避免由于突发流量导致的网络排队,补充了传统拥塞控制算法保持长期稳定性和公平性的努力。
图41. On-Ramp对数据包传输进行配速,以避免由于突发流量导致的网络排队,补充了传统拥塞控制算法保持长期稳定性和公平性的努力。
其思想是将拥塞控制机制分成两部分,每一部分只关注长期/瞬时流量平衡的一个方面。具体来说,On-Ramp被实现为位于传统TCP拥塞控制算法之下的"垫片(shim)",如图41所示。On-Ramp处理突发流量(临时填充网络队列),当测量到单向延迟(OWD, One-Way Delay) 增长过大(在OWD大于某个阈值)时在发送端临时缓存数据包(而不是占用网络内缓冲区)来试图快速减少排队时延。然后On-Ramp与现有拥塞控制算法合作,努力达成长期流量的平衡。On-Ramp已经被证明可以与包括DCTCP在内的几种拥塞控制算法一起工作。
On-Ramp的关键设计是使两个控制决策在各自的时间尺度上独立运行。但为了正常工作,On-Ramp需要精确测量OWD,而OWD又依赖发送方和接收方之间的同步时钟。由于数据中心延迟可以小于几十微秒,发送方和接收方的时钟必须同步到几微秒内。这种高精度的时钟同步传统上需要硬件密集型协议,但On-Ramp利用了一种新的方法,利用协作节点网格中的网络效应来实现纳秒级的时钟同步,而不需要特殊硬件,这使得On-Ramp很容易部署。
延伸阅读:
S. Liu, et al. Breaking the Transience-Equilibrium Nexus: A New Approach to Datacenter Packet Transport. Usenix NSDI ‘21. April 2021.
Y. Geng, et al. Exploiting a Natural Network Effect for Scalable, Fine-grained Clock Synchronization. Usenix NSDI ‘18, April 2018.
7.2 背景传输(LEDBAT)
与低延迟数据中心环境形成鲜明对比的是,许多应用程序需要在很长一段时间内传输大量数据,BitTorrent和软件更新等文件共享协议就是类似例子。LEDBAT(Low Extra Delay Background Transport)就是为了解决这一用例的问题的。
改进TCP拥塞控制算法的各种努力的共同主题之一是与标准TCP共存。众所周知,算法可以通过更积极的响应拥塞而"超越"TCP。因此,隐含的假设是新的拥塞控制算法应该与标准TCP一起评估,以确保不只是从不那么激进的TCP实现中窃取带宽。
LEDBAT采用了相反的思路,它创建了一个故意不像TCP那么咄咄逼人的拥塞控制协议。其思想是利用链路不拥塞时可用的带宽,但在其他标准流到达时,迅速收回流量并将带宽留给其他流。此外,顾名思义,与TCP填充瓶颈链路时的典型行为不同,LEDBAT尽量不触发明显的排队延迟。
与TCP Vegas一样,LEDBAT的目标是在拥塞严重到足以造成丢包之前检测到它的发生。然而,LEDBAT采用了一种不同的方法来进行,即通过单向延迟测量作为主要输入参数。这是一个相对新颖的方法,在一个具有合理精度但不完全同步的时钟被认为是常态的时代是有意义的。
为了计算单向延迟,发送方在每个传输包中放入时间戳,接收方将其与本地系统时间进行比较,以测量包所经历的延迟,然后将这个计算值发送回发送方。即使时钟不是精确同步的,这种延迟的变化也可以用来推断队列的堆积。假设时钟没有较大的相对"偏差",即它们的相对偏移量不会变化太快,这在实践中是一个合理的假设。
发送端监测测量到的延迟,并估算固定组件(可能是由于光速和其他固定延迟)是在某一(可配置的)时间间隔内看到的最低值。排除时间最久的估算,从而允许改变路由路径并改变固定延迟。任何超过这个最小值的延迟都被认为是由于排队引起的延迟。
建立"基础"延迟后,发送方从测量延迟中减去该延迟以获得排队延迟,并可以选择性的使用滤波算法来减少估算中的短期噪声。然后将这个估计的排队延迟与目标延迟进行比较,当延迟低于目标时,允许增大拥塞窗口,当延迟高于目标时,减小拥塞窗口,其增大和减小的速度与距离目标的距离成正比,增大速度被限制为不超过标准TCP窗口在增长阶段的增长速度。
LEDBAT在收到ACK时设置CongestionWindow的算法总结如下:
其中,GAIN取值为0到1的配置参数,off_target是测量的排队延迟和目标之间的差距,表示为目标的一个分数,bytes_newly_acked是当前ACK中确认的数据包字节数。因此,测量延迟相对目标越低,拥塞窗口增长越快,但绝不会超过每个RTT一个MSS。减小速度与队列长度超过目标的距离成正比。CongestionWindow在响应丢包、超时和长空闲期时也会有所减少,这与TCP非常相似。
因此,LEDBAT可以很好的利用空闲的可用带宽,同时避免创建长队列,其目标是将时延保持在目标附近(这是一个可配置的数字,建议在100毫秒量级)。如果其他流量开始与LEDBAT流竞争,LEDBAT将会后退,从而防止队列变长。
LEDBAT被IETF定义为实验协议,允许相当大程度的实现灵活性,例如根据延迟估算和一系列配置参数,可以在RFC中找到更多细节。
延伸阅读:
S. Shalunov, et al. Low Extra Delay Background Transport (LEDBAT). RFC 6817, December 2012.
7.3 HTTP性能(QUIC)
HTTP自20世纪90年代万维网发明以来就一直存在,一开始就运行在TCP上。最初版本HTTP/1.0由于使用TCP的方式存在大量性能问题,例如,每个对象的请求都需要建立新的TCP连接,然后在返回应答后关闭。早期提出的HTTP/1.1的目的是更好的利用TCP。TCP继续被HTTP使用了20多年。
事实上,TCP作为一种支持Web的协议仍然存在问题,特别是因为可靠、有序的字节流并不完全是Web流量的正确模型。特别是,由于大多数网页包含许多对象,因此能够并行请求许多对象是有意义的,但TCP只提供单一字节流。如果一个包丢失,TCP会等待重传这个数据包,然后再继续,然而HTTP可以很高兴的接收其他不受单个丢包影响的对象。多TCP连接似乎是一个解决方案,但也有其自身缺陷,包括缺乏连接之间拥塞的共享信息。
高延迟无线网络的兴起等其他因素使得单一设备有可能使用多个网络(例如,Wi-Fi和蜂窝网络)。同时,加密、身份验证等越来越多被使用,也促使人们认识到HTTP的传输层将从新方法中受益。为满足这一需求而出现的协议是QUIC。
QUIC由谷歌在2012年提出,随后被提议为IETF标准。它已经得到了大量的部署,出现在大多数Web浏览器和流行网站中,甚至开始用于非HTTP应用程序。可部署性是协议设计者考虑的关键因素。在QUIC中有很多可选部分,其规范跨越了三个RFC,长达几百页,但在这里主要关注其拥塞控制方法,其中包含了我们在本书中看到的许多观点。
和TCP一样,QUIC在传输中建立拥塞控制,但它认识到没有完美的拥塞控制算法。相反,它假设不同的发送者可能使用不同的算法。QUIC规范中的基准算法类似于TCP NewReno,但发送方可以单方面选择不同的算法,如CUBIC。QUIC提供了所有的机制来检测丢包,以支持各种拥塞控制算法。
与TCP相比,QUIC的许多设计特性使丢包和拥塞检测更加健壮。例如,无论是第一次发送还是重传,TCP对一个数据包使用相同的序列号,而QUIC序列号(称为包号)是严格递增的。序列号越大表示报文发送的时间越晚,越低表示报文发送的时间越早,这意味着始终有可能区分第一次传输的数据包和由于丢包或超时重传的数据包。
还要注意,TCP序列号指的是传输字节流中的字节,而QUIC序列号指的是整个包。由于QUIC序列号空间足够大(高达2^62 - 1),可以避免循环问题。
QUIC协议支持选择性确认,在TCP SACK选项中可以支持确认三个以上数据包范围,从而提高了高丢包环境性能,只要成功接收了部分包,就可以向前推进。
与TCP快速恢复所依赖的重复ACK相比,QUIC采用了一种更可靠的方法来判断丢包。该方法是独立于QUIC开发的,名为RACK-TLP: 最近确认和尾丢包探针(Recent Acknowledgments and Tail Loss Probes)。其关键观点为,当发送方在丢包之后没有发送足够的数据来触发重复ACK时,或者当重传的数据包本身丢失时,重复ACK无法触发丢包恢复。相反,如果实际上没有丢包,包的重排序也可能触发快速恢复。QUIC采用了RACK-TLP的思想,通过两个机制来解决这个问题:
- 收到包的时候,如果一个序列号更高的包已经被确认,并且这个包在"过去足够长的时间"被发送,或者在确认包之前有K个包(K是一个参数),那么这个包被认为是丢失的。
- 在等待ACK到达的"探测超时时间间隔"之后发送探测包,以触发ACK,从而提供关于丢失包的信息。
第一个机制是确保少量包被重新排序不会被解释为丢包事件。K建议初始设置为3,但如果有更严重的无序情况,可以更新K。"过去足够长的时间"的定义比测量的RTT稍微长一点。
第二个机制是确保即使数据包没有生成重复ACK,也会发送探测数据包来引出进一步的ACK,从而暴露接收到的数据包流中的缺口。通过使用估算RTT及其方差,将"探测超时间隔"计算为足以解释ACK可能遇到的所有延迟。
QUIC是传输协议领域最有趣的发展。TCP的许多限制几十年来一直为人所知,但QUIC代表了迄今为止最成功的努力之一,它在设计空间中指明了一个不同的点,基于几十年来的宝贵经验,将TCP拥塞控制提炼为基准规范。因为QUIC的灵感来自于HTTP和Web的经验(在TCP出现很久之后才出现),提供了关于分层设计和互联网演变中不可预见后果的有趣案例研究。还有更多内容可以介绍,关于QUIC的权威参考是RFC 9000,但是拥塞控制在单独的RFC 9002中涉及。
延伸阅读:
J. Iyengar and I. Swett, Eds. QUIC Loss Detection and Congestion Control. RFC 9002, May 2021.
7.4 TCP友好协议(TCP-Friendly Protocols, TFRC)
正如本书提到的,因为TCP在检测到拥塞时以各种形式退出,因此很容易构建出性能优于TCP的传输协议。任何不通过降低发送速率来响应拥塞的协议,最终都会比它竞争的任何TCP或TCP类流量获得更大的瓶颈链路份额。在有限资源下,这可能会导致拥塞崩溃,而在TCP拥塞控制刚被开发出来时,拥塞崩溃开始变得很普遍。因此,业界有强烈的兴趣确保互联网上的绝大多数流量在某种意义上是"TCP友好的"。
当我们使用"TCP友好"这个术语时,是在说我们期望得到与TCP类似的拥塞响应。LEDBAT可以被认为"比TCP友好",因为在第一个延迟提示时就减少窗口大小,它比TCP更积极的在拥塞时退后。但是有一类应用对于TCP友好需要更多的思考,因为它们不使用基于窗口的拥塞方案,这就是包括流媒体在内的典型"实时"应用。
如视频流和电话等多媒体应用可以通过改变编码参数来调整发送速率,在带宽和质量之间进行权衡。但是,不可能突然大幅降低发送速率而不影响质量,而且它们通常需要在有限的质量级别中进行选择。如3.1节所讨论的,这些考虑导致其采用基于速率的方法,而不是基于窗口的方法。
对于这些应用来说,TCP友好的方法是尝试选择一个与TCP在类似条件下实现的发送速率相似的发送速率,但要以一种防止速率波动太大的方式进行。支持这一想法的是多年来对TCP吞吐量建模的研究。在定义TFRC标准的RFC 5348中给出了TCP吞吐量方程的简化版本,其中一些变量设置为推荐值,目标传输速率X(比特/秒)的方程为:
其中:
- s是分片大小(不包括IP和传输层头域);
- R为RTT,单位为秒;
- P是"丢包事件"的数量,体现为占传输数据包的比例。
虽然这个公式的推导本身就很有趣(参见下面的第二个参考),但这里的关键思想是,如果我们知道RTT和路径的丢包率,就能很好的知道TCP连接能够提供多少带宽。因此,TFRC试图引导无法实现基于窗口的拥塞控制算法的应用程序在相同的条件下达到与TCP相同的吞吐量。
唯一需要解决的问题是p和R的度量,然后决定应用程序应该如何响应X的变化。与其他协议一样,TFRC使用时间戳来比TCP最初更准确的度量RTT。包序列号用于确定接收端丢包,连续丢包被分组为单个丢包事件。从这些信息中可以计算出损包事件概率p,然后由接收端反馈给发送端。
对速率变化的确切响应方式当然取决于应用程序本身,其基本思想是,应用程序可以在一组编码速率中选择能够适应TFRC规定的速率的最高质量。
虽然TFRC的概念可靠,但由于若干原因,其部署很有限。一个原因是以DASH(Dynamic Adaptive Streaming over HTTP) 出现了针对某些类型的流通信的更简单的解决方案。DASH只适用于非实时媒体(例如看电影),但事实证明,这在整个互联网上的媒体流量中占很大比例,事实上在所有互联网流量中占比也很大。
DASH让TCP(或者QUIC)负责拥塞控制,应用程序测量TCP正在交付的吞吐量,然后相应调整视频流的质量,以避免接收端饥饿。这种方法已经被证明适合于视频娱乐,但是由于依赖于接收端有适度的大量缓冲来平滑TCP吞吐量的波动,并不真正适合于交互式音视频领域。DASH的关键实现之一是可以对不同带宽要求的视频进行多质量级编码,并提前存储在流媒体服务器上。然后,一旦观察到的网络吞吐量下降,服务器就会下降到较低质量的流,然后在条件允许的情况下再上升到较高质量的流。客户端可以向服务器发送信息,比如它还有多少缓冲视频等待播放,以帮助服务器选择合适的质量和带宽流。这种方法的成本是服务器上额外的媒体存储,但在现代流媒体视频时代,这种成本已经变得相当廉价。请注意,这里的"服务器"可能是CDN(内容分发网络)中的一个节点。因此,视频流可以利用客户端和服务它的CDN节点之间可用带宽的任何改进,从而传输更高质量级别的媒体。
TFRC的另一个限制是,它使用丢包作为主要拥塞信号,但不响应丢包之前的延迟。虽然在TFRC的研究中这是最先进的技术,但TCP拥塞控制领域现在已经把延迟考虑在内了,比如TCP Vegas和BBR(参见第5章)。当我们考虑到真正需要一些别的支持(不是DASH)的多媒体应用程序正是那些对延迟敏感的应用程序时,这就特别有问题了。由于这个原因,在撰写本文时,仍在继续为实时流量定义TCP友好的拥塞控制标准。IETF RMCAT (RTP Media Congestion Avoidance Techniques)工作组是这项工作的中心。因此,下面的TFRC规范并不是最后的工作,但为如何实现TCP友好协议提供了有用的参考。
延伸阅读:
S. Floyd, M. Handley, J. Padhye, and J. Widmer. TCP Friendly Rate Control (TFRC): Protocol Specification. RFC 5348, September 2008.
J. Padhye, V. Firoiu, D. Towsley, and J. Kurose. Modeling TCP Throughput: A Simple Model and its Empirical Validation. ACM SIGCOMM, September 1998
7.5 多路径传输
虽然连接到互联网的早期主机只有一个网络接口,但现在在一个设备上有至少两个不同网络的接口很常见,最常见的例子是具有蜂窝和WiFi接口的移动电话。另一个例子是数据中心,服务器经常会分配多个网络接口,以提高容错能力。许多应用程序一次只使用一个可用的网络,但同时使用多个接口可以提高性能。这种多路径通信的思想已经存在了几十年,并导致了IETF对TCP扩展的标准化,以支持利用成对主机之间的多路径的端到端连接,这被称为MPTCP(Multipath TCP) 。
一对主机同时通过两条或多条路径发送流量对拥塞控制来说有重要意义。例如,如果两条路径共享一个瓶颈链接,那么每个路径一个TCP连接的简单实现将获得两倍于标准TCP连接的瓶颈带宽份额,MPTCP的设计者在保持多路径好处的同时正着手解决这种潜在的不公平。MPTCP提出的拥塞控制方法同样适用于其他传输协议,如QUIC。多路径传输拥塞控制的高级目标是:
- 在最佳可用路径上执行效果至少与单一路径流一样好。
- 不要从任何路径中获取比单一路径流更多的资源。
- 从最拥堵的路径上移除更多流量,与前两个目标一致。
值得注意的是,对其他TCP流公平的想法有一些微妙之处,我们在第3.2节中讨论过。
虽然多路径算法的细节涉及到复杂的计算,但所采取的总体方法比较简单。拥塞控制算法在每个子流的基础上大致模拟TCP,同时试图确保上述三个目标都得到满足。该算法的核心是使用以下公式在子流上接收到ACK时增加每个子流的拥塞窗口大小。
CongestionWindowTotal是所有子流拥塞窗口的总和, 是子流i的拥塞窗口。MIN的第二个参数模拟了标准TCP将获得的增量,从而确保子流不会比TCP更激进(目标2)。第一个参数使用变量α来确保总体上多路径流获得与使用其最佳可用路径(目标1)相同的吞吐量。RFC 6356介绍了计算α的细节。需要注意的是,因为没有丢包,因此非拥塞路径能够比拥塞路径增加更多的拥塞窗口,随着时间的推移,更多流量会移动到非拥塞路径上(目标3)。
虽然回头看这很简单,但正如Wischik和他的同事在NSDI的一篇论文中介绍的那样,正是基于许多有趣的分析才帮助他们找到了正确的方法。
延伸阅读:
D. Wischik, C. Raiciu, A. Greenhalgh and M. Handley. Design, Implementation and Evaluation of Congestion Control for Multipath TCP. NSDI, April 2011.
C. Raiciu, M. Handley and D. Wischik. Coupled Congestion Control for Multipath Transport Protocols. RFC 6356, October 2011.
7.6 移动蜂窝网络
我们以一个一直受到研究团体关注的用例作为总结: 拥塞控制和移动蜂窝网络之间的相互作用。从历史上看,TCP/IP互联网和移动蜂窝网络是独立发展的,自3G宽带服务引入以来,后者充当了端到端TCP连接的"最后一英里"。随着5G的推出,我们可以预期移动网络将在提供互联网连接方面发挥越来越重要的作用,其如何影响拥塞控制将会受到越来越多的关注。
虽然移动无线连接可以被视为与通过互联网的端到端路径上的任何其他跳没有什么不同,但由于历史原因,它被视为一种特殊情况,端到端路径在逻辑上被划分为图42所示的两个段: 通过互联网的有线段和通过无线接入网(RAN)的无线最后一跳。这种"特殊情况"的观点是有理由的,因为(1)由于无线电频谱的稀缺,无线链路通常是瓶颈;(2)由于设备移动性和无线电干扰的综合效果,RAN中可用带宽可能是高度可变的;并且(3)当设备从一个蜂窝移动到另一个蜂窝时,由给定基站提供服务的设备数量会波动。
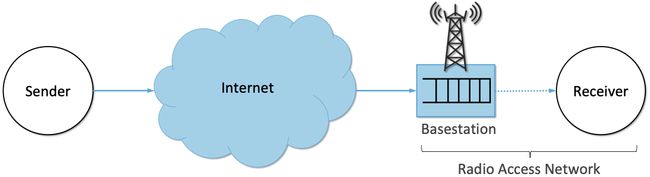 图42. 包括最后一跳无线链路的端到端路径,其中基站缓冲数据包等待通过无线接入网(RAN)传输。
图42. 包括最后一跳无线链路的端到端路径,其中基站缓冲数据包等待通过无线接入网(RAN)传输。
虽然RAN内部很大程度上是封闭和专有的,但研究人员通过实验观察到,在边缘有明显的缓冲,这可能是为了吸收预期的无线电链路争用,同时在容量打开时保持足够的工作负载。正如Haiqing Jiang和他的同事在2012年CellNet研讨会论文中指出的那样,这种大缓冲区对于TCP拥塞控制是有问题的,会导致发送端超出无线电链路上的实际可用带宽,并且在这个过程中,会引入显著的延迟和抖动。这是第6.3节中确定的缓冲膨胀问题的另一个示例。
延伸阅读:
H. Jiang, Z. Liu, Y. Wang, K. Lee and I. Rhee. Understanding Bufferbloat in Cellular Networks ACM SIGCOMM Workshop on Cellular Networks, August 2012.
Jiang的论文提出了可能的解决方案,并普遍观察到,像Vegas这样基于延迟的方法比Reno或CUBIC这样基于丢包的方法表现更好,但近十年来,这个问题在很大程度上一直没有得到解决。随着基于开源软件的RAN实现的承诺正在逐步兴起,可能很快就可以采取跨层方法,由RAN提供接口,使基站内部发生的事情对更高层次的协议栈(例如,在第6章中描述的AQM机制)可见。 Xie Yi和Jamieson最近的研究表明,这种方法可能是有效的,尽管他们的实现使用终端设备反馈,而不是让RAN直接参与。无论如何实现,其想法是让接收方明确告诉发送方在最后一跳上有多少带宽可用,然后发送方必须判断实际瓶颈是在最后一跳还是互联网路径上的其他点上。
延伸阅读:
Y. Xie, F. Yi, and K. Jamieson. PBE-CC: Congestion Control via Endpoint-Centric, Physical-Layer Bandwidth Measurements. SIGCOMM 2020.
L. Peterson and O. Sunay. 5G Mobile Networks: A Systems Approach. January 2020.
L. Peterson, C. Cascone, B. O’Connor, T. Vachuska, and B. Davie. Software-Defined Networks: A Systems Approach. November 2021.
蜂窝网络成为TCP拥塞控制新挑战的另一个方面是,链路带宽不是恒定的,而是随每个接收端所经历的信噪比的函数而变化。正如BBR作者所指出的,这个无线链路的调度器(目前是不透明的)可以使用给定客户端的队列数据包数量作为其调度算法的输入,因此构建队列的"好处"可以增加调度器提供的带宽。BBR试图在其设计中解决这一问题,确保具有足够的侵略性,至少在无线链路缓冲区中缓存一些包。
撇开过去的研究不谈,一个很有趣的问题是,无线连接未来是否仍将保持其独特性。如果从移动网络运营商的角度看,那么目标始终是在大范围变化的条件下最大限度利用稀缺的无线电频谱,使用深度队列将工作负载保持在尽可能高的水平是一种经过验证的方法。当宽带连接是新的服务,语音和文本是主要用例时,这当然是有意义的,但今天的5G需要提供良好的TCP性能,重点应该放在端到端goodput和最大化吞吐量/延迟比(即在第3.2节讨论的功率曲线)。但是有改进的机会吗?
我们相信这个问题的答案是肯定的。除了提供对前面提到的RAN调度器和队列的更多可见性之外,还有三个其他因素可能会改变这个领域。首先,5G部署可能会支持网络切片,这是一种隔离不同类别流量的机制,意味着每个切片都有自己的队列,可以按照特定于流量的方式进行调整和调度。其次,小型基站的普及可能会减少在给定基站上争夺带宽的流量数量,这将如何影响调度器最大化频谱利用率还有待观察。第三,通过附近的边缘云而不是互联网为5G连接设备提供服务将变得越来越普遍,这意味着端到端TCP连接将有更短的往返时间,将使拥塞控制算法对RAN中可用容量的变化更敏感。当然,没人能保证未来如何发展,但所有这些因素都应该为未来调整拥塞控制算法提供充足的机会。
附录
关于拥塞控制的研究论文非常广泛,本书只引用了一小部分。这里收集了更全面的参考书目,(目前)根据书中涉及的主要主题组织。
我们邀请社区帮助保持书目的完整和更新。如果提供额外的引用或修复错误,请提交Pull Request到GitHub[2]。如果对如何改进书目的组织方式提出建议,请向GitHub发布Issue[3]。
基础
队列分析
- L. Kleinrock. Queueing Systems, Volume 2. Wiley & Sons, May 1976.
- V. Paxson and S. Floyd. Wide-Area Traffic: The Failure of Poisson Modeling. IEEE/ACM Transactions on Networking, June 1995.
- W. Leland et al, On the self-similar nature of Ethernet traffic. ACM SIGCOMM ‘93 Symposium, August 1993.
- J. Gettys. Bufferbloat: Dark Buffers in the Internet. IEEE Internet Computing, April 2011.
理论基础
- M. Mathis, J. Semke, J. Mahdavi, and T. Ott. The Macroscopic Behavior of the TCP Congestion Avoidance Algorithm. SIGCOMM CCR, 27(3), July 1997.
- F. Kelly. Charging and Rate Control for Elastic Traffic. European Transactions on Telecommunications, 8:33–37, 1997.
- S. Athuraliya and S. Low. An Empirical Validation of a Duality Model of TCP and Active Queue Management Algorithms. Proceedings of the Winter Simulation Conference, 2001.
- R. Jain and K. K. Ramakrishnan. Congestion Avoidance in Computer Networks with a Connectionless Network Layer: Concepts, Goals and Methodology. Computer Networking Symposium, April 1988.
评估标准
- R. Jain, D. Chiu, and W. Hawe. A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Computer Systems. DEC Research Report TR-301, 1984.
- Bob Briscoe. Flow Rate Fairness: Dismantling a Religion. ACM SIGCOMM CCR, April 2007.
- R. Ware, et al. Beyond Jain’s Fairness Index: Setting the Bar for the Deployment of Congestion Control Algorithms. ACM SIGCOMM HotNets. November 2019.
架构
- J. Saltzer, D. Reed, and D. Clark. End-to-End Arguments in System Design. ACM Transactions on Computer Systems, Nov. 1984.
- D. Clark, The Design Philosophy of the DARPA Internet Protocols. ACM SIGCOMM, 1988.
- S. Jain, et al. B4: Experience with a Globally-Deployed Software Defined WAN. ACM SIGCOMM, August 2013.
- J. Perry, et al. Fastpass: A Centralized “Zero-Queue” Datacenter Network. ACM SIGCOMM, August 2014.
通用算法
- V. Jacobson. Congestion Avoidance and Control. ACM SIGCOMM ‘88 Symposium, August 1988.
- J. Hoe. Improving the start-up behavior of a congestion control scheme for TCP. ACM SIGCOMM ‘96 Symposium. August 1996.
- L. Brakmo, S. O’Malley, and L. Peterson TCP Vegas: New Technique for Congestion Detection and Avoidance. ACM SIGCOMM ‘94 Symposium. August 1994. (Reprinted in IEEE/ACM Transactions on Networking, October 1995).
- S. Low, L. Peterson, and L. Wang. Understanding TCP Vegas: A Duality Model. Journal of the ACM, Volume 49, Issue 2, March 2002.
- S. Ha, I. Rhee, and L. Xu. CUBIC: a new TCP-friendly high-speed TCP variant. ACM SIGOPS Operating Systems Review, Volume 42, Issue 5, July 2008.
- N. Cardwell, Y. Cheng, C. S. Gunn, S. Yeganeh, V. Jacobson. BBR: Congestion-based Congestion Control. Communications of the ACM, Volume 60, Issue 2, February 2017.
- B. Briscoe, et al. Implementing the “Prague Requirements” for Low Latency Low Loss Scalable Throughput (L4S). Linux NetDev 0x13 Conference, March 2019.
主动队列管理
- K.K. Ramakrishnan and R. Jain. A Binary Feedback Scheme for Congestion Avoidance in Computer Networks with a Connectionless Network Layer. ACM SIGCOMM, August 1988.
- S. Floyd and V. Jacobson Random Early Detection (RED) Gateways for Congestion Avoidance. IEEE/ACM Transactions on Networking. August 1993.
- R. Braden, et al. Recommendations on Queue Management and Congestion Avoidance in the Internet. RFC 2309, April 1998.
- K. Ramakrishnan, S. Floyd, and D. Black. The Addition of Explicit Congestion Notification (ECN) to IP. RFC 3168, September 2001.
- K. Nichols and V. Jacobson. Controlling Queue Delay. ACM Queue, 10(5), May 2012.
特定领域算法
数据中心
- M. Alizadeh, et al. Data Center TCP (DCTCP). ACM SIGCOMM, August 2010.
- R. Mittal, et al. TIMELY: RTT-based Congestion Control for the Datacenter. ACM SIGCOMM 2015.
- S. Liu, et al. Breaking the Transience-Equilibrium Nexus: A New Approach to Datacenter Packet Transport. Usenix NSDI ‘21. April 2021.
背景传输
- S. Shalunov, et al. Low Extra Delay Background Transport (LEDBAT). RFC 6817, December 2012.
HTTP
- J. Iyengar and I. Swett, Eds. QUIC Loss Detection and Congestion Control. RFC 9002, May 2021.
无线
- H. Jiang, Z. Liu, Y. Wang, K. Lee and I. Rhee. Understanding Bufferbloat in Cellular Networks. ACM SIGCOMM Workshop on Cellular Networks, August 2012.
- K. Liu and J. Y. B. Lee, On Improving TCP Performance over Mobile Data Networks. IEEE Transactions on Mobile Computing, 2016.
- Y. Xie, F. Yi, and K. Jamieson. PBE-CC: Congestion Control via Endpoint-Centric, Physical-Layer Bandwidth Measurements. SIGCOMM 2020.
- Y. Gao, et al. Understanding On-device Bufferbloat For Cellular Upload. ACM Internet Measurement Conference (IMC), November 2016.
实时
- S. Floyd, M. Handley, J. Padhye, and J. Widmer. TCP Friendly Rate Control (TFRC): Protocol Specification. RFC 5348, September 2008.
- J. Padhye, V. Firoiu, D. Towsley, and J. Kurose. Modeling TCP Throughput: A Simple Model and its Empirical Validation. ACM SIGCOMM, September 1998.
多路径
- D. Wischik, C. Raiciu, A. Greenhalgh and M. Handley. Design, Implementation and Evaluation of Congestion Control for Multipath TCP. NSDI, April 2011.
- C. Raiciu, M. Handley, and D. Wischik. Coupled Congestion Control for Multipath Transport Protocols. RFC 6356, October 2011.
实现与工具
- S.J. Leffler, M.K. McKusick, M.J. Karels, and J.S Quarterman. The Design and Implementation of the 4.3 BSD Unix Operating System. Addison-Wesley. January 1989.
- Netesto.
- NS-3 Network Simulator.
- RFC 6298: Computing TCP’s Retransmission Timer. June 2011.
- The Linux Kernel. BPF Documentation.
关于本书
TCP Congestion Control: A Systems Approach在GitHub上根据创作共用协议(CC BY-NC-ND 4.0)许可条款提供。邀请社区在相同的条件下提供更正、改进、更新和新材料。虽然本授权并不自动授予制作衍生作品的权利,但我们非常希望与感兴趣的各方讨论衍生作品(如翻译)。请联系[email protected]。
如果使用该作品,其包括以下版权信息:
Title: TCP Congestion Control: A Systems Approach
Authors: Larry Peterson, Lawrence Brakmo, and Bruce Davie
Source: https://github.com/SystemsApproach/tcpcc
License: CC BY-NC-ND 4.0
阅读本书
本书是系统方法系列的一部分,其在线版本发布在https://tcpcc.systemsapproach.org。
要跟踪进度并接收新版本通知,可以在Facebook[4]和Twitter[5]上关注本项目。要阅读关于互联网发展的实时评论,请订阅Systems Approach Newsletter。
编译本书
要建立可供网页浏览的版本,首先需要下载源码:
$ mkdir ~/systemsapproach
$ cd ~/systemsapproach
$ git clone https://github.com/SystemsApproach/tcpcc.git
$ cd tcpcc
构建过程实现在Makefile中,并且需要安装Python。Makefile将创建一个虚拟环境(venv-docs),用于安装文档生成工具集,可能还需要使用系统的包管理器安装enchant C库,以便拼写检查器正常工作。
请运行make html,在_build/html中生成HTML。
请运行make lint检查格式。
执行make spelling检查拼写。如果有拼写正确但字典中没有的单词、名称或首字母缩写词,请添加到dict.txt文件中。
请运行make查看其他可用的输出格式。
向本书投稿
如果你使用这些材料,希望也愿意给出回馈。如果你是开放源码的新手,可以查看How to Contribute to Open Source指南,你将学到如何发布Issue,如何发出Pull Request合并改进,以及其他一些主题。
如果你想投稿,并且正在寻找一些需要关注的内容,请查看wiki[6]上的当前待办事项列表。
关于作者
Larry Peterson是普林斯顿大学计算机科学系Robert E. Kahn名誉教授,并从2003年到2009年担任主席。Peterson教授的研究主要集中在互联网大规模分布式系统的设计、实现和操作,包括广泛使用的PlanetLab和MeasurementLab平台。他目前正在为开放网络基金会(ONF)的Aether接入边缘云项目做出贡献,并担任首席科学家。Peterson是美国国家工程院院士,ACM和IEEE院士,2010年IEEE Kobayashi计算机与通信奖得主,2013年ACM SIGCOMM奖得主。Peterson拥有普渡大学博士学位。
Lawrence Brakmo目前在Facebook的Kernel小组工作。在加入Facebook之前,他是谷歌主机网络组的成员,在此之前,是DoCoMo美国实验室操作系统组的研究员和项目经理。Brakmo致力于TCP增强以提高网络性能,包括TCP Vegas和TCP-NV拥塞控制算法的设计。他还开发了操作系统技术,以提高系统的可靠性、性能和能耗。Brakmo在亚利桑那大学获得计算机科学博士学位。
Bruce Davie是计算机科学家,因其在网络领域的贡献而闻名。他是VMware亚太区的前副总裁兼首席技术官,在VMware收购SDN初创公司Nicira期间加入VMware。在此之前,他是Cisco Systems研究员,领导一个架构师团队,负责多协议标签交换(MPLS)。Davie拥有超过30年的网络行业经验,并合著了17个RFC。他于2009年成为ACM研究员,并于2009年至2013年担任ACM SIGCOMM主席。他还在麻省理工学院做了五年的访问讲师。Davie是多本书的作者,拥有40多项美国专利。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
[1]TCP Congestion Control: A Systems Approach: https://tcpcc.systemsapproach.org/index.html
[2]TCP Congestion Control Github: https://github.com/SystemsApproach/tcpcc
[3]TCP Congestion Control Github Issues: https://github.com/SystemsApproach/tcpcc/issues
[4]Systems Approach Facebook: https://www.facebook.com/Computer-Networks-A-Systems-Approach-110933578952503
[5]Systems Approach Twitter: https://twitter.com/SystemsAppr
[6]Systems Approach Wiki: https://github.com/SystemsApproach/tcpcc/wiki
- END -本文由 mdnice 多平台发布